
Crear IA de producción en TPUs de Cloud con JAX
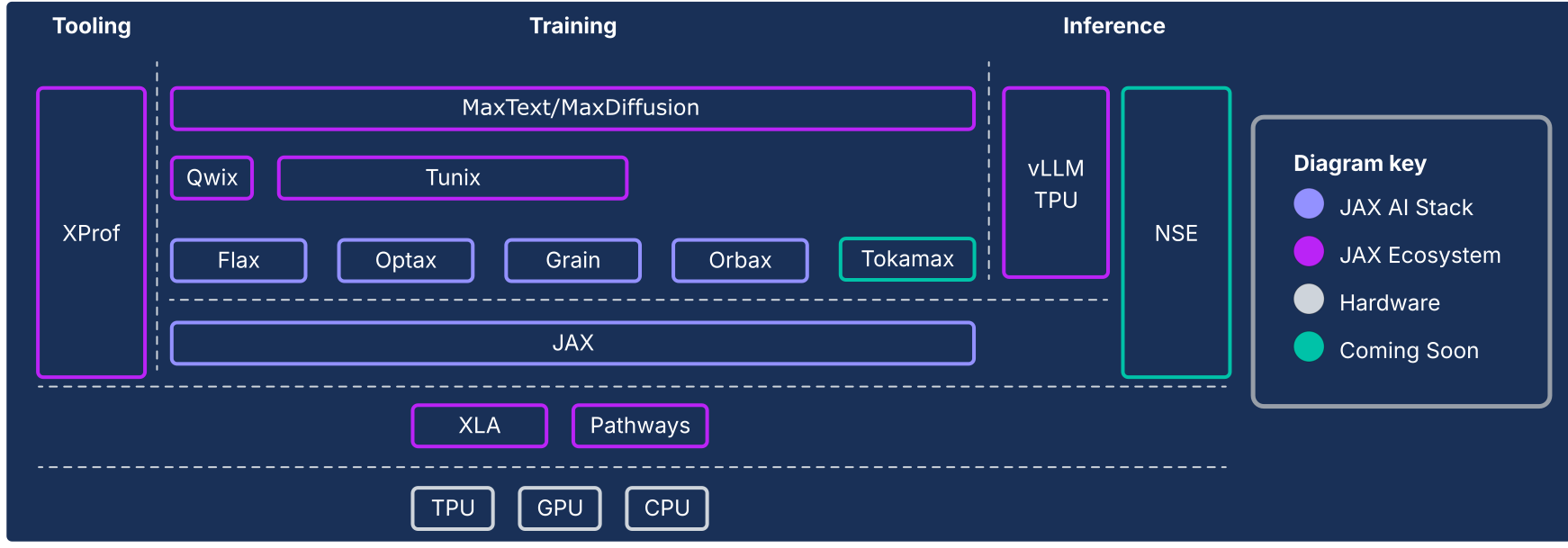
La pila de IA de JAX amplía el núcleo numérico de JAX con una colección de bibliotecas componibles respaldadas por Google, lo que la convierte en una plataforma de código abierto sólida, integral y a gran escala para el aprendizaje automático. Por lo tanto, la pila de IA de JAX consta de un ecosistema completo y robusto que abarca todo el ciclo de vida del aprendizaje automático:
Base a escala industrial: la pila de IA de JAX se ha diseñado para ofrecer una escala masiva. Para ello, aprovecha ML Pathways para orquestar el entrenamiento en decenas de miles de chips y Orbax para ofrecer un registro de puntos de control asíncrono, resistente y de alto rendimiento, lo que permite entrenar modelos de última generación con calidad de producción.
Kit de herramