
JAX と Cloud TPU による本番環境 AI の構築
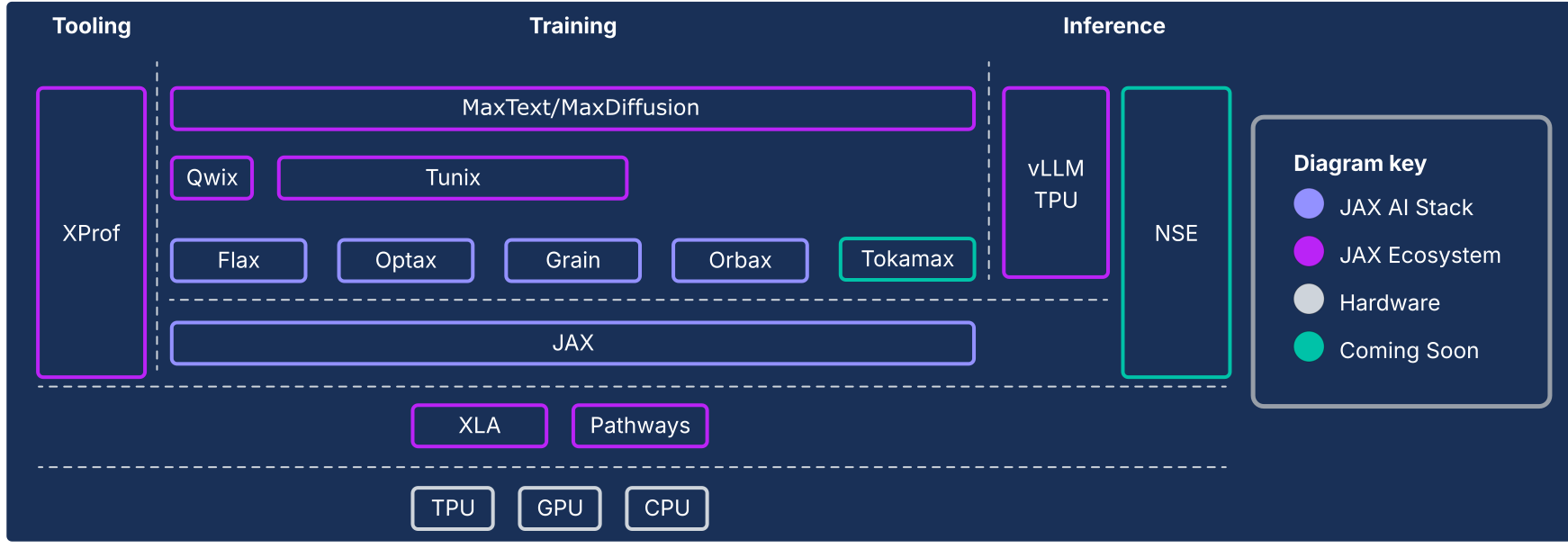
JAX AI スタックは、Google がサポートする構成可能なライブラリのコレクションで JAX 数値コアを拡張し、大規模な ML 用の堅牢でエンドツーエンドのオープンソース プラットフォームに進化させます。そのため、JAX AI スタックは、ML ライフサイクル全体を網羅する堅牢なエコシステムで構成されています。
産業規模の基盤: JAX AI スタックは大規模なスケール向けに設計されています。数万個のチップにわたるトレーニングのオーケストレートに ML Pathways、復元力とスループットの高い非同期チェックポインティングに Orbax を活用し、最先端のモデルのプロダクション グレードのトレーニングを実現しています。
完全な本番環境対応のツールキット: JAX AI スタックは、柔軟なモデル作成のための Flax、構成可能な最適化戦略のための Optax、再現可能な大規模実行に不可欠な決定論的データ パイプラインの Grain など、開発プロセス全体に対応する包括的なライブラリ セットを提供しています。
ピーク時の特殊なパフォーマンス: ハードウェアの利用率を最大化するため、JAX AI スタックは、最先端のカスタム カーネルに Tokamax、トレーニングと推論の速度を向上させる非侵入型の量子化に Qwix、ハードウェア統合型の詳細なパフォーマンス プロファイリングに XProf など、特殊なライブラリを提供しています。
本番環境へのフルパス: JAX AI スタックは、研究からデプロイへのシームレスな移行を実現します。これには、基盤モデルのトレーニングのスケーラブルなリファレンスとしての MaxText、最先端の強化学習(RL)とアライメントのための Tunix、vLLM TPU 統合と JAX サービング ランタイムによる統合推論ソリューションが含まれます。
JAX AI スタックの哲学は、疎結合のコンポーネントのそれぞれを有効に活用することです。JAX はモノリシックな ML フレームワークではなく、スコープが狭く、効率的な配列演算とプログラム変換に重点を置いています。このコア フレームワーク上にエコシステムが構築され、ML モデルのトレーニングと、科学計算などの他のタイプのワークロードの両方に関連する幅広い機能が提供されています。
この疎結合コンポーネントのシステムにより、要件に最適な方法でライブラリを選択して組み合わせることができます。ソフトウェア エンジニアリングの観点から見ると、このアーキテクチャでは、従来はコア フレームワーク コンポーネントと見なされていた機能(データ パイプラインやチェックポイントなど)を、コア フレームワークを不安定にするリスクや、リリース サイクルに巻き込まれるリスクを冒すことなく、反復的に更新できます。ほとんどの機能はモノリシック フレームワークの変更ではなく、ライブラリに実装されているため、コア数値ライブラリの耐久性が高まり、将来のテクノロジー環境の変化にも適応しやすくなっています。
以降のセクションでは、JAX AI スタックの技術的な概要、主な機能、その背後にある設計上の決定事項、最新の ML ワークロード用に耐久性の高いプラットフォームを構築するためにこのスタックがどのように併用されているのかについて説明します。
JAX AI スタックとその他のエコシステム コンポーネント
| コンポーネント | 機能 / 説明 |
|---|---|
| JAX AI スタックのコアとコンポーネント1 | |
| JAX | アクセラレータ指向の配列計算とプログラム変換(JIT、grad、vmap、pmap)。 |
| Flax | 直感的なモデルの作成と変更が可能な柔軟なニューラル ネットワーク作成ライブラリ。 |
| Optax | 構成可能な勾配処理と最適化変換のライブラリ。 |
| Orbax | 桁外れのトレーニング復元力を実現する「任意のスケール」の分散チェックポインティング ライブラリ。 |
| Grain | スケーラブルかつ決定論的でチェックポインティング可能な入力データ パイプライン ライブラリ。 |
| JAX AI スタック - インフラストラクチャ | |
| XLA | TPU、CPU、GPU 用のオープンソースの ML コンパイラ。 |
| Pathways | 数万個のチップにわたって計算をオーケストレートするための分散ランタイム。 |
| JAX AI スタック - 高度な開発 | |
| Pallas | Python で実装された低レベルの高性能カスタム カーネルを作成するための JAX 拡張機能。 |
| Tokamax | 最先端の高性能カスタム カーネル(Attention など)のキュレートされたライブラリ。 |
| Qwix | 量子化(PTQ、QAT、QLoRA)用の包括的で非侵入型のライブラリ。 |
| JAX AI スタック - アプリケーション | |
| MaxText / MaxDiffusion | 基盤モデル(LLM や拡散など)のトレーニング用のスケーラブルなリファレンス フレームワーク。 |
| Tunix | 最先端のトレーニング後とアライメント(RLHF、DPO)用のフレームワーク。 |
| vLLM | vLLM フレームワークの組み込み統合を使用した高性能 LLM 推論ソリューション。 |
| XProf | システム全体のパフォーマンス分析のための、ハードウェア統合型の詳細なプロファイラ。 |
1jax-ai-stack Python パッケージに含まれています。
図 1: JAX AI スタックとエコシステムのコンポーネント
アーキテクチャの必須事項: フレームワークを超えたパフォーマンス
モデル アーキテクチャが収束するにつれて(たとえば、マルチモーダル Mixture-of-Experts(MoE)Transformer など)、ピーク パフォーマンスの追求によりメガカーネルが登場しました。メガカーネルは、NVIDIA GPU の CUDA SDK などの下位レベルの API を使用して手動でコーディングされた、特定のモデルのフォワードパス全体(または大部分)になります。このアプローチでは、コンピューティング、メモリ、通信を積極的にオーバーラップさせることで、ハードウェアの使用率を最大化します。コミュニティの最近の研究では、このアプローチにより、GPU での推論スループットが大幅に向上することが示されています。場合によっては 22% を超える向上率が得られています。この傾向は推論に限定されません。大規模なトレーニングで、効率を大幅に向上させるために低レベルのハードウェア制御が使用されていることを示す証拠があります。
この傾向が加速すると、成熟した安定したアーキテクチャのパフォーマンスにとって最終的に重要なものはハードウェアへの低レベルアクセスであるため、現在のすべての高レベル フレームワークの重要性が低下する可能性があります。これは、高レベルのフレームワークの生産性と柔軟性を損なうことなく、エキスパート レベルのハードウェア制御をどのように提供するかという、すべての最新の ML スタックにとって課題を浮き彫りにしています。
