
Cette page présente la réplication interrégionale d'AlloyDB pour PostgreSQL.
La réplication interrégionale d'AlloyDB vous permet de créer des clusters et des instances secondaires à partir d'un cluster principal. Vous pouvez ainsi rendre les ressources disponibles dans différentes régions en cas de panne dans la région principale. Ces clusters et instances secondaires fonctionnent comme des copies des ressources de votre cluster et de votre instance principaux.
Voici les principaux concepts abordés sur cette page :
Cluster principal : cluster en lecture/écriture dans une seule région.
Cluster secondaire : cluster en lecture seule situé dans une région différente de celle du cluster principal, qui effectue une réplication asynchrone à partir du cluster principal. En cas de défaillance d'un cluster principal AlloyDB, vous pouvez promouvoir un cluster secondaire en cluster principal.
Vous pouvez créer jusqu'à cinq clusters secondaires pour un cluster principal. Tous les clusters secondaires effectuent une réplication à partir d'un seul cluster principal. Si vous promouvez un cluster secondaire, il devient un cluster principal indépendant.
Instance secondaire : leader en lecture seule d'un cluster secondaire. Elle est chargée de recevoir un flux de réplication à partir d'un cluster principal. Le flux de réplication met à jour le volume de stockage dans la région secondaire en fonction du volume de stockage dans la région principale. Si un cluster secondaire est promu en cluster principal, l'instance secondaire devient l'instance principale.
Une instance secondaire peut être de base (zonale) ou à haute disponibilité (régionale).
Le schéma suivant illustre le fonctionnement de la réplication interrégionale :
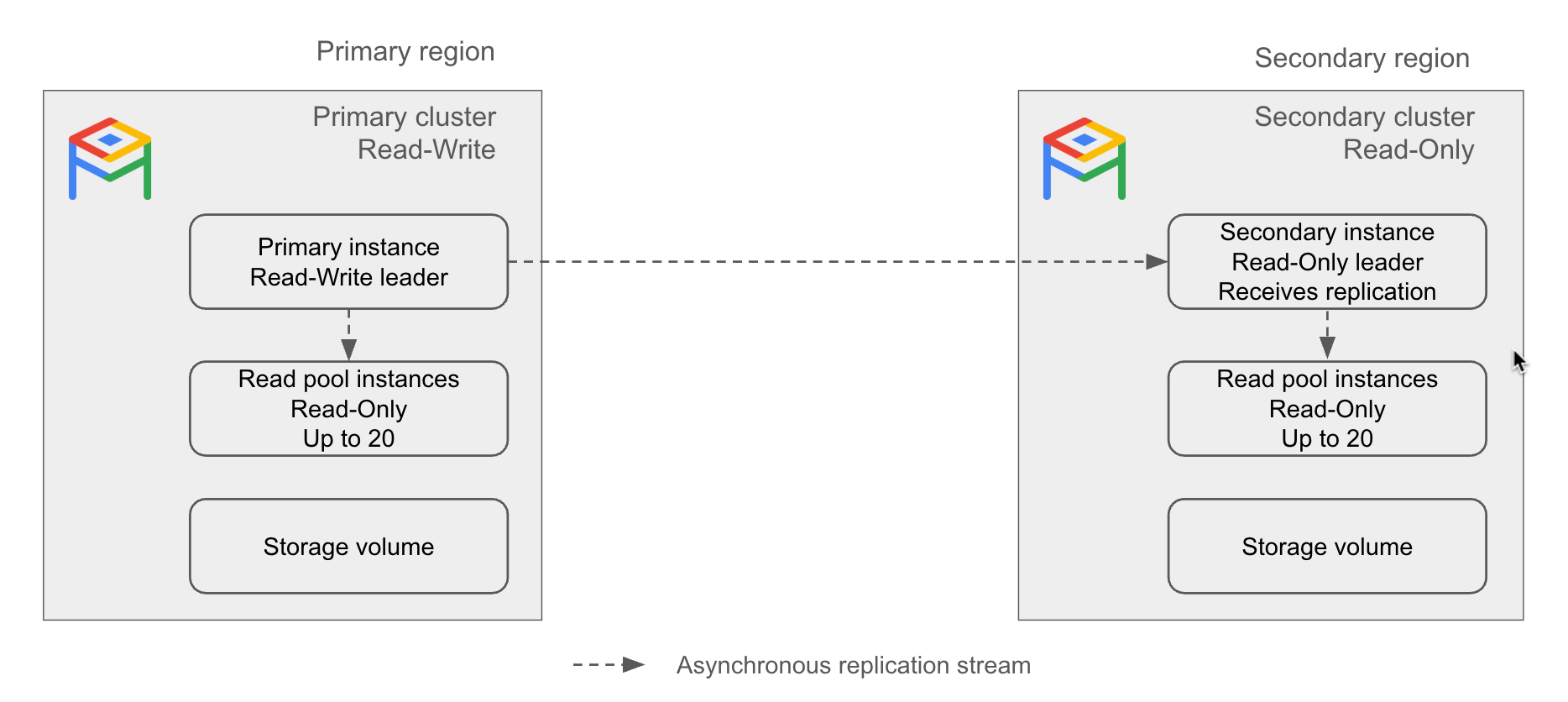
Figure 1 : exemple d'architecture de réplication interrégionale d'AlloyDB.
