
ארכיטקטורה
התרשים הבא מציג את הארכיטקטורה הכללית של צינור extract, load, and transform (ELT) בלי שרת (serverless) באמצעות Workflows.

בתרשים שלמעלה, נניח שיש פלטפורמת קמעונאות שאוספת מעת לעת אירועי מכירות כקבצים מחנויות שונות, ואז כותבת את הקבצים לקטגוריה של Cloud Storage. האירועים משמשים ליצירת מדדים עסקיים באמצעות ייבוא ועיבוד ב-BigQuery. הארכיטקטורה הזו מספקת מערכת תזמור אמינה וללא שרתים (serverless) לייבוא קבצים ל-BigQuery, והיא מחולקת לשני המודולים הבאים:
- רשימת קבצים: רשימת הקבצים שלא עברו עיבוד שנוספו לקטגוריה של Cloud Storage בקולקציה של Firestore.
המודול הזה פועל באמצעות פונקציית Cloud Run שמופעלת על ידי אירוע אחסון מסוג Object Finalize, שנוצר כשמוסיפים קובץ חדש לקטגוריה של Cloud Storage. שם הקובץ מצורף למערך
filesשל האוסף שנקראnewב-Firestore. Workflow: מפעיל את תהליכי העבודה המתוזמנים. Cloud Scheduler מפעיל תהליך עבודה שמבצע סדרה של שלבים בהתאם לתחביר מבוסס YAML כדי לתזמן את הטעינה, ואז להמיר את הנתונים ב-BigQuery באמצעות קריאה לפונקציות של Cloud Run. השלבים בתהליך העבודה מפעילים פונקציות Cloud Run כדי לבצע את המשימות הבאות:
- יוצרים משימת טעינה ב-BigQuery ומפעילים אותה.
- שליחת שאילתה לגבי הסטטוס של משימת הטעינה.
- יוצרים את עבודת השאילתה של הטרנספורמציה ומפעילים אותה.
- שליחת שאילתה לגבי הסטטוס של משימת השינוי.
שימוש בטרנזקציות כדי לשמור על רשימת הקבצים החדשים ב-Firestore עוזר להבטיח שלא יפספסו קובץ כשמייבאים אותו ל-BigQuery בתהליך עבודה. כדי להפוך את ההרצות הנפרדות של תהליך העבודה לאידמפוטנטיות, מאחסנים את המטא-נתונים והסטטוס של המשימה ב-Firestore.
מטרות
- יוצרים מסד נתונים ב-Firestore.
- מגדירים טריגר של פונקציית Cloud Run כדי לעקוב אחרי קבצים שנוספו לקטגוריה של Cloud Storage ב-Firestore.
- פריסת פונקציות Cloud Run להרצה ולמעקב אחרי משימות BigQuery.
- פורסים ומריצים תהליך עבודה כדי להפוך את התהליך לאוטומטי.
עלויות
במסמך הזה משתמשים ברכיבים הבאים של Google Cloud, והשימוש בהם כרוך בתשלום:
כדי להעריך את ההוצאות בהתאם לתחזית השימוש שלכם, אתם יכולים להיעזר במחשבון העלויות.
כשמסיימים את המשימות שמתוארות במסמך הזה אפשר למחוק את המשאבים שיצרתם כדי להימנע מחיובים נוספים. מידע נוסף זמין בקטע הסרת המשאבים.
לפני שמתחילים
-
בדף לבחירת הפרויקט במסוף Google Cloud , בוחרים פרויקט ב- Google Cloud או יוצרים אותו.
תפקידים שנדרשים כדי לבחור או ליצור פרויקט
- Select a project: כדי לבחור פרויקט לא צריך תפקיד IAM ספציפי – אפשר לבחור כל פרויקט שקיבלתם בו תפקיד.
-
יצירת פרויקט: כדי ליצור פרויקט, צריך את התפקיד Project Creator (יצירת פרויקטים) (
roles/resourcemanager.projectCreator), שכולל את ההרשאהresourcemanager.projects.create. איך מקצים תפקידים
-
מפעילים את ממשקי Cloud Build, Cloud Run Functions, ניהול הזהויות והרשאות הגישה, מנהל המשאבים ו-Workflows API.
תפקידים שנדרשים להפעלת ממשקי API
כדי להפעיל ממשקי API, צריך את תפקיד ה-IAM 'אדמין של Service Usage' (
roles/serviceusage.serviceUsageAdmin), שכולל את ההרשאהserviceusage.services.enable. איך מקצים תפקידים עוברים לדף Welcome ורושמים את מזהה הפרויקט כדי להשתמש בו בשלב מאוחר יותר.
