
Les clusters Ray sur Vertex AI offrent deux options de scaling : l'autoscaling et le scaling manuel. L'autoscaling permet au cluster d'ajuster automatiquement le nombre de nœuds de calcul en fonction des ressources requises par les tâches et les acteurs Ray. Si vous exécutez une charge de travail importante et que vous n'êtes pas sûr des ressources nécessaires, l'autoscaling est recommandé. Le scaling manuel permet aux utilisateurs de contrôler plus précisément les nœuds.
L'autoscaling peut réduire les coûts liés à la charge de travail, mais ajoute des frais généraux de lancement de nœuds et peut être difficile à configurer. Si vous débutez avec Ray, commencez par des clusters sans autoscaling et utilisez la fonctionnalité de scaling manuel.
Autoscaling
Activez la fonctionnalité d'autoscaling d'un cluster Ray en spécifiant le nombre minimal de réplicas (min_replica_count) et le nombre maximal de réplicas (max_replica_count) d'un pool de nœuds de calcul.
Veuillez noter les points suivants :
- Configurez la spécification d'autoscaling de tous les pools de nœuds de calcul.
- La vitesse d'upscaling et de downscaling personnalisée n'est pas prise en charge. Pour connaître les valeurs par défaut, consultez la section Vitesse d'upscaling et de downscaling dans la documentation de Ray.
Définir la spécification d'autoscaling du pool de nœuds de calcul
Utilisez la console Google Cloud ou le SDK Vertex AI pour Python pour activer la fonctionnalité d'autoscaling d'un cluster Ray.
SDK Ray sur Vertex AI
from google.cloud import aiplatform import vertex_ray from vertex_ray import AutoscalingSpec autoscaling_spec = AutoscalingSpec( min_replica_count=1, max_replica_count=3, ) head_node_type = Resources( machine_type="n1-standard-16", node_count=1, ) worker_node_types = [Resources( machine_type="n1-standard-16", accelerator_type="NVIDIA_TESLA_T4", accelerator_count=1, autoscaling_spec=autoscaling_spec, )] # Create the Ray cluster on Vertex AI CLUSTER_RESOURCE_NAME = vertex_ray.create_ray_cluster( head_node_type=head_node_type, worker_node_types=worker_node_types, ... )
Console
Conformément aux bonnes pratiques OSS Ray, le nombre de processeurs logiques est défini sur 0 sur le nœud principal de Ray afin d'éviter toute exécution de charge de travail sur ce nœud.
Dans la console Google Cloud , accédez à la page "Ray sur Vertex AI".
Cliquez sur Créer un cluster pour ouvrir le panneau Créer un cluster.
Pour chaque étape du panneau Créer un cluster, vérifiez ou remplacez les informations du cluster par défaut. Cliquez sur Continuer à chaque étape :
- Dans le champ Nom et région, spécifiez un Nom et choisissez un emplacement pour votre cluster.
Pour les paramètres de calcul, spécifiez la configuration du cluster Ray sur le nœud principal, y compris le type de machine, le type et le nombre d'accélérateurs, le type et la taille du disque, et le nombre d'instances répliquées. Vous pouvez éventuellement ajouter un URI d'image personnalisée pour spécifier une image de conteneur personnalisé afin d'ajouter des dépendances Python non fournies par l'image de conteneur par défaut. Consultez Image personnalisée.
Sous Options avancées, vous pouvez :
- Spécifier votre propre clé de chiffrement.
- Spécifiez un compte de service personnalisé.
- Si vous n'avez pas besoin de surveiller les statistiques de ressources de votre charge de travail pendant l'entraînement, désactivez la collecte de métriques.
Pour créer un cluster avec un pool de nœuds de calcul à autoscaling, indiquez une valeur pour le nombre maximal d'instances répliquées du pool de nœuds de calcul.
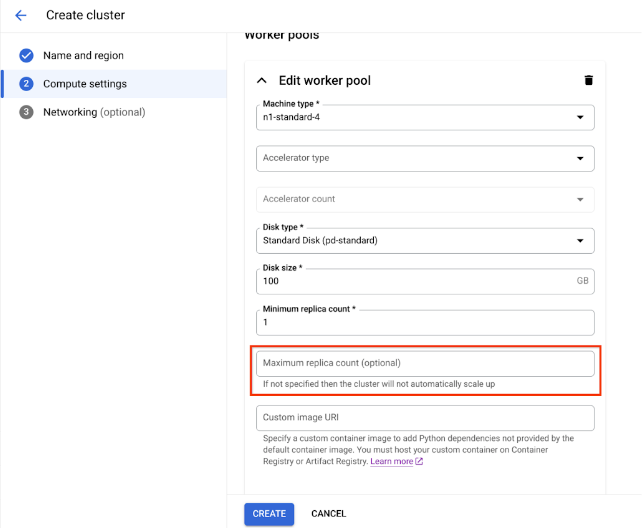
Cliquez sur Créer.
