
Ray est un framework Open Source qui permet de faire évoluer des applications d'IA et Python. Ray fournit l'infrastructure nécessaire pour les opérations de calculs distribuées et de traitement en parallèle pour votre workflow de machine learning (ML).
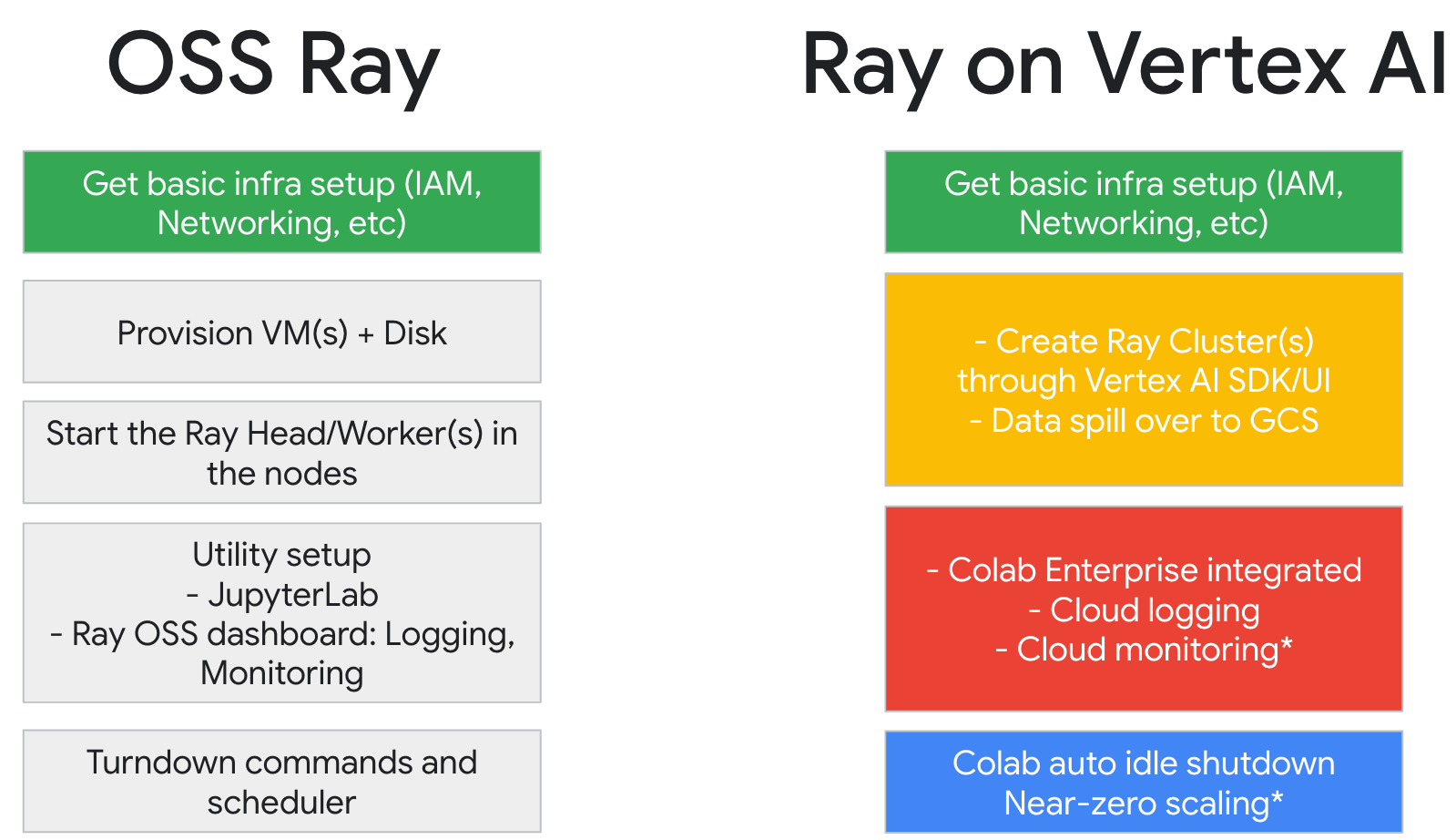
Si vous utilisez déjà Ray, vous pouvez vous servir du même code Ray Open Source pour écrire des programmes et développer des applications sur Vertex AI avec un minimum de modifications. Vous pouvez ensuite utiliser les intégrations de Vertex AI avec d'autres services Google Cloud, tels que Vertex AI Inference et BigQuery, dans votre workflow de machine learning.
