
TPU v4
Questo documento descrive l'architettura e le configurazioni supportate di Cloud TPU v4.
Architettura di sistema
Ogni chip TPU v4 contiene due TensorCore. Ogni TensorCore ha quattro unità di moltiplicazione a matrice (MXU), un'unità vettoriale e un'unità scalare. La tabella seguente mostra le specifiche chiave per un pod di TPU v4.
| Specifica | Valori |
|---|---|
| Calcolo di picco per chip | 275 teraflop (bf16 o int8) |
| Capacità e larghezza di banda HBM2 | 32 GiB, 1200 GBps |
| Potenza minima/media/massima misurata | 90/170/192 W |
| Dimensioni del pod di TPU | 4096 chip |
| Topologia di interconnessione | Mesh 3D |
| Calcolo di picco per pod | 1,1 exaflop (bf16 o int8) |
| Larghezza di banda all-reduce per pod | 1,1 PB/s |
| Larghezza di banda bisezionale per pod | 24 TB/s |
Il seguente diagramma illustra un chip TPU v4.
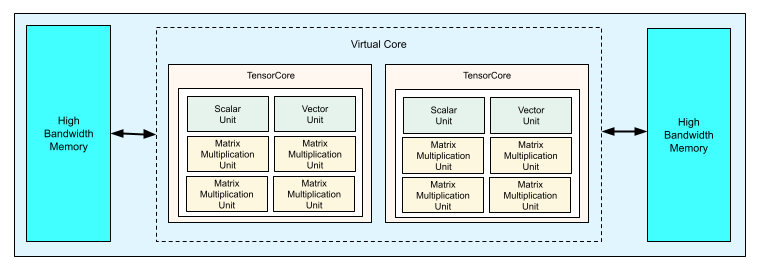
Per ulteriori informazioni sui dettagli dell'architettura e sulle caratteristiche di rendimento di TPU v4, consulta TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings.
Mesh 3D e toro 3D
Le TPU v4 hanno una connessione diretta ai chip vicini più vicini in 3 dimensioni, il che si traduce in una mesh 3D di connessioni di rete. Le connessioni possono essere configurate come un toro 3D sulle sezioni in cui la topologia, AxBxC, è 2A=B=C o 2A=2B=C, dove ogni dimensione è un multiplo di 4. Ad esempio, 4x4x8, 4x8x8 o 12x12x24. In generale, il rendimento di una configurazione a toro 3D sarà migliore rispetto a una configurazione a mesh 3D. Per ulteriori informazioni, consulta Topologie a toro ritorto.
Vantaggi di rendimento di TPU v4 rispetto a v3
Questa sezione mostra un modo efficiente in termini di memoria per eseguire uno script di addestramento di esempio su TPU v4, nonché i miglioramenti del rendimento per TPU v4 rispetto a TPU v3.
Sistema di memoria
L'accesso alla memoria non uniforme (NUMA) è un'architettura di memoria del computer per le macchine con più CPU. Ogni CPU ha accesso diretto a un blocco di memoria ad alta velocità. Una CPU e la relativa memoria sono chiamate nodo NUMA. I nodi NUMA sono collegati ad altri nodi NUMA direttamente adiacenti tra loro. Una CPU di un nodo NUMA può accedere alla memoria di un altro nodo NUMA, ma questo accesso è più lento rispetto all'accesso alla memoria all'interno di un nodo NUMA.
Il software in esecuzione su una macchina multi-CPU può inserire i dati necessari a una CPU all'interno del relativo nodo NUMA, aumentando il throughput della memoria. Per ulteriori informazioni su NUMA, consulta Accesso alla memoria non uniforme su Wikipedia.
Puoi sfruttare i vantaggi della località NUMA associando lo script di addestramento al nodo NUMA 0.
Per abilitare l'associazione del nodo NUMA:
Installa lo strumento a riga di comando numactl. numactl consente di eseguire processi con una policy di posizionamento della memoria o di pianificazione NUMA specifica.
$ sudo apt-get update $ sudo apt-get install numactl
Associa il codice dello script al nodo NUMA 0. Sostituisci your-training-script con il percorso dello script di addestramento.
$ numactl --cpunodebind=0 python3 your-training-script
Abilita l'associazione del nodo NUMA se:
- Se il carico di lavoro dipende molto dai carichi di lavoro della CPU (ad esempio, classificazione delle immagini, carichi di lavoro di raccomandazione) indipendentemente dal framework.
