
TPU v4
Dokumen ini menjelaskan arsitektur dan konfigurasi Cloud TPU v4 yang didukung.
Arsitektur sistem
Tiap chip TPU v4 berisi dua TensorCore. Tiap TensorCore memiliki empat unit perkalian matriks (MXU), satu unit vektor, dan satu unit skalar. Tabel berikut menampilkan spesifikasi utama untuk Pod TPU v4.
| Spesifikasi | Nilai |
|---|---|
| Komputasi puncak per chip | 275 teraflops (bf16 atau int8) |
| Kapasitas dan bandwidth HBM2 | 32 GiB, 1200 GBps |
| Daya min/rata-rata/maksimum yang diukur | 90/170/192 W |
| Ukuran Pod TPU | 4096 chip |
| Topologi interkoneksi | Mesh 3D |
| Komputasi puncak per Pod | 1,1 exaflops (bf16 atau int8) |
| Bandwidth all-reduce per Pod | 1,1 PB/dtk |
| Bandwidth bisection per Pod | 24 TB/dtk |
Diagram berikut menggambarkan chip TPU v4.
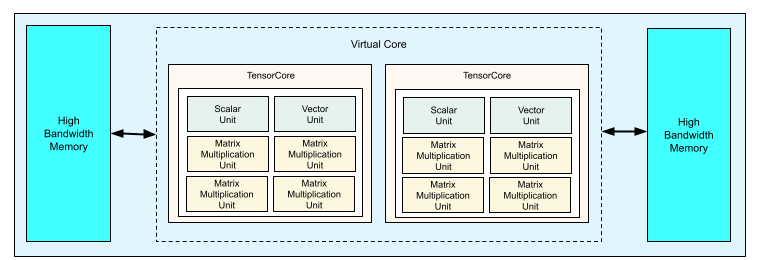
Untuk mengetahui informasi selengkapnya tentang detail arsitektur dan karakteristik performa untuk TPU v4, lihat TPU v4: Superkomputer yang Dapat Dikonfigurasi Secara Optik untuk Machine Learning dengan Dukungan Hardware untuk Penyematan.
Mesh 3D dan torus 3D
TPU v4 memiliki koneksi langsung ke chip tetangga terdekat dalam 3 dimensi, sehingga menghasilkan mesh 3D dari koneksi jaringan. Koneksi dapat dikonfigurasi sebagai torus 3D pada slice dengan topologi, AxBxC, adalah 2A=B=C atau 2A=2B=C, dengan setiap dimensi adalah kelipatan 4. Misalnya, 4x4x8, 4x8x8, atau 12x12x24. Secara umum, performa konfigurasi torus 3D akan lebih baik daripada konfigurasi mesh 3D. Untuk mengetahui informasi selengkapnya, lihat Topologi torus twisted.
Manfaat performa TPU v4 dibandingkan v3
Bagian ini menunjukkan cara hemat memori untuk menjalankan skrip pelatihan contoh di TPU v4, serta peningkatan performa untuk TPU v4 dibandingkan dengan TPU v3.
Sistem memori
Non Uniform Memory Access (NUMA) adalah arsitektur memori komputer untuk mesin yang memiliki beberapa CPU. Setiap CPU memiliki akses langsung ke blok memori berkecepatan tinggi. CPU dan memorinya disebut node NUMA. Node NUMA terhubung ke node NUMA lain yang berdekatan satu sama lain. CPU dari satu node NUMA dapat mengakses memori di node NUMA lain, tetapi akses ini lebih lambat daripada mengakses memori dalam node NUMA.
Software yang berjalan di mesin multi-CPU dapat menempatkan data yang diperlukan oleh CPU dalam node NUMA-nya, sehingga meningkatkan throughput memori. Untuk mengetahui informasi selengkapnya tentang NUMA, lihat Non Uniform Memory Access di Wikipedia.
Anda dapat memanfaatkan manfaat lokalitas NUMA dengan mengikat skrip pelatihan ke Node NUMA 0.
Untuk mengaktifkan pengikatan node NUMA:
Instal alat command line numactl. numactl memungkinkan Anda menjalankan proses dengan kebijakan penempatan memori atau penjadwalan NUMA tertentu.
$ sudo apt-get update $ sudo apt-get install numactl
Ikat kode skrip Anda ke Node NUMA 0. Ganti your-training-script dengan jalur ke skrip pelatihan Anda.