Si vous utilisez déjà Vertex AI et que vous avez besoin d'un moyen plus simple de gérer les ressources de calcul, vous pouvez utiliser le code Ray pour faire évoluer l'entraînement.
Workflow d'utilisation de Ray sur Vertex AI
Utilisez Colab Enterprise et le SDK Vertex AI pour Python pour vous connecter au cluster Ray.
| Étapes | Description |
|---|---|
| 1. Configurez Ray sur Vertex AI. | Configurez votre projet Google, installez la version du SDK Vertex AI pour Python qui inclut les fonctionnalités du client Ray, puis configurez un réseau d'appairage de VPC, ce qui est facultatif. |
| 2. Créer un cluster Ray sur Vertex AI | Créez un cluster Ray sur Vertex AI. Le rôle Administrateur Vertex AI est requis. |
| 3. Développer une application Ray sur Vertex AI | Connectez-vous à un cluster Ray sur Vertex AI et développez une application. Le rôle Utilisateur Vertex AI est requis. |
| 4. (Facultatif) Utiliser Ray sur Vertex AI avec BigQuery | Lisez, écrivez et transformez des données avec BigQuery |
| 5. (Facultatif) Déployer un modèle sur Vertex AI et obtenir des inférences | Déployez un modèle sur un point de terminaison en ligne Vertex AI et obtenez des inférences. |
| 6. Surveiller votre cluster Ray sur Vertex AI | Surveillez les journaux générés dans Cloud Logging et les métriques dans Cloud Monitoring. |
| 7. Supprimer un cluster Ray sur Vertex AI | Supprimez un cluster Ray sur Vertex AI pour éviter que des frais ne vous soient facturés. |
Présentation
Les clusters Ray sont intégrés pour garantir la disponibilité de la capacité pour les charges de travail de ML critiques ou pendant les périodes de pics. Contrairement aux tâches personnalisées, où le service d'entraînement libère la ressource une fois la tâche terminée, les clusters Ray restent disponibles jusqu'à leur suppression.
Remarque : Utilisez des clusters Ray de longue durée dans les scénarios suivants :
- Si vous envoyez le même job Ray plusieurs fois, vous pouvez bénéficier de la mise en cache des données et des images en exécutant les jobs sur le même cluster Ray de longue durée.
- Si vous exécutez de nombreux jobs Ray de courte durée dans lesquels le temps de traitement réel est plus court que temps de démarrage des jobs, il peut être intéressant de disposer d'un cluster de longue durée.
Les clusters Ray sur Vertex AI peuvent être configurés avec une connectivité publique ou privée. Les schémas suivants présentent l'architecture et le workflow de Ray sur Vertex AI. Pour en savoir plus, consultez Connectivité publique ou privée.
Architecture avec connectivité publique
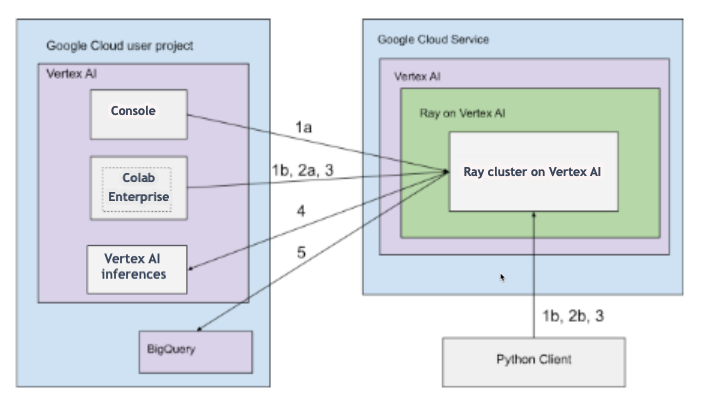
Créez le cluster Ray sur Vertex AI à l'aide des options suivantes :
a. Utilisez la console Google Cloud pour créer le cluster Ray sur Vertex AI.
b. Créez le cluster Ray sur Vertex AI à l'aide du SDK Vertex AI pour Python.
Connectez-vous au cluster Ray sur Vertex AI pour le développement interactif à l'aide des options suivantes :
a. Utilisez Colab Enterprise dans la console Google Cloud pour une connexion fluide.
b. Utilisez n'importe quel environnement Python accessible sur l'Internet public.
Développez votre application et entraînez votre modèle sur le cluster Ray sur Vertex AI :
Utilisez le SDK Vertex AI pour Python dans l'environnement de votre choix (notebook Colab Enterprise ou Python).
Écrivez un script Python à l'aide de l'environnement de votre choix.
Envoyez un job Ray au cluster Ray sur Vertex AI à l'aide du SDK Vertex AI pour Python, de la CLI Ray Job ou de l'API Ray Job Submission.