Scaling manuel
Lorsque vos charges de travail augmentent ou diminuent sur vos clusters Ray sur Vertex AI, ajustez manuellement le nombre d'instances répliquées pour répondre à la demande. Par exemple, si vous disposez d'une capacité excédentaire, réduisez la taille de vos pools de nœuds de calcul pour réduire les coûts.
Limites de l'appairage de VPC
Lorsque vous mettez à l'échelle des clusters, vous ne pouvez modifier que le nombre de répliques dans vos pools de nœuds de calcul existants. Par exemple, vous ne pouvez pas ajouter ni supprimer de pools de nœuds de calcul dans votre cluster, ni modifier le type de machine de vos pools de nœuds de calcul. De plus, le nombre de répliques de vos pools de nœuds de calcul ne peut pas être inférieur à un.
Si vous utilisez une connexion d'appairage de VPC pour vous connecter à vos clusters, le nombre maximal de nœuds est limité. Le nombre maximal de nœuds dépend du nombre de nœuds que le cluster comportait lors de sa création. Pour en savoir plus, consultez Calcul du nombre maximal de nœuds. Ce nombre maximal inclut non seulement vos pools de nœuds de calcul, mais aussi votre nœud principal. Si vous utilisez la configuration réseau par défaut, le nombre de nœuds ne peut pas dépasser les limites supérieures décrites dans la documentation sur la création de clusters.
Bonnes pratiques pour l'allocation de sous-réseaux
Lorsque vous déployez Ray sur Vertex AI à l'aide de l'accès aux services privés (PSA), il est essentiel de vous assurer que la plage d'adresses IP allouée est suffisamment grande et contiguë pour accueillir le nombre maximal de nœuds que votre cluster peut atteindre. L'épuisement des adresses IP peut se produire si la plage d'adresses IP réservée à votre connexion PSA est trop petite ou fragmentée, ce qui entraîne des échecs de déploiement.
Nous vous recommandons également de déployer Ray sur Vertex AI avec une interface Private Service Connect, qui réduit la consommation d'adresses IP à un sous-réseau /28.
Surveillance de l'accès privé aux services
Nous vous recommandons d'utiliser Network Analyzer, un outil de diagnostic du Network Intelligence Center de Google Cloud qui surveille automatiquement les configurations de votre réseau de cloud privé virtuel (VPC) pour détecter les erreurs de configuration et les paramètres non optimaux. Network Analyzer fonctionne en continu. Il exécute des tests de manière proactive et génère des insights pour vous aider à identifier, diagnostiquer et résoudre les problèmes réseau avant qu'ils n'affectent la disponibilité des services.
Network Analyzer peut surveiller les sous-réseaux utilisés pour l'accès privé aux services (PSA, Private Service Access) et fournit des informations spécifiques à leur sujet. Il s'agit d'une fonction essentielle pour gérer les services tels que Cloud SQL, Memorystore et Vertex AI, qui utilisent le PSA.
L'analyseur de réseaux surveille principalement les sous-réseaux PSA en fournissant des insights sur l'utilisation des adresses IP pour les plages allouées.
Utilisation de la plage PSA : Network Analyzer suit activement le pourcentage d'adresses IP attribuées dans les blocs CIDR dédiés que vous avez alloués pour PSA. C'est important, car lorsque vous créez un service géré (tel que Vertex AI), Google crée un VPC de producteur de services et un sous-réseau dans celui-ci, en tirant une plage d'adresses IP de votre bloc alloué.
Alertes proactives : si l'utilisation des adresses IP pour une plage allouée à un PSA dépasse un certain seuil (75 %, par exemple), l'analyseur réseau génère un insight d'avertissement. Vous êtes ainsi alerté de manière proactive des éventuels problèmes de capacité, ce qui vous laisse le temps d'étendre la plage d'adresses IP allouée avant de manquer d'adresses disponibles pour les nouvelles ressources de service.
Mises à jour des sous-réseaux d'accès aux services privés
Pour les déploiements Ray sur Vertex AI, Google recommande d'allouer un bloc CIDR /16 ou /17 pour votre connexion PSA. Cela fournit un bloc contigu d'adresses IP suffisamment grand pour permettre une mise à l'échelle importante, avec respectivement jusqu'à 65 536 ou 32 768 adresses IP uniques. Cela permet d'éviter l'épuisement des adresses IP, même avec de grands clusters Ray.
Si vous épuisez votre espace d'adresses IP alloué, Google Cloud renvoie l'erreur suivante :
Échec de la création du sous-réseau. Impossible de trouver des blocs libres dans les plages d'adresses IP allouées.
Nous vous recommandons d'étendre la plage de sous-réseaux actuelle ou d'allouer une plage qui tient compte de la croissance future.