$ numactl --cpunodebind=0 python3 your-training-script
Aktifkan pengikatan node NUMA jika:
- Jika workload Anda sangat bergantung pada workload CPU (misalnya, klasifikasi gambar, workload rekomendasi) terlepas dari framework.
- Jika Anda menggunakan versi runtime TPU tanpa akhiran -pod (misalnya,
tpu-vm-tf-2.10.0-v4).
Perbedaan sistem memori lainnya:
- Chip TPU v4 memiliki ruang memori HBM 32 GiB terpadu di seluruh chip, sehingga memungkinkan koordinasi yang lebih baik antara dua TensorCore on-chip.
- Performa HBM yang ditingkatkan menggunakan standar dan kecepatan memori terbaru.
- Profil performa DMA yang ditingkatkan dengan dukungan bawaan untuk striding berperforma tinggi pada granularitas 512B.
TensorCores
- Jumlah MXU dua kali lipat dan kecepatan clock yang lebih tinggi memberikan TFLOPS maksimum 275.
- Bandwidth transposisi dan permutasi 2x.
- Model akses memori load-store untuk Memori Umum (Cmem).
- Bandwidth pemuatan bobot MXU yang lebih cepat dan dukungan mode 8-bit untuk memungkinkan ukuran batch yang lebih rendah dan latensi inferensi yang ditingkatkan.
Interkoneksi antar-chip
Enam link interkoneksi per chip untuk mengaktifkan topologi jaringan yang memiliki diameter jaringan lebih kecil.
Lainnya
- Antarmuka PCIE gen3 x16 ke host (koneksi langsung).
- Model keamanan yang ditingkatkan.
- Efisiensi energi yang ditingkatkan.
Konfigurasi
Pod TPU v4 terdiri dari 4096 chip yang saling terhubung dengan link berkecepatan tinggi yang dapat dikonfigurasi ulang. Jaringan fleksibel TPU v4 memungkinkan Anda menghubungkan chip dalam slice berukuran sama dengan berbagai cara. Saat membuat slice TPU, Anda menentukan versi TPU dan jumlah resource TPU yang diperlukan.
Anda menentukan topologi TPU menggunakan 3-tuple, AxBxC dengan A<=B<=C dan A, B, C semuanya <= 4 atau semuanya kelipatan bilangan bulat dari 4. Nilai A, B, dan C adalah jumlah chip dalam masing-masing dari tiga dimensi.
Topologi dengan 2A=B=C atau 2A=2B=C juga memiliki varian topologi yang dioptimalkan untuk komunikasi all-to-all, misalnya, 4×4×8, 8×8×16, dan 12×12×24. Topologi ini dikenal sebagai topologi torus twisted.
Ilustrasi berikut menunjukkan beberapa topologi TPU v4 umum.
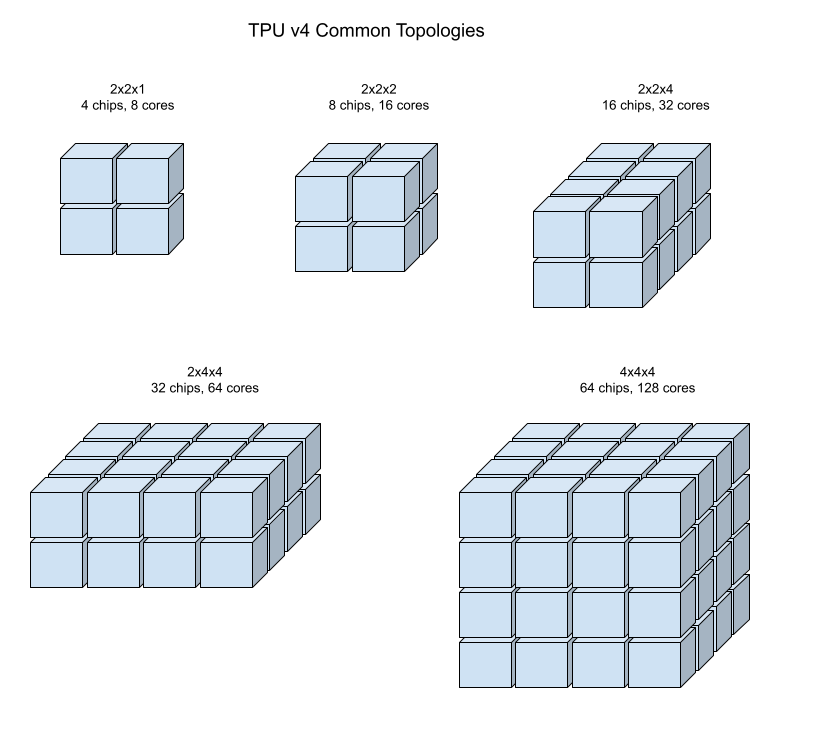
Slice yang lebih besar dapat dibuat dari satu atau beberapa "kubus" chip 4x4x4.