Déployez le modèle entraîné sur un point de terminaison Vertex AI en ligne pour l'inférence en direct.
Utilisez BigQuery pour gérer vos données.
Architecture avec VPC
Le schéma suivant présente l'architecture et le workflow de Ray sur Vertex AI après la configuration de votre projet Google Cloud et de votre réseau VPC, ce qui est facultatif :
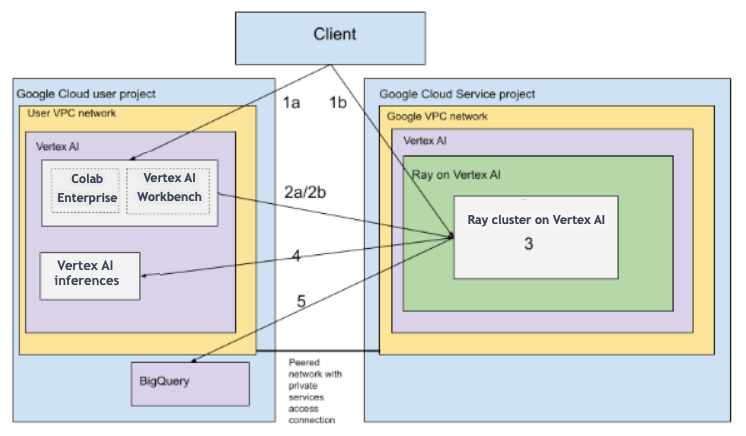
Configurez votre (a) projet Google et votre (b) réseau VPC.
Créez le cluster Ray sur Vertex AI à l'aide des options suivantes :
a. Utilisez la console Google Cloud pour créer le cluster Ray sur Vertex AI.
b. Créez le cluster Ray sur Vertex AI à l'aide du SDK Vertex AI pour Python.
Connectez-vous au cluster Ray sur Vertex AI via un réseau VPC appairé à l'aide des options suivantes :
Utilisez Colab Enterprise dans la consoleGoogle Cloud .
Utilisez un notebook Vertex AI Workbench.
Développez votre application et entraînez votre modèle sur le cluster Ray sur Vertex AI à l'aide des options suivantes :
Utilisez le SDK Vertex AI pour Python dans l'environnement de votre choix (notebook Colab Enterprise ou Vertex AI Workbench).
Écrivez un script Python à l'aide de l'environnement de votre choix. Envoyez un job Ray au cluster Ray sur Vertex AI à l'aide du SDK Vertex AI pour Python, de la CLI du job Ray ou du tableau de bord Ray.
Déployez le modèle entraîné sur un point de terminaison Vertex AI en ligne pour les inférences.
Utilisez BigQuery pour gérer vos données.
Terminologie
Pour obtenir la liste complète des termes, consultez le glossaire Vertex AI pour l'IA prédictive.
-
autoscaling
- L'autoscaling est la capacité d'une ressource de calcul, comme le pool de nœuds de calcul d'un cluster Ray, à ajuster automatiquement le nombre de nœuds à la hausse ou à la baisse en fonction des exigences de la charge de travail, ce qui permet d'optimiser l'utilisation des ressources et les coûts. Pour en savoir plus, consultez Mettre à l'échelle les clusters Ray sur Vertex AI : autoscaling.
-
inférence par lot
- L'inférence par lot extrait un groupe de requêtes d'inférence et génère les résultats dans un fichier. Pour en savoir plus, consultez la Présentation de l'obtention d'inférences sur Vertex AI.
-
BigQuery
- BigQuery est un entrepôt de données d'entreprise sans serveur, entièrement géré et hautement évolutif fourni par Google Cloud. Il est conçu pour analyser de vastes ensembles de données à l'aide de requêtes SQL à des vitesses incroyablement élevées. BigQuery permet de bénéficier d'une informatique décisionnelle et d'analyses puissantes sans que les utilisateurs aient à gérer d'infrastructure. Pour en savoir plus, consultez D'un entrepôt de données à une plate-forme de données et d'IA autonome.
-
Cloud Logging
- Cloud Logging est un service de journalisation en temps réel entièrement géré fourni par Google Cloud. Il vous permet de collecter, de stocker, d'analyser et de surveiller les journaux de toutes vos ressources Google Cloud, de vos applications sur site et même de vos sources personnalisées. Cloud Logging centralise la gestion des journaux, ce qui facilite le dépannage, l'audit et la compréhension du comportement et de l'état de vos applications et de votre infrastructure. Pour en savoir plus, consultez la présentation de Cloud Logging.
