
TPU7x (Ironwood)
Auf dieser Seite werden die Architektur und die verfügbaren Konfigurationen für TPU7x beschrieben, die neueste TPU, die auf Google Cloudverfügbar ist. TPU7x ist die erste Version der Ironwood-Familie,der siebten Generation von TPUs von Google Cloud. Die Ironwood-Generation ist für umfangreiches KI-Training und ‑Inferenz konzipiert.
Mit 9.216 Chips pro Pod ähnelt die TPU7x-Architektur der TPU v5p. TPU7x bietet eine hohe Leistung für umfangreiche dichte und MoE-Modelle, Vortraining, Sampling und Inferenz mit hohem Decodierungsaufwand.
Wenn Sie TPU7x verwenden möchten, können Sie Google Kubernetes Engine (GKE) oder Compute Engine nutzen. Weitere Informationen zur Verwendung von TPUs mit GKE finden Sie unter TPUs in GKE.
Sie können auch TPU7x und GKE im Modus „All Capacity“ verwenden. Der Modus „Alle Kapazitäten“ ist über eine Reservierung im Modus „Alle Kapazitäten“ verfügbar. Damit erhalten Sie vollen Zugriff auf alle Ihre reservierten Kapazitäten (keine Einschränkungen) und vollständigen Einblick in die TPU-Hardwaretopologie, den Auslastungsstatus und den Zustand. Weitere Informationen finden Sie unter Übersicht über den Modus „Alle Kapazitäten“.
Systemarchitektur
Jeder TPU7x-Chip enthält zwei TensorCores und vier SparseCores. In der folgenden Tabelle sind die wichtigsten Spezifikationen und ihre Werte für TPU7x im Vergleich zu früheren Generationen aufgeführt.
| Spezifikation | v5p | v6e (Trillium) | TPU7x (Ironwood) |
|---|---|---|---|
| Anzahl der Chips pro Pod | 8960 | 256 | 9216 |
| Maximale Rechenleistung pro Chip (BF16) (TFLOPs) | 459 | 918 | 2307 |
| Maximale Rechenleistung pro Chip (FP8) (TFLOPs) | 459 | 918 | 4614 |
| HBM-Kapazität pro Chip (GiB) | 95 | 32 | 192 |
| HBM-Bandbreite pro Chip (GB/s) | 2765 | 1638 | 7380 |
| Anzahl der vCPUs (VM mit 4 Chips) | 208 | 180 | 224 |
| RAM (GB) (VM mit 4 Chips) | 448 | 720 | 960 |
| Anzahl der TensorCores pro Chip | 2 | 1 | 2 |
| Anzahl der SparseCores pro Chip | 4 | 2 | 4 |
| Bidirektionale ICI-Bandbreite (Inter-Chip Interconnect) pro Chip (GBps) | 1.200 | 800 | 1.200 |
| Bandbreite des Rechenzentrumsnetzwerks (Data Center Network, DCN) pro Chip (Gbit/s) | 50 | 100 | 100 |
Das folgende Diagramm veranschaulicht die Architektur von Ironwood:
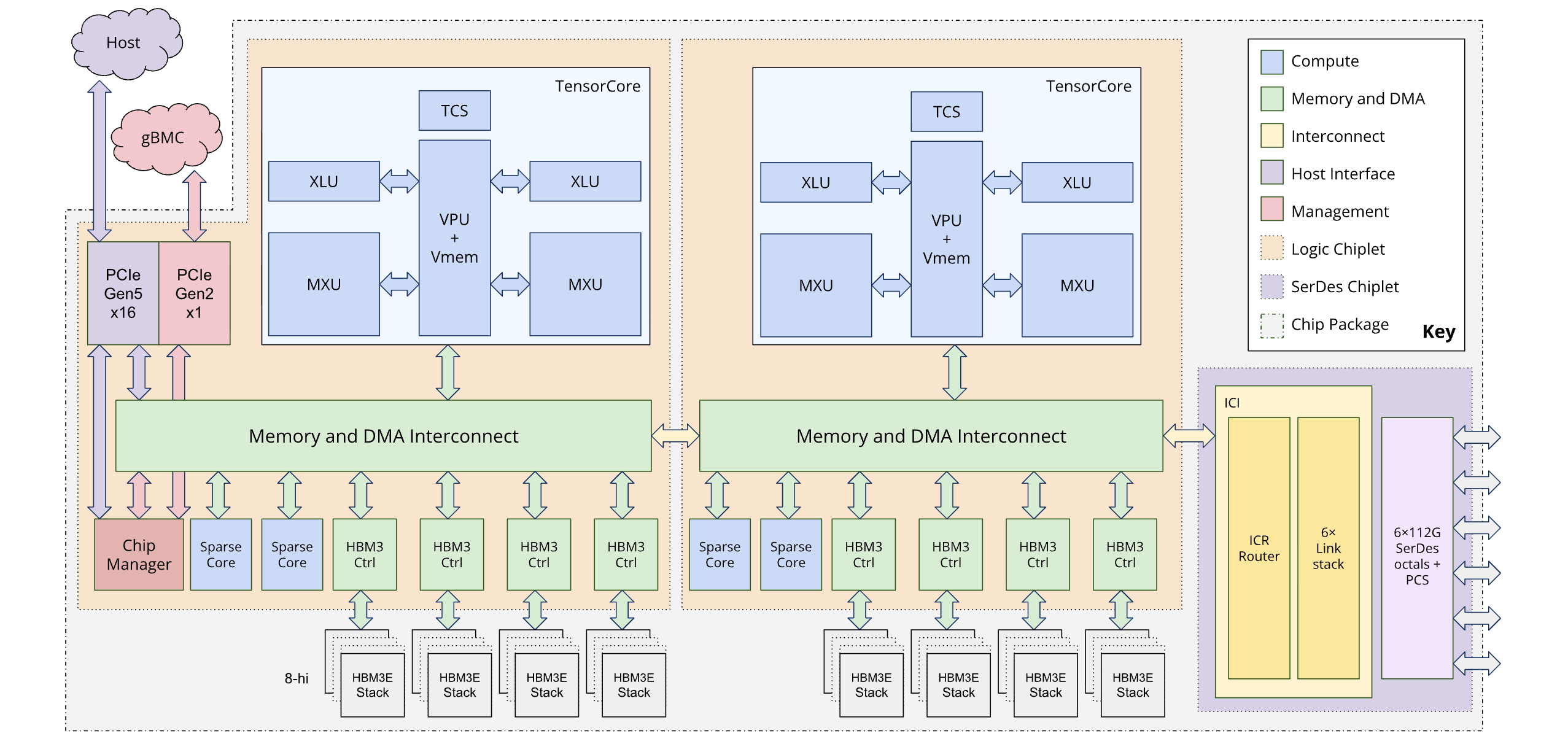
Speicherhierarchie
