
TPU7x(Ironwood)
このページでは、 Google Cloudで利用可能な最新の TPU である TPU7x のアーキテクチャと利用可能な構成について説明します。TPU7x は、Ironwood ファミリーの最初のリリースであり、 Google Cloudの第 7 世代 TPU です。Ironwood 世代は、大規模な AI トレーニングと推論向けに設計されています。
Pod あたり 9,216 チップのフットプリントを備えた TPU7x は、TPU v5p と多くの類似点があります。TPU7x は、大規模な密モデルと MoE モデル、事前トレーニング、サンプリング、デコードを多用する推論で高いパフォーマンスを発揮します。
TPU7x を使用するには、Google Kubernetes Engine(GKE)を使用する必要があります。詳細については、GKE での TPU についてをご覧ください。
TPU7x と GKE を TPU Cluster Director で使用することもできます。TPU Cluster Director は、予約容量すべてにアクセスできる(ホールドバックのない)All Capacity モードの予約で使用できます。これにより、TPU ハードウェアのトポロジ、使用率、健全性ステータスを完全に把握できます。詳細については、All Capacity モードの概要をご覧ください。
TPU7x を利用する場合は、アカウント チームにお問い合わせください。
システム アーキテクチャ
各 TPU7x チップには、2 つの TensorCore と 4 つの SparseCore が含まれています。次の表に、TPU7x の主な仕様と値を以前の世代と比較して示します。
| 仕様 | v5p | v6e(Trillium) | TPU7x(Ironwood) |
|---|---|---|---|
| Pod あたりのチップ数 | 8960 | 256 | 9,216 |
| チップあたりのピーク コンピューティング(BF16)(TFLOP) | 459 | 918 | 2,307 |
| チップあたりのピーク コンピューティング(FP8)(TFLOP) | 459 | 918 | 4,614 |
| チップあたりの HBM 容量(GiB) | 95 | 32 | 192 |
| チップあたりの HBM 帯域幅(GB/秒) | 2765 | 1638 | 7,380 |
| vCPU 数(4 チップ VM) | 208 | 180 | 224 |
| RAM(GB)(4 チップ VM) | 448 | 720 | 960 |
| チップあたりの TensorCore の数 | 2 | 1 | 2 |
| チップあたりの SparseCore の数 | 4 | 2 | 4 |
| チップあたりの双方向チップ間相互接続(ICI)帯域幅(GB/秒) | 1200 | 800 | 1200 |
| チップあたりのデータセンター ネットワーク(DCN)帯域幅(Gb/秒) | 50 | 100 | 100 |
次の図は、Ironwood のアーキテクチャを示しています。
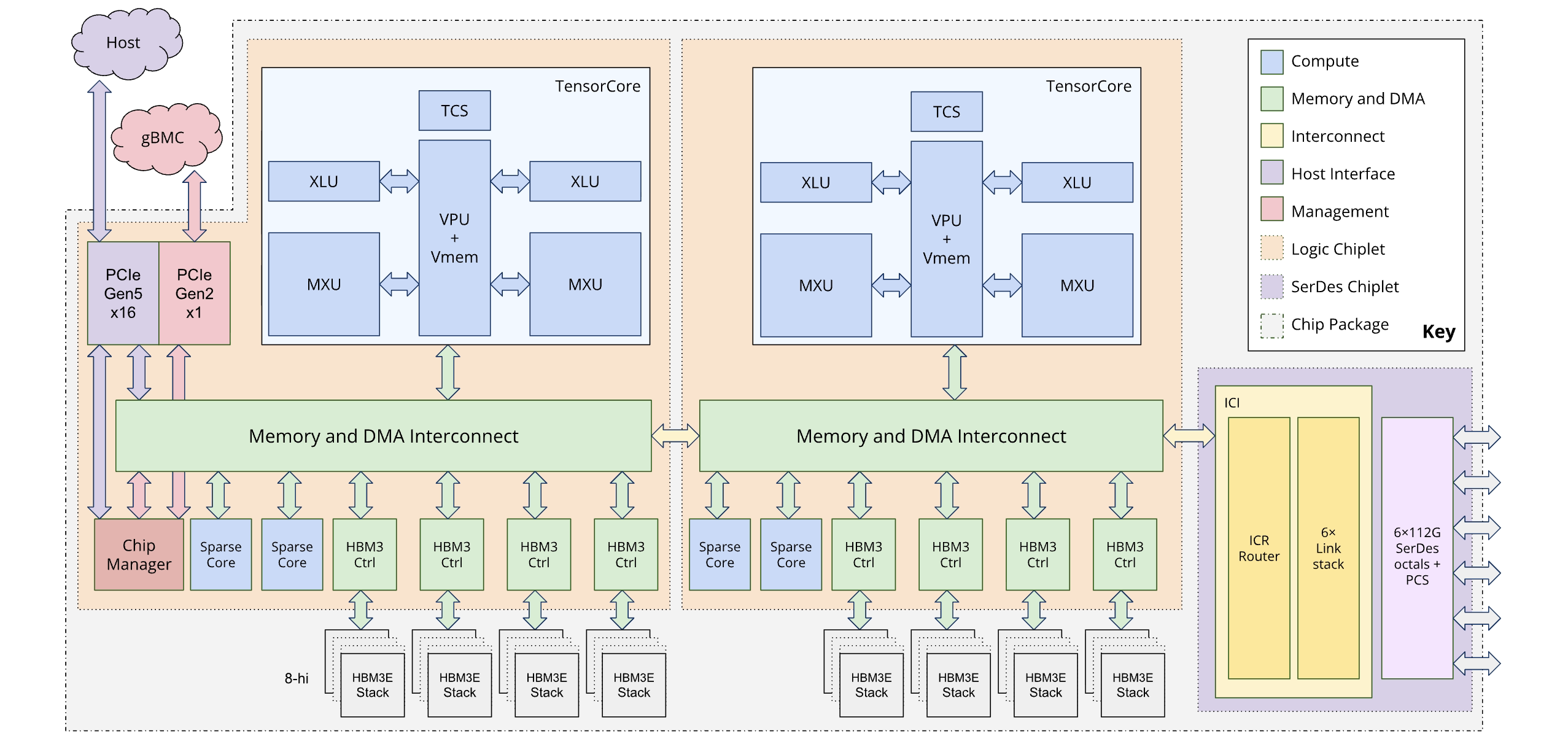
デュアル チップレット アーキテクチャ
Ironwood プログラミング モデルを使用すると、前世代(TPU v4 と v5p)で使用されていた単一の論理コア(MegaCore とも呼ばれます)アーキテクチャではなく、2 つの TPU デバイスにアクセスできます。この変更により、チップ製造の費用対効果と効率が向上します。これはアーキテクチャの変更ですが、新しい設計により、既存のソフトウェア モデルを最小限の変更で再利用できます。
Ironwood TPU は、2 つの異なるチップレットで構成されています。これは、MegaCore アーキテクチャの統合メモリ空間とは異なります。
チップレット構成: 各チップレットは、1 つの TensorCore、2 つの SparseCore、96 GB の高帯域幅メモリ(HBM)を備えた自己完結型のユニットです。