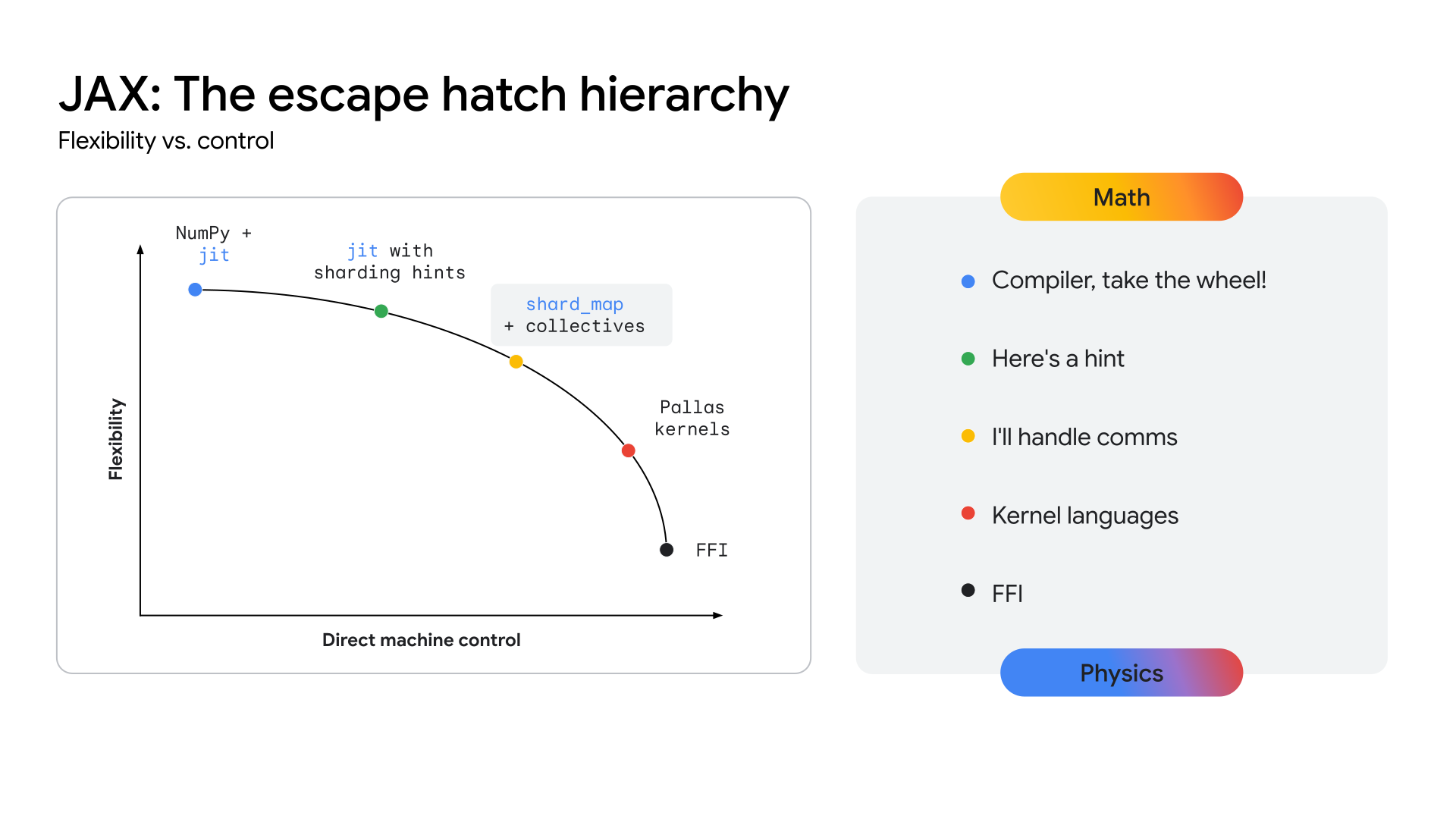
TPU がこのレベルのパフォーマンスを実現するための明確なパスを提供するには、エコシステムでハードウェアに近い API レイヤを公開し、高度に特殊化されたカーネルの開発を可能にする必要があります。JAX スタックは、XLA コンパイラの自動化された高レベルの最適化から、Pallas カーネル作成ライブラリのきめ細かい手動制御まで、抽象化の連続体(図 2 を参照)を提供することで、この問題を解決するように設計されています。
図 2: JAX の抽象化の連続体
コア JAX AI スタック
コア JAX AI スタックは、モデル開発の基盤となる 5 つの主要なライブラリで構成されています。
JAX: 構成可能で高パフォーマンスのプログラム変換の基盤
JAX は、アクセラレータ指向の配列計算とプログラム変換のための Python ライブラリで、高パフォーマンスの数値計算と大規模な ML 用に設計されています。関数型プログラミング モデルと NumPy のような API を備えた JAX は、高レベル ライブラリの確固たる基盤となります。
コンパイラ ファーストの設計により、JAX は XLA(XLA セクションを参照)を活用して、プログラム全体の積極的な分析、最適化、ハードウェア ターゲティングを行うことで、スケーラビリティを促進しています。JAX は関数型プログラミング(純粋関数など)を重視しているため、コアプログラム変換が扱いやすくなっています(重要なことに、構成可能になっています)。
これらのコア変換を組み合わせて、モデルサイズ、クラスタサイズ、ハードウェア タイプ全体でワークロードの高性能とスケーリングを実現できます。
- jit: Python 関数を最適化された融合 XLA 実行可能ファイルへのジャストインタイム コンパイル。
- grad: 自動微分。順方向モードと逆方向モード、高階導関数をサポートします。
- vmap: 関数のロジックを変更することなく、シームレスなバッチ処理とデータ並列処理を可能にする自動ベクトル化。
- pmap / shard_map: 複数のデバイス(TPU コアなど)にわたる自動並列化。分散トレーニングの基盤を形成します。
XLA の GSPMD(汎用 SPMD)モデルとのシームレスな統合により、JAX はコードの変更を最小限に抑えながら、大規模な TPU Pod 間で計算を自動的に並列化できます。ほとんどの場合、スケーリングには高レベルのシャーディング アノテーションのみが必要です。
Flax: 柔軟なニューラル ネットワークの作成
Flax は、モデル構築に対する直感的でオブジェクト指向のアプローチを提供することで、JAX でのニューラル ネットワークの作成、デバッグ、分析を簡素化します。JAX の関数型 API は強力ですが、PyTorch などのフレームワークに慣れているデベロッパー向けに、パフォーマンスを低下させず、より使い慣れたレイヤベースの抽象化を提供します。
この設計により、トレーニング済みモデル コンポーネントの変更や結合が簡素化されます。LoRA や量子化などの手法では、操作可能なモデル定義が必要です。Flax の NNX API は、Pythonic インターフェースを介してこれを提供します。NNX はモデルの状態をカプセル化し、ユーザーの認知負荷を軽減します。また、モデル階層のプログラムによるトラバーサルと変更を可能にします。
主な強み
- 直感的なオブジェクト指向 API: モデルの構築を簡素化し、サブモジュールの置換や部分的な初期化などの高度なユースケースを可能にします。
- Core JAX との一貫性: Flax は、JAX の関数型パラダイムと完全に互換性のあるリフト変換を提供し、JAX のパフォーマンスを最大限に引き出しながら、デベロッパーの使いやすさを向上させます。
Optax: 構成可能な勾配処理と最適化戦略
Optax は、JAX 用の勾配処理と最適化のライブラリです。これは、モデルビルダーに、ディープ ラーニング モデルなどのアプリケーションをトレーニングするために柔軟に再結合可能なビルディング ブロックを提供するように設計されています。これは、コア JAX ライブラリの機能を基盤として、ML モデルのトレーニングに使用できる損失関数、オプティマイザー関数、高性能ライブラリ、それに関連する手法を提供します。
目的
損失の計算と最小化は、ML モデルのトレーニングを可能にする中核となるものです。自動微分をサポートするコア JAX ライブラリは、モデルをトレーニングするための数値機能を提供しますが、一般的なオプティマイザー(RMSProp や Adam など)や損失(CrossEntropy や MSE など)の標準実装は提供しません。これらの関数を実装することは可能ですが(一部の上級デベロッパーはそうするでしょう)、オプティマイザーの実装にバグがあると、モデルの品質に関する問題の診断が難しくなります。Optax は、正確性とパフォーマンスがテストされたこれらのアルゴリズムの実装を提供します。ユーザーがこのような重要な部分を実装する必要はありません。
最適化理論の分野はいまだに研究領域ではありますが、トレーニングにおける中心的な役割を担っているため、本番環境の ML モデルのトレーニングに不可欠な要素となっています。この役割を果たすライブラリは、研究成果を迅速に反映できる柔軟性と、本番環境のモデル トレーニングで信頼できる堅牢性とパフォーマンスを備えている必要があります。また、標準方程式に一致する最先端のアルゴリズムのテスト済みの実装も提供する必要があります。Optax ライブラリは、モジュラー構成が可能なアーキテクチャと、正しい読み取り可能なコードを重視することで、これを実現するように設計されています。
デザイン
Optax は、読みやすく、十分にテストされ、効率的なコア アルゴリズムの実装を提供することで、研究速度と研究から本番環境への移行の両方を強化するように設計されています。Optax はディープ ラーニングのコンテキスト以外でも使用されますが、このコンテキストでは、JAX の哲学に沿って純粋関数型で実装された、よく知られた損失関数、最適化アルゴリズム、勾配変換のコレクションと見なすことができます。よく知られている損失関数とオプティマイザーのコレクションにより、ユーザーは簡単かつ確実に作業を始めることができます。
Optax のモジュール型アプローチにより、複数のオプティマイザーの連結を行い、その後に他の一般的な変換(勾配クリッピングなど)を適用し、MultiStep や Lookahead などの一般的な手法を使用してそれらをラップすることで、数行のコードで強力な最適化戦略を実現できます。柔軟なインターフェースにより、新しい最適化アルゴリズムを研究し、shampoo や muon などの強力な 2 次最適化手法を使用できます。
