
TPU v5e
本文档介绍了 Cloud TPU v5e 的架构和支持的配置。
TPU v5e 支持单主机和多主机训练,以及单主机推理。使用 Sax 支持多主机推理。 如需了解详情,请参阅 Cloud TPU 推理。
系统架构
每个 v5e 芯片包含一个 TensorCore。每个 TensorCore 都有四个矩阵乘法单元 (MXU)、一个向量单元和一个标量单元。
下图展示了 TPU v5e 芯片。

下表展示了 v5e 的主要芯片规格及其值。
| 芯片主要规格 | v5e 值 |
|---|---|
| 每个芯片的峰值计算能力 (bf16) | 197 TFLOPs |
| HBM2 容量和带宽 | 16 GB,819 GBps |
| 双向芯片间互连 (ICI) 带宽(每芯片) | 400 GBps |
下表展示了 Pod 规范及其 v5e 值。
| 关键 Pod 规范 | v5e 值 |
|---|---|
| TPU Pod 大小 | 256 个芯片 |
| 互连拓扑 | 2D 环面 |
| 每个 Pod 的峰值计算能力 | 100 PetaOps(Int8) |
| 每个 Pod 的 All-reduce 带宽 | 51.2 TBps |
| 每个 Pod 的对分带宽 | 1.6 TBps |
| 每个 Pod 的数据中心网络带宽 | 6.4 Tbps |
配置
Cloud TPU v5e 是一款集训练和推理(服务)于一体的产品。训练作业针对吞吐量和可用性进行了优化,服务作业则针对延迟时间进行了优化。在为服务而预配的 TPU 上运行的训练作业的可用性可能较低,同样,在为训练而预配的 TPU 上执行的服务作业的延迟时间可能较长。
v5e 支持以下 2D 切片形状:
| 拓扑 | TPU 芯片数量 | 主机数量 |
|---|---|---|
| 1x1 | 1 | 1/8 |
| 2x2 | 4 | 1/2 |
| 2x4 | 8 | 1 |
| 4x4 | 16 | 2 |
| 4x8 | 32 | 4 |
| 8x8 | 64 | 8 |
| 8x16 | 128 | 16 |
| 16x16 | 256 | 32 |
虚拟机类型
v5e TPU 切片中的每个 TPU 虚拟机都包含 1 个、4 个或 8 个芯片。在 4 芯片及更小的切片中,所有 TPU 芯片共享同一非统一内存访问 (NUMA) 节点。
对于 8 芯片 v5e TPU 虚拟机,CPU-TPU 通信在 NUMA 分区内会更高效。例如,在下图中,CPU0-Chip0 通信会比 CPU0-Chip4 通信更快。
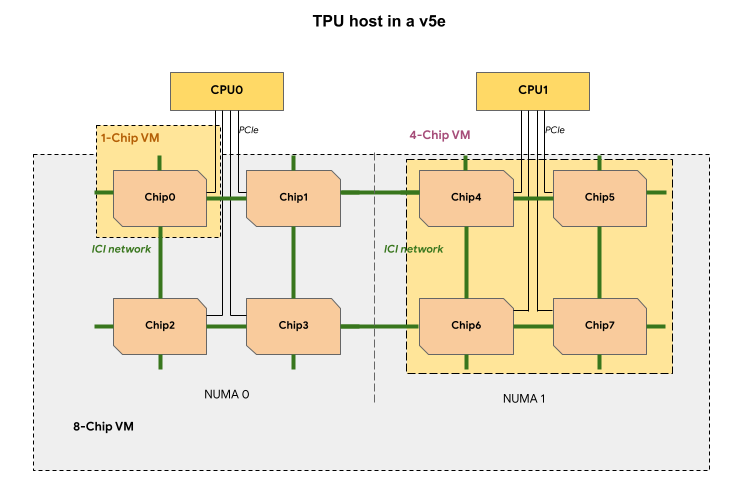
下表比较了 TPU v5e 虚拟机类型:
| 虚拟机类型 | 机器类型 (GKE API) | 每个虚拟机的 vCPU 数量 | 每个虚拟机的 RAM (GB) | 每个虚拟机的 NUMA 节点数 |
|---|---|---|---|---|
| 单芯片虚拟机 | ct5lp-hightpu-1t |
24 | 48 | 1 |
| 4 芯片虚拟机 | ct5lp-hightpu-4t |
112 | 192 | 1 |
| 8 芯片虚拟机 | ct5lp-hightpu-8t |
224 | 384 | 2 |
用于服务的 Cloud TPU v5e 类型
单主机服务最多支持 8 个 v5e 芯片。支持以下配置:1x1、2x2 和 2x4 切片。每个切片分别有 1 个、4 个和 8 个芯片。
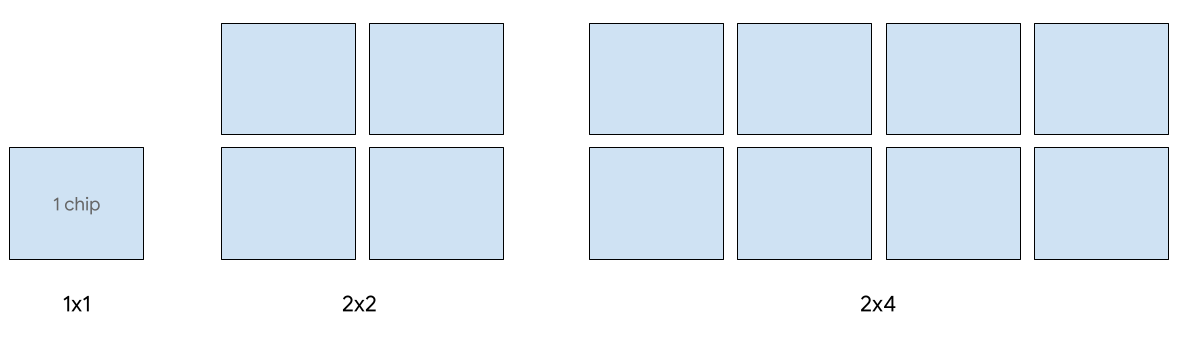
如需为服务作业预配 TPU,请在 CLI 或 API TPU 创建请求中使用以下 TPU 切片大小之一:
| TPU 芯片数量 | 机器类型 (GKE API) |
|---|---|
1 |
ct5lp-hightpu-1t |
4 |
ct5lp-hightpu-4t |
8 |
ct5lp-hightpu-8t |
如需详细了解如何管理 TPU,请参阅管理 TPU。如需详细了解 Cloud TPU 的系统架构,请参阅系统架构。
使用 Sax 可在超过 8 个 v5e 芯片上提供服务,也称为多主机服务。如需了解详情,请参阅 Cloud TPU 推理。
用于训练的 Cloud TPU v5e 类型
训练最多支持 256 个芯片。
如需为 v5e 训练作业预配 TPU,请在 CLI 或 API TPU 创建请求中使用以下 TPU 切片大小之一:
| TPU 芯片数量 | 机器类型 (GKE API) | 拓扑 |
|---|---|---|
16 |
ct5lp-hightpu-4t |
4x4 |
32 |
ct5lp-hightpu-4t |
4x8 |
64 |
ct5lp-hightpu-4t |
8x8 |
128 |
ct5lp-hightpu-4t |
8x16 |
256 |
ct5lp-hightpu-4t |
16x16 |
如需详细了解如何管理 TPU,请参阅管理 TPU。如需详细了解 Cloud TPU 的系统架构,请参阅系统架构。