
Architettura TPU
Le TPU (Tensor Processing Unit) sono circuiti integrati specifici per le applicazioni (ASIC) progettati da Google per accelerare i carichi di lavoro di machine learning. Puoi utilizzare le TPU tramite Compute Engine, Google Kubernetes Engine e Vertex AI.
Le TPU sono progettate per eseguire rapidamente le operazioni sulle matrici, il che le rende ideali per i carichi di lavoro di machine learning. Puoi eseguire carichi di lavoro di machine learning sulle TPU utilizzando framework come PyTorch e JAX.
Come funzionano le TPU?
Per capire come funzionano le TPU, è utile comprendere in che modo altri acceleratori affrontano le sfide computazionali dell'addestramento dei modelli di ML.
Come funziona una CPU
Una CPU è un processore per uso generico basato sull'architettura di Von Neumann. Ciò significa che una CPU funziona con software e memoria nel seguente modo:
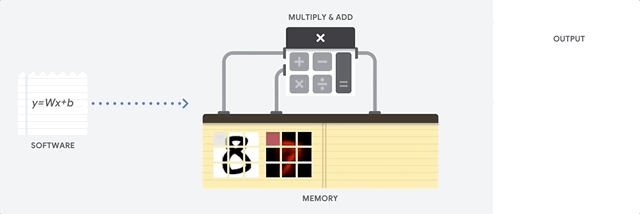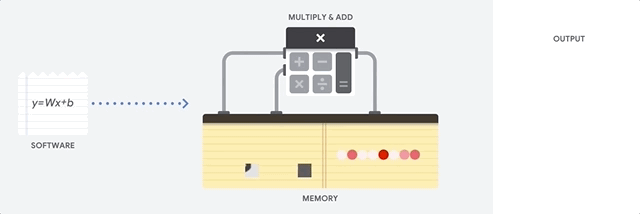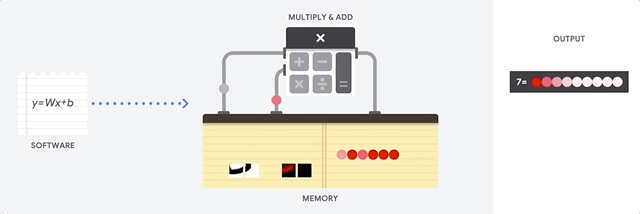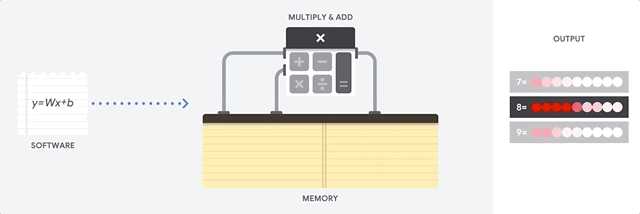
Il vantaggio principale delle CPU è la loro flessibilità. Puoi caricare qualsiasi tipo di software su una CPU per molti tipi diversi di applicazioni. Ad esempio, puoi utilizzare una CPU per l'elaborazione di testi su un PC, il controllo dei motori dei razzi, l'esecuzione di transazioni bancarie o la classificazione delle immagini con una rete neurale.
Per ogni calcolo, una CPU carica i valori dalla memoria, esegue un calcolo sui valori e memorizza il risultato nella memoria. L'accesso alla memoria è lento rispetto alla velocità di calcolo e può limitare la velocità effettiva totale delle CPU. Questo è spesso indicato come il collo di bottiglia di Von Neumann.
Come funziona una GPU
Per ottenere una velocità effettiva maggiore, le GPU contengono migliaia di unità logiche aritmetiche (ALU) in un singolo processore. Una GPU moderna in genere contiene tra 2500 e 5000 ALU. Il gran numero di processori significa che puoi eseguire migliaia di moltiplicazioni e addizioni contemporaneamente.

Questa architettura GPU funziona bene sulle applicazioni con un parallelismo massiccio, come le operazioni sulle matrici in una rete neurale. Infatti, in un tipico carico di lavoro di addestramento per il deep learning, una GPU può fornire una velocità effettiva di un ordine di grandezza superiore rispetto a una CPU.
Tuttavia, la GPU è ancora un processore per uso generico che deve supportare molte applicazioni e software diversi. Pertanto, le GPU hanno lo stesso problema delle CPU. Per ogni calcolo nelle migliaia di ALU, una GPU deve accedere ai registri o alla memoria condivisa per leggere gli operandi e memorizzare i risultati di calcolo intermedi.
Come funziona una TPU
Google ha progettato le Cloud TPU come processore di matrici specializzato per i carichi di lavoro delle reti neurali. Le TPU non possono eseguire word processor, controllare i motori dei razzi o eseguire transazioni bancarie, ma possono gestire operazioni sulle matrici di grandi dimensioni utilizzate nelle reti neurali a velocità elevate.
L'attività principale delle TPU è l'elaborazione delle matrici, che è una combinazione di operazioni di moltiplicazione e accumulo. Le TPU contengono migliaia di accumulatori di moltiplicazione collegati direttamente tra loro per formare una matrice fisica di grandi dimensioni. Questa è chiamata architettura di array sistolica. Le Cloud TPU v3 contengono due array sistolici di ALU 128 x 128 su un singolo processore.
L'host TPU trasmette i dati a una coda di input. La TPU carica i dati dalla coda di input e li memorizza nella memoria HBM (High Bandwidth Memory). Al termine del calcolo, la TPU carica i risultati nella coda di output. L'host TPU legge quindi i risultati dalla coda di output e li memorizza nella memoria dell'host.
Per eseguire le operazioni sulle matrici, la TPU carica i parametri da HBM nell'unità di moltiplicazione a matrice (MXU).

Poi, la TPU carica i dati da HBM. Man mano che viene eseguita ogni moltiplicazione, il risultato viene passato all'accumulatore di moltiplicazione successivo. L'output è la somma di tutti i risultati di moltiplicazione tra i dati e i parametri. Non è necessario accedere alla memoria durante il processo di moltiplicazione delle matrici.
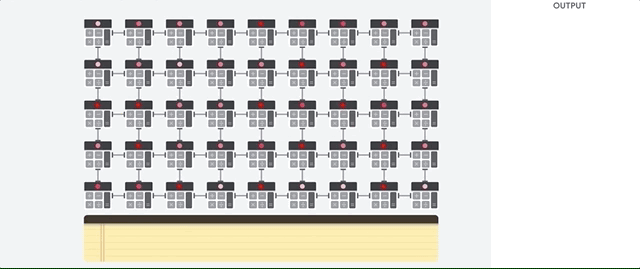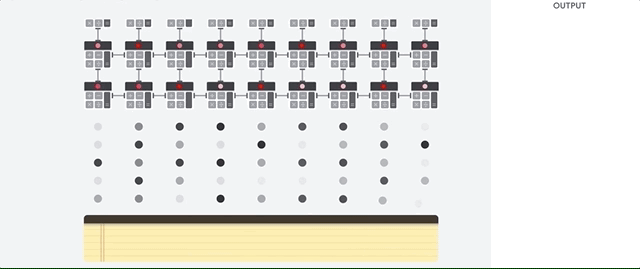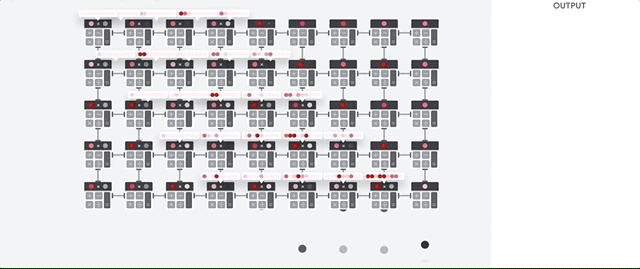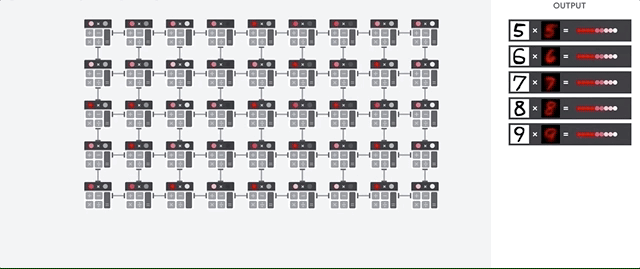
Di conseguenza, le TPU possono ottenere una velocità effettiva di calcolo elevata per i calcoli delle reti neurali.
Architettura del sistema TPU
Le sezioni seguenti descrivono i concetti chiave di un sistema TPU. Per saperne di più sui termini comuni di machine learning, consulta il glossario di machine learning.
Se non hai familiarità con Cloud TPU, consulta la home page della documentazione di TPU.
Chip TPU
Un chip TPU contiene uno o più TensorCore. Il numero di TensorCore dipende dalla versione del chip TPU. Ogni TensorCore è costituito da una o più unità di moltiplicazione a matrice (MXU), un'unità vettoriale e un'unità scalare. Per saperne di più sui TensorCore, consulta Un supercomputer specifico per il dominio per l'addestramento di reti neurali profonde.
Un'unità MXU è composta da accumulatori di moltiplicazione 256 x 256 (TPU v6e e TPU7x) o 128 x 128 (versioni TPU precedenti alla v6e) in un array sistolico array. Le unità MXU forniscono la maggior parte della potenza di calcolo in un TensorCore. Ogni unità MXU è in grado di eseguire 16.000 operazioni di moltiplicazione e accumulo per ciclo. Tutte le moltiplicazioni accettano bfloat16, ma tutti gli accumuli vengono eseguiti nel formato numerico FP32.
L'unità vettoriale viene utilizzata per il calcolo generale, ad esempio per le attivazioni e softmax. L'unità scalare viene utilizzata per il flusso di controllo, il calcolo degli indirizzi di memoria e altre operazioni di manutenzione.
pod di TPU
Un pod di TPU è un insieme contiguo di TPU raggruppate su una rete specializzata. Il numero di chip TPU in un pod di TPU dipende dalla versione della TPU.
Sezione
Una slice è una raccolta di chip tutti situati all'interno dello stesso pod di TPU connessi da interconnessioni inter-chip (ICI) ad alta velocità. Le sezioni sono descritte in termini di chip o TensorCore, a seconda della versione della TPU.
Topologia
La topologia definisce la disposizione fisica delle TPU all'interno di una sezione TPU. Le sezioni TPU hanno topologie bidimensionali (2D) o tridimensionali (3D), a seconda della versione della TPU. Specifichi una topologia come il numero di chip TPU in ogni dimensione nel seguente modo:
- Topologie 3D: definisci la topologia come una tupla di 3 elementi (
{A}x{B}x{C}), ad esempio4x4x4. Il prodotto di{A}x{B}x{C}definisce il numero di chip TPU nella sezione. Se utilizzi una topologia con più di 64 chip, i valori che assegni a{A},{B}e{C}devono soddisfare le seguenti condizioni:{A},{B}e{C}devono essere multipli di quattro.- I valori assegnati devono seguire questo pattern:
{A}≤{B}≤{C}. Ad esempio,4x4x8o8x8x8.
- Topologie 2D: definisci la topologia come una tupla di 2 elementi (
{A}x{B}), per esempio,2x4. Il prodotto di{A}x{B}definisce il numero di chip TPU nella sezione.
Una topologia a host singolo si riferisce a una topologia con chip TPU di un singolo host di calcolo. Ad esempio, per TPU7x, ogni host è connesso a quattro chip. Una sezione 2x2x1 ha quattro chip connessi a un singolo host, quindi 2x2x1 è una topologia a host singolo.
Una topologia multi-host si riferisce a una topologia con chip TPU di più host di calcolo. Ad esempio, per TPU7x, 2x2x2 (otto chip di due host) e le sezioni più grandi sono topologie multi-host.
Multislice e sezione singola
Multislice è un gruppo di sezioni che estende la connettività TPU oltre le connessioni inter-chip (ICI) e sfrutta la rete del data center (DCN) per trasmettere i dati oltre una sezione. I dati all'interno di ogni sezione vengono comunque trasmessi da ICI. Utilizzando questa connettività ibrida, Multislice consente il parallelismo tra le sezioni e ti consente di utilizzare un numero maggiore di core TPU per un singolo job rispetto a quello che può ospitare una singola sezione.
Le TPU possono essere utilizzate per eseguire un job su una singola sezione o su più sezioni. Per maggiori dettagli, consulta l'introduzione a Multislice.
Cubo TPU
Una topologia 4x4x4 di chip TPU interconnessi. Questo si applica solo alle topologie 3D (a partire da TPU v4).
SparseCore
SparseCore sono processori di dataflow che accelerano i modelli utilizzando operazioni sparse. Un caso d'uso principale è l'accelerazione dei modelli di suggerimenti, che si basano molto sugli incorporamenti. v5p e TPU7x hanno quattro SparseCore per chip, mentre v6e ha due SparseCore per chip. Per una spiegazione approfondita su come utilizzare SparseCore, consulta Un'analisi approfondita di SparseCore per i modelli di incorporamento di grandi dimensioni (LEM). Controlli il modo in cui il compilatore XLA utilizza SparseCore utilizzando i flag XLA. Per saperne di più, consulta: Flag XLA TPU.
Resilienza ICI di Cloud TPU
La resilienza ICI contribuisce a migliorare la tolleranza agli errori dei collegamenti ottici e degli switch di circuiti ottici (OCS) che collegano le TPU tra i cubi. (Le connessioni ICI all'interno di un cubo utilizzano collegamenti in rame che non sono interessati). La resilienza ICI consente di instradare le connessioni ICI intorno a OCS e guasti ICI ottici. Di conseguenza, migliora la disponibilità di pianificazione delle sezioni TPU, con il compromesso di un degrado temporaneo delle prestazioni ICI.
Per Cloud TPU v4, v5p e TPU7x, la resilienza ICI è abilitata per impostazione predefinita per le sezioni di un cubo o più grandi, ad esempio:
- v5p-128 quando si specifica il tipo di acceleratore
- 4x4x4 quando si specifica la configurazione dell'acceleratore
Versioni TPU
L'architettura esatta di un chip TPU dipende dalla versione della TPU che utilizzi. Ogni versione TPU supporta anche dimensioni e configurazioni di sezioni diverse. Per saperne di più sull'architettura del sistema e sulle configurazioni supportate, consulta le seguenti pagine:
Architettura cloud TPU
Google Cloud rende le TPU disponibili come risorse di calcolo tramite le VM TPU. Puoi utilizzare le TPU per i tuoi carichi di lavoro tramite Compute Engine, Google Kubernetes Engine e Vertex AI. Le sezioni seguenti descrivono i componenti chiave dell'architettura cloud TPU.
Architettura VM TPU
L'architettura VM TPU ti consente di connetterti direttamente alla VM connessa fisicamente al dispositivo TPU utilizzando SSH. Una VM TPU, nota anche come worker, è una macchina virtuale che esegue Linux e ha accesso alle TPU sottostanti. Hai accesso root alla VM, quindi puoi eseguire codice arbitrario. Puoi accedere ai log di debug del compilatore e del runtime e ai messaggi di errore.

Host singolo, multi-host e sub-host
Un host TPU è una VM che viene eseguita su un computer fisico connesso all'hardware TPU. I carichi di lavoro TPU possono utilizzare uno o più host.
Un carico di lavoro a host singolo è limitato a una VM TPU. Un carico di lavoro multi-host distribuisce l'addestramento su più VM TPU. Un carico di lavoro sub-host non utilizza tutti i chip su una VM TPU.
Visualizzatore della topologia TPU
Il visualizzatore della topologia TPU è uno strumento che ti consente di visualizzare il layout fisico delle TPU e della relativa infrastruttura di rete all'interno di un data center fisico. Utilizza lo strumento per comprendere il layout dell'infrastruttura fisica per diverse generazioni e topologie di TPU.