במסוף Google Cloud , מפעילים את Cloud Shell.
הכנת הסביבה
כדי להכין את הסביבה, צריך ליצור מסד נתונים של Firestore, לשכפל את דוגמאות הקוד ממאגר GitHub, ליצור משאבים באמצעות Terraform, לערוך את קובץ ה-YAML של Workflows ולהתקין את הדרישות של מחולל הקבצים.
כדי ליצור מסד נתונים של Firestore:
נכנסים לדף Firestore במסוף Google Cloud .
לוחצים על בחירת מצב מותאם.
בתפריט Select a location, בוחרים את האזור שבו רוצים לארח את מסד הנתונים של Firestore. מומלץ לבחור אזור שקרוב למיקום הפיזי שלכם.
לוחצים על יצירת מסד נתונים.
ב-Cloud Shell, משכפלים את מאגר המקור:
cd $HOME && git clone https://github.com/GoogleCloudPlatform/workflows-demos cd workflows-demos/workflows-bigquery-loadב-Cloud Shell, יוצרים את המשאבים הבאים באמצעות Terraform:
terraform init terraform apply \ -var project_id=PROJECT_ID \ -var region=REGION \ -var zone=ZONE \ --auto-approveמחליפים את מה שכתוב בשדות הבאים:
-
PROJECT_ID: מזהה הפרויקט ב- Google Cloud -
REGION: מיקום גיאוגרפי ספציפי לאירוח המשאבים, לדוגמהus-central1Google Cloud -
ZONE: מיקום באזור לאירוח המשאבים, לדוגמהus-central1-b
אמורה להופיע הודעה דומה לזו:
Apply complete! Resources: 7 added, 0 changed, 1 destroyed.בעזרת Terraform אפשר ליצור, לשנות ולשדרג תשתית באופן בטוח וצפוי, ובקנה מידה גדול. המשאבים הבאים נוצרים בפרויקט:
- חשבונות שירות עם ההרשאות הנדרשות כדי להבטיח גישה מאובטחת למשאבים.
- מערך נתונים ב-BigQuery בשם
serverless_elt_datasetוטבלה בשםword_countלטעינת הקבצים הנכנסים. - קטגוריה של Cloud Storage בשם
${project_id}-ordersbucketלאחסון זמני של קובצי קלט. - חמש פונקציות Cloud Run:
-
file_add_handlerמוסיף את שמות הקבצים שנוספו לקטגוריה של Cloud Storage לאוסף Firestore. -
create_jobיוצר משימת טעינה חדשה ב-BigQuery ומשייך קבצים באוסף Firebase למשימה. -
create_queryיוצר משימת שאילתה חדשה ב-BigQuery. -
poll_bigquery_jobמקבל את הסטטוס של משימת BigQuery. -
run_bigquery_jobמתחילה משימת BigQuery.
-
-
מקבלים את כתובות ה-URL של פונקציות Cloud Run
create_job,create_query,poll_jobו-run_bigquery_jobשפרסתם בשלב הקודם.gcloud functions describe create_job | grep url gcloud functions describe poll_bigquery_job | grep url gcloud functions describe run_bigquery_job | grep url gcloud functions describe create_query | grep url
הפלט אמור להיראות כך:
url: https://REGION-PROJECT_ID.cloudfunctions.net/create_job url: https://REGION-PROJECT_ID.cloudfunctions.net/poll_bigquery_job url: https://REGION-PROJECT_ID.cloudfunctions.net/run_bigquery_job url: https://REGION-PROJECT_ID.cloudfunctions.net/create_query
חשוב לרשום את כתובות האתרים האלה, כי תצטרכו אותן כשפריסת תהליך העבודה תסתיים.