Untuk mengetahui informasi selengkapnya tentang cara mengelola TPU, lihat Mengelola TPU. Untuk mengetahui informasi selengkapnya tentang arsitektur sistem Cloud TPU, lihat Arsitektur sistem.
Topologi torus twisted
Untuk beberapa bentuk slice 3D, Anda dapat menggunakan topologi torus twisted. Topologi ini menawarkan bandwidth bisection yang jauh lebih tinggi. Misalnya, topologi twisted 4x4x8 memberikan peningkatan bandwidth bisection teoretis sebesar 70% dibandingkan dengan slice 4x4x8 non-twisted. Peningkatan bandwidth ini membantu workload yang menggunakan pola komunikasi global. Topologi twisted dapat meningkatkan performa untuk sebagian besar model, dengan workload penyematan TPU besar yang memberikan manfaat terbesar. Software TPU mendukung topologi twisted pada slice dengan setiap dimensi sama dengan atau dua kali ukuran dimensi terkecil. Misalnya, 4x4x8, 4×8×8, atau 12x12x24. Topologi twisted didukung di TPU v4 dan TPU v5p melalui Cloud TPU API.
Untuk workload yang menggunakan paralelisme data sebagai satu-satunya strategi paralelisme, topologi twisted mungkin akan berperforma sedikit lebih baik. Dengan model bahasa besar (LLM), performa topologi twisted bervariasi bergantung pada jenis paralelisme yang digunakan (misalnya, paralelisme data atau paralelisme model). Untuk menemukan performa terbaik untuk model Anda, latih LLM Anda dengan dan tanpa topologi twisted. Beberapa eksperimen pada model FSDP MaxText menunjukkan peningkatan 1-2 poin persentase dalam pemakaian FLOP model (MFU) saat menggunakan topologi twisted.
Manfaat utama topologi twisted adalah mengubah topologi torus asimetris (misalnya, 4×4×8) menjadi topologi simetris. Topologi simetris menawarkan:
- Load balancing yang ditingkatkan
- Bandwidth bisection yang lebih tinggi
- Rute paket yang lebih pendek
Manfaat ini menghasilkan peningkatan performa untuk banyak pola komunikasi global.
Misalnya, pertimbangkan topologi torus 4×2 ini dengan TPU yang diberi label dengan koordinat X dan Y dalam slice:
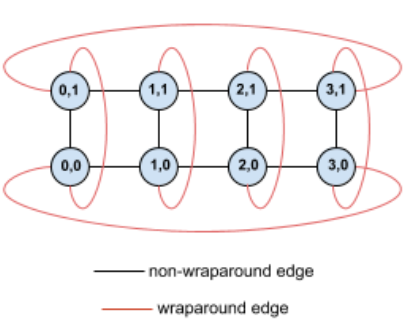
Agar lebih jelas, grafik menunjukkan koneksi sebagai tepi yang tidak diarahkan. Dalam praktiknya, setiap tepi adalah koneksi dua arah antara TPU. Tepi antara satu sisi petak ini dan sisi yang berlawanan adalah tepi wrap-around.
Memutar topologi ini akan membuat topologi torus twisted 4×2 simetris:
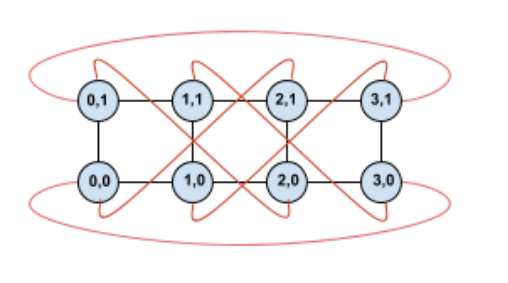
Perbedaan antara diagram twisted ini dan diagram non-twisted terletak pada tepi wrap-around Y. Alih-alih terhubung ke TPU lain dengan koordinat X yang sama, tepi wrap-around ini bergeser untuk terhubung ke TPU pada koordinat X+2 mod 4.