高速相互接続: 2 つのチップレットは、1D チップ間相互接続(ICI)リンクの 6 倍の速度のダイ間(D2D)インターフェースで接続されています。チップレット間の通信は、集合演算を使用して管理されます。
プログラミング モデルとフレームワークの公開
Ironwood のプログラミング モデルは、TPU v3 など、v4 より前の TPU 世代のプログラミング モデルと似ています。新しいアーキテクチャは、次の方法で公開されます。
チップあたり 2 つのデバイス: JAX などのフレームワークは、各 Ironwood チップを 2 つの個別の「デバイス」として公開します(チップレットごとに 1 つ)。
4D トポロジ: JAX は、2 つのオンチップ デバイスのどちらを使用するかを指定するために、トポロジに 4 番目のディメンションを追加します。これにより、既存のソフトウェア モデルを最小限の変更で使用できます。
デュアル チップレット アーキテクチャで最適なパフォーマンスを実現する方法については、Ironwood のデュアル チップレット アーキテクチャのパフォーマンスに関する推奨事項をご覧ください。
サポートされている構成
TPU7x チップは 3 次元の最近傍チップに直接接続され、ネットワーク接続の 3D メッシュを形成します。64 個を超えるチップで構成されるスライスは、1 つ以上の 4x4x4 の「キューブ」チップで構成されます。
次の表に、TPU7x でサポートされている一般的な 3D スライス シェイプを示します。
| トポロジ | TPU チップ | ホスト | VM | キューブ | 範囲 |
|---|---|---|---|---|---|
| 2x2x1 | 4 | 1 | 1 | 1/16 | 単一ホスト |
| 2x2x2 | 8 | 2 | 2 | 1/8 | マルチホスト |
| 2x2x4 | 16 | 4 | 4 | 1/4 | マルチホスト |
| 2x4x4 | 32 | 8 | 8 | 1/2 | マルチホスト |
| 4x4x4 | 64 | 16 | 16 | 1 | マルチホスト |
| 4x4x8 | 128 | 32 | 32 | 2 | マルチホスト |
| 4x8x8 | 256 | 64 | 64 | 4 | マルチホスト |
| 8x8x8 | 512 | 128 | 128 | 8 | マルチホスト |
| 8x8x16 | 1024 | 256 | 256 | 16 | マルチホスト |
| 8x16x16 | 2048 | 512 | 512 | 32 | マルチホスト |
TPU7x VM
各 TPU7x 仮想マシン(VM)には 4 つのチップが含まれています。各 VM は 2 つの NUMA ノードにアクセスできます。NUMA の詳細については、Wikipedia の 不均一メモリアクセスをご覧ください。
すべての TPU7x スライスは、フルホストの 4 チップ VM を使用します。TPU7x VM の技術仕様は次のとおりです。
- VM あたりの vCPU 数: 224
- VM あたりの RAM: 960 GB
- VM あたりの NUMA ノードの数: 2
Hyperdisk
デフォルトでは、TPU7x の VM ブートディスクは Hyperdisk Balanced です。追加のストレージ用に、追加の Hyperdisk Balanced ディスクを TPU VM にアタッチできます。
Hyperdisk の詳細については、Hyperdisk の概要をご覧ください。Cloud TPU のストレージ オプションの詳細については、Cloud TPU データのストレージ オプションをご覧ください。
次のステップ
- GKE で TPU7x を使用する
- TPU Cluster Director で TPU7x を使用する
- Google Cloud ML 診断プラットフォームを使用してワークロードの最適化と診断を行う
- TPU7x 向けに最適化されたレシピを使用してトレーニング ワークロードを実行する
- TPU7x マイクロベンチマークを実行する