# Optax implementation of a RMSProp optimizer with a custom learning rate
# schedule, gradient clipping and gradient accumulation.
optimizer = optax.chain(
optax.clip_by_global_norm(GRADIENT_CLIP_VALUE),
optax.rmsprop(learning_rate=optax.cosine_decay_schedule(init_value=lr,decay_steps=decay)),
optax.apply_every(k=ACCUMULATION_STEPS)
)
# The same thing, in PyTorch
optimizer = optim.RMSprop(model_params, lr=LEARNING_RATE)
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=TOTAL_STEPS)
for i, (inputs, targets) in enumerate(data_loader):
# ... Training loop body ...
if (i + 1) % ACCUMULATION_STEPS == 0:
torch.nn.utils.clip_grad_norm_(model.parameters(), GRADIENT_CLIP_VALUE)
optimizer.step()
scheduler.step()
optimizer.zero_grad()
前のコード スニペットは、カスタム学習率、勾配クリッピング、勾配累積を使用してオプティマイザーを設定する方法を示しています。
主な強み
- 堅牢なライブラリ: 正確性と読みやすさに重点を置いた、損失、オプティマイザー、アルゴリズムの包括的なライブラリを提供します。
- モジュール式のチェーン可能な変換: この柔軟な API を使用すると、トレーニング ループを変更することなく、強力で複雑な最適化戦略を宣言的に作成できます。
- 機能的でスケーラブル: 純粋な関数型実装は、JAX の並列化メカニズム(pmap など)とシームレスに統合されるため、同じコードを使用して単一のホストから大規模なクラスタにスケーリングできます。
Orbax / TensorStore - 大規模分散チェックポイント処理
Orbax は、単一デバイスから大規模な分散トレーニングまで、あらゆる規模に対応するように設計された JAX 用のチェックポインティング ライブラリです。断片化されたチェックポインティングの実装を統合し、非同期チェックポインティングや多層チェックポインティングなどの重要なパフォーマンス機能をより多くのユーザーに提供することを目的としています。Orbax は、大規模なトレーニング ジョブに必要な復元力を実現し、チェックポイントを公開するための柔軟な形式を提供します。
システム状態全体をスナップショットする一般的なチェックポイントと復元システムとは異なり、Orbax を使用した ML チェックポインティングでは、トレーニング モデルの重み、オプティマイザーの状態、データローダの状態の再開に必要な情報のみが選択的に保持されます。この目標を絞り込んだアプローチにより、アクセラレータのダウンタイムを最小限に抑えることができます。Orbax は、I/O オペレーションと計算をオーバーラップさせることでこれを実現します。これは、大規模なワークロードにとって重要な機能です。アクセラレータのアイドル時間がデバイスからホストへのデータ転送の時間にまで短縮されます。次のトレーニング ステップと重複する場合もあるため、チェックポインティングはパフォーマンスの観点からほぼ無料になります。
Orbax は、配列データの効率的な並列読み取りと書き込みに TensorStore を使用します。Orbax API はこの複雑さを抽象化し、JAX のモデルの標準表現である PyTree を処理するためのユーザー フレンドリーなインターフェースを提供します。
主な強み
- 広範囲で採用: 毎月数百万件のダウンロードがある Orbax は、ML アーティファクトを共有するための一般的なメディアとして機能します。
- 複雑さを簡素化: Orbax は、非同期保存、アトミック性、ファイル システムの詳細など、分散チェックポインティングの複雑さを抽象化します。
- 柔軟性: Orbax では、一般的なユースケース向けの API が用意されているだけでなく、特殊な要件を処理するようにワークフローをカスタマイズできます。
- パフォーマンスとスケーラビリティ: 非同期チェックポインティング、効率的なストレージ形式(OCDBT)、インテリジェントなデータ読み込み戦略などの機能により、Orbax は数万のノードを含むトレーニング実行にスケーリングできます。
Grain: 決定論的でスケーラブルな入力データ パイプライン
Grain は、JAX モデルのトレーニングと評価用のデータを読み取って処理するための Python ライブラリです。柔軟性、高速性、決定論的であり、大規模なワークロードのトレーニングを成功させるために不可欠なチェックポインティングなど、高度な機能をサポートしています。一般的なデータ形式とストレージ バックエンドをサポートしており、ネイティブでサポートされていないユーザー固有の形式とバックエンドへのサポートを拡張するための柔軟な API も提供しています。Grain は主に JAX で動作するように設計されていますが、フレームワークに依存せず、JAX を実行する必要はありません。他のフレームワークでも使用できます。
目的
データ パイプラインはトレーニング インフラストラクチャの重要な部分を形成します。一般的な変換を効率的に表現できる柔軟性と、アクセラレータを常にビジー状態に保つことができる十分なパフォーマンスが必要です。また、複数のストレージ形式とバックエンドに対応できる必要があります。ステップ時間が長いため、大規模なモデルを大規模にトレーニングするには、通常のトレーニング ワークロードで必要とされる要件に加えて、主に決定論と再現性に関するデータ パイプラインの要件が必要になります2。Grain ライブラリは、これらのニーズに対応する柔軟なアーキテクチャで設計されています。
2PaLM 論文のセクション 5.1 で、グラデーション クリッピングを有効にしているにもかかわらず、損失の急増が非常に大きかったことが指摘されています。解決策として、問題のあるデータバッチを削除し、損失が急増する前のチェックポイントからトレーニングを再開することが記述されています。これは、完全に決定論的で再現可能なトレーニング ステップでのみ可能になります。
デザイン
最上位レベルで入力パイプラインを構成する方法は 2 つあります。1 つはデータワーカーの個別のクラスタとして構成する方法、もう 1 つはアクセラレータを駆動するホストにデータワーカーを配置する方法です。Grain はさまざまな理由から後者を選択しています。
アクセラレータは、通常はトレーニング ステップ中にアイドル状態になる強力なホストと組み合わされるため、入力データ パイプラインの実行に適しています。この実装には、入力とコンピューティング全体で一貫したシャーディングのビューを提供することで、データ シャーディングのビューを簡素化するという利点もあります。データワーカーをアクセラレータ ホストに配置すると、ホスト CPU が飽和するリスクがあるという見方もありますが、RPC を使用してコンピューティング負荷の高い変換を別のクラスタにオフロードできないというわけではありません3。
API 側では、複数のプロセスと柔軟な API をサポートする純粋な Python 実装により、Grain では、よく理解されている変換パラダイムに基づいてパイプライン ステージを構成することで、任意の複雑なデータ変換を実装できます。
