
記憶庫可讓您從使用者與代理之間的對話建構長期記憶。本頁說明記憶體生成功能運作方式、如何自訂記憶體擷取方式,以及如何觸發記憶體生成功能。
如要完成本指南中示範的步驟,請先按照「設定記憶體庫」中的步驟操作。
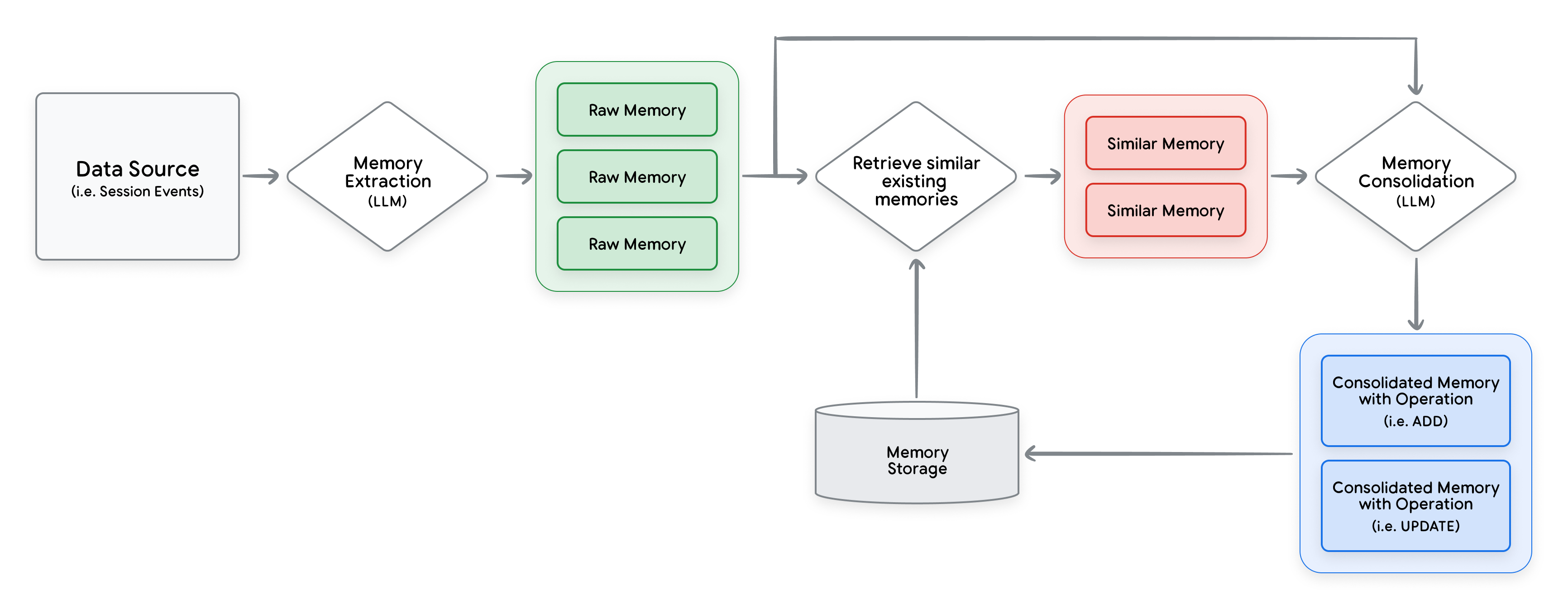
瞭解記憶生成
記憶體庫會從來源資料擷取記憶體,並隨著時間新增、更新及移除記憶體,自行為特定記憶體集合 (由 scope 定義) 策劃記憶體。
觸發記憶生成時,記憶庫會執行下列作業:
擷取:從使用者與服務專員的對話中擷取使用者資訊。系統只會保留符合至少一個執行個體記憶體主題的資訊。
合併:根據擷取的資訊,判斷是否應刪除或更新相同範圍的現有回憶集錦。記憶體庫會先檢查新記憶是否重複或矛盾,再與現有記憶合併。如果現有記憶與新資訊不重疊,系統會建立新記憶。
您可以使用記憶體修訂版本,檢查記憶體生成的中間步驟,並查看記憶體在多個要求中的變化。每個修訂版本都包含每個記憶體生成要求的擷取步驟 (extracted_memories) 和最終合併步驟 (fact) 的中繼輸出內容。
list(client.agent_engines.memories.revisions.list(
name="projects/.../locations/.../reasoningEngines/.../memories/.../revisions/..."))
