
TPU7x (Ironwood)
En esta página se describe la arquitectura y las configuraciones disponibles de TPU7x, la TPU más reciente disponible en Google Cloud. TPU7x es la primera versión de la familia Ironwood,la TPU de séptima generación de Google Cloud. La generación Ironwood se ha diseñado para el entrenamiento y la inferencia de IA a gran escala.
Con una superficie de 9216 chips por pod, TPU7x comparte muchas similitudes con TPU v5p. TPU7x ofrece un alto rendimiento para modelos densos y MoE a gran escala, preentrenamiento, muestreo e inferencia con mucha decodificación.
Para usar TPU7x, debes usar Google Kubernetes Engine (GKE). Para obtener más información, consulta Información sobre las TPUs en GKE.
También puedes usar TPU7x y GKE con TPU Cluster Director. TPU Cluster Director está disponible mediante una reserva en modo All Capacity, que te da acceso completo a toda la capacidad reservada (sin restricciones) y visibilidad total de la topología del hardware de TPU, el estado de utilización y el estado de salud. Para obtener más información, consulta el resumen del modo Capacidad total.
Para acceder a TPU v7, ponte en contacto con el equipo de tu cuenta.
Arquitectura del sistema
Cada chip TPU7x contiene dos TensorCores y cuatro SparseCores. En la siguiente tabla se muestran las especificaciones clave y sus valores de TPU v7 en comparación con las generaciones anteriores.
| Especificaciones | v5p | v6e (Trillium) | TPU7x (Ironwood) |
|---|---|---|---|
| Número de chips por pod | 8960 | 256 | 9216 |
| Rendimiento máximo por chip (BF16) (TFLOPS) | 21. | 918 | 2307 |
| Pico de computación por chip (FP8) (TFLOPS) | 21. | 918 | 4614 |
| Capacidad de HBM por chip (GiB) | 95 | 32 | 192 |
| Ancho de banda de HBM por chip (GB/s) | 2765 | 1638 | 7380 |
| Número de vCPUs (VM de 4 chips) | 208 | 180 | 224 |
| RAM (GB) (VM de 4 chips) | 448 | 720 | 960 |
| Número de Tensor Cores por chip | 2 | 1 | 2 |
| Número de SparseCores por chip | 4 | 2 | 4 |
| Ancho de banda de interconexión entre chips (ICI) bidireccional por chip (GBps) | 1200 | 800 | 1200 |
| Ancho de banda de la red del centro de datos (DCN) por chip (Gbps) | 50 | 100 | 100 |
En el siguiente diagrama se muestra la arquitectura de Ironwood:
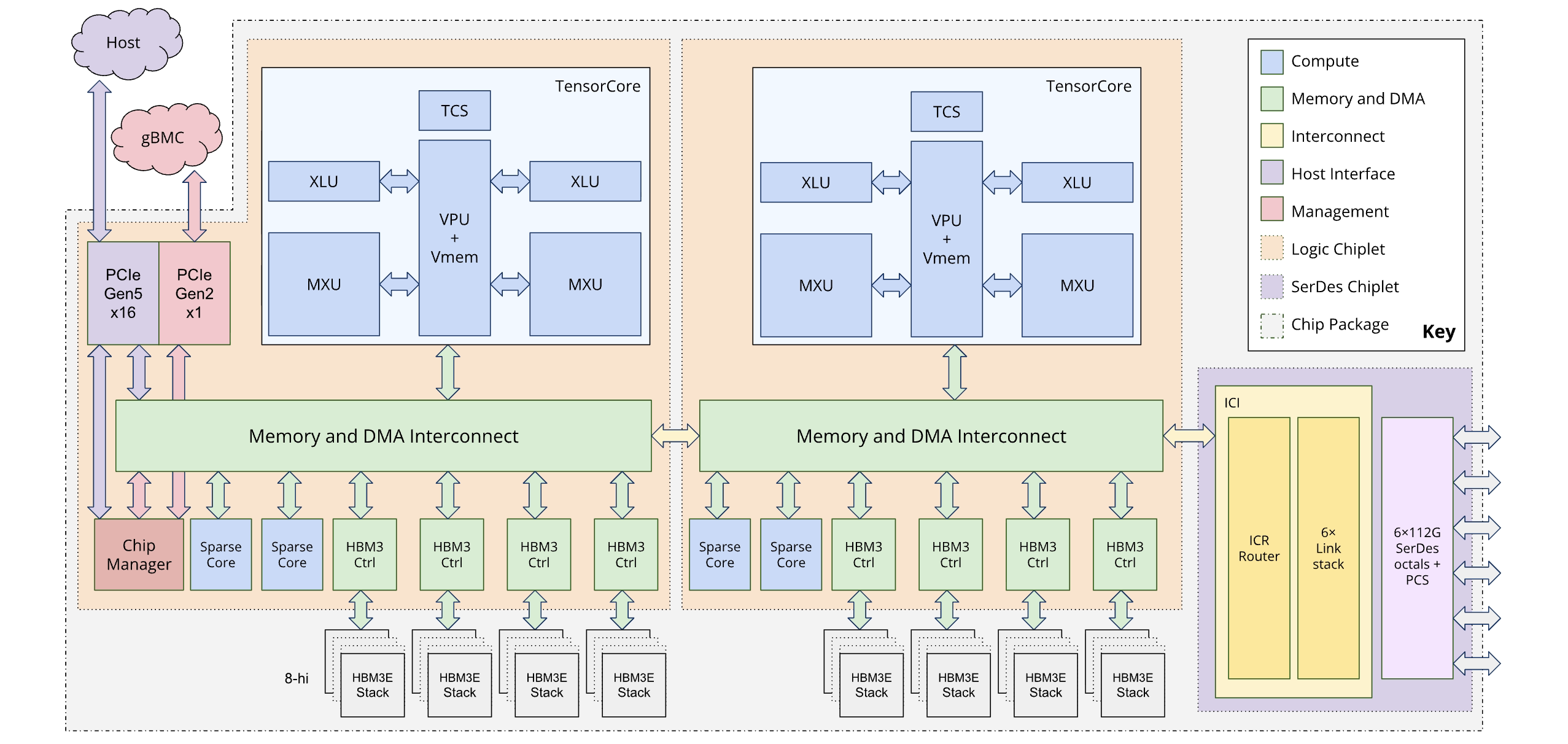
Arquitectura de doble chiplet
El modelo de programación de Ironwood te permite acceder a dos dispositivos de TPU en lugar de a la arquitectura de un solo núcleo lógico (también conocido como MegaCore) que se usaba en generaciones anteriores (TPU v4 y v5p). Este cambio mejora la rentabilidad y la eficiencia de la fabricación del chip. Aunque esto supone un cambio en la arquitectura, el nuevo diseño te permite reutilizar los modelos de software actuales con cambios mínimos.