Grain は、Parquet や TFDS などの他の一般的なデータ形式とともに、ArrayRecord や Bagz などの効率的なランダム アクセス データ形式もサポートしています。Grain には、ローカル ファイル システムからの読み取りと Cloud Storage からの読み取りのサポートがデフォルトで含まれています。一般的なストレージ形式とバックエンドのサポートに加えて、ストレージ レイヤへのクリーンな抽象化により、既存のデータソースのサポートを追加することも、Grain ライブラリと互換性を持たせるために既存のデータソースをラップすることも可能です。
3マルチモーダル データ パイプラインは、このように動作する必要があります。たとえば、画像と音声のトークナイザーは、独自のアクセラレータ上の独自のクラスタで実行されるモデル自体であり、入力パイプラインは RPC 呼び出しを行ってデータのサンプルをトークンのストリームに変換します。
主な強み
- 決定論的なデータフィード: データワーカーをアクセラレータと同じ場所に配置し、安定したグローバル シャッフルとチェックポイント可能なイテレータと組み合わせることで、Orbax を使用してモデルの状態とデータ パイプラインの状態を整合性のあるスナップショットで一緒にチェックポインティングできます。これにより、トレーニング プロセスの決定論性が向上します。
- 強力なデータ変換を可能にする柔軟な API: 柔軟で純粋な Python 変換 API を使用すると、入力処理パイプライン内で広範なデータ変換を実行できます。
- 複数の形式とバックエンドの拡張可能なサポート: 拡張可能なデータソース API は、一般的なストレージ形式とバックエンドをサポートしており、新しい形式とバックエンドのサポートを追加できます。
- 強力なデバッグ インターフェース: データ パイプラインの可視化ツールとデバッグモードを使用すると、データ パイプラインのパフォーマンスを内省、デバッグ、最適化できます。
拡張された JAX AI スタック
コアスタックに加えて、専門ライブラリの豊富なエコシステムが、エンドツーエンドの ML 開発に必要なインフラストラクチャ、高度なツール、アプリケーション レイヤ ソリューションを提供します。
基盤となるインフラストラクチャ: コンパイラとランタイム
XLA: ハードウェアに依存しないコンパイラ中心のエンジン
目的
XLA(Accelerated Linear Algebra)は Google のドメイン固有のコンパイラで、JAX に統合されており、TPU、CPU、GPU のハードウェア デバイスをサポートしています。XLA は、TPU、GPU、CPU をターゲットとするハードウェアに依存しないコード ジェネレータとして設計されました。
XLA コンパイラのコンパイラ ファーストの設計は、急速に進化する研究環境において持続的な優位性を生み出すための基本的なアーキテクチャ上の選択です。一方、他のエコシステムでの一般的なカーネル中心のアプローチでは、パフォーマンスのために手動で最適化されたライブラリに依存しています。これは、安定し、確立されたモデル アーキテクチャには非常に効果的ですが、イノベーションにはボトルネックとなります。新しい研究で新しいアーキテクチャが導入されると、エコシステムは、新しいカーネルが作成され、最適化されるまで待たなければなりません。しかし、コンパイラ中心の設計では新しいパターンに一般化できることが多く、最先端の研究に最初から高性能なパスを提供できます。
デザイン
XLA は、JAX がトレース プロセス中に生成する計算グラフをジャストインタイム(JIT)でコンパイルすることで機能します(たとえば、関数に @jax.jit デコレーターが付いている場合など)。
このコンパイルは、マルチステージ パイプラインに従って行われます。
- JAX 計算グラフ
- High-Level Optimizer(HLO)
- Low-Level Optimizer(LLO)
- ハードウェア コード
- JAX グラフから HLO へ: JAX 計算グラフが XLA の HLO 表現に変換されます。この高レベルの最適化では、オペレーター フュージョンや効率的なメモリ管理など、強力なハードウェアに依存しない最適化が適用されます。StableHLO 言語は、このステージのバージョニングされた永続的インターフェースとして機能します。
- HLO から LLO へ: 高レベルの最適化の後、ハードウェア固有のバックエンドが引き継ぎ、HLO 表現をマシン指向の LLO に変換します。
- LLO からハードウェア コードへ: 最終的に LLO は効率性の高いマシンコードにコンパイルされます。TPU の場合、このコードはハードウェアに直接送信される Very Long Instruction Word(VLIW)パケットとしてバンドルされます。
スケーリングの場合、XLA の設計は並列処理を中心に構築されています。アルゴリズムを使用して、チップ上の行列乗算ユニット(MXU)を最大限に活用します。チップ間では、XLA は SPMD(単一プログラム、複数データ)を使用します。これは、すべてのデバイスで単一のプログラムを使用するコンパイラ ベースの並列化技術です。この強力なモデルは JAX API を介して公開され、高レベルのシャーディング アノテーションを使用してデータ、モデル、パイプラインの並列処理を管理できます。
より複雑な並列処理パターンでは、MPMD(複数プログラム、複数データ)も可能です。PartIR:MPMD などのライブラリを使用すると MPMD アノテーションも提供できます。
主な強み
- コンパイル: 計算グラフのジャストインタイム コンパイルにより、メモリ レイアウト、バッファ割り当て、メモリ管理の最適化が可能になります。カーネルベースの手法などの場合、この負担はデベロッパーに課せられます。ほとんどの場合、XLA はデベロッパーの速度を損なうことなく優れたパフォーマンスを実現できます。
- 並列処理: XLA は SPMD を使用して複数の形式の並列処理を実装しており、これは JAX レベルで公開されています。これにより、シャーディング戦略を表現し、数千個のチップにわたるモデルのテストとスケーラビリティを実現できます。
Pathways: 大規模な分散コンピューティング用の統合ランタイム
Pathways は、分散トレーニングと推論の抽象化を提供し、フォールト トレランスと復元が組み込まれています。ML 研究者は単一の強力なマシンを使用しているかのようにコーディングできます。
目的
大規模なモデルをトレーニングしてデプロイするには、数百から数千個のチップが必要です。これらのチップは、多数のラックとホストマシンに分散されています。トレーニング ジョブは、これらのチップとそれぞれのホストが、並列化(シャーディング)された XLA コンピューティングで連携して動作する必要がある大規模な同期プログラムです。大規模言語モデルの場合、数万個以上のチップが必要になる可能性があるため、このサービスは、Pod 内でチップ間相互接続(ICI)とオンチップ相互接続(OCI)ファブリックを使用するだけでなく、データセンター ファブリック内の複数の Pod にまたがって使用できるようにする必要があります。
デザイン
ML Pathways は、ホストと TPU チップ間で分散コンピューティングを調整するために使用するシステムです。このサービスは、数十万のアクセラレータにわたるスケーラビリティと効率性を実現するように設計されています。大規模なトレーニングでは、複数の Pod ジョブ用の単一の Python クライアント、Megascale XLA の統合、コンパイル サービス、リモート Python が提供されます。また、クロススライス並列処理とプリエンプション許容度もサポートしており、リソースのプリエンプションからの自動復旧が可能です。
Pathways には、XLA 計算グラフを単一の TPU Pod を超えて拡張できる最適化されたクロスホスト コレクティブが組み込まれています。XLA のデータ、モデル、パイプラインの並列処理のサポートを拡張し、データセンター ネットワーク(DCN)を使用して TPU スライス境界を越えて動作するようにします。これは、DCN 通信を XLA 通信プリミティブで管理する分散ランタイムを統合することで実現されます。
