
TPU v5p
Dokumen ini menjelaskan arsitektur dan konfigurasi Cloud TPU v5p yang didukung.
Arsitektur sistem
Bagian ini menjelaskan arsitektur sistem khusus untuk versi v5p. Setiap TensorCore memiliki empat Matrix Multiply Unit (MXU), satu unit vektor, dan satu unit skalar.
Ada 8.960 chip dalam Pod v5p. Job terbesar yang dapat dijadwalkan adalah job 96 kubus (6.144 chip).
Tabel berikut menunjukkan spesifikasi utama untuk TPU v5p.
| Spesifikasi | Nilai |
|---|---|
| Jumlah chip per pod | 8960 |
| Komputasi puncak per chip (BF16) (TFLOPs) | 459 |
| Komputasi puncak per chip (FP8) (TFLOPs) | 459 |
| Kapasitas HBM per chip (GiB) | 95 |
| Bandwidth HBM per chip (GiBps) | 2575 |
| Jumlah vCPU (VM 4 chip) | 208 |
| RAM (GB) (VM 4 chip) | 448 |
| Jumlah TensorCore per chip | 2 |
| Jumlah SparseCore per chip | 4 |
| Bandwidth interkoneksi antar-chip (ICI) dua arah per chip (GBps) | 1200 |
| Bandwidth jaringan pusat data (DCN) per chip (Gbps) | 50 |
| Topologi interkoneksi | Torus 3D * |
Konfigurasi
Pod TPU v5p terdiri dari 8.960 chip yang saling terhubung dengan link berkecepatan tinggi yang dapat dikonfigurasi ulang. Jaringan fleksibel TPU v5p memungkinkan Anda menghubungkan chip dalam slice berukuran sama dengan berbagai cara.
Tabel berikut menunjukkan bentuk slice tunggal yang paling umum didukung dengan v5p, ditambah sebagian besar (tetapi tidak semua) bentuk kubus penuh yang lebih besar dari 1 kubus. Bentuk v5p maksimum adalah 16x16x24 (6.144 chip, 96 kubus).
| Topologi | Cores | Chip | Host | Cubes | Jenis mesin | Mendukung twisted? |
|---|---|---|---|---|---|---|
| 2x2x1 | 8 | 4 | 1 | T/A | ct5p-hightpu-4t |
T/A |
| 2x2x2 | 16 | 8 | 2 | T/A | ct5p-hightpu-4t |
T/A |
| 2x4x4 | 64 | 32 | 8 | T/A | ct5p-hightpu-4t |
T/A |
| 4x4x4 | 128 | 64 | 16 | 1 | ct5p-hightpu-4t |
T/A |
| 4x4x8 | 256 | 128 | 32 | 2 | ct5p-hightpu-4t |
Ya |
| 4x8x8 | 512 | 256 | 64 | 4 | ct5p-hightpu-4t |
Ya |
| 8x8x8 | 1024 | 512 | 128 | 8 | ct5p-hightpu-4t |
T/A |
| 8x8x16 | 2048 | 1024 | 256 | 16 | ct5p-hightpu-4t |
Ya |
| 8x16x16 | 4096 | 2048 | 512 | 32 | ct5p-hightpu-4t |
Ya |
| 16x16x16 | 8192 | 4096 | 1024 | 64 | ct5p-hightpu-4t |
T/A |
| 16x16x24 | 12288 | 6144 | 1536 | 96 | ct5p-hightpu-4t |
T/A |
Pelatihan slice tunggal didukung hingga 6.144 chip. Anda dapat melakukan peningkatan skala hingga 18.432 chip menggunakan Multislice. Untuk mengetahui informasi selengkapnya tentang Multislice, lihat Ringkasan Multislice Cloud TPU.
Topologi torus twisted
Untuk beberapa bentuk slice 3D, Anda dapat menggunakan topologi torus twisted. Topologi ini menawarkan bandwidth bisection yang jauh lebih tinggi. Misalnya, topologi twisted 4x4x8 memberikan peningkatan bandwidth bisection teoretis sebesar 70% dibandingkan dengan slice 4x4x8 non-twisted. Peningkatan bandwidth ini membantu workload yang menggunakan pola komunikasi global. Topologi twisted dapat meningkatkan performa untuk sebagian besar model, dengan workload embedding TPU besar yang memberikan manfaat terbesar. Software TPU mendukung topologi twisted pada slice dengan setiap dimensi sama dengan atau dua kali ukuran dimensi terkecil. Misalnya, 4x4x8, 4×8×8, atau 12x12x24. Topologi twisted didukung di TPU v4 dan TPU v5p melalui Cloud TPU API.
