
TPU v5p
Questo documento descrive l'architettura e le configurazioni supportate di Cloud TPU v5p.
Architettura di sistema
Questa sezione descrive l'architettura del sistema specifica della versione v5p. Ogni Tensor Core ha quattro unità di moltiplicazione a matrice (MXU), un'unità vettoriale e un'unità scalare.
Un pod v5p contiene 8960 chip. Il job più grande che può essere pianificato è un job di 96 cubi (6144 chip).
La tabella seguente mostra le specifiche chiave della TPU v5p.
| Specifica | Valori |
|---|---|
| Numero di chip per pod | 8960 |
| Picco di calcolo per chip (BF16) (TFLOP) | 459 |
| Picco di calcolo per chip (FP8) (TFLOP) | 459 |
| Capacità HBM per chip (GiB) | 95 |
| Larghezza di banda HBM per chip (GBps) | 2765 |
| Numero di vCPU (VM a 4 chip) | 208 |
| RAM (GB) (VM a 4 chip) | 448 |
| Numero di Tensor Core per chip | 2 |
| Numero di SparseCore per chip | 4 |
| Larghezza di banda bidirezionale di interconnessione inter-chip (ICI) per chip (GBps) | 1200 |
| Larghezza di banda della rete del data center (DCN) per chip (Gbps) | 50 |
| Topologia di interconnessione | Toro 3D * |
Configurazioni
Un pod TPU v5p è composto da 8960 chip interconnessi con link riconfigurabili ad alta velocità. La rete flessibile della TPU v5p ti consente di connettere i chip in una sezione delle stesse dimensioni in più modi.
La tabella seguente mostra le forme a singola fetta più comuni supportate con v5p, oltre alla maggior parte (ma non tutte) delle forme a cubo intero maggiori di 1 cubo. La forma massima di v5p è 16x16x24 (6144 chip, 96 cubi).
| Topologia | Core | Chip | Hosting | Cubi | Tipo di macchina | Supporta la torsione? |
|---|---|---|---|---|---|---|
| 2x2x1 | 8 | 4 | 1 | N/D | ct5p-hightpu-4t |
N/D |
| 2x2x2 | 16 | 8 | 2 | N/D | ct5p-hightpu-4t |
N/D |
| 2x4x4 | 64 | 32 | 8 | N/D | ct5p-hightpu-4t |
N/D |
| 4x4x4 | 128 | 64 | 16 | 1 | ct5p-hightpu-4t |
N/D |
| 4x4x8 | 256 | 128 | 32 | 2 | ct5p-hightpu-4t |
Sì |
| 4x8x8 | 512 | 256 | 64 | 4 | ct5p-hightpu-4t |
Sì |
| 8x8x8 | 1024 | 512 | 128 | 8 | ct5p-hightpu-4t |
N/D |
| 8x8x16 | 2048 | 1024 | 256 | 16 | ct5p-hightpu-4t |
Sì |
| 8x16x16 | 4096 | 2048 | 512 | 32 | ct5p-hightpu-4t |
Sì |
| 16x16x16 | 8192 | 4096 | 1024 | 64 | ct5p-hightpu-4t |
N/D |
| 16x16x24 | 12288 | 6144 | 1536 | 96 | ct5p-hightpu-4t |
N/D |
L'addestramento a una sola fetta è supportato per un massimo di 6144 chip. Puoi fare lo scale up fino a 18.432 chip utilizzando Multislice. Per maggiori informazioni su Multislice, consulta la panoramica di Cloud TPU Multislice.
Topologie di tori attorcigliati
Per alcune forme di sezioni 3D, puoi utilizzare una topologia toroidale contorta. Queste topologie offrono una larghezza di banda di bisezione significativamente superiore. Ad esempio, una topologia intrecciata 4x4x8 fornisce un aumento teorico del 70% della larghezza di banda di bisezione rispetto a una sezione 4x4x8 non intrecciata. Questa maggiore larghezza di banda aiuta i carichi di lavoro che utilizzano pattern di comunicazione globali. Le topologie twisted possono migliorare le prestazioni della maggior parte dei modelli, con i carichi di lavoro di incorporamento TPU di grandi dimensioni che offrono il vantaggio maggiore. Il software TPU supporta le topologie contorte nelle sezioni in cui ogni dimensione è uguale o doppia rispetto alla dimensione più piccola. Ad esempio, 4x4x8, 4×8×8 o 12x12x24. Le topologie contorte sono supportate su TPU v4 e TPU v5p tramite l'API Cloud TPU.