主な強み
JAX と統合された単一コントローラ アーキテクチャは、重要な抽象化です。これにより、研究者はトレーニングとデプロイのさまざまなシャーディングと並列処理戦略を簡単に試すことができます。また、数万個のチップへのスケーリングも簡単に行うことができます。
高度な開発: パフォーマンス、データ、効率性
Pallas: JAX で高性能なカスタム カーネルを記述する
JAX はコンパイラ優先ですが、パフォーマンスを最大化するためにハードウェアをきめ細かく制御したい場合があります。Pallas は、GPU と TPU のカスタム カーネルの作成を可能にする JAX の拡張機能です。これは、生成されたコードを正確に制御することと、JAX トレースと jax.numpy API の高レベルのエルゴノミクスを組み合わせることを目的としています。
Pallas は、ユーザー定義のカーネル関数が並列ワークグループの多次元グリッド全体で実行されるグリッドベースの並列処理モデルを公開しています。これにより、インデックス マップを使用してグリッドの場所を特定のデータブロックに関連付け、テンソルをタイル化して、低速で大容量のメモリ(HBM など)と高速で小容量のオンチップ メモリ(TPU の VMEM、GPU の共有メモリなど)の間の転送方法を定義することで、メモリ階層を明示的に管理できます。Pallas は、カーネルをターゲット アーキテクチャに適した中間表現(TPU の場合は Mosaic、GPU の場合は Triton などのテクノロジーを利用)にコンパイルすることで、同じカーネル定義を Google の TPU とさまざまな GPU の両方で効率的に実行できるようにします。Pallas を使用すると、ベンダー固有のツールキットに依存することなく、ターゲット ハードウェアで最適なモデル パフォーマンスを実現するために、アテンションなどのブロックに特化した高性能カーネルを作成できます。
Tokamax: 最先端のカーネルを集めたキュレーション ライブラリ
Pallas がカーネルを作成するためのツールであるのに対し、Tokamax は、TPU と GPU の両方をサポートする最先端のカスタム アクセラレータ カーネルのライブラリです。Tokamax は JAX と Pallas 上に構築されており、ハードウェアの性能を最大限に活用できます。また、カスタム カーネルをビルドして自動調整するためのツールも用意されています。
目的
XLA を基盤とする JAX はコンパイラ ファーストのフレームワークですが、最大限のパフォーマンスを実現するためにハードウェアを直接制御する必要があるケースもないわけではありません4。カスタム カーネルは、TPU や GPU などの高価な ML アクセラレータ リソースから最高のパフォーマンスを引き出すために不可欠です。これらは、Attention などの主要なオペレーターの実行を可能にするために広く使用されていますが、実装するには、モデルとターゲット ハードウェア アーキテクチャの両方についてよく理解する必要があります。Tokamax は、厳選され、十分にテストされた高性能カーネルの信頼できるソースを提供します。また、開発、メンテナンス、ライフサイクル管理のための堅牢な共有インフラストラクチャも提供します。このようなライブラリは、必要に応じてビルドしてカスタマイズするためのリファレンス実装としても機能します。これにより、インフラストラクチャを気にすることなく、モデリングに集中できます。
4これは確立されたパラダイムです。CPU の世界では、コンパイル済みのコードがプログラムの大部分を占めていますが、パフォーマンスが重要なセクションを最適化するためにデベロッパーが組み込み関数やインライン アセンブリに切り替えることがあります。
デザイン
Tokamax は、特定のカーネルに対して、複数の実装でサポートされる共通 API を提供します。たとえば、TPU カーネルは、標準の XLA 低減によって実装することも、Pallas / Mosaic-TPU を使用して明示的に実装することもできます。GPU カーネルは、標準の XLA 低減、Mosaic-GPU、または Triton によって実装できます。デフォルトでは、Tokamax API は、定期的な自動チューニングとベンチマーク実行のキャッシュに保存された結果に基づいて、特定の構成に最適な実装を選択します。ただし、必要に応じて特定の実装を選択することもできます。新しいハードウェア世代の特定の機能をより有効に活用してパフォーマンスをさらに向上させるために、新しい実装が時間の経過とともに追加される可能性があります。
Tokamax ライブラリの重要なコンポーネントは、カーネル自体だけでなく、カスタム カーネルを作成できるサポート インフラストラクチャです。たとえば、自動チューニング インフラストラクチャを使用すると、Tokamax が徹底的なスイープを実行し、最適なチューニング設定を特定してキャッシュに保存できるように、構成可能なパラメータ(タイルサイズなど)のセットを定義できます。ナイトリー回帰テストは、基盤となるコンパイラ インフラストラクチャやその他の依存関係の変更によって発生する予期しないパフォーマンスや数値の問題から保護します。
主な強み
- シームレスなデベロッパー エクスペリエンス: 厳選され、統合されたライブラリは、主要なカーネルの既知の優れた高性能実装を提供します。サポートされているハードウェア世代と期待されるパフォーマンスは、プログラムとドキュメントの両方で明確に表現されています。これにより、断片化と離脱を最小限に抑えることができます。
- 柔軟性とライフサイクル管理: 異なる実装を選択できます。必要であれば変更することもできます。たとえば、XLA コンパイラで特定のオペレーションのサポートが強化され、カスタム カーネルが不要になった場合には、非推奨と移行のパスが存在します。
- 拡張性: 独自のカーネルを実装しながら、十分にサポートされている共有インフラストラクチャを活用できるため、付加価値機能と最適化に集中できます。明確に作成された標準実装は、ユーザーが学習して拡張するための出発点となります。
Qwix: 非侵入型の包括的な量子化
Qwix は、JAX AI スタック用の包括的な量子化ライブラリです。トレーニング(量子化認識トレーニング(QAT)、量子化手法(QT)、量子化低ランク適応(QLoRA))や推論(トレーニング後の量子化(PTQ))など、すべてのステージで LLM と他のモデルタイプをサポートし、XLA とオンデバイス ランタイムの両方をターゲットにしています。
目的
既存の量子化ライブラリ(特に PyTorch エコシステム)は、多くの場合、限られた目的(PTQ のみ、QLoRA のみなど)で使用されます。この断片化された環境では、ツールを切り替える必要があり、一貫したコードの使用や、トレーニングと推論間の正確な数値照合が妨げられます。また、多くのソリューションでは、モデルのロジックと量子化のロジックが密接に結合しているため、モデルの大幅な変更が必要になります。
デザイン
Qwix の設計理念では、包括的なソリューションと、特に非侵入型のモデル統合を重視しています。再利用可能な関数型 API を基盤とする、階層型の拡張可能な設計で構築されています。
この非侵入型の統合は、JAX 関数を量子化された対応する関数にリダイレクトする、綿密に設計されたインターセプト メカニズムによって実現されています。これにより、モデルを修正することなく統合し、量子化コードをモデル定義から完全に切り離すことができます。
次の例は、LLM の MLP レイヤに w4a4(4 ビットの重み、4 ビットのアクティベーション)量子化を適用し、エンベッダーに w8(8 ビットの重み)量子化を適用する方法を示しています。量子化レシピを変更するには、ルールリストを更新するだけで済みます。
fp_model = ModelWithoutQuantization(...)