"""
[
MemoryRevision(
name="projects/123/locations/us-central1/reasoningEngines/456/memories/789/revision/456",
fact="This is my updated fact",
extracted_memories=[
IntermediateExtractedMemory(
fact='This is the output of extraction for a single request.'
),
],
...
),
MemoryRevision(
name="projects/123/locations/us-central1/reasoningEngines/456/memories/789/revision/123",
fact="This is my original fact",
extracted_memories=[
IntermediateExtractedMemory(
fact='This is my original fact.'
),
],
...
)
]
"""
回憶集錦主題
「記憶體主題」會識別記憶體銀行認為有意義的資訊,因此應保留為生成的回憶。記憶體庫支援兩種記憶主題:
受管理的主題:標籤和指示由記憶庫定義。您只需要提供受管理主題的名稱。例如:
字典
memory_topic = { "managed_memory_topic": { "managed_topic_enum": "USER_PERSONAL_INFO" } }以類別為準
from vertexai.types import ManagedTopicEnum from vertexai.types import MemoryBankCustomizationConfigMemoryTopic as MemoryTopic from vertexai.types import MemoryBankCustomizationConfigMemoryTopicManagedMemoryTopic as ManagedMemoryTopic memory_topic = MemoryTopic( managed_memory_topic=ManagedMemoryTopic( managed_topic_enum=ManagedTopicEnum.USER_PERSONAL_INFO ) )自訂主題:設定記憶體庫執行個體時,您可以定義標籤和說明。這些資訊會用於記憶體庫擷取步驟的提示。例如:
字典
memory_topic = { "custom_memory_topic": { "label": "business_feedback", "description": """Specific user feedback about their experience at the coffee shop. This includes opinions on drinks, food, pastries, ambiance, staff friendliness, service speed, cleanliness, and any suggestions for improvement.""" } }以類別為準
from vertexai.types import MemoryBankCustomizationConfigMemoryTopic as MemoryTopic from vertexai.types import MemoryBankCustomizationConfigMemoryTopicCustomMemoryTopic as CustomMemoryTopic memory_topic = MemoryTopic( custom_memory_topic=CustomMemoryTopic( label="business_feedback", description="""Specific user feedback about their experience at the coffee shop. This includes opinions on drinks, food, pastries, ambiance, staff friendliness, service speed, cleanliness, and any suggestions for improvement.""" ) )使用自訂主題時,建議一併提供少量樣本,說明如何從對話中擷取記憶內容。
根據預設,記憶體庫會保留下列所有受管理的主題:
- 個人資訊 (
USER_PERSONAL_INFO):使用者的重要個人資訊,例如姓名、關係、興趣和重要日期。例如「我在 Google 工作」或「我的結婚紀念日是 12 月 31 日」。 - 使用者偏好設定 (
USER_PREFERENCES):明確或隱含的喜好、厭惡、偏好的風格或模式。例如「我比較喜歡中間的座位」。 - 重要對話事件和工作結果 (
KEY_CONVERSATION_DETAILS):對話中的重要里程碑或結論。例如:「我預訂了從 JFK 往返 SFO 的機票。我將於 2025 年 6 月 1 日出發,並於 2025 年 6 月 7 日返回。 - 明確的記憶 / 忘記指令 (
EXPLICIT_INSTRUCTIONS):使用者明確要求代理程式記憶或忘記的資訊。舉例來說,如果使用者說「記住我主要使用 Python」,記憶庫就會產生「我主要使用 Python」這類記憶。
這相當於使用下列一組受管理記憶體主題:
字典
memory_topics = [
{"managed_memory_topic": {"managed_topic_enum": "USER_PERSONAL_INFO"}},
{"managed_memory_topic": {"managed_topic_enum": "USER_PREFERENCES"}},