- Se utilizzi una versione di runtime TPU senza suffisso -pod (ad esempio,
tpu-vm-tf-2.10.0-v4).
Altre differenze del sistema di memoria:
- I chip TPU v4 hanno uno spazio di memoria HBM unificato di 32 GiB sull'intero chip, il che consente una migliore coordinazione tra i due TensorCore on-chip.
- Rendimento HBM migliorato grazie agli standard e alle velocità di memoria più recenti.
- Profilo di rendimento DMA migliorato con supporto integrato per lo striding ad alte prestazioni con granularità di 512 B.
TensorCores
- Il doppio del numero di MXU e una frequenza di clock più elevata che offre 275 TFLOPS massimi.
- Larghezza di banda di trasposizione e permutazione 2x.
- Modello di accesso alla memoria di caricamento-memorizzazione per la memoria comune (Cmem).
- Larghezza di banda di caricamento dei pesi MXU più veloce e supporto della modalità a 8 bit per consentire dimensioni dei batch inferiori e una latenza di inferenza migliorata.
Interconnessione tra chip
Sei link di interconnessione per chip per abilitare topologie di rete con diametri di rete più piccoli.
Altro
- Interfaccia PCIE gen3 x16 per l'host (connessione diretta).
- Modello di sicurezza migliorato.
- Efficienza energetica migliorata.
Configurazioni
Un pod TPU v4 è composto da 4096 chip interconnessi con link ad alta velocità riconfigurabili. La rete flessibile di TPU v4 consente di collegare i chip in una sezione di dimensioni uguali in più modi. Quando crei una sezione TPU, specifichi la versione di TPU e il numero di risorse TPU richieste.
Specifichi una topologia TPU utilizzando una tripla, AxBxC, dove A<=B<=C e A, B, C sono tutti <= 4 o sono tutti multipli interi di 4. I valori A, B e C sono i conteggi dei chip in ciascuna delle tre dimensioni.
Le topologie in cui 2A=B=C o 2A=2B=C hanno anche varianti di topologia ottimizzate per la comunicazione all-to-all, ad esempio 4×4×8, 8×8×16 e 12×12×24. Queste sono note come topologie a toro ritorto.
Le seguenti illustrazioni mostrano alcune topologie TPU v4 comuni.
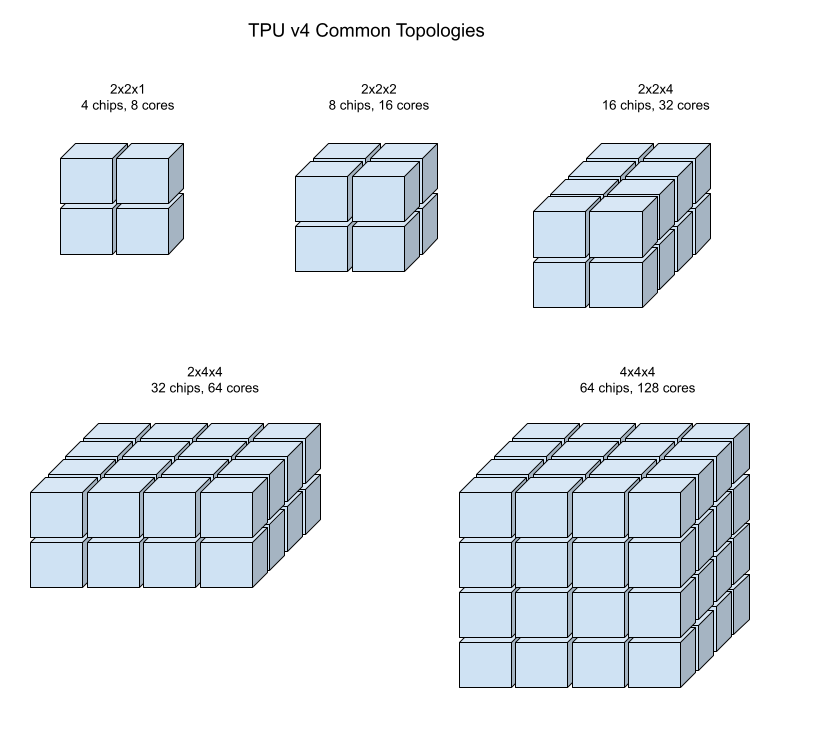
Le sezioni più grandi possono essere create da uno o più "cubi" di chip 4x4x4.
Per ulteriori informazioni sulla gestione delle TPU, consulta Gestire le TPU. Per ulteriori informazioni sull'architettura di sistema di Cloud TPU, consulta Architettura di sistema.
Topologie a toro ritorto
Per alcune forme di sezioni 3D, puoi utilizzare una topologia a toro ritorto. Queste topologie offrono una larghezza di banda bisezionale notevolmente superiore. Ad esempio, una topologia ritorta 4x4x8 offre un aumento teorico del 70% della larghezza di banda bisezionale rispetto a una sezione 4x4x8 non ritorta. Questa maggiore larghezza di banda aiuta i carichi di lavoro che utilizzano pattern di comunicazione globali. Le topologie ritorte possono migliorare il rendimento della maggior parte dei modelli, con i carichi di lavoro di incorporamento TPU di grandi dimensioni che offrono il massimo vantaggio. Il software TPU supporta le topologie ritorte sulle sezioni in cui ogni dimensione è uguale o doppia rispetto alla dimensione più piccola. Ad esempio, 4x4x8, 4×8×8 o 12x12x24. Le topologie ritorte sono supportate su TPU v4 e TPU v5p tramite l'API Cloud TPU.
Per i carichi di lavoro che utilizzano il parallelismo dei dati come unica strategia di parallelismo, le topologie ritorte potrebbero avere un rendimento leggermente migliore. Con i modelli linguistici di grandi dimensioni (LLM), il rendimento della topologia ritorta varia a seconda del tipo di parallelismo utilizzato (ad esempio, parallelismo dei dati o parallelismo dei modelli). Per trovare il rendimento migliore per il tuo modello, addestra l'LLM sia con che senza una topologia ritorta. Alcuni esperimenti sul modello FSDP MaxText hanno mostrato miglioramenti di 1-2 punti percentuali nell'utilizzo FLOP del modello (MFU) quando si utilizza una topologia ritorta.
Il vantaggio principale delle topologie ritorte è che trasformano una topologia a toro asimmetrica (ad esempio, 4×4×8) in una simmetrica. Una topologia simmetrica offre:
- Bilanciamento del carico migliorato
- Larghezza di banda bisezionale più elevata
- Percorsi dei pacchetti più brevi
Questi vantaggi comportano un miglioramento del rendimento per molti pattern di comunicazione globali.
Ad esempio, considera questa topologia a toro 4×2 con TPU etichettate con coordinate X e Y nella sezione:
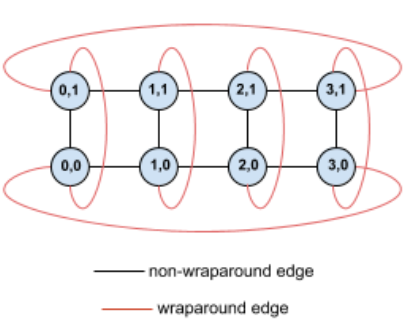
Per chiarezza, il grafico mostra le connessioni come bordi non diretti. In pratica, ogni bordo è una connessione bidirezionale tra le TPU. I bordi tra un lato di questa griglia e il lato opposto sono bordi di wrapping.
La torsione di questa topologia crea una topologia a toro ritorto simmetrica 4×2:
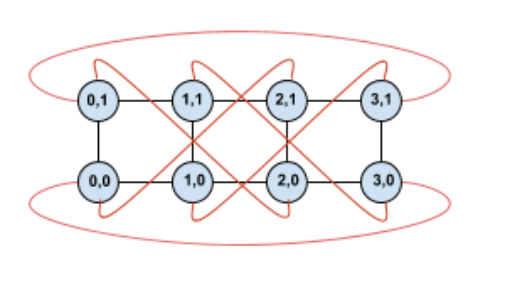
La differenza tra questo diagramma ritorto e quello non ritorto risiede nei bordi di wrapping Y. Anziché connettersi a un'altra TPU con la stessa coordinata X, questi bordi di wrapping si spostano per connettersi alla TPU con coordinata X+2 mod 4.
Questo principio si applica a dimensioni e numeri di dimensioni diversi. La rete risultante è simmetrica se ogni dimensione è uguale o doppia rispetto alla dimensione più piccola.
La tabella seguente mostra alcune delle topologie ritorte supportate e l'aumento teorico della larghezza di banda bisezionale che forniscono rispetto alle topologie non ritorte.
| Topologia | Aumento teorico della larghezza di banda bisezionale rispetto a un toro non ritorto |
|---|---|
| 4×4×8 | ~70% |
| 8x8x16 | |
| 12×12×24 | |
| 4×8×8 | ~40% |
| 8×16×16 |
Varianti di topologia TPU v4
Alcune topologie contenenti lo stesso numero di chip possono essere disposte in modi diversi. Ad esempio, una sezione TPU con 512 chip (1024 TensorCore) può essere configurata utilizzando le seguenti topologie: 4x4x32, 4x8x16 o 8x8x8. Una sezione TPU con 2048 chip (4096 TensorCore) offre ancora più opzioni di topologia: 4x4x128, 4x8x64, 4x16x32 e 8x16x16.
La topologia predefinita associata a un determinato conteggio dei chip è quella più simile a un cubo. Questa forma è probabilmente la scelta migliore per l'addestramento ML con parallelismo dei dati. Altre topologie possono essere utili per i carichi di lavoro con più tipi di parallelismo (ad esempio, parallelismo dei modelli e dei dati o partizionamento spaziale di una simulazione). Questi carichi di lavoro hanno un rendimento ottimale se la topologia corrisponde al parallelismo utilizzato. Ad esempio, il posizionamento del parallelismo dei modelli a 4 vie sulla dimensione X e del parallelismo dei dati a 256 vie sulle dimensioni Y e Z corrisponde a una topologia 4x16x16.
I modelli con più dimensioni di parallelismo hanno un rendimento ottimale se le dimensioni di parallelismo sono mappate alle dimensioni della topologia TPU. Si tratta in genere di modelli linguistici di grandi dimensioni (LLM) con parallelismo dei dati e dei modelli. Ad esempio, per una sezione TPU v4 con topologia 8x16x16, le dimensioni della topologia TPU sono 8, 16 e 16. È più efficiente utilizzare il parallelismo dei modelli a 8 vie o 16 vie (mappato a una delle dimensioni della topologia TPU fisica). Un parallelismo dei modelli a 4 vie non sarebbe ottimale con questa topologia, poiché non è allineato a nessuna delle dimensioni della topologia TPU, ma sarebbe ottimale con una topologia 4x16x32 sullo stesso numero di chip.
Le configurazioni TPU v4 sono costituite da due gruppi: quelle con topologie inferiori a 64 chip (topologie piccole) e quelle con topologie superiori a 64 chip (topologie grandi).
Topologie v4 piccole
Cloud TPU supporta le seguenti sezioni TPU v4 più piccole di 64 chip, un cubo 4x4x4. Puoi creare queste piccole topologie v4 utilizzando il nome basato su TensorCore (ad esempio, v4-32) o la topologia (ad esempio, 2x2x4):
| Nome (in base al conteggio di TensorCore) | Numero di chip | Topologia |
| v4-8 | 4 | 2x2x1 |
| v4-16 | 8 | 2x2x2 |
| v4-32 | 16 | 2x2x4 |
| v4-64 | 32 | 2x4x4 |
Topologie v4 grandi
Le sezioni TPU v4 sono disponibili con incrementi di 64 chip, con forme che sono multipli di 4 su tutte e tre le dimensioni. Le dimensioni devono essere in ordine crescente. Nella tabella seguente sono riportati alcuni esempi. Alcune di queste topologie sono topologie "personalizzate" che possono essere create solo utilizzando i flag --type e --topology perché esiste più di un modo per disporre i chip.
| Nome (in base al conteggio di TensorCore) | Numero di chip | Topologia |
| v4-128 | 64 | 4x4x4 |
| v4-256 | 128 | 4x4x8 |
| v4-512 | 256 | 4x8x8 |
topologia personalizzata: devi utilizzare i flag --type e --topology |
256 | 4x4x16 |
| v4-1024 | 512 | 8x8x8 |
| v4-1536 | 768 | 8x8x12 |
| v4-2048 | 1024 | 8x8x16 |
topologia personalizzata: devi utilizzare i flag --type e --topology |
1024 | 4x16x16 |
| v4-4096 | 2048 | 8x16x16 |
| … | … | … |