rules = [
qwix.QuantizationRule(
module_path=r'embedder',
weight_qtype='int8',
),
qwix.QuantizationRule(
module_path=r'layers_\d+/mlp',
weight_qtype='int4',
act_qtype='int4',
tile_size=128,
weight_calibration_method='rms,7',
),
]
quantized_model = qwix.quantize_model(fp_model, qwix.PtqProvider(rules))
主な強み
- 包括的なソリューション: Qwix は、さまざまな量子化シナリオに幅広く適用でき、トレーニングと推論の間で一貫したコードの使用を保証します。
- 非侵入型のモデル統合: 例に示すように、1 行のコードでモデルを統合できます。これにより、多くの量子化スキームでハイパーパラメータを使用して、品質とパフォーマンスの最適なトレードオフを見つけることができます。
- 他のライブラリとの連携: Qwix は JAX AI スタックとシームレスに統合されます。たとえば、Qwix でモデルが量子化されると、Tokamax は追加のユーザーコードなしで、量子化されたバージョンのカーネルを使用するように自動的に適応します。
- 研究に最適: Qwix の基盤となる API と拡張可能なアーキテクチャにより、研究者は新しいアルゴリズムを探索し、統合されたベンチマーク ツールと評価ツールを使用して比較を簡単に行うことができます。
アプリケーション レイヤ: トレーニングとアライメント
基盤モデルのトレーニング: MaxText と MaxDiffusion
MaxText と MaxDiffusion は、それぞれ Google の主力 LLM と拡散モデルのトレーニング フレームワークです。これらのリポジトリには、一般的なオープンウェイト モデルの高度に最適化された実装がいくつか含まれています。これらは、すぐに使用できるモデル トレーニング コードベースと、基盤モデルビルダーが構築に使用できるリファレンスの両方として機能します。
目的
業界全体で生成 AI モデルのトレーニングに対する関心が急速に高まっています。オープンモデルの人気が高まったことで、この傾向が加速し、実績のあるアーキテクチャが提供されています。これらのモデルのトレーニングと適応には、高いパフォーマンス、効率性、多数のチップへのスケーラビリティ、明確で理解しやすいコードが必要です。MaxText と MaxDiffusion は、TPU または GPU で使用できる包括的なソリューションであり、こうしたニーズを満たすように設計されています。
デザイン
MaxText と MaxDiffusion] は、読みやすさとパフォーマンスを重視して設計された基盤モデルのコードベースです。これらは、最大パフォーマンスを実現するカスタム カーネル(Tokamax など)を使用するモデル定義、オーケストレーションとモニタリング用のトレーニング ハーネス、シャーディングや量子化(Qwix を使用)などの詳細を直感的なインターフェースで制御できる強力な構成システムなど、十分にテストされた再利用可能なコンポーネントで構成されています。マルチティア チェックポインティングなどの高度な信頼性機能が組み込まれており、スループットの維持が保証されます。
MaxText と MaxDiffusion は、クラス最高の JAX ライブラリである Qwix、Tunix、Orbax、Optax を使用して、コア機能を提供します。これらのライブラリは、堅牢でスケーラブルなインフラストラクチャを提供し、開発オーバーヘッドを削減して、モデリング タスクに集中できるようにします。推論では、モデルコードが共有され、効率的でスケーラブルなサービングが可能になります。
主な強み
- 設計によるパフォーマンス: MaxText と MaxDiffusion は、高い「グッドプット」(有用なスループット)を実現するように設定されたトレーニング インフラストラクチャと、高い MFU(モデルの FLOP 使用率)を実現するように最適化されたモデル実装により、すぐに使用できる高パフォーマンスを大規模に実現しています。
- スケーラビリティを重視した設計: JAX AI スタック(特に Pathways)の能力を活用することで、これらのフレームワークで数十個のチップから数万個のチップまでシームレスにスケーリングできます。
- 基盤モデルビルダー向けの確固たる基盤: 高品質で読みやすい実装は、デベロッパーがエンドツーエンド ソリューションとして使用したり、独自のカスタマイズのリファレンス実装として使用するための確固たる基盤となります。
トレーニングとアライメント後の処理: Tunix フレームワーク
Tunix は、最先端のオープンソース強化学習(RL)アルゴリズムと、堅牢なフレームワークとインフラストラクチャを提供します。これにより、デベロッパーは JAX と TPU を使用した教師ありファインチューニング(SFT)やアライメントなど、LLM のトレーニング後の手法を効率的に試すことができます。
目的
トレーニング後のステップは、LLM の真の力を引き出すための重要なステップです。強化学習(RL)ステージは、アライメントと推論機能を開発するうえで特に重要です。この分野のオープンソース開発は、ほぼ PyTorch と GPU をベースとしており、JAX と TPU によるソリューションとは根本的なギャップがあります。Tunix(Tune-in-JAX)は、このギャップを埋めるように設計された高パフォーマンスの JAX ネイティブ ライブラリです。
デザイン
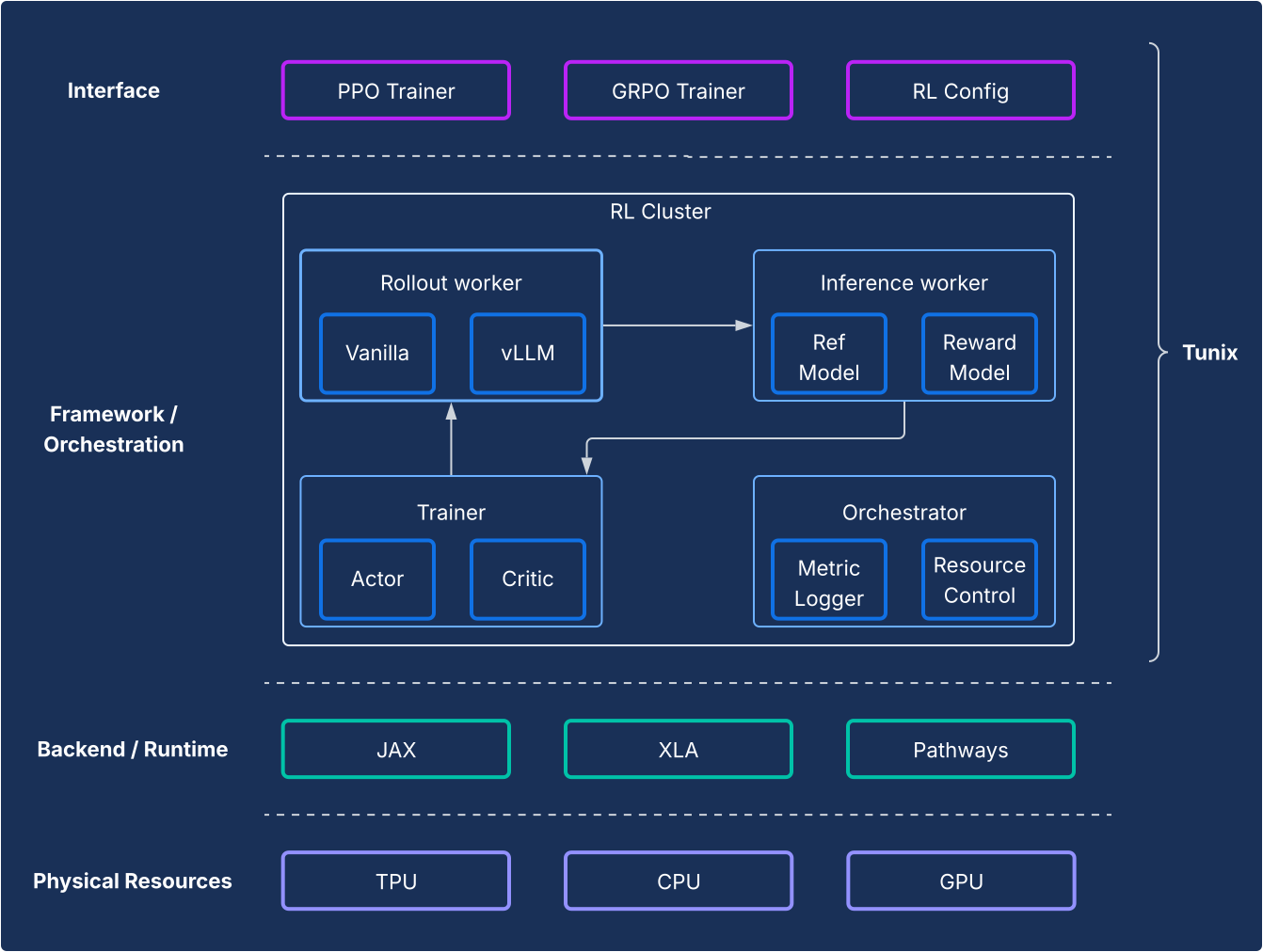
フレームワークの観点から見ると、Tunix は RL アルゴリズムとインフラストラクチャを明確に分離する最先端のセットアップを可能にします。軽量でクライアントのような API を提供し、RL インフラストラクチャの複雑さを隠して、新しいアルゴリズムを開発できるようにします。Tunix は、Proximal Policy Optimization(PPO)、Direct Preference Optimization(DPO)などの一般的なアルゴリズムに対応したすぐに使えるソリューションを提供します。
インフラストラクチャ側では、Tunix は Pathways と統合されており、マルチノード RL トレーニングを可能にする単一コントローラ アーキテクチャを実現しています。トレーニング側では、Tunix はパラメータ効率の高いトレーニング(LoRA など)をネイティブにサポートし、JAX シャーディングと XLA(ML 計算グラフ(GSPMD)の一般および拡張可能な並列化)を活用して、パフォーマンスの高いコンピューティング グラフを生成します。Gemma や Llama などの一般的なオープンソース モデルをすぐに利用できます。
主な強み
- シンプル: 基盤となる分散インフラストラクチャの複雑さを抽象化する、高レベルのクライアントのような API を提供します。
- デベロッパーの効率性: Tunix は、組み込みのアルゴリズムと「レシピ」を使用して研究開発ライフサイクルを加速させます。動作するモデルを提供して、迅速なイテレーションを可能にします。
- パフォーマンスとスケーラビリティ: Tunix は、バックエンドで Pathways を単一のコントローラとして活用することで、効率性が高く水平方向にスケーラブルなトレーニング インフラストラクチャを実現します。
アプリケーション レイヤ: 本番環境と推論
JAX の導入におけるこれまでの課題は、研究から本番環境への移行でした。JAX AI スタックは、エコシステムの互換性と JAX パフォーマンスの両方を提供する、成熟した 2 つのプロダクション ストーリーを提供します。
高性能 LLM 推論: vLLM ソリューション
vLLM-TPU は、Cloud TPU で PyTorch と JAX の大規模言語モデル(LLM)を効率的に実行するように設計された Google の高性能推論スタックです。これは、一般的なオープンソース vLLM フレームワークを Google の JAX および TPU エコシステムとネイティブに統合することで実現されます。