Untuk workload yang menggunakan paralelisme data sebagai satu-satunya strategi paralelisme, topologi twisted mungkin akan berperforma sedikit lebih baik. Dengan model bahasa besar (LLM), performa topologi twisted bervariasi bergantung pada jenis paralelisme yang digunakan (misalnya, paralelisme data atau paralelisme model). Untuk menemukan performa terbaik untuk model Anda, latih LLM Anda dengan dan tanpa topologi twisted. Beberapa eksperimen pada model FSDP MaxText menunjukkan peningkatan 1-2 poin persentase dalam pemanfaatan FLOP model (MFU) saat menggunakan topologi twisted.
Manfaat utama topologi twisted adalah mengubah topologi torus asimetris (misalnya, 4×4×8) menjadi topologi simetris. Topologi simetris menawarkan:
- Load balancing yang ditingkatkan
- Bandwidth bisection yang lebih tinggi
- Rute paket yang lebih pendek
Manfaat ini menghasilkan peningkatan performa untuk banyak pola komunikasi global.
Misalnya, pertimbangkan topologi torus 4×2 ini dengan TPU yang diberi label dengan koordinat X dan Y dalam slice:
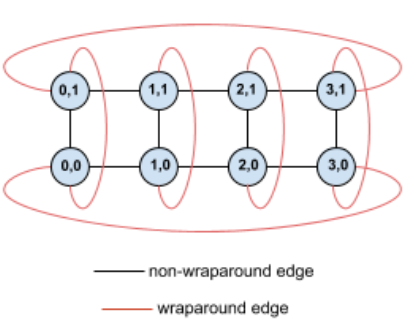
Agar lebih jelas, grafik menunjukkan koneksi sebagai tepi tidak terarah. Dalam praktiknya, setiap tepi adalah koneksi dua arah antara TPU. Tepi antara satu sisi petak ini dan sisi yang berlawanan adalah tepi loop (wrap-around edge).
Memutar topologi ini akan membuat topologi torus twisted 4×2 simetris:
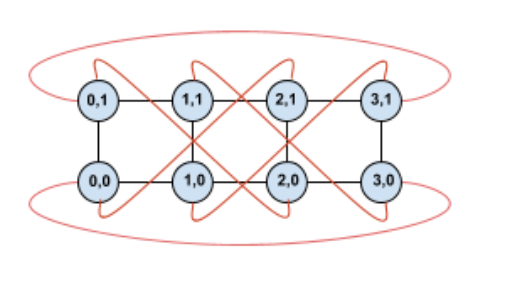
Perbedaan antara diagram twisted ini dan diagram non-twisted terletak pada tepi loop Y. Daripada terhubung ke TPU lain dengan koordinat X yang sama, tepi loop ini bergeser untuk terhubung ke TPU pada koordinat X+2 mod 4.
Prinsip ini berlaku untuk ukuran dimensi dan jumlah dimensi yang berbeda. Jaringan yang dihasilkan bersifat simetris jika setiap dimensi sama dengan atau dua kali ukuran dimensi terkecil.
Tabel berikut menunjukkan beberapa topologi twisted yang didukung dan peningkatan bandwidth bisection teoretis yang diberikannya dibandingkan dengan topologi non-twisted.
| Topologi | Peningkatan bandwidth bisection teoretis dibandingkan dengan torus non-twisted |
|---|---|
| 4×4×8 | ~70% |
| 8x8x16 | |
| 12×12×24 | |
| 4×8×8 | ~40% |
| 8×16×16 |
Resiliensi ICI Cloud TPU
Resiliensi ICI membantu meningkatkan fault tolerance link optik dan optical circuit switch (OCS) yang menghubungkan TPU antar-kubus. (Koneksi ICI dalam kubus menggunakan link tembaga yang tidak terpengaruh). Resiliensi ICI memungkinkan koneksi ICI dirutekan di sekitar kesalahan OCS dan ICI optik. Akibatnya, hal ini meningkatkan ketersediaan penjadwalan slice TPU, dengan pertukaran penurunan sementara dalam performa ICI.
Mirip dengan Cloud TPU v4, resiliensi ICI diaktifkan secara default untuk slice v5p yang berukuran satu kubus atau lebih besar (topologi 4x4x4).
Properti VM, host, dan slice
| Properti | Nilai dalam TPU |
|---|---|
| Jumlah chip v5p | 4 |
| Jumlah vCPU | 208 (hanya setengah yang dapat digunakan jika menggunakan binding NUMA untuk menghindari penalti performa lintas-NUMA) |
| RAM (GB) | 448 (hanya setengah yang dapat digunakan jika menggunakan binding NUMA untuk menghindari penalti performa lintas-NUMA) |
| Jumlah node NUMA | 2 |
| Throughput NIC (Gbps) | 200 |
Hubungan antara jumlah TensorCore, chip, host/VM, dan kubus dalam Pod:
| Cores | Chip | Host/VM | Kubus | |
|---|---|---|---|---|
| Host | 8 | 4 | 1 | |
| Kubus (rak) | 128 | 64 | 16 | 1 |
| Slice terbesar yang didukung | 12288 | 6144 | 1536 | 96 |
| Pod lengkap v5p | 17920 | 8960 | 2240 | 140 |