{"managed_memory_topic": {"managed_topic_enum": "KEY_CONVERSATION_DETAILS"}},
{"managed_memory_topic": {"managed_topic_enum": "EXPLICIT_INSTRUCTIONS"}},
]
以類別為準
from vertexai.types import ManagedTopicEnum
from vertexai.types import MemoryBankCustomizationConfigMemoryTopic as MemoryTopic
from vertexai.types import MemoryBankCustomizationConfigMemoryTopicManagedMemoryTopic as ManagedMemoryTopic
memory_topics = [
MemoryTopic(
managed_memory_topic=ManagedMemoryTopic(
managed_topic_enum=ManagedTopicEnum.USER_PERSONAL_INFO)),
MemoryTopic(
managed_memory_topic=ManagedMemoryTopic(
managed_topic_enum=ManagedTopicEnum.USER_PREFERENCES)),
MemoryTopic(
managed_memory_topic=ManagedMemoryTopic(
managed_topic_enum=ManagedTopicEnum.KEY_CONVERSATION_DETAILS)),
MemoryTopic(
managed_memory_topic=ManagedMemoryTopic(
managed_topic_enum=ManagedTopicEnum.EXPLICIT_INSTRUCTIONS)),
]
如要自訂記憶體庫保留的主題,請在設定記憶體庫時,於自訂設定中設定記憶體主題。
觸發記憶生成
您可以在工作階段結束時或工作階段期間,以固定間隔使用 GenerateMemories 觸發記憶體生成作業。記憶內容生成功能會從來源對話中擷取重要脈絡,並與相同範圍的現有記憶內容合併。舉例來說,您可以使用 {"user_id": "123", "session_id": "456"} 等範圍建立工作階段層級的記憶體。您可以合併相同範圍的記憶內容,並一起擷取。
GenerateMemories 是長時間執行的作業。作業完成後,AgentEngineGenerateMemoriesOperation 會包含產生的回憶集錦清單 (如有):
AgentEngineGenerateMemoriesOperation(
name="projects/.../locations/.../reasoningEngines/.../operations/...",
done=True,
response=GenerateMemoriesResponse(
generatedMemories=[
GenerateMemoriesResponseGeneratedMemory(
memory=Memory(
"name": "projects/.../locations/.../reasoningEngines/.../memories/..."
),
action="CREATED",
),
GenerateMemoriesResponseGeneratedMemory(
memory=Memory(
"name": "projects/.../locations/.../reasoningEngines/.../memories/..."
),
action="UPDATED",
),
GenerateMemoriesResponseGeneratedMemory(
memory=Memory(
"name": "projects/.../locations/.../reasoningEngines/.../memories/..."
),
action="DELETED",
),
]
)
)
每則生成的記憶內容都會顯示對該記憶內容執行的 action:
CREATED:表示新增了回憶,代表現有回憶未涵蓋的新概念。UPDATED:表示現有記憶內容已更新,如果記憶內容涵蓋的概念與新擷取的資訊類似,就會發生這種情況。記憶內容的事實可能會更新為新資訊,也可能維持不變。DELETED:表示系統已刪除現有記憶內容,因為該內容與從對話中擷取的新資訊有矛盾之處。
如果是 CREATED 或 UPDATED 記憶體,可以使用 GetMemories 擷取記憶體的完整內容。擷取 DELETED 記憶體會導致 404 錯誤。
在背景生成回憶集錦
GenerateMemories 是長時間執行的作業。根據預設,client.agent_engines.generate_memories 是封鎖函式,會輪詢作業,直到作業完成為止。如要手動檢查生成的記憶體或通知使用者生成的記憶體,以封鎖作業的形式執行記憶體生成作業會很有幫助。
不過,對於正式版代理程式,您通常會希望在背景以非同步程序執行記憶體生成作業。在大多數情況下,用戶端不需要使用目前執行的輸出內容,因此不必等待回應而產生額外延遲。如要讓記憶體生成作業在背景執行,請將 wait_for_completion 設為 False:
client.agent_engines.memories.generate(
...,
config={
"wait_for_completion": False
}
)
資料來源
你可以透過多種方式提供記憶內容的來源資料:
提供預先擷取的資訊,與相同範圍的現有回憶內容合併。
直接在酬載中提供事件,或使用 Vertex AI Agent Engine 工作階段時,系統會從對話中擷取資訊,並與現有記憶內容合併。如果只想從這些資料來源擷取資訊,可以停用整併功能:
client.agent_engines.memories.generate(
...