目的
業界は急速に進化しており、シームレスで高性能かつ使いやすい推論ソリューションに対する需要が高まっています。デベロッパーは、複雑で一貫性のないツール、パフォーマンスの低下、モデルの互換性の制限など、多くの課題に直面しています。vLLM スタックは、統合された高性能で直感的なプラットフォームを提供することで、これらの問題に対処しています。
デザイン
このソリューションは、vLLM フレームワークを再発明するのではなく、拡張します。vLLM-TPU は、高スループットで知られる高度に最適化されたオープンソースの LLM サービング エンジンです。これは、PagedAttention(仮想メモリのように KV キャッシュを管理して断片化を最小限に抑える)や Continuous Batching(バッチにリクエストを動的に追加して使用率を向上させる)などの主要機能を使用して実現されています。
vLLM-TPU はこの基盤に基づいて、リクエスト処理、スケジューリング、メモリ管理のコア コンポーネントを開発します。ブリッジとして機能する JAX ベースのバックエンドが導入され、vLLM の計算グラフとメモリ オペレーションが TPU 実行可能コードに変換されます。このバックエンドは、デバイスのインタラクション、JAX モデルの実行、TPU ハードウェアでの KV キャッシュの管理の詳細を処理します。これには、効率的なアテンション メカニズム(Ragged Paged Attention に JAX Pallas カーネルを活用するなど)や量子化など、TPU アーキテクチャに合わせて調整された TPU 固有の最適化が組み込まれています。
主な強み
- ユーザーのオンボーディング / オフボーディングのコストがゼロ: ユーザーは抵抗なくこのソリューションを採用できます。ユーザー エクスペリエンスの観点から見ると、TPU での推論リクエストの処理は GPU での処理と同じでなければなりません。サーバーを起動し、プロンプトを受け入れて出力を返す CLI はすべて共有されています。
- エコシステムを完全に活用する: このアプローチでは、vLLM インターフェースとユーザー エクスペリエンスを活用し、貢献することで、互換性と使いやすさを確保しています。
- TPU と GPU 間の互換性: このソリューションは TPU と GPU の両方で効率的に動作するため、柔軟性が高まります。
- 費用対効果(パフォーマンス / 費用の比率が最適): パフォーマンスを最適化して、一般的なモデルでパフォーマンスと費用の比率が最も高くなるようにします。
JAX サービング: Orbax シリアル化と Neptune サービング エンジン
LLM 以外のモデルや、完全に JAX ネイティブなパイプラインを必要とするユーザーには、Orbax シリアル化ライブラリと Neptune サービング エンジン(NSE)システムが、エンドツーエンドの高性能サービング ソリューションを提供します。
目的
これまで、JAX モデルは、TensorFlow グラフにラップして TensorFlow Serving でデプロイするなど、迂回的な方法で本番環境に移行することがよくありました。このアプローチには重大な制限と非効率性があり、デベロッパーは別のエコシステムに関与せざるを得ず、イテレーションも遅くなっていました。持続可能性、複雑さの軽減、パフォーマンスの最適化には、専用の JAX ネイティブ サービング システムが不可欠です。
デザイン
このソリューションは、次の図に示すように 2 つのコア コンポーネントで構成されています。
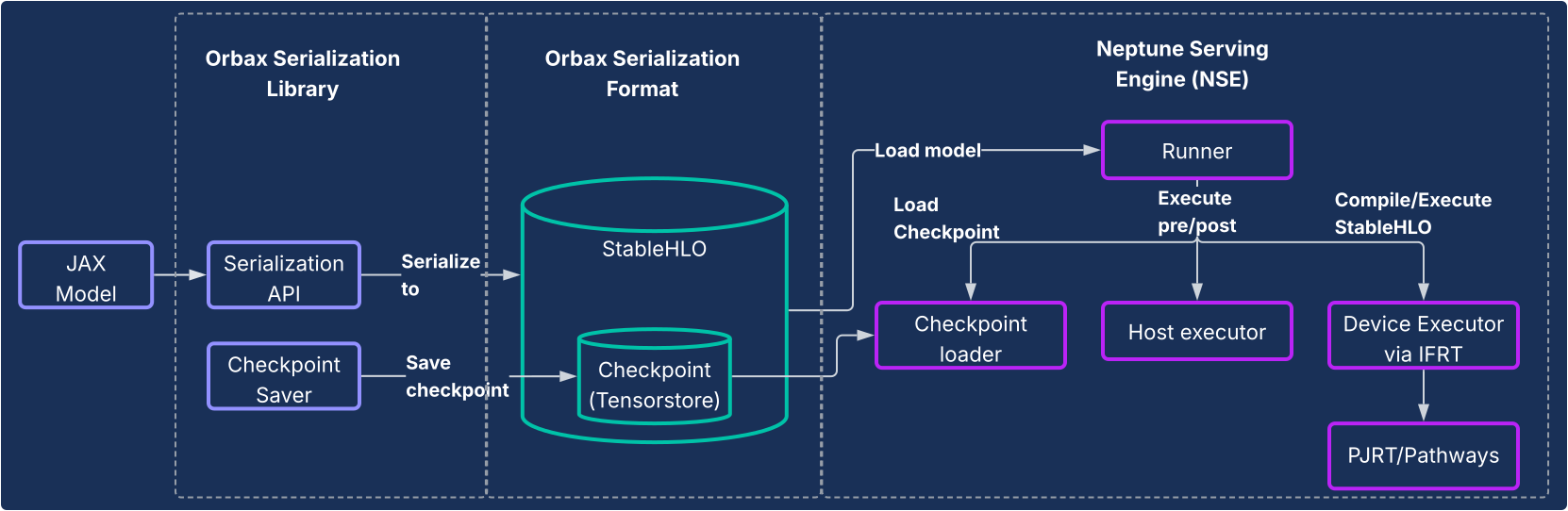
- Orbax シリアル化ライブラリ: JAX モデルを新しい堅牢な Orbax シリアル化形式に変換するための使いやすい API を提供します。この形式は、本番環境へのデプロイ用に最適化されています。StableHLO を使用して JAX モデルの計算を直接表すため、計算グラフをネイティブに表すことができます。また、重みの保存に TensorStore を活用し、サービング用のチェックポイントを高速で読み込めるようにしています。
- Neptune Serving Engine(NSE): これは、Orbax 形式で JAX モデルをネイティブに実行するように設計された、高パフォーマンスで柔軟なサービング エンジンです(通常は C++ バイナリとしてデプロイ)。NSE は、高速なモデル読み込み、バッチ処理が組み込まれた高スループットの同時サービング、複数のモデル バージョンのサポート、シングルホストとマルチホストの両方のサービング(PJRT と Pathways を活用)など、本番環境に不可欠な機能を提供します。Neptune Serving Engine は、次の用途で使用します。
- 非 LLM モデル: レコメンデーション システム、拡散モデル、その他の AI モデルなどのワークロードに最適な汎用ソリューションです。
- 小規模な LLM と「ワンショット」サービング: 非回帰モデルや、単項式でサービングされる小規模なモデル向けに設計されています。このモデルでは、KV キャッシュのような複雑な状態管理を必要とせず、1 回のパスで出力全体が生成されます。
つまり、Neptune Serving Engine は、大規模な自己回帰言語モデルではない、さまざまなモデルのサービングのギャップを埋め、より広範な ML エコシステムに高性能の TPU ネイティブ ソリューションを提供します。
主な強み
- JAX ネイティブ サービス: このソリューションは JAX 用にネイティブに構築されているため、モデルのシリアル化とサービングにおけるフレームワーク間のオーバーヘッドがなくなります。これにより、モデルの読み込みが高速になり、CPU、GPU、TPU での実行が最適化されます。
- 本番環境への簡単なデプロイ: シリアル化されたモデルは、Python 依存関係のドリフトの影響を受けず、ランタイム モデルの完全性チェックを可能にする密閉型のデプロイパスを提供します。これにより、JAX モデルのプロダクション化のためのシームレスで直感的なパスが提供されます。
- デベロッパー エクスペリエンスの向上: このソリューションは、煩雑なフレームワーク ラッピングの必要性を排除することで、依存関係とシステムの複雑さを大幅に軽減し、JAX デベロッパーのイテレーションを高速化します。
システム全体の分析とプロファイリング
XProf: ハードウェア統合型の詳細なパフォーマンス プロファイリング
XProf は、ML ワークロードの実行のさまざまな側面を詳細に可視化するプロファイリングとパフォーマンス分析ツールです。これにより、パフォーマンスをデバッグして最適化できます。JAX と TPU の両方のエコシステムに深く統合されています。
目的
ML ワークロードはますます複雑になっています。一方で、これらのワークロードをターゲットとする特殊なハードウェア機能が爆発的に増加しています。ML インフラストラクチャのコストは膨大であるため、ピーク パフォーマンスと効率を確保するために、この 2 つを効果的に一致させることが重要です。これには、ワークロードとハードウェアの両方を迅速に把握できる形で可視化する必要があります。XProf はこの点で優れています。
デザイン
XProf は、収集と分析という 2 つの主要コンポーネントで構成されています。
- 収集: XProf は、JAX コードのアノテーション、XLA コンパイラ内のオペレーションの費用モデル、TPU 内の専用ハードウェア プロファイリング機能など、さまざまなソースから情報を収集します。この収集は、プログラムでトリガーすることも、オンデマンドでトリガーすることもでき、包括的なイベント アーティファクトを生成します。
- 分析: XProf は収集されたデータを後処理し、ブラウザでアクセスできる強力な可視化スイートを作成します。
主な強み
XProf の真の力は、フルスタックとの深い統合にあります。これにより、共同設計された JAX / TPU エコシステムの具体的なメリットである、広範で詳細な分析が可能になります。
- TPU との共同設計: XProf は、プロファイルのシームレスな収集専用に設計されたハードウェア機能を活用し、収集オーバーヘッドを 1% 未満に抑えます。これにより、プロファイリングは軽量で反復的な開発の一部になります。