Prinsip ini berlaku untuk ukuran dimensi dan jumlah dimensi yang berbeda. Jaringan yang dihasilkan bersifat simetris jika setiap dimensi sama dengan atau dua kali ukuran dimensi terkecil.
Tabel berikut menunjukkan beberapa topologi twisted yang didukung dan peningkatan bandwidth bisection teoretis yang diberikannya dibandingkan dengan topologi non-twisted.
| Topologi | Peningkatan bandwidth bisection teoretis dibandingkan dengan torus non-twisted |
|---|---|
| 4×4×8 | ~70% |
| 8x8x16 | |
| 12×12×24 | |
| 4×8×8 | ~40% |
| 8×16×16 |
Varian topologi TPU v4
Beberapa topologi yang berisi jumlah chip yang sama dapat diatur dengan cara yang berbeda. Misalnya, slice TPU dengan 512 chip (1024 TensorCore) dapat dikonfigurasi menggunakan topologi berikut: 4x4x32, 4x8x16, atau 8x8x8. Slice TPU dengan 2048 chip (4096 TensorCore) menawarkan lebih banyak opsi topologi: 4x4x128, 4x8x64, 4x16x32, dan 8x16x16.
Topologi default yang terkait dengan jumlah chip tertentu adalah topologi yang paling mirip dengan kubus. Bentuk ini kemungkinan merupakan pilihan terbaik untuk pelatihan ML paralel data. Topologi lain dapat berguna untuk workload dengan beberapa jenis paralelisme (misalnya, paralelisme model dan data, atau partisi spasial simulasi). Workload ini berperforma terbaik jika topologi cocok dengan paralelisme yang digunakan. Misalnya, menempatkan paralelisme model 4 arah pada dimensi X dan paralelisme data 256 arah pada dimensi Y dan Z cocok dengan topologi 4x16x16.
Model dengan beberapa dimensi paralelisme berperforma terbaik dengan dimensi paralelisme yang dipetakan ke dimensi topologi TPU. Model ini biasanya merupakan model bahasa besar (LLM) paralel data dan model. Misalnya, untuk slice TPU v4 dengan topologi 8x16x16, dimensi topologi TPU adalah 8, 16, dan 16. Lebih berperforma jika menggunakan paralelisme model 8 arah atau 16 arah (dipetakan ke salah satu dimensi topologi TPU fisik). Paralelisme model 4 arah akan menjadi sub-optimal dengan topologi ini, karena tidak selaras dengan dimensi topologi TPU mana pun, tetapi akan optimal dengan topologi 4x16x32 pada jumlah chip yang sama.
Konfigurasi TPU v4 terdiri dari dua grup, yaitu konfigurasi dengan topologi yang lebih kecil dari 64 chip (topologi kecil) dan konfigurasi dengan topologi yang lebih besar dari 64 chip (topologi besar).
Topologi v4 kecil
Cloud TPU mendukung slice TPU v4 berikut yang lebih kecil dari 64 chip, kubus 4x4x4. Anda dapat membuat topologi v4 kecil ini menggunakan nama berbasis TensorCore (misalnya, v4-32), atau topologinya (misalnya, 2x2x4):
| Nama (berdasarkan jumlah TensorCore) | Jumlah chip | Topologi |
| v4-8 | 4 | 2x2x1 |
| v4-16 | 8 | 2x2x2 |
| v4-32 | 16 | 2x2x4 |
| v4-64 | 32 | 2x4x4 |
Topologi v4 besar
Slice TPU v4 tersedia dalam kelipatan 64 chip, dengan bentuk yang merupakan kelipatan 4 pada ketiga dimensi. Dimensi harus dalam urutan yang meningkat. Beberapa contoh ditampilkan dalam tabel berikut. Beberapa topologi ini adalah topologi "kustom" yang hanya dapat dibuat menggunakan flag --type dan --topology karena ada lebih dari satu cara untuk mengatur chip.
| Nama (berdasarkan jumlah TensorCore) | Jumlah chip | Topologi |
| v4-128 | 64 | 4x4x4 |
| v4-256 | 128 | 4x4x8 |
| v4-512 | 256 | 4x8x8 |
topologi kustom: harus menggunakan flag --type dan --topology |
256 | 4x4x16 |
| v4-1024 | 512 | 8x8x8 |
| v4-1536 | 768 | 8x8x12 |
| v4-2048 | 1024 | 8x8x16 |
topologi kustom: harus menggunakan flag --type dan --topology |
1024 | 4x16x16 |
| v4-4096 | 2048 | 8x16x16 |
| … | … | … |