
TPU7x (Ironwood)
Questa pagina descrive l'architettura e le configurazioni disponibili per TPU7x, l'ultima TPU disponibile su Google Cloud. TPU7x è la prima release della famiglia Ironwood, Google Cloudla TPU di settima generazione. La generazione Ironwood è progettata per l'addestramento e l'inferenza dell'AI su larga scala.
Con un footprint di 9216 chip per pod, TPU7x condivide molte somiglianze con TPU v5p. TPU7x offre prestazioni elevate per modelli densi e MoE su larga scala, preaddestramento, campionamento e inferenza con decodifica pesante.
Per utilizzare TPU7x, puoi utilizzare Google Kubernetes Engine (GKE) o Compute Engine. Per maggiori informazioni sull'utilizzo delle TPU con GKE, consulta Informazioni sulle TPU in GKE.
Puoi anche utilizzare TPU7x e GKE con la modalità All Capacity. La modalità All Capacity è disponibile tramite una prenotazione in modalità All Capacity , che ti offre l'accesso completo a tutta la capacità prenotata (senza limitazioni) e la piena visibilità della topologia hardware TPU, dello stato di utilizzo e dello stato di integrità. Per saperne di più, consulta la panoramica della modalità Tutta la capacità.
Architettura di sistema
Ogni chip TPU7x contiene due TensorCore e quattro SparseCore. La tabella seguente mostra le specifiche chiave e i relativi valori per TPU7x rispetto alle generazioni precedenti.
| Specifica | v5p | v6e (Trillium) | TPU7x (Ironwood) |
|---|---|---|---|
| Numero di chip per pod | 8960 | 256 | 9216 |
| Picco di calcolo per chip (BF16) (TFLOP) | 459 | 918 | 2307 |
| Picco di calcolo per chip (FP8) (TFLOP) | 459 | 918 | 4614 |
| Capacità HBM per chip (GiB) | 95 | 32 | 192 |
| Larghezza di banda HBM per chip (GBps) | 2765 | 1638 | 7380 |
| Numero di vCPU (VM a 4 chip) | 208 | 180 | 224 |
| RAM (GB) (VM a 4 chip) | 448 | 720 | 960 |
| Numero di Tensor Core per chip | 2 | 1 | 2 |
| Numero di SparseCore per chip | 4 | 2 | 4 |
| Larghezza di banda bidirezionale Inter-Chip Interconnect (ICI) per chip (GBps) | 1200 | 800 | 1200 |
| Larghezza di banda della rete del data center (DCN) per chip (Gbps) | 50 | 100 | 100 |
Il seguente diagramma illustra l'architettura di Ironwood:
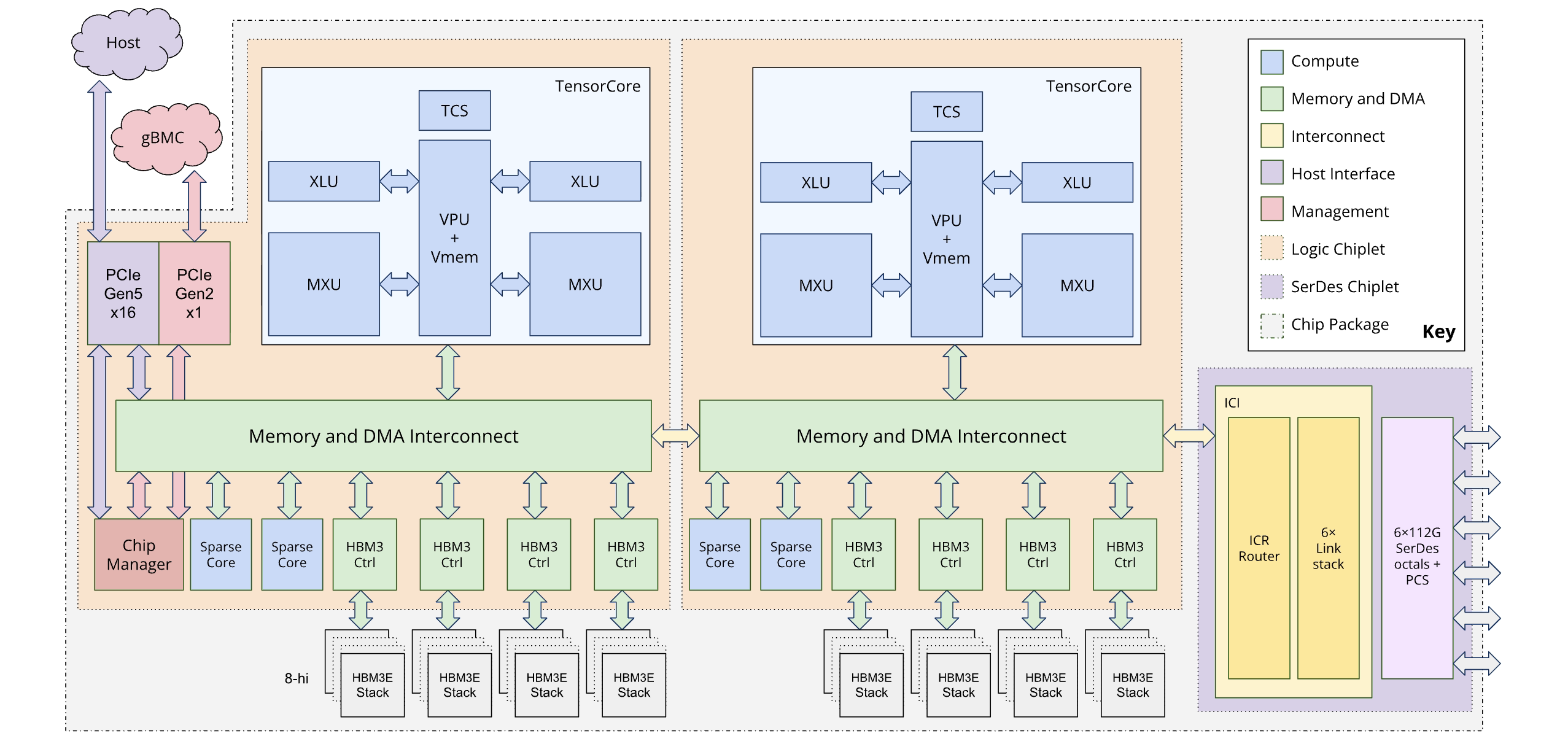
Gerarchia della memoria
TPU7x è dotato di un sistema di memoria a più livelli e la gestione del movimento dei dati tra questi livelli è fondamentale per le prestazioni:
- Memoria a larghezza di banda elevata (HBM): ogni chip è dotato di 192 GB di HBM, con una larghezza di banda di circa 7,37 TB/s. L'ampia capacità HBM consente dimensioni dei batch elevate, che possono migliorare il throughput. Tuttavia, nonostante le sue dimensioni, l'HBM può comunque rappresentare un collo di bottiglia, in particolare per le operazioni vettoriali con vincoli di memoria o per pattern di accesso ai dati inefficienti.
- Memoria vettoriale (VMEM): VMEM è una SRAM (static random-access memory) on-chip più piccola con una larghezza di banda significativamente superiore all'unità di moltiplicazione a matrice (MXU) rispetto alla HBM. Questa memoria funge da blocco note ad alta velocità per i kernel personalizzati. Le dimensioni di questo buffer sono un parametro regolabile. L'ottimizzazione delle dimensioni del buffer è fondamentale per la messa a punto dei kernel Pallas personalizzati, poiché le dimensioni dei blocchi sono spesso limitate dalla VMEM disponibile.
- Memoria host e PCIe: ogni set di quattro chip TPU è connesso a un host CPU tramite una rete PCIe. Sebbene questa connessione abbia una larghezza di banda molto inferiore rispetto all'HBM, la memoria principale dell'host può essere utilizzata per scaricare le attivazioni o gli stati dell'ottimizzatore per liberare HBM, una tecnica particolarmente utile per gestire la pressione della memoria nei modelli di grandi dimensioni.
Per saperne di più sulla gestione efficiente dello spostamento dei dati tra i livelli della gerarchia di memoria TPU7x, consulta Ottimizzazioni delle prestazioni di Ironwood.
Architettura dual-chiplet
Il modello di programmazione Ironwood consente di accedere a due chiplet TPU anziché a un'architettura a singolo core logico (nota anche come MegaCore) utilizzata nelle generazioni precedenti (TPU v4 e v5p). Questa modifica migliora l'efficacia in termini di costi e l'efficienza della produzione del chip. Sebbene ciò rappresenti un cambiamento architettonico, il nuovo design garantisce che tu possa riutilizzare i modelli software esistenti con modifiche minime.
Le TPU Ironwood sono composte da due chiplet distinti, ognuno con il proprio spazio di memoria dedicato. Si tratta di un'eccezione allo spazio di memoria unificato dell'architettura MegaCore.
Composizione dei chiplet: ogni chiplet è un'unità autonoma con un TensorCore, due SparseCore e 96 GB di memoria ad alta larghezza di banda (HBM).
Interconnessione ad alta velocità: i due chiplet sono collegati da un'interfaccia die-to-die (D2D) sei volte più veloce di un collegamento di interconnessione inter-chip (ICI) 1D. La comunicazione tra chiplet viene gestita utilizzando operazioni collettive.
Esposizione del modello di programmazione e del framework
Il modello di programmazione per Ironwood è simile a quello delle generazioni di TPU precedenti alla v4, come la TPU v3. La nuova architettura è esposta nei seguenti modi:
Due dispositivi per chip: framework come JAX espongono ogni chip Ironwood come due "dispositivi" separati, uno per ogni chiplet.
Specifica del chiplet:puoi specificare quale chiplet utilizzare per un calcolo. JAX aggiunge una quarta dimensione alla specifica della topologia per distinguere tra i chiplet. Questo design ti consente di riutilizzare i modelli software esistenti con modifiche minime.
Per ulteriori informazioni su come ottenere prestazioni ottimali con l'architettura dual-chiplet, consulta Consigli sulle prestazioni per l'architettura dual-chiplet di Ironwood.
Configurazioni supportate
I chip TPU7x hanno una connessione diretta ai chip vicini più prossimi in 3 dimensioni, il che si traduce in una mesh 3D di connessioni di rete. Le sezioni più grandi di 64 chip sono costituite da uno o più "cubi" di chip 4x4x4.
I chip TPU7x hanno una topologia di interconnessione a toro 3D. Questa topologia consente alle sezioni di scalare fino a 9216 chip. Ha una larghezza di banda bidirezionale di 200 GBps per asse per la comunicazione tra i chip all'interno di un pod.
La tabella seguente mostra le forme comuni delle sezioni 3D supportate per TPU7x:
| Topologia | Chip TPU | Hosting | VM | Cubi | Ambito |
|---|---|---|---|---|---|
| 2x2x1 | 4 | 1 | 1 | 1/16 | A host singolo |
| 2x2x2 | 8 | 2 | 2 | 1/8 | Multi-host |
| 2x2x4 | 16 | 4 | 4 | 1/4 | Multi-host |
| 2x4x4 | 32 | 8 | 8 | 1/2 | Multi-host |
| 4x4x4 | 64 | 16 | 16 | 1 | Multi-host |
| 4x4x8 | 128 | 32 | 32 | 2 | Multi-host |
| 4x8x8 | 256 | 64 | 64 | 4 | Multi-host |
| 8x8x8 | 512 | 128 | 128 | 8 | Multi-host |
| 8x8x16 | 1024 | 256 | 256 | 16 | Multi-host |
| 8x16x16 | 2048 | 512 | 512 | 32 | Multi-host |
VM TPU7x
Ogni macchina virtuale (VM) TPU7x contiene 4 chip. Ogni VM ha accesso a due nodi NUMA. Per saperne di più sui nodi NUMA, consulta Non-uniform memory access su Wikipedia.
Tutte le sezioni di TPU7x utilizzano VM full-host a 4 chip. Le specifiche tecniche di una VM TPU7x sono:
- Numero di vCPU per VM: 224
- RAM per VM: 960 GB
- Numero di nodi NUMA per VM: 2
Hyperdisk
Per impostazione predefinita, il disco di avvio della VM per TPU7x è Hyperdisk bilanciato. Puoi collegare più dischi alla tua VM TPU per ulteriore spazio di archiviazione. I seguenti tipi di dischi sono supportati su TPU7x:
- Hyperdisk bilanciato
- Hyperdisk ML
Per saperne di più su Hyperdisk, consulta la panoramica di Hyperdisk. Per saperne di più sulle opzioni di archiviazione per Cloud TPU, consulta Opzioni di archiviazione per i dati di Cloud TPU.
Passaggi successivi
- Utilizzare TPU7x con GKE
- Utilizzare TPU7x con la modalità All Capacity
- Utilizza la piattaforma ML Diagnostics Google Cloud per ottimizzare e diagnosticare i tuoi workload
- Esegui un carico di lavoro di addestramento utilizzando una ricetta ottimizzata per TPU7x
- Esegui un microbenchmark TPU7x
- Ottimizzazioni del rendimento di Ironwood
- Addestra modelli di machine learning su larga scala su GKE con il checkpoint multi-livello