
TPU7x (Ironwood)
Cette page décrit l'architecture et les configurations disponibles pour TPU7x, le dernier TPU disponible sur Google Cloud. TPU7x est la première version de la famille Ironwood,le TPU de septième génération de Google Cloud. La génération Ironwood est conçue pour l'entraînement et l'inférence d'IA à grande échelle.
Avec une empreinte de 9 216 puces par pod, TPU7x présente de nombreuses similitudes avec TPU v5p. TPU7x offre des performances élevées pour les modèles denses et MoE à grande échelle, le pré-entraînement, l'échantillonnage et l'inférence intensive en décodage.
Pour utiliser TPU7x, vous pouvez utiliser Google Kubernetes Engine (GKE) ou Compute Engine. Pour en savoir plus sur l'utilisation des TPU avec GKE, consultez À propos des TPU dans GKE.
Vous pouvez également utiliser TPU7x et GKE avec le mode "Toute capacité". Le mode "Toute la capacité" est disponible via une réservation en mode "Toute la capacité". Il vous donne un accès complet à toute votre capacité réservée (sans retenue) et une visibilité totale sur la topologie matérielle des TPU, l'état d'utilisation et l'état de fonctionnement. Pour en savoir plus, consultez Présentation du mode "Toute capacité".
Architecture du système
Chaque puce TPU7x contient deux TensorCores et quatre SparseCores. Le tableau suivant présente les principales spécifications et leurs valeurs pour les TPU 7x par rapport aux générations précédentes.
| Spécification | v5p | v6e (Trillium) | TPU7x (Ironwood) |
|---|---|---|---|
| Nombre de puces par pod | 8 960 | 256 | 9216 |
| Puissance de calcul maximale par puce (BF16) (TFLOPS) | 459 | 918 | 2307 |
| Puissance de calcul maximale par puce (FP8) (TFLOPS) | 459 | 918 | 4614 |
| Capacité de mémoire HBM par puce (Gio) | 95 | 32 | 192 |
| Bande passante HBM par puce (Go/s) | 2765 | 1638 | 7380 |
| Nombre de vCPU (VM à quatre puces) | 208 | 180 | 224 |
| RAM (Go) (VM à quatre puces) | 448 | 720 | 960 |
| Nombre de TensorCores par puce | 2 | 1 | 2 |
| Nombre de SparseCores par puce | 4 | 2 | 4 |
| Bande passante d'interconnexion bidirectionnelle entre puces (ICI) par puce (GBps) | 1200 | 800 | 1200 |
| Bande passante réseau de centre de données (DCN) par puce (Gbit/s) | 50 | 100 | 100 |
Le schéma suivant illustre l'architecture d'Ironwood :
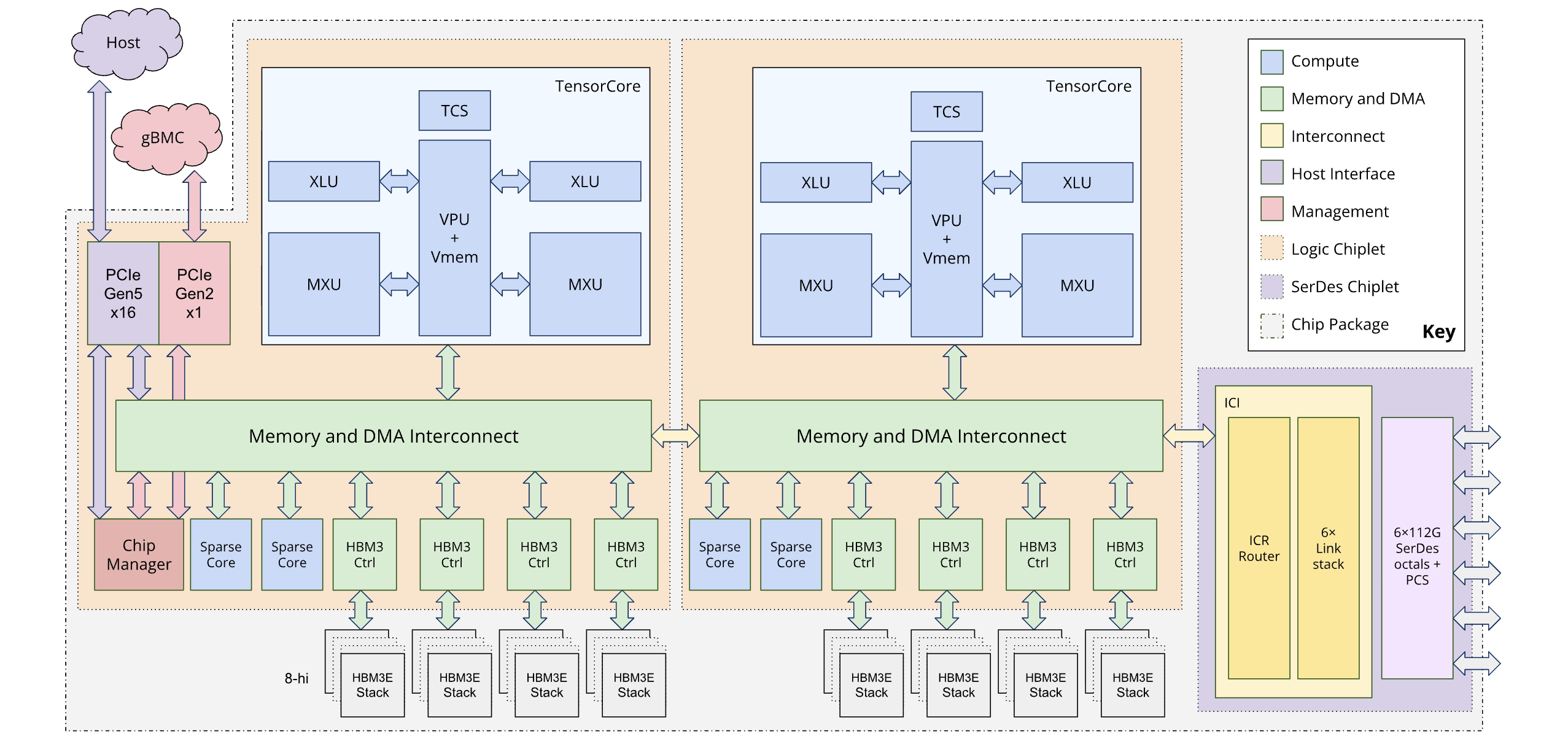
Hiérarchie de la mémoire
Le TPU v7x dispose d'un système de mémoire à plusieurs niveaux. La gestion du transfert de données entre ces niveaux est essentielle pour les performances :
- Mémoire à haut débit (HBM) : chaque puce est équipée de 192 Go de mémoire HBM, avec une bande passante d'environ 7,37 To/s. La grande capacité HBM permet d'utiliser des tailles de lot importantes, ce qui peut améliorer le débit. Toutefois, malgré sa taille, la HBM peut toujours être un goulot d'étranglement, en particulier pour les opérations vectorielles liées à la mémoire ou les modèles d'accès aux données inefficaces.
- Mémoire vectorielle (VMEM) : la VMEM est une SRAM (mémoire vive statique) intégrée plus petite, avec une bande passante beaucoup plus élevée vers l'unité de multiplication matricielle (MXU) que la HBM. Cette mémoire sert de bloc-notes haute vitesse pour les noyaux personnalisés. La taille de cette mémoire tampon est un paramètre ajustable. L'optimisation de la taille du tampon est essentielle pour ajuster les noyaux Pallas personnalisés, car leurs tailles de bloc sont souvent limitées par la VMEM disponible.
- Mémoire hôte et PCIe : chaque ensemble de quatre puces TPU est connecté à un hôte de processeur à l'aide d'un réseau PCIe. Bien que cette connexion ait une bande passante beaucoup plus faible que la HBM, la mémoire principale de l'hôte peut être utilisée pour décharger les activations ou les états de l'optimiseur afin de libérer de la HBM. Cette technique est particulièrement utile pour gérer la pression de la mémoire dans les grands modèles.
Pour en savoir plus sur la gestion efficace des transferts de données entre les niveaux de la hiérarchie de mémoire TPU7x, consultez Optimisations des performances d'Ironwood.
Architecture à double chiplet
Le modèle de programmation Ironwood vous permet d'accéder à deux chiplets TPU au lieu d'un seul cœur logique (également appelé architecture MegaCore) utilisé dans les générations précédentes (TPU v4 et v5p). Ce changement améliore la rentabilité et l'efficacité de la fabrication du chip. Bien que cela représente un changement d'architecture, la nouvelle conception vous permet de réutiliser les modèles logiciels existants avec un minimum de modifications.
Les TPU Ironwood sont composés de deux chiplets distincts, chacun avec son propre espace mémoire dédié. Cela diffère de l'espace mémoire unifié de l'architecture MegaCore.
Composition des chiplets : chaque chiplet est une unité autonome avec un TensorCore, deux SparseCores et 96 Go de mémoire à haut débit (HBM).
Interconnexion à haut débit : les deux chiplets sont connectés par une interface die-to-die (D2D) six fois plus rapide qu'une liaison d'interconnexion inter-puces (ICI) 1D. La communication entre les chiplets est gérée à l'aide d'opérations collectives.
Exposition du modèle et du framework de programmation
Le modèle de programmation pour Ironwood est semblable à celui des générations de TPU antérieures à la v4, comme le TPU v3. La nouvelle architecture est exposée de différentes manières :
Deux appareils par puce : les frameworks tels que JAX exposent chaque puce Ironwood sous la forme de deux "appareils" distincts, un pour chaque chiplet.
Spécification du chiplet : vous pouvez spécifier le chiplet à utiliser pour un calcul. JAX ajoute une quatrième dimension à la spécification de la topologie pour faire la distinction entre les chiplets. Cette conception vous permet de réutiliser les modèles logiciels existants avec un minimum de modifications.
Pour en savoir plus sur l'obtention de performances optimales avec l'architecture à double chiplet, consultez Recommandations de performances pour l'architecture à double chiplet d'Ironwood.
Configurations compatibles
Les puces TPU7x sont directement connectées aux puces voisines les plus proches en trois dimensions, ce qui crée un maillage 3D de connexions réseau. Les tranches de plus de 64 puces sont constituées d'un ou de plusieurs "cubes" 4x4x4 de puces.
Les puces TPU7x disposent d'une topologie d'interconnexion en tore 3D. Cette topologie permet aux tranches de passer à 9 216 puces. Il dispose d'une bande passante bidirectionnelle de 200 Go/s par axe pour la communication entre les puces d'un même pod.
Le tableau suivant présente les formes de tranche 3D courantes compatibles avec TPU7x :
| Topologie | Puces TPU | Hôtes | VM | Cubes | Champ d'application |
|---|---|---|---|---|---|
| 2x2x1 | 4 | 1 | 1 | 1/16 | Hôte unique |
| 2x2x2 | 8 | 2 | 2 | 1/8 | Multi-hôtes |
| 2x2x4 | 16 | 4 | 4 | 1/4 | Multi-hôtes |
| 2x4x4 | 32 | 8 | 8 | 1/2 | Multi-hôtes |
| 4x4x4 | 64 | 16 | 16 | 1 | Multi-hôtes |
| 4x4x8 | 128 | 32 | 32 | 2 | Multi-hôtes |
| 4x8x8 | 256 | 64 | 64 | 4 | Multi-hôtes |
| 8x8x8 | 512 | 128 | 128 | 8 | Multi-hôtes |
| 8x8x16 | 1 024 | 256 | 256 | 16 | Multi-hôtes |
| 8x16x16 | 2 048 | 512 | 512 | 32 | Multi-hôtes |
VM TPU7x
Chaque machine virtuelle (VM) TPU7x contient quatre puces. Chaque VM a accès à deux nœuds NUMA. Pour en savoir plus sur les nœuds NUMA, consultez Non-uniform memory access sur Wikipédia.
Toutes les tranches TPU7x utilisent des VM à hôte complet et à quatre puces. Voici les caractéristiques techniques d'une VM TPU v7 x :
- Nombre de processeurs virtuels par VM : 224
- RAM par VM : 960 Go
- Nombre de nœuds NUMA par VM : 2
Hyperdisk
Par défaut, le disque de démarrage de la VM pour TPU7x est Hyperdisk Balanced. Vous pouvez associer d'autres disques à votre VM TPU pour obtenir de l'espace de stockage supplémentaire. Les types de disques suivants sont compatibles avec les TPU7x :
- Volume Hyperdisk équilibré
- Hyperdisk ML
Pour en savoir plus sur Hyperdisk, consultez Présentation d'Hyperdisk. Pour en savoir plus sur les options de stockage pour Cloud TPU, consultez Options de stockage pour les données Cloud TPU.
Étapes suivantes
- Utiliser TPU7x avec GKE
- Utiliser TPU7x avec le mode "Toute la capacité"
- Utilisez la plate-forme Google Cloud ML Diagnostics pour optimiser et diagnostiquer vos charges de travail.
- Exécuter une charge de travail d'entraînement à l'aide d'une recette optimisée pour TPU7x
- Exécuter un microbenchmark TPU7x
- Optimisations des performances d'Ironwood
- Entraîner des modèles de machine learning à grande échelle sur GKE avec le checkpointing multicouche