יצירה ופריסה של תהליך עבודה
ב-Cloud Shell, פותחים את קובץ המקור של זרימת העבודה,
workflow.yaml:מחליפים את מה שכתוב בשדות הבאים:
-
CREATE_JOB_URL: כתובת ה-URL של הפונקציה ליצירת משימה חדשה -
POLL_BIGQUERY_JOB_URL: כתובת ה-URL של הפונקציה לבדיקת הסטטוס של משימה שפועלת -
RUN_BIGQUERY_JOB_URL: כתובת ה-URL של הפונקציה להפעלת משימת טעינה ב-BigQuery -
CREATE_QUERY_URL: כתובת ה-URL של הפונקציה להפעלת משימת שאילתה ב-BigQuery -
BQ_REGION: האזור ב-BigQuery שבו הנתונים מאוחסנים – למשל,US -
BQ_DATASET_TABLE_NAME: שם הטבלה במערך הנתונים ב-BigQuery בפורמטPROJECT_ID.serverless_elt_dataset.word_count
-
פורסים את הקובץ
workflow:gcloud workflows deploy WORKFLOW_NAME \ --location=WORKFLOW_REGION \ --description='WORKFLOW_DESCRIPTION' \ --service-account=workflow-runner@PROJECT_ID.iam.gserviceaccount.com \ --source=workflow.yamlמחליפים את מה שכתוב בשדות הבאים:
-
WORKFLOW_NAME: השם הייחודי של תהליך העבודה -
WORKFLOW_REGION: האזור שבו תהליך העבודה נפרס. לדוגמה,us-central1 -
WORKFLOW_DESCRIPTION: תיאור תהליך העבודה
-
יוצרים סביבה וירטואלית של Python 3 ומתקינים את הדרישות של מחולל הקבצים:
sudo apt-get install -y python3-venv python3 -m venv env . env/bin/activate cd generator pip install -r requirements.txt
יצירת קבצים לייבוא
gen.py סקריפט Python יוצר תוכן אקראי בפורמט Avro. הסכימה זהה לטבלת word_count ב-BigQuery. קבצי ה-Avro האלה מועתקים לקטגוריה שצוינה ב-Cloud Storage.
ב-Cloud Shell, יוצרים את הקבצים:
python gen.py -p PROJECT_ID \
-o PROJECT_ID-ordersbucket \
-n RECORDS_PER_FILE \
-f NUM_FILES \
-x FILE_PREFIX
מחליפים את מה שכתוב בשדות הבאים:
-
RECORDS_PER_FILE: מספר הרשומות בקובץ אחד -
NUM_FILES: המספר הכולל של הקבצים שיועלו -
FILE_PREFIX: הקידומת לשמות של הקבצים שנוצרו
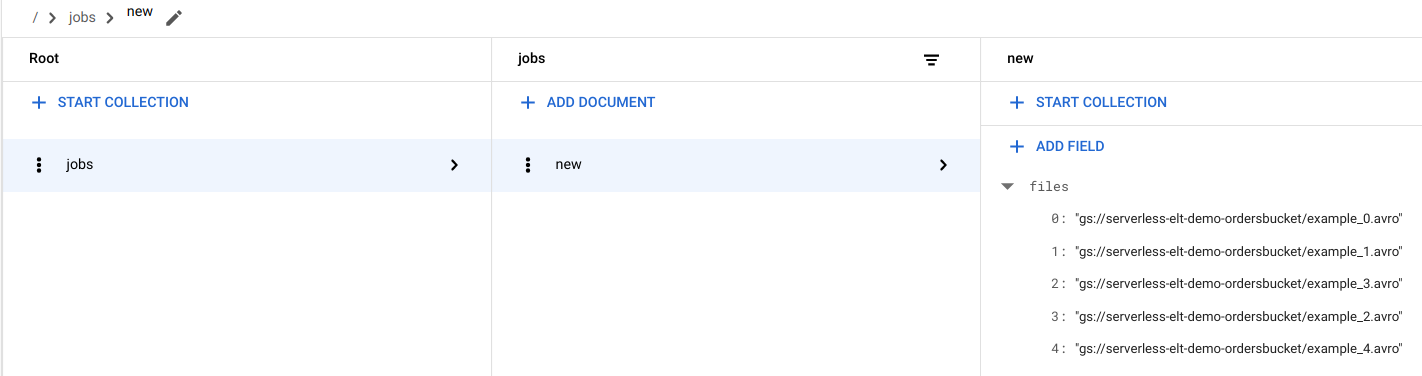
הצגת רשומות של קבצים ב-Firestore
כשמעתיקים את הקבצים ל-Cloud Storage, מופעלת פונקציית Cloud Run handle_new_file. הפונקציה הזו מוסיפה את רשימת הקבצים למערך רשימת הקבצים במסמך new באוסף jobs של Firestore.
כדי לראות את רשימת הקבצים, במסוף Google Cloud עוברים לדף Data של Firestore.
הפעלת תהליך העבודה
Workflows מקשר בין סדרה של משימות ללא שרת מ-Google Cloud ומממשקי API. כל שלב בתהליך העבודה הזה מופעל כפונקציית Cloud Run, והמצב מאוחסן ב-Firestore. כל הקריאות לפונקציות Cloud Run מאומתות באמצעות חשבון השירות של זרימת העבודה.
ב-Cloud Shell, מריצים את זרימת העבודה:
gcloud workflows execute WORKFLOW_NAME
התרשים הבא מציג את השלבים בתהליך העבודה:

תהליך העבודה מחולק לשני חלקים: תהליך העבודה הראשי ותהליך העבודה המשני. תהליך העבודה הראשי מטפל ביצירת משימות ובהרצה מותנית, בעוד שתהליך העבודה המשני מריץ משימת BigQuery. תהליך העבודה מבצע את הפעולות הבאות:
- הפונקציה
create_jobCloud Run יוצרת אובייקט חדש של עבודה, מקבלת את רשימת הקבצים שנוספו ל-Cloud Storage ממסמך Firestore ומשייכת את הקבצים לעבודת הטעינה. אם אין קבצים לטעינה, הפונקציה לא יוצרת משימה חדשה. - פונקציית
create_queryCloud Run מקבלת את השאילתה שצריך להריץ ואת האזור ב-BigQuery שבו השאילתה צריכה לפעול. הפונקציה יוצרת את המשימה ב-Firestore ומחזירה את מזהה המשימה. - פונקציית
run_bigquery_jobCloud Run מקבלת את המזהה של המשימה שצריך להריץ, ואז מפעילה את BigQuery API כדי לשלוח את המשימה. - במקום לחכות לסיום העבודה בפונקציית Cloud Run, אפשר לדגום את סטטוס העבודה באופן תקופתי.
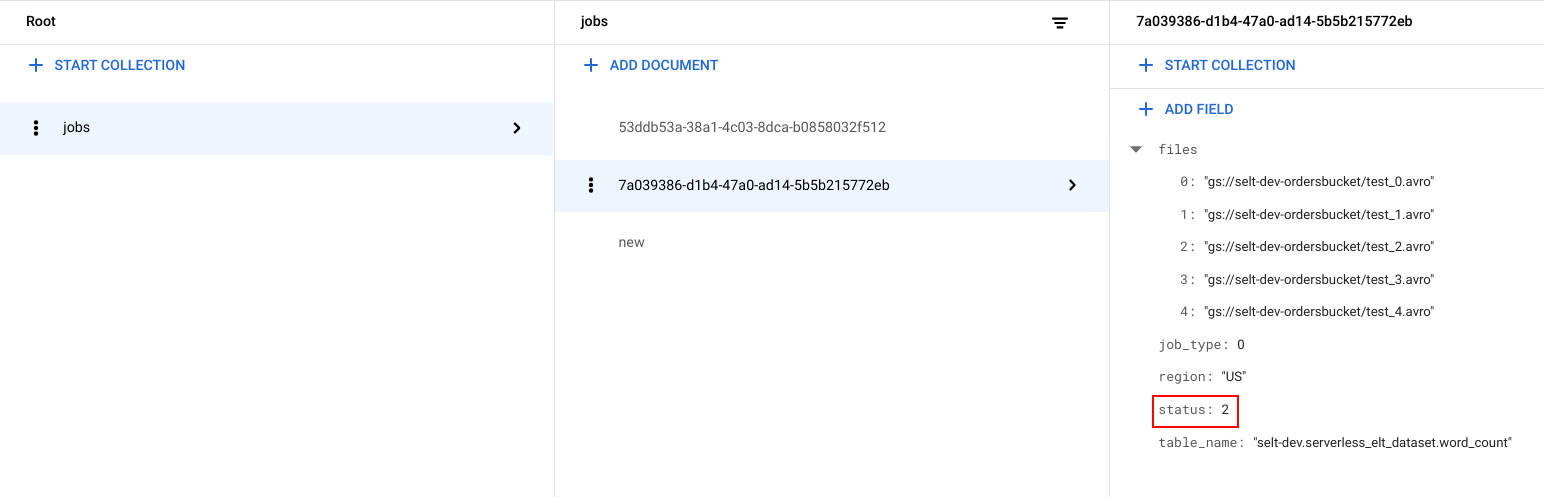
צפייה בסטטוס של המשימה
אפשר לראות את רשימת הקבצים ואת הסטטוס של העבודה.
במסוףGoogle Cloud , עוברים לדף Data ב-Firestore.
מזהה ייחודי (UUID) נוצר לכל משימה. כדי להציג את
job_typeואתstatus, לוחצים על מזהה המשימה. כל עבודה יכולה להיות מסוג מסוים ולכלול סטטוס מסוים מתוך האפשרויות הבאות:
job_type: סוג העבודה שמופעלת על ידי תהליך העבודה, עם אחד מהערכים הבאים:- 0: טעינת נתונים ל-BigQuery.
- 1: מריצים שאילתה ב-BigQuery.
status: המצב הנוכחי של העבודה, עם אחד מהערכים הבאים:- 0: העבודה נוצרה, אבל לא הופעלה.