- 分析の幅と深さ: XProf は、複数の軸にわたって詳細な分析を行います。このツールには次の機能があります。
- Trace Viewer: さまざまなハードウェア ユニット(TensorCore など)での実行オペレーションのタイムライン ビュー。
- HLO Op Profile: 費やされた合計時間をさまざまなカテゴリのオペレーションに分類します。
- Memory Viewer: プロファイル ウィンドウでのさまざまなオペレーションによるメモリ割り当ての詳細を表示します。
- Roofline Analysis: 特定のオペレーションがコンピューティング依存型かメモリ依存型か、ハードウェアのピーク時の能力からどれだけ離れているかを特定する際に役立ちます。
- Graph Viewer: ハードウェアで実行される完全な HLO グラフを表示します。
比較の観点: JAX / TPU スタックは魅力的な選択肢
最新の ML 環境には、優れた成熟したツールチェーンが多数あります。JAX AI スタックは、大規模で高性能な ML に注力するデベロッパーにとって、独自の魅力的なメリットをもたらします。これは、モジュラー設計とハードウェアの深い共同設計に直接由来するものです。
多くのフレームワークは幅広い機能を提供していますが、JAX AI スタックは開発ライフサイクルの重要な分野で、具体的かつ強力な差別化要因を提供します。
- よりシンプルで強力なデベロッパー エクスペリエンス: Optax のチェーン可能な勾配変換パラダイムにより、トレーニング ループで命令的に管理するのではなく、一度宣言するだけで、より強力かつ柔軟な最適化戦略が可能になります。システムレベルでは、Pathways のシンプルな単一コントローラ インターフェースにより、マルチスライス トレーニングの複雑さが抽象化され、研究者にとって大幅な簡素化が実現します。
- 大規模な復元力を実現するように設計: JAX スタックは、大規模なトレーニング向けに設計されています。Orbax は、緊急チェックポインティングやマルチティア チェックポインティングなどの「桁外れのトレーニング復元力」を提供します。これは、決定論的なグローバル シャッフルとチェックポインティング可能なデータローダによる再現性を完全にサポートする Grain によって補完されます。データ パイプラインの状態(Grain)とモデルの状態(Orbax)をアトミックにチェックポインティングできる機能は、長時間実行されるジョブの再現性を保証するうえで重要な機能です。
- 完全なエンドツーエンドのエコシステム: スタックは、一貫性のあるエンドツーエンドのソリューションを提供します。デベロッパーは、トレーニングの SOTA リファレンスとして MaxText、アライメントに Tunix、vLLM 互換性に vLLM-TPU、JAX パフォーマンスに NSE を使用して、明確なデュアルパスで本番環境に移行できます。
高レベルのソフトウェアの観点から見ると、多くのスタックは似ていますが、決定要因は多くの場合、パフォーマンス / TCO になります。JAX と TPU の共同設計は、この点で明確なメリットをもたらします。このパフォーマンスと TCO のメリットは、ソフトウェアと TPU ハードウェアの垂直統合の直接的な結果です。XLA コンパイラが TPU アーキテクチャ専用のオペレーションを融合できることや、XProf プロファイラが 1% 未満のオーバーヘッドでプロファイリングを行うためにハードウェア フックを使用できることは、この深い統合の具体的なメリットです。
このスタックを採用する組織にとって、JAX AI スタックのフル機能により、移行のコストを最小限に抑えることができます。一般的なオープンモデル アーキテクチャを使用しているユーザーの場合、他のフレームワークから MaxText への移行は、多くの場合、構成ファイルの設定が問題となります。さらに、このスタックは safetensors などの一般的なチェックポイント形式を取り込むことができるため、コストのかかる再トレーニングを行うことなく、既存のチェックポイントを移行できます。
次の表に、JAX AI スタックで提供されるコンポーネントと、他のフレームワークやライブラリの同等のコンポーネントの対応を示します。
| 機能 | JAX | 他のフレームワークの代替機能 / 同等の機能5 |
| コンパイラ / ランタイム | XLA | Inductor、eager |
| マルチポッド トレーニング | Pathways | Torch Lightning の戦略、Ray Train、Monarch(新規)。 |
| コア フレームワーク | JAX | PyTorch |
| モデルの作成 | Flax、Max* モデル | torch.nn.*、NVidia TransformerEngine、HuggingFace Transformers |
| オプティマイザーと損失 | Optax | torch.optim.*, torch.nn.*Loss |
| データローダ | Grain | Ray Data、HuggingFace データローダ |
| チェックポインティング | Orbax | PyTorch 分散チェックポインティング、NeMo チェックポインティング |
| 量子化 | Qwix | TorchAO、bitsandbytes |
| カーネルの作成と既知の実装 | Pallas / Tokamax | Triton/Helion、Liger-kernel、TransformerEngine |
| トレーニング / チューニング後 | Tunix | VERL、NeMoRL |
| プロファイリング | XProf | PyTorch プロファイラ、NSight システム、NSight Compute |
| 基盤モデルのトレーニング | MaxText、MaxDiffusion | NeMo-Megatron、DeepSpeed、TorchTitan |
| LLM 推論 | vLLM | SGLang |
| 非 LLM 推論 | NSE | Triton Inference Server、RayServe |
5他のフレームワークでは JAX とは異なる方法で API 境界が設定されているため、ここで示されている同等の処理は必ずしも同等とは限りません。同等のライブラリのリストはすべてを網羅しているわけではなく、新しいライブラリが頻繁に登場しています。
まとめ: AI の未来に向けた、持続可能な本番環境対応プラットフォーム
前の表のデータは、自明の結論を示しています。これらのスタックには、少数の領域で独自の長所と短所がありますが、全体的にはソフトウェアの観点から非常に類似しています。どちらのスタックも、基盤モデルの事前トレーニング、トレーニング後の適応、デプロイのためのターンキー ソリューションを提供します。
JAX AI スタックは、あらゆる規模で ML モデルをトレーニングしてデプロイするための魅力的で堅牢なソリューションを提供します。ソフトウェアと TPU ハードウェア間の深い垂直統合を活用して、クラス最高のパフォーマンスと総所有コストを実現します。
実戦でテスト済みの内部システムを基盤として構築されたこのスタックは、信頼性とスケーラビリティを本質的に備えるように進化しました。これにより、ユーザーは最大規模のモデルでも安心して開発、デプロイすることができます。JAX AI スタックの哲学に根ざしたモジュール式で作成可能な設計により、ユーザーは比類のない自由と制御を得て、モノリシック フレームワークの制約を受けることなく、特定のニーズに合わせてスタックを調整できます。
スケーラブルでフォールト トレラントなベースを提供する XLA と Pathways、パフォーマンスと表現力に優れた数値ライブラリを提供する JAX、Flax、Optax、Grain、Orbax などの強力なコア開発ライブラリ、Pallas、Tokamax、Qwix などの高度なパフォーマンス ツール、MaxText、vLLM、NSE の堅牢なアプリケーションとプロダクション レイヤを備えた JAX AI スタックは、ユーザーが構築し、最先端の研究を迅速に本番環境に移行するための堅牢な基盤を提供します。