Las TPUs Ironwood se componen de dos chiplets distintos. Esto supone un cambio con respecto al espacio de memoria unificado de la arquitectura MegaCore.
Composición de los chiplets: cada chiplet es una unidad independiente con un Tensor Core, dos Sparse Cores y 96 GB de memoria de alto ancho de banda (HBM).
Interconexión de alta velocidad: los dos chiplets están conectados por una interfaz de chip a chip (D2D) seis veces más rápida que un enlace de interconexión entre chips (ICI) 1D. La comunicación entre chiplets se gestiona mediante operaciones colectivas.
Exposición del modelo de programación y del framework
El modelo de programación de Ironwood es similar al de las generaciones de TPU anteriores a la versión 4, como la versión 3. La nueva arquitectura se expone de las siguientes formas:
Dos dispositivos por chip: frameworks como JAX exponen cada chip Ironwood como dos "dispositivos" independientes, uno por cada chiplet.
Topología 4D: JAX añade una cuarta dimensión a la topología para especificar cuál de los dos dispositivos en el chip se debe usar. De esta forma, puedes usar modelos de software con mínimas modificaciones.
Para obtener más información sobre cómo conseguir un rendimiento óptimo con la arquitectura de doble chiplet, consulta las recomendaciones de rendimiento para la arquitectura de doble chiplet de Ironwood.
Configuraciones admitidas
Los chips TPU7x tienen una conexión directa con los chips vecinos más cercanos en 3 dimensiones, lo que da como resultado una malla 3D de conexiones de red. Los segmentos de más de 64 chips se componen de uno o varios "cubos" de chips de 4x4x4.
En la siguiente tabla se muestran las formas de sectores 3D habituales que se admiten en TPU v7:
| Topología | Chips de TPU | Hosts | VMs | Cubos | Ámbito |
|---|---|---|---|---|---|
| 2x2x1 | 4 | 1 | 1 | 1/16 | Un solo host |
| 2x2x2 | 8 | 2 | 2 | 1/8 | Varios hosts |
| 2x2x4 | 16 | 4 | 4 | 1/4 | Varios hosts |
| 2x4x4 | 32 | 8 | 8 | 1/2 | Varios hosts |
| 4x4x4 | 64 | 16 | 16 | 1 | Varios hosts |
| 4x4x8 | 128 | 32 | 32 | 2 | Varios hosts |
| 4x8x8 | 256 | 64 | 64 | 4 | Varios hosts |
| 8x8x8 | 512 | 128 | 128 | 8 | Varios hosts |
| 8x8x16 | 1024 | 256 | 256 | 16 | Varios hosts |
| 8x16x16 | 2048 | 512 | 512 | 32 | Varios hosts |
Máquina virtual TPU7x
Cada máquina virtual (VM) TPU7x contiene 4 chips. Cada máquina virtual tiene acceso a dos nodos NUMA. Para obtener más información sobre los nodos NUMA, consulta Acceso a memoria no uniforme en Wikipedia.
Todas las slices de TPU v7 usan VMs de 4 chips de host completo. Las especificaciones técnicas de una VM TPU7x son las siguientes:
- Número de vCPUs por VM: 224
- RAM por VM: 960 GB
- Número de nodos NUMA por VM: 2
Hyperdisk
De forma predeterminada, el disco de arranque de la máquina virtual de TPU7x es Hyperdisk Balanced. Puedes conectar discos Hyperdisk Balanced adicionales a tu VM de TPU para tener más almacenamiento.
Para obtener más información sobre Hyperdisk, consulta el artículo Introducción a Hyperdisk. Para obtener más información sobre las opciones de almacenamiento de las TPU de Cloud, consulta Opciones de almacenamiento de datos de TPU de Cloud.
Siguientes pasos
- Usar TPU7x con GKE
- Usar TPU7x con TPU Cluster Director
- Utilizar la plataforma Google Cloud Diagnóstico de aprendizaje automático para optimizar y diagnosticar sus cargas de trabajo
- Ejecutar una carga de trabajo de entrenamiento con una receta optimizada para TPU7x
- Ejecutar una microprueba comparativa de TPU v7