TPU7x verfügt über ein mehrstufiges Speichersystem. Die Verwaltung der Datenübertragung zwischen diesen Ebenen ist entscheidend für die Leistung:
- Speicher mit hoher Bandbreite (High-Bandwidth Memory, HBM): Jeder Chip ist mit 192 GB HBM ausgestattet, mit einer Bandbreite von etwa 7,37 TB/s. Die große HBM-Kapazität ermöglicht große Batchgrößen, was den Durchsatz verbessern kann. Trotz seiner Größe kann HBM jedoch immer noch ein Engpass sein, insbesondere bei speichergebundenen Vektoroperationen oder ineffizienten Datenzugriffsmustern.
- Vektorspeicher (Vector Memory, VMEM): VMEM ist ein kleinerer On-Chip-SRAM (Static Random-Access Memory) mit einer deutlich höheren Bandbreite zur Matrix Multiply Unit (MXU) als HBM. Dieser Speicher dient als schneller Scratchpad für benutzerdefinierte Kernel. Die Größe dieses Puffers ist ein abstimmbarer Parameter. Die Optimierung der Puffergröße ist entscheidend für die Optimierung benutzerdefinierter Pallas-Kernel, da ihre Blockgrößen oft durch den verfügbaren VMEM begrenzt werden.
- Hostspeicher und PCIe:Jeder Satz von vier TPU-Chips ist über ein PCIe-Netzwerk mit einem CPU-Host verbunden. Diese Verbindung hat zwar eine viel geringere Bandbreite als HBM, der Hauptspeicher des Hosts kann jedoch zum Auslagern von Aktivierungen oder Optimierungsstatus verwendet werden, um HBM freizugeben. Diese Technik ist besonders nützlich, um den Speicherdruck bei großen Modellen zu verringern.
Weitere Informationen zum effizienten Verwalten von Datenübertragungen zwischen den Ebenen der TPU7x-Speicherhierarchie finden Sie unter Leistungsoptimierungen für Ironwood.
Dual-Chiplet-Architektur
Mit dem Ironwood-Programmiermodell können Sie auf zwei TPU-Chiplets zugreifen anstelle eines einzelnen logischen Kerns (auch als MegaCore bezeichnet), der in früheren Generationen (TPU v4 und v5p) verwendet wurde. Diese Änderung verbessert die Kosteneffizienz und Effizienz der Chipherstellung. Das neue Design stellt zwar eine architektonische Umstellung dar, sorgt aber dafür, dass Sie vorhandene Softwaremodelle mit minimalen Änderungen wiederverwenden können.
Ironwood-TPUs bestehen aus zwei separaten Chiplets mit jeweils eigenem dedizierten Speicherplatz. Das ist eine Abweichung vom einheitlichen Speicherplatz der MegaCore-Architektur.
Chiplet-Zusammensetzung: Jedes Chiplet ist eine in sich geschlossene Einheit mit einem TensorCore, zwei SparseCores und 96 GB High-Bandwidth Memory (HBM).