-
Colab Enterprise
- Colab Enterprise est un environnement de notebook Jupyter géré et collaboratif qui apporte l'expérience utilisateur populaire de Google Colab à Google Cloud, en offrant des fonctionnalités de sécurité et de conformité de niveau entreprise. Colab Enterprise offre une expérience sans configuration axée sur les notebooks, avec des ressources de calcul gérées par Vertex AI, et s'intègre à d'autres services Google Cloud tels que BigQuery. Pour en savoir plus, consultez la présentation de Colab Enterprise.
-
Image de conteneur personnalisé
- Une image de conteneur personnalisée est un package exécutable autonome qui inclut le code d'application de l'utilisateur, son environnement d'exécution, ses bibliothèques, ses dépendances et la configuration de son environnement. Dans le contexte de Google Cloud, en particulier Vertex AI, il permet à l'utilisateur d'empaqueter son code d'entraînement de machine learning ou son application de diffusion avec ses dépendances exactes, ce qui garantit la reproductibilité et lui permet d'exécuter une charge de travail sur des services gérés à l'aide de versions logicielles spécifiques ou de configurations uniques non fournies par les environnements standards. Pour en savoir plus, consultez Exigences concernant les conteneurs personnalisés pour l'inférence.
-
point de terminaison
- Ressources sur lesquelles vous pouvez déployer des modèles entraînés pour diffuser des inférences. Pour en savoir plus, consultez Choisir un type de point de terminaison.
-
Autorisations IAM (Identity and Access Management)
- Les autorisations Identity and Access Management (IAM) sont des fonctionnalités précises qui définissent qui peut faire quoi sur quelles ressources Google Cloud. Ils sont attribués à des comptes principaux (comme des utilisateurs, des groupes ou des comptes de service) par le biais de rôles, ce qui permet de contrôler précisément l'accès aux services et aux données dans un projet ou une organisation Google Cloud. Pour en savoir plus, consultez la page Contrôle des accès avec IAM.
-
inference
- Dans le contexte de la plate-forme Vertex AI, l'inférence fait référence au processus d'exécution de points de données dans un modèle de machine learning pour calculer une sortie, telle qu'un score numérique unique. Ce processus est également appelé "opérationnalisation d'un modèle de machine learning" ou "mise en production d'un modèle de machine learning". L'inférence est une étape importante du workflow de machine learning, car elle permet aux modèles d'être utilisés pour faire des inférences sur de nouvelles données. Dans Vertex AI, l'inférence peut être effectuée de différentes manières, y compris l'inférence par lot et l'inférence en ligne. L'inférence par lot consiste à exécuter un groupe de requêtes d'inférence et à générer les résultats dans un fichier, tandis que l'inférence en ligne permet d'effectuer des inférences en temps réel sur des points de données individuels.
-
Network File System (NFS)
- Système client/serveur qui permet aux utilisateurs d'accéder à des fichiers sur un réseau et de les traiter comme s'ils se trouvaient dans un répertoire de fichiers local. Pour en savoir plus, consultez Monter un partage Network File System.
-
Inférence en ligne
- Obtenir des inférences sur des instances individuelles de manière synchrone. Pour en savoir plus, consultez Inférence en ligne.
-
Ressource persistante
- Type de ressource de calcul Vertex AI, tel qu'un cluster Ray, qui reste alloué et disponible jusqu'à ce qu'il soit explicitement supprimé. Cela est utile pour le développement itératif et réduit les frais généraux de démarrage entre les jobs. Pour en savoir plus, consultez Obtenir des informations sur une ressource persistante.
-
pipeline
- Les pipelines de ML sont des workflows de ML portables et évolutifs basés sur des conteneurs. Pour en savoir plus, consultez la Présentation de Vertex AI Pipelines.
-
Conteneur prédéfini
- Images de conteneurs fournies par Vertex AI, préinstallées avec des frameworks et des dépendances de ML courants, ce qui simplifie la configuration des jobs d'entraînement et d'inférence. Pour en savoir plus, consultez Conteneurs prédéfinis pour l'entraînement sans serveur .
-
Private Service Connect (PSC)
- Private Service Connect est une technologie qui permet aux clients Compute Engine de mapper des adresses IP privées de leur réseau à un autre réseau VPC ou à des API Google. Pour en savoir plus, consultez Private Service Connect.