Per i workload che utilizzano il parallelismo dei dati come unica strategia di parallelismo, le topologie contorte potrebbero avere un rendimento leggermente migliore. Con i modelli linguistici di grandi dimensioni (LLM), le prestazioni della topologia twisted variano a seconda del tipo di parallelismo utilizzato (ad esempio, parallelismo dei dati o del modello). Per ottenere le prestazioni migliori per il tuo modello, addestra l'LLM sia con una topologia contorta sia senza. Alcuni esperimenti sul modello FSDP MaxText hanno mostrato miglioramenti di 1-2 punti percentuali nell'utilizzo FLOP del modello (MFU) quando si utilizza una topologia twisted.
Il vantaggio principale delle topologie contorte è che trasformano una topologia di toro asimmetrica (ad esempio 4×4×8) in una simmetrica. Una topologia simmetrica offre:
- Bilanciamento del carico migliorato
- Larghezza di banda bisezionale più elevata
- Percorsi dei pacchetti più brevi
Questi vantaggi si traducono in un miglioramento delle prestazioni per molti pattern di comunicazione globali.
Ad esempio, considera questa topologia a toro 4×2 con TPU etichettate con coordinate X e Y nella sezione:
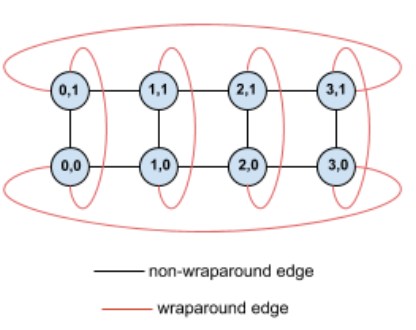
Per chiarezza, il grafico mostra le connessioni come archi non orientati. In pratica, ogni edge è una connessione bidirezionale tra le TPU. I bordi tra un lato di questa griglia e quello opposto sono bordi di ritorno.
Se si ruota questa topologia, si crea una topologia a toro ritorto simmetrico 4×2:
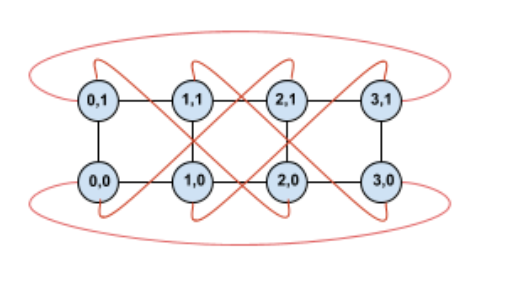
La differenza tra questo diagramma distorto e quello non distorto risiede nei bordi di wrapping Y. Anziché connettersi a un'altra TPU con la stessa coordinata X, questi bordi di ritorno si spostano per connettersi alla TPU con coordinata X+2 mod 4.
Questo principio si applica a dimensioni e numeri di dimensioni diversi. La rete risultante è simmetrica se ogni dimensione è uguale o doppia rispetto alla dimensione più piccola.
La tabella seguente mostra alcune delle topologie twisted supportate e l'aumento teorico della larghezza di banda di bisezione che forniscono rispetto alle topologie untwisted.
| Topologia | Aumento teorico della larghezza di banda di bisezione rispetto a un toro non attorcigliato |
|---|---|
| 4×4×8 | ~70% |
| 8x8x16 | |
| 12×12×24 | |
| 4×8×8 | ~40% |
| 8×16×16 |
Resilienza dell'ICI di Cloud TPU
La resilienza dell'ICI contribuisce a migliorare la tolleranza agli errori dei collegamenti ottici e degli interruttori di circuiti ottici (OCS) che collegano le TPU tra i cubi. (le connessioni ICI all'interno di un cubo utilizzano collegamenti in rame che non sono interessati). La resilienza ICI consente di instradare le connessioni ICI intorno ai guasti OCS e ICI ottici. Di conseguenza, migliora la disponibilità di pianificazione degli slice TPU, con il compromesso di un peggioramento temporaneo delle prestazioni ICI.
Analogamente a Cloud TPU v4, la resilienza ICI è abilitata per impostazione predefinita per le sezioni v5p che sono un cubo o più grandi (topologia 4x4x4).
Proprietà di VM, host e slice
| Proprietà | Valore di una TPU |
|---|---|
| # of v5p chips | 4 |
| Numero di vCPU | 208 (solo la metà è utilizzabile se si utilizza il binding NUMA per evitare penalità di rendimento cross-NUMA) |
| RAM (GB) | 448 (solo la metà è utilizzabile se si utilizza il binding NUMA per evitare penalità di rendimento cross-NUMA) |
| Numero di nodi NUMA | 2 |
| Throughput NIC (Gbps) | 200 |
Relazione tra il numero di Tensor Core, chip, host/VM e cubi in un pod:
| Core | Chip | Host/VM | Cubi | |
|---|---|---|---|---|
| Organizzatore | 8 | 4 | 1 | |
| Cube (rack) | 128 | 64 | 16 | 1 |
| Fetta più grande supportata | 12288 | 6144 | 1536 | 96 |
| v5p full Pod | 17920 | 8960 | 2240 | 140 |