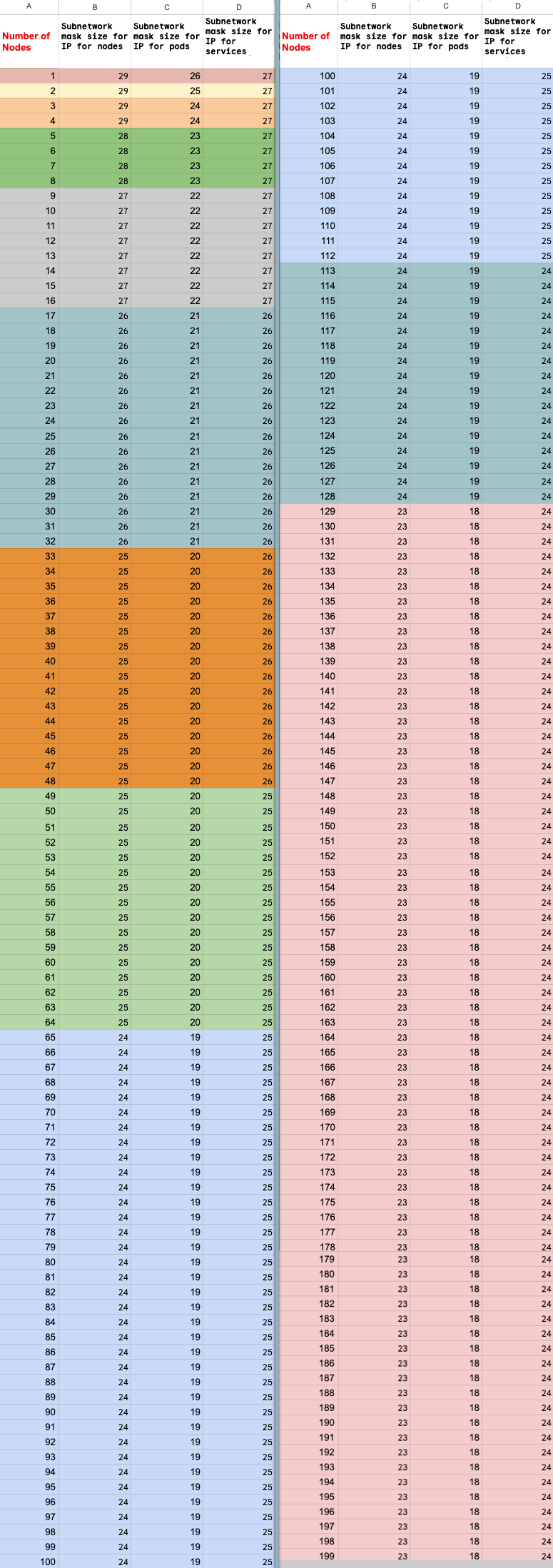
Calcul du nombre maximal de nœuds
Si vous utilisez l'accès aux services privés (appairage VPC) pour vous connecter à vos nœuds, utilisez les formules suivantes pour vérifier que vous ne dépassez pas le nombre maximal de nœuds (M), en supposant f(x) = min(29, (32 -
ceiling(log2(x))) :
f(2 * M) = f(2 * N)f(64 * M) = f(64 * N)f(max(32, 16 + M)) = f(max(32, 16 + N))
Le nombre total maximal de nœuds dans le cluster Ray sur Vertex AI que vous pouvez faire évoluer (M) dépend du nombre total initial de nœuds que vous avez configurés (N). Après avoir créé le cluster Ray sur Vertex AI, vous pouvez adapter le nombre total de nœuds à une valeur comprise entre P et M inclus, où P correspond au nombre de pools de votre cluster.
Le nombre total initial de nœuds dans le cluster et le nombre cible de scaling à la hausse doivent se trouver dans le même bloc de couleur.
Mettre à jour le nombre d'instances répliquées
Utilisez la console Google Cloud ou le SDK Vertex AI pour Python pour mettre à jour le nombre d'instances dupliquées de votre pool de nœuds de calcul. Si votre cluster comprend plusieurs pools de nœuds de calcul, vous pouvez modifier individuellement le nombre d'instances répliquées de chacun d'eux dans une seule requête.
SDK Ray sur Vertex AI
import vertexai import vertex_ray vertexai.init() cluster = vertex_ray.get_ray_cluster("CLUSTER_NAME") # Get the resource name. cluster_resource_name = cluster.cluster_resource_name # Create the new worker pools new_worker_node_types = [] for worker_node_type in cluster.worker_node_types: worker_node_type.node_count = REPLICA_COUNT # new worker pool size new_worker_node_types.append(worker_node_type) # Make update call updated_cluster_resource_name = vertex_ray.update_ray_cluster( cluster_resource_name=cluster_resource_name, worker_node_types=new_worker_node_types, )
Console
Dans la console Google Cloud , accédez à la page "Ray sur Vertex AI".
Dans la liste des clusters, cliquez sur celui que vous souhaitez modifier.
Sur la page Détails du cluster, cliquez sur Modifier le cluster.
Dans le volet Modifier le cluster, sélectionnez le pool de nœuds de calcul à mettre à jour, puis modifiez le nombre d'instances dupliquées.
Cliquez sur Mettre à jour.
Patientez quelques minutes pendant la mise à jour de votre cluster. Une fois la mise à jour terminée, vous pouvez consulter le nombre d'instances répliquées mis à jour sur la page Détails du cluster.
Cliquez sur Créer.