-
Cluster Ray sur Vertex AI
- Un cluster Ray sur Vertex AI est un cluster géré de nœuds de calcul qui peut être utilisé pour exécuter des applications Python et de machine learning (ML) distribuées. Il fournit l'infrastructure nécessaire pour les opérations de calculs distribuées et de traitement en parallèle pour votre workflow de ML. Les clusters Ray sont intégrés à Vertex AI pour garantir la disponibilité de la capacité pour les charges de travail de ML critiques ou pendant les périodes de pics. Contrairement aux tâches personnalisées, où le service d'entraînement libère la ressource une fois la tâche terminée, les clusters Ray restent disponibles jusqu'à leur suppression. Pour en savoir plus, consultez la présentation de Ray sur Vertex AI.
-
Ray sur Vertex AI (RoV)
- Ray sur Vertex AI est conçu pour vous permettre d'utiliser le même code Ray Open Source pour écrire des programmes et développer des applications sur Vertex AI avec un minimum de modifications. Pour en savoir plus, consultez la présentation de Ray sur Vertex AI.
-
SDK Ray sur Vertex AI pour Python
- Le SDK Ray sur Vertex AI pour Python est une version du SDK Vertex AI pour Python qui inclut les fonctionnalités du client Ray, du connecteur BigQuery pour Ray, de la gestion des clusters Ray sur Vertex AI et des inférences sur Vertex AI. Pour en savoir plus, consultez Présentation du SDK Vertex AI pour Python.
-
SDK Ray sur Vertex AI pour Python
- Le SDK Ray sur Vertex AI pour Python est une version du SDK Vertex AI pour Python qui inclut les fonctionnalités du client Ray, du connecteur BigQuery pour Ray, de la gestion des clusters Ray sur Vertex AI et des inférences sur Vertex AI. Pour en savoir plus, consultez Présentation du SDK Vertex AI pour Python.
-
compte de service
- Les comptes de service sont des comptes Google Cloud spéciaux utilisés par les applications ou les machines virtuelles pour effectuer des appels d'API autorisés aux services Google Cloud. Contrairement aux comptes utilisateur, ils ne sont pas liés à une personne physique, mais servent d'identité à votre code, ce qui permet d'accéder aux ressources de manière sécurisée et programmatique sans nécessiter d'identifiants humains. Pour en savoir plus, consultez la présentation des comptes de service.
-
Vertex AI Workbench
- Vertex AI Workbench est un environnement de développement unifié basé sur des notebooks Jupyter. Il prend en charge l'ensemble du workflow de data science, de l'exploration et de l'analyse des données au développement, à l'entraînement et au déploiement de modèles. Vertex AI Workbench fournit une infrastructure gérée et évolutive avec des intégrations intégrées à d'autres services Google Cloud tels que BigQuery et Cloud Storage. Les data scientists peuvent ainsi effectuer efficacement leurs tâches de machine learning sans avoir à gérer l'infrastructure sous-jacente. Pour en savoir plus, consultez la présentation de Vertex AI Workbench.
-
Nœud de calcul
- Un nœud de calcul fait référence à une machine ou une instance de calcul individuelle au sein d'un cluster, qui est responsable de l'exécution des tâches ou du travail. Dans les systèmes tels que les clusters Kubernetes ou Ray, les nœuds sont les unités de calcul fondamentales. Pour en savoir plus, consultez Qu'est-ce que le calcul hautes performances (HPC) ?.
-
Pool de nœuds de calcul
- Composants d'un cluster Ray qui exécutent des tâches distribuées. Les pools de nœuds de calcul peuvent être configurés avec des types de machines spécifiques et sont compatibles avec l'autoscaling et le scaling manuel. Pour en savoir plus, consultez Structure du cluster d'entraînement.
Tarifs
Les tarifs de Ray sur Vertex AI sont calculés comme suit :
Les ressources de calcul que vous utilisez sont facturées en fonction de la configuration de machine que vous sélectionnez lors de la création de votre cluster Ray sur Vertex AI. Pour connaître les tarifs de Ray sur Vertex AI, consultez la page des tarifs.
En ce qui concerne les clusters Ray, vous n'êtes facturé que lorsqu'ils sont à l'état "RUNNING" (EN COURS D'EXÉCUTION) ou "UPDATING" (EN COURS DE MISE À JOUR). Aucun autre État n'est concerné. Le montant facturé est basé sur la taille réelle du cluster au moment de la facturation.
Lorsque vous effectuez des tâches à l'aide du cluster Ray sur Vertex AI, les journaux sont automatiquement générés et facturés en fonction des tarifs de Cloud Logging.
Si vous déployez votre modèle sur un point de terminaison pour les inférences en ligne, consultez la section Prédiction et explications de la page"Tarifs de Vertex AI".
Si vous utilisez BigQuery avec Ray sur Vertex AI, consultez les tarifs de BigQuery.