- 1: העבודה פועלת.
- 2: העבודה הושלמה בהצלחה.
- 3: הייתה שגיאה והעבודה לא הושלמה בהצלחה.
אובייקט המשימה מכיל גם מאפייני מטא-נתונים, כמו האזור של מערך הנתונים ב-BigQuery, השם של הטבלה ב-BigQuery, ואם מדובר במשימת שאילתה, מחרוזת השאילתה שמופעלת.
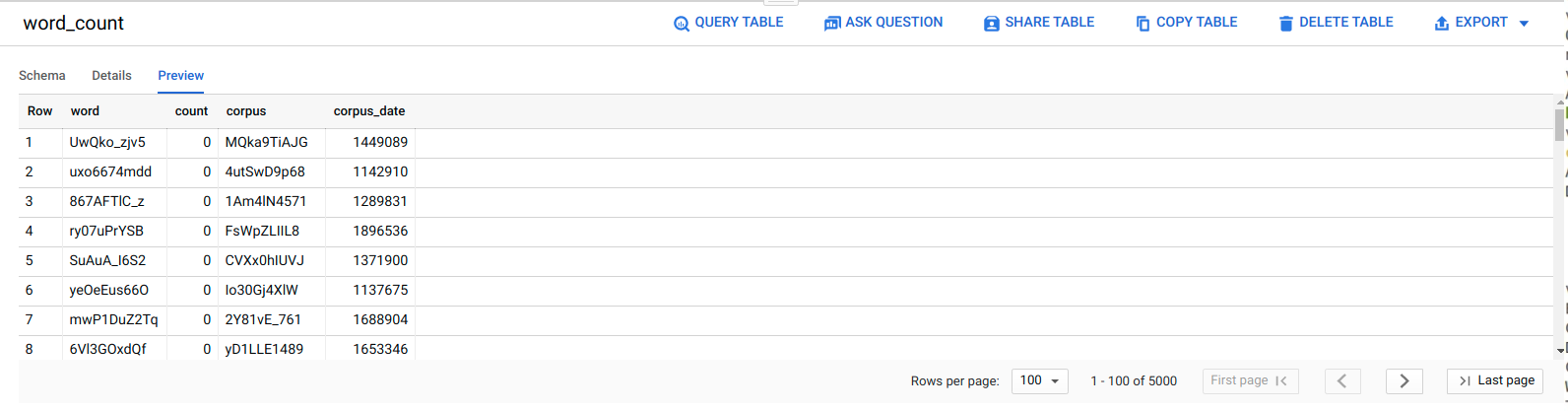
הצגת נתונים ב-BigQuery
כדי לוודא שמשימת ה-ELT בוצעה בהצלחה, בודקים שהנתונים מופיעים בטבלה.
במסוף Google Cloud , עוברים לדף Editor ב-BigQuery.
לוחצים על הטבלה
serverless_elt_dataset.word_count.לוחצים על הכרטיסייה תצוגה מקדימה.
תזמון תהליך העבודה
כדי להפעיל את תהליך העבודה באופן מחזורי לפי לוח זמנים, אפשר להשתמש ב-Cloud Scheduler.
הסרת המשאבים
הדרך הקלה ביותר לבטל את החיוב היא למחוק את Google Cloud הפרויקט שיצרתם בשביל המדריך. אפשר גם למחוק את המשאבים בנפרד.מחיקת המשאבים הבודדים
ב-Cloud Shell, מסירים את כל המשאבים שנוצרו באמצעות Terraform:
cd $HOME/bigquery-workflows-load terraform destroy \ -var project_id=PROJECT_ID \ -var region=REGION \ -var zone=ZONE \ --auto-approve
נכנסים לדף Data של Firestore במסוף Google Cloud .
לצד משרות, לוחצים על תפריט ובוחרים באפשרות מחיקה.
מחיקת הפרויקט
- במסוף Google Cloud , נכנסים לדף Manage resources.
- ברשימת הפרויקטים, בוחרים את הפרויקט שרוצים למחוק ולוחצים על Delete.
- כדי למחוק את הפרויקט, כותבים את מזהה הפרויקט בתיבת הדו-שיח ולוחצים על Shut down.
המאמרים הבאים
- מידע נוסף על BigQuery זמין במאמרי העזרה של BigQuery.
- איך יוצרים צינורות להעברת נתונים של למידת מכונה בהתאמה אישית ללא שרתים
- לדוגמאות נוספות של ארכיטקטורות, תרשימים ושיטות מומלצות, עיינו במאמר Cloud Architecture Center.