config={
"disable_consolidation": True
}
)
使用酬載中的事件做為資料來源
如要使用酬載中直接提供的事件生成回憶集錦,請使用 direct_contents_source。系統會從這些事件中擷取有意義的資訊,並與相同範圍的現有資訊合併。如果您使用的工作階段儲存空間與 Vertex AI Agent Engine Sessions 不同,可以採用這種做法。
字典
事件應包含 Content 字典。
events = [
{
"content": {
"role": "user",
"parts": [
{"text": "I work with LLM agents!"}
]
}
}
]
client.agent_engines.memories.generate(
name=agent_engine.api_resource.name,
direct_contents_source={
"events": EVENTS
},
# For example, `scope={"user_id": "123"}`.
scope=SCOPE,
config={
"wait_for_completion": True
}
)
更改下列內容:
- SCOPE:字典,代表生成回憶的範圍。例如,
{"session_id": "MY_SESSION"}。系統只會合併範圍相同的記憶體。
以類別為準
事件應包含 Content 物件。
from google import genai
import vertexai
events = [
vertexai.types.GenerateMemoriesRequestDirectContentsSourceEvent(
content=genai.types.Content(
role="user",
parts=[
genai.types.Part.from_text(text="I work with LLM agents!")
]
)
)
]
client.agent_engines.memories.generate(
name=agent_engine.api_resource.name,
direct_contents_source={
"events": events
},
# For example, `scope={"user_id": "123"}`.
scope=SCOPE,
config={
"wait_for_completion": True
}
)
更改下列內容:
- SCOPE:字典,代表生成回憶的範圍。例如,
{"session_id": "MY_SESSION"}。系統只會合併範圍相同的記憶體。
使用 Vertex AI Agent Engine 工作階段做為資料來源
透過 Agent Engine Sessions,Memory Bank 會使用工作階段事件做為記憶體生成的來源對話。
如要設定生成記憶體的範圍,記憶體庫預設會從工作階段中擷取並使用使用者 ID。舉例來說,如果工作階段的 user_id 是「123」,記憶體的範圍就會儲存為 {"user_id": "123"}。您也可以直接提供 scope,這會覆寫使用工作階段的 user_id 做為範圍。
字典
client.agent_engines.memories.generate(
name=agent_engine.api_resource.name,
vertex_session_source={
# For example, projects/.../locations/.../reasoningEngines/.../sessions/...
"session": "SESSION_NAME"
},
# Optional when using Agent Engine Sessions. Defaults to {"user_id": session.user_id}.
scope=SCOPE,
config={
"wait_for_completion": True
}
)
更改下列內容:
SESSION_NAME:完整工作階段名稱。
(選用) SCOPE:字典,代表所產生回憶的範圍。例如,
{"session_id": "MY_SESSION"}。系統只會合併範圍相同的記憶體。如未提供,則會使用{"user_id": session.user_id}。
以類別為準
client.agent_engines.memories.generate(
name=agent_engine.api_resource.name,
vertex_session_source=vertexai.types.GenerateMemoriesRequestVertexSessionSource(
# For example, projects/.../locations/.../reasoningEngines/.../sessions/...
session="SESSION_NAME"
),
# Optional when using Agent Engine Sessions. Defaults to {"user_id": session.user_id}.
scope=SCOPE,
config={
"wait_for_completion": True
}
)