Hochgeschwindigkeitsverbindung: Die beiden Chiplets sind über eine Die-to-Die-Schnittstelle (D2D) verbunden, die sechsmal schneller ist als eine 1D-Inter-Chip-Interconnect-Verbindung (ICI). Die Kommunikation zwischen Chiplets wird über kollektive Vorgänge verwaltet.
Programmiermodell und Framework-Offenlegung
Das Programmiermodell für Ironwood ähnelt dem von TPU-Generationen vor v4, z. B. TPU v3. Die neue Architektur wird auf folgende Weise verfügbar gemacht:
Zwei Geräte pro Chip:Frameworks wie JAX machen jeden Ironwood-Chip als zwei separate „Geräte“ verfügbar, eines für jedes Chiplet.
Chiplet-Spezifikation:Sie können angeben, welches Chiplet für eine Berechnung verwendet werden soll. JAX fügt der Topologiespezifikation eine vierte Dimension hinzu, um zwischen Chiplets zu unterscheiden. So können Sie vorhandene Softwaremodelle mit minimalen Änderungen wiederverwenden.
Weitere Informationen zur optimalen Leistung mit der Dual-Chiplet-Architektur finden Sie unter Leistungsempfehlungen für die Dual-Chiplet-Architektur von Ironwood.
Unterstützte Konfigurationen
TPU7x-Chips haben eine direkte Verbindung zu den nächstgelegenen benachbarten Chips in 3 Dimensionen, was zu einem 3D-Mesh von Netzwerkverbindungen führt. Slices mit mehr als 64 Chips bestehen aus einem oder mehreren 4 × 4 × 4-Cubes von Chips.
TPU7x-Chips haben eine 3D-Torus-Interconnect-Topologie. Mit dieser Topologie können Slices auf bis zu 9.216 Chips skaliert werden. Sie hat eine bidirektionale Bandbreite von 200 GBps pro Achse für die Kommunikation zwischen Chips innerhalb eines Pods.
In der folgenden Tabelle sind die gängigen 3D-Slice-Formen aufgeführt, die für TPU7x unterstützt werden:
| Topologie | TPU-Chips | Hosts | VMs | Cubes | Umfang |
|---|---|---|---|---|---|
| 2x2x1 | 4 | 1 | 1 | 1/16 | Einzelner Host |
| 2x2x2 | 8 | 2 | 2 | 1/8 | Mehrere Hosts |
| 2x2x4 | 16 | 4 | 4 | 1/4 | Mehrere Hosts |
| 2x4x4 | 32 | 8 | 8 | 1/2 | Mehrere Hosts |
| 4x4x4 | 64 | 16 | 16 | 1 | Mehrere Hosts |
| 4 x 4 x 8 | 128 | 32 | 32 | 2 | Mehrere Hosts |
| 4 x 8 x 8 | 256 | 64 | 64 | 4 | Mehrere Hosts |
| 8 x 8 x 8 | 512 | 128 | 128 | 8 | Mehrere Hosts |
| 8 x 8 x 16 | 1.024 | 256 | 256 | 16 | Mehrere Hosts |
| 8 x 16 x 16 | 2.048 | 512 | 512 | 32 | Mehrere Hosts |
TPU7x-VM
Jede TPU7x-VM enthält 4 Chips. Jede VM hat Zugriff auf zwei NUMA-Knoten. Weitere Informationen zu NUMA-Knoten finden Sie im Wikipedia-Artikel zu Non-Uniform Memory Access.
Für alle TPU7x-Slices werden Full-Host-VMs mit 4 Chips verwendet. Die technischen Spezifikationen für eine TPU7x-VM sind:
- Anzahl der vCPUs pro VM: 224
- RAM pro VM: 960 GB
- Anzahl der NUMA-Knoten pro VM: 2
Hyperdisk
Standardmäßig ist das VM-Bootlaufwerk für TPU7x Hyperdisk Balanced. Sie können Ihrer TPU-VM weitere Laufwerke für zusätzlichen Speicherplatz hinzufügen. Die folgenden Laufwerkstypen werden auf TPU7x unterstützt:
- Hyperdisk Balanced
- Hyperdisk ML
Weitere Informationen zu Hyperdisk finden Sie unter Hyperdisk – Übersicht. Weitere Informationen zu Speicheroptionen für Cloud TPU finden Sie unter Speicheroptionen für Cloud TPU-Daten.
Nächste Schritte
- TPU7x mit GKE verwenden
- TPU7x im Modus „All Capacity“ verwenden
- Google Cloud ML Diagnostics-Plattform zum Optimieren und Diagnostizieren Ihrer Arbeitslasten verwenden
- Trainings-Workload mit einem für TPU7x optimierten Rezept ausführen
- TPU7x-Microbenchmark ausführen
- Leistungsoptimierungen in Ironwood
- Umfangreiche Modelle für maschinelles Lernen in GKE mit Multi-Tier Checkpointing trainieren