Avantages
La réplication interrégionale sur AlloyDB présente les avantages suivants :
Reprise après sinistre : si la région du cluster principal devient indisponible, vous pouvez promouvoir les ressources AlloyDB d'une autre région pour répondre aux requêtes.
Réduction des temps d'arrêt : la prise en charge de la haute disponibilité sur les clusters secondaires réduit les temps d'arrêt lors des événements de maintenance ou des pannes imprévues.
Données réparties géographiquement : la répartition géographique des données les rapproche de vous et réduit la latence en lecture.
Scaling en lecture accru : chaque instance dupliquée interrégionale (ou cluster secondaire) peut accepter jusqu'à 20 nœuds de lecture, ce qui vous permet de faire évoluer davantage vos lectures.
Commutation sans perte de données : pour les configurations de réplication interrégionale, AlloyDB prend en charge la commutation entre l'instance principale et l'instance secondaire sans perte de données.
Utiliser la réplication interrégionale
L'utilisation de la réplication interrégionale d'AlloyDB implique les tâches suivantes :
Créer un cluster secondaire un cluster secondaire est une copie mise à jour en continu de votre cluster AlloyDB principal.
Afficher un cluster secondaire une fois que vous avez créé un cluster secondaire, vous pouvez afficher ses détails sur la page Clusters de la Google Cloud console.
Ajouter des instances de pool de lecture vous pouvez ajouter des instances de pool de lecture à un cluster secondaire. Si vous souhaitez faire évoluer votre capacité de lecture horizontalement, vous pouvez ajouter jusqu'à 20 nœuds de lecture à votre cluster secondaire.
Promouvoir un cluster secondaire. vous pouvez lire les données d'un cluster secondaire, mais vous ne pouvez pas y écrire tant que vous ne l'avez pas promu en cluster principal autonome et complet. Lorsque vous promouvez un cluster secondaire, l'instance secondaire du cluster est également promue en instance principale avec accès en lecture et écriture.
Le principal cas d'utilisation de la promotion d'un cluster secondaire est la reprise après sinistre. Si une panne régionale se produit dans la région de votre cluster principal, vous pouvez promouvoir votre cluster secondaire en cluster principal autonome et reprendre la diffusion de votre application.
Commutation sans perte de données la commutation vous permet d'inverser les rôles de vos clusters principal et secondaire sans perte de données. Vous pouvez effectuer une commutation pour tester votre configuration de reprise après sinistre ou migrer votre charge de travail. Une fois la commutation terminée, la direction de la réplication est inversée.
Si vous disposez de plusieurs clusters secondaires, le cluster secondaire qui reçoit la commande de commutation devient un cluster principal. Le cluster principal précédent devient un cluster secondaire, qui effectue une réplication à partir du nouveau cluster principal. Tous les autres clusters secondaires passent à la réplication à partir du nouveau cluster principal.
Il existe deux scénarios courants pour la commutation de votre cluster secondaire :
- Exercices de reprise après sinistre : vous pouvez exécuter des tests de vos processus de reprise après sinistre en commutant votre application vers une autre région sans perte de données pour simuler une panne régionale.
- Migration régionale : effectuez une migration planifiée des ressources AlloyDB de leur région principale vers une autre région. La commutation garantit que le cluster secondaire devient un cluster principal avec un objectif de point de récupération (RPO) de 0, ce qui garantit que la migration ne perd aucune donnée.
Configurer des sauvegardes automatiques et continues par défaut, AlloyDB copie automatiquement les configurations de sauvegarde automatiques et continues du cluster principal vers un cluster secondaire nouvellement créé. Si vous souhaitez utiliser des configurations de sauvegarde différentes pour votre cluster secondaire, vous pouvez modifier la configuration de sauvegarde lorsque vous créez un cluster secondaire.
Si votre cluster principal utilise le chiffrement avec une clé de chiffrement gérée par le client (CMEK) pour les sauvegardes, effectuez l'une des opérations suivantes lorsque vous créez un cluster secondaire :
- Fournissez les paramètres de chiffrement CMEK pour les sauvegardes du cluster secondaire.
- Désactivez les sauvegardes pour le cluster secondaire.
Pour en savoir plus sur le chiffrement de vos sauvegardes avec CMEK, consultez la section Utiliser CMEK.
Vous pouvez modifier les paramètres de sauvegarde automatiques et continues pour le cluster secondaire après sa création.