此外,您也可以視需要提供時間範圍,指出應納入工作階段的事件。如未提供,系統會納入工作階段中的所有事件。
字典
import datetime
client.agent_engines.memories.generate(
name=agent_engine.api_resource.name,
vertex_session_source={
"session": "SESSION_NAME",
# Extract memories from the last hour of events.
"start_time": datetime.datetime.now(tz=datetime.timezone.utc) - datetime.timedelta(seconds=24 * 60),
"end_time": datetime.datetime.now(tz=datetime.timezone.utc)
},
scope=SCOPE
)
以類別為準
import datetime
client.agent_engines.memories.generate(
name=agent_engine.api_resource.name,
vertex_session_source=vertexai.types.GenerateMemoriesRequestVertexSessionSource(
session="SESSION_NAME",
# Extract memories from the last hour of events.
start_time=datetime.datetime.now(tz=datetime.timezone.utc) - datetime.timedelta(seconds=24 * 60),
end_time=datetime.datetime.now(tz=datetime.timezone.utc)
),
scope=SCOPE
)
整合預先擷取的記憶
除了使用記憶體庫的自動擷取程序,您也可以直接提供預先擷取的記憶內容。直接來源回憶集錦會與相同範圍的現有回憶集錦合併。這項功能非常實用,因為您可讓專員或參與迴圈的人員負責擷取記憶內容,同時利用記憶庫的整合功能,確保沒有重複或矛盾的記憶內容。
client.agent_engines.memories.generate(
name=agent_engine.api_resource.name,
direct_memories_source={"direct_memories": [{"fact": "FACT"}]},
scope=SCOPE
)
更改下列內容:
FACT:應與現有記憶內容合併的預先擷取事實。您最多可以在清單中提供 5 個預先擷取的資訊,如下所示:
{"direct_memories": [{"fact": "fact 1"}, {"fact": "fact 2"}]}SCOPE:字典,代表生成回憶的範圍。例如,
{"session_id": "MY_SESSION"}。系統只會合併範圍相同的記憶體。
使用多模態輸入內容
你可以從多模態輸入內容中擷取記憶內容。不過,記憶只會從來源內容中的文字、內嵌檔案和檔案資料擷取。生成回憶集錦時,系統會忽略所有其他內容,包括函式呼叫和回應。
系統會從使用者提供的圖片、影片和音訊中擷取記憶。如果記憶庫判斷多模態輸入提供的脈絡對日後互動有意義,系統可能會建立文字記憶,當中包含從輸入內容擷取的資訊。舉例來說,如果使用者提供黃金獵犬的圖片,並附上「這是我的狗」的文字,記憶庫就會生成「我的狗是黃金獵犬」等記憶。
舉例來說,您可以在酬載中提供圖片和圖片情境:
字典
with open(file_name, "rb") as f:
inline_data = f.read()
events = [
{
"content": {
"role": "user",
"parts": [
{"text": "This is my dog"},
{
"inline_data": {
"mime_type": "image/jpeg",
"data": inline_data
}
},
{
"file_data": {
"file_uri": "gs://cloud-samples-data/generative-ai/image/dog.jpg",
"mime_type": "image/jpeg"
}
},
]
}
}
]
以類別為準
from google import genai
import vertexai
with open(file_name, "rb") as f:
inline_data = f.read()
events = [
vertexai.types.GenerateMemoriesRequestDirectContentsSourceEvent(
content=genai.types.Content(
role="user",
parts=[
genai.types.Part.from_text(text="This is my dog"),
genai.types.Part.from_bytes(
data=inline_data,
mime_type="image/jpeg",
),
genai.types.Part.from_uri(
file_uri="gs://cloud-samples-data/generative-ai/image/dog.jpg",
mime_type="image/jpeg",
)
]
)
)
]
使用 Vertex AI Agent Engine Sessions 做為資料來源時,多模態內容會直接在 Session 的事件中提供。