
TPU 架構
Tensor Processing Unit (TPU) 是 Google 設計的特殊應用積體電路 (ASIC),專門用來加速機器學習的工作負載。您可以透過 Compute Engine、Google Kubernetes Engine 和 Vertex AI 使用 TPU。
TPU 的設計可快速執行矩陣運算,因此非常適合機器學習工作負載。您可以使用 PyTorch 和 JAX 等架構,在 TPU 上執行機器學習工作負載。
TPU 的運作方式
如要瞭解 TPU 的運作方式,不妨先瞭解其他加速器如何解決訓練機器學習模型時的運算挑戰。
CPU 的運作方式
CPU 是以 von Neumann 架構為基礎的通用處理器。這表示 CPU 可與軟體和記憶體搭配使用,如以下所示:
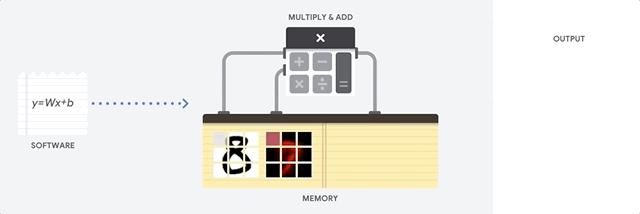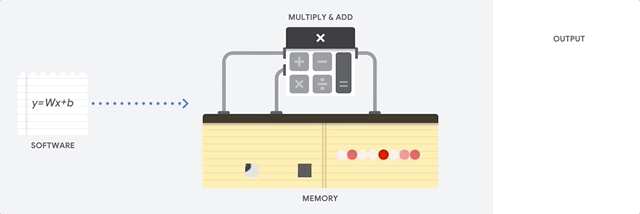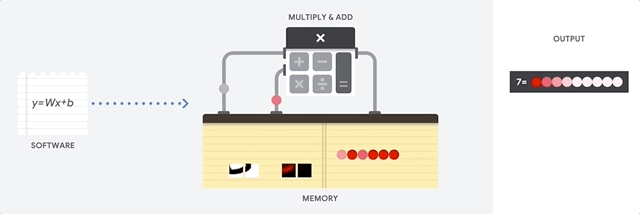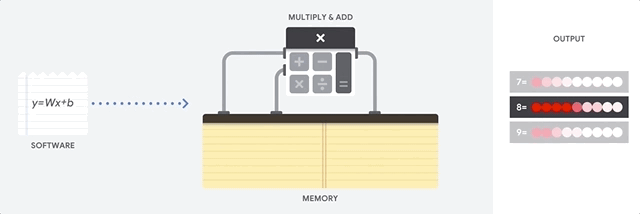
CPU 的最大優點是其彈性。您可以在 CPU 上載入各種軟體,用於許多不同類型的應用程式。舉例來說,您可以使用 CPU 在 PC 中進行文字處理、控制火箭引擎、執行銀行交易,或使用類神經網路將圖片分類。
CPU 會從記憶體載入值、對值執行計算,並將結果存回記憶體,每次計算都是如此。與計算速度相比,記憶體存取速度較慢,可能會限制 CPU 的總輸送量。這通常稱為「馮紐曼瓶頸」。
GPU 運作方式
為了獲得更高的處理量,GPU 在單一處理器中包含數千個算術邏輯單元 (ALU)。新型 GPU 通常包含 2,500 至 5,000 個 ALU。大量的處理器表示您可以同時執行數千個乘積和加法。

此 GPU 架構可在具有大量平行運作 (例如類神經網路中的矩陣運算) 的應用程式上順利運作。實際上,在深度學習的典型訓練工作負載上,GPU 可以提供較 CPU 高幾十倍的總處理量。
但 GPU 仍是一般用途處理器,可支援許多不同的應用程式和軟體。因此,GPU 與 CPU 有相同的問題。對於數千個 ALU 中的每個計算,GPU 必須存取暫存器或共用記憶體來讀取運算元,並儲存中繼計算結果。
TPU 運作方式
Google 將 Cloud TPU 設計為類神經網路工作負載專用的矩陣處理器。TPU 無法執行文書處理程式、控制火箭引擎或執行銀行交易,但可以快速處理類神經網路使用的大量矩陣運算。
TPU 的主要工作是矩陣處理,也就是乘法和累加運算的組合。TPU 內含數千個直接相互連結的乘法累加器,形成大型實體矩陣。這稱為脈動陣列架構。Cloud TPU v3 在單一處理器上包含兩個 128 x 128 ALU 的脈動陣列。
TPU 主機會將資料串流至饋入佇列。TPU 會從饋入佇列載入資料,並儲存至高頻寬記憶體 (HBM)。計算完成後,TPU 會將結果載入 outfeed 佇列。接著,TPU 主機會從輸出佇列讀取結果,並儲存在主機的記憶體中。
如要執行矩陣運算,TPU 會將參數從 HBM 載入至矩陣乘法單元 (MXU)。

接著,TPU 會從 HBM 載入資料。執行每個乘法時,結果會傳遞到下一個乘積累加器。輸出即是資料和參數間所有乘法結果的總和。矩陣乘法運算過程中不需要記憶體存取權。

因此,TPU 可以在類神經網路計算時達到較高的運算總處理量。
TPU 系統架構
以下各節說明 TPU 系統的重要概念。如要進一步瞭解常見的機器學習用語,請參閱機器學習詞彙表。
如果您是 Cloud TPU 新手,請參閱 TPU 說明文件首頁。
TPU 晶片
TPU 晶片包含一或多個 TensorCore。TensorCore 數量取決於 TPU 晶片的版本。每個 TensorCore 包含一或多個矩陣乘法單元 (MXU)、向量單元和純量單元。如要進一步瞭解 TensorCore,請參閱「A Domain-Specific Supercomputer for Training Deep Neural Networks」。
MXU 由 256 x 256 (TPU v6e 和 TPU7x) 或 128 x 128 (v6e 之前的 TPU 版本) 的乘法累加器組成,位於脈動陣列中。MXU 可在 TensorCore 中提供大部分的運算能力。每個 MXU 在各個週期中都能執行 16000 次乘積累加運算。所有乘法運算都會採用 bfloat16 輸入,但所有累加運算都會以 FP32 數字格式執行。
向量單元用於一般運算,例如活化和 softmax。 純量單元用於控制流程、計算記憶體位址,以及其他維護作業。
TPU Pod
TPU Pod 是透過專用網路群聚部署的連續 TPU 集合。TPU Pod 中的 TPU 晶片數量取決於 TPU 版本。
配量
配量是一組晶片,這些晶片都位於同一個 TPU Pod 內,透過高速晶片間互連 (ICI) 相連。配量通常會以晶片或 TensorCore 表示,視 TPU 版本而定。
拓撲
拓撲會定義 TPU 配量中 TPU 的實體排列方式。TPU 配量有二維 (2D) 或三維 (3D) 拓撲,取決於 TPU 版本。您會指定每個維度的 TPU 晶片數量,如下所示:
- 3D 拓撲:您可將拓撲定義為 3 元組 (
{A}x{B}x{C}),例如4x4x4。{A}x{B}x{C}的乘積會定義配量中的 TPU 晶片數量。如果使用的拓撲包含超過 64 個晶片,您為{A}、{B}和{C}指派的值必須符合下列條件:{A}、{B}和{C}必須是四的倍數。- 指派的值必須符合以下模式:
{A}≤{B}≤{C}。例如4x4x8或8x8x8。
- 2D 拓撲:將拓撲定義為 2 元組 (
{A}x{B}),例如2x4。{A}x{B}的乘積會定義配量中的 TPU 晶片數量。
單一主機拓撲是指拓撲中含有單一運算主機的 TPU 晶片。舉例來說,對於 TPU7x,每個主機都會連線至四個晶片。一個 2x2x1 切片有四個晶片,連線至單一主機,因此 2x2x1 是單一主機拓撲。
多主機拓撲是指拓撲中有多個運算主機的 TPU 晶片。舉例來說,對於 TPU7x,2x2x2 (來自兩部主機的八個晶片) 和較大的配量是多主機拓撲。
多配量與單一配量
多配量是一組配量,可將 TPU 連線能力延伸至晶片間互連 (ICI) 連線之外,並利用資料中心網路 (DCN) 在配量之間傳輸資料。每個切片中的資料仍會透過 ICI 傳輸。透過這種混合連線模式,多配量可實現跨配量的平行處理,使單一工作能使用的 TPU 核心數量遠超過單一配量的上限。
TPU 可用於在單一或多個配量上執行工作。詳情請參閱「多配量簡介」。
TPU 立方體
互連 TPU 晶片的 4x4x4 拓撲。這種架構僅適用於 3D 拓撲 (自 TPU v4 起採用)。
SparseCore
SparseCore 是資料流處理器,可加速使用稀疏作業的模型。主要用途是加速推薦模型,這類模型高度依賴嵌入項目。v5p 和 TPU7x 每個晶片有四個 SparseCore,v6e 每個晶片有兩個 SparseCore。如要深入瞭解 SparseCore 的使用方式,請參閱大型嵌入模型 (LEM) 的 SparseCore 深入探索。您可以透過 XLA 旗標,控管 XLA 編譯器使用 SparseCore 的方式。詳情請參閱:TPU XLA 旗標。
Cloud TPU ICI 復原能力
ICI 韌性有助於提升光纖連結和光纖電路交換器 (OCS) 的容錯能力,這些連結和交換器會連接立方體之間的 TPU。(立體架構內的 ICI 連線使用不受影響的銅線連結)。ICI 韌性可讓 ICI 連線繞過 OCS 和光纖 ICI 故障路徑。因此,這項功能會提升 TPU 節點的排程可用性,但 ICI 效能可能會暫時下降。
對於 Cloud TPU v4、v5p 和 TPU7x,系統已為一個立方體或更大規模的配量預設開啟 ICI 韌性功能,例如:
- 指定加速器類型時為 v5p-128
- 指定加速器設定時為 4x4x4
TPU 版本
TPU 晶片的確切架構取決於您使用的 TPU 版本。每個 TPU 版本也支援不同的切片大小和設定。如要進一步瞭解系統架構和支援的設定,請參閱下列頁面:
TPU 雲端架構
Google Cloud 透過 TPU VM 提供 TPU 做為運算資源。您可以透過 Compute Engine、Google Kubernetes Engine、Vertex AI,將 TPU 用於工作負載。以下各節說明 TPU 雲端架構的主要元件。
TPU VM 架構
TPU VM 架構可讓您使用 SSH,直接連線至實體連接 TPU 裝置的 VM。TPU VM (也稱為工作站) 是執行 Linux 的虛擬機器,可存取基礎 TPU。您擁有 VM 的根存取權,因此可以執行任意程式碼。您可以存取編譯器和執行階段的偵錯記錄和錯誤訊息。

單一主機、多主機和子主機
TPU 主機是 VM,在連接 TPU 硬體的實體電腦上運作。TPU 工作負載可使用一或多個主機。
單一主機工作負載僅限一個 TPU VM。多主機工作負載會將訓練分配至不同 TPU VM 執行。子主機工作負載不會使用 TPU VM 上的所有晶片。
TPU 拓撲視覺化工具
TPU 拓撲視覺化工具可讓您查看實體資料中心內的 TPU 實體配置,以及相關聯的網路基礎架構。使用這項工具,瞭解不同 TPU 世代和拓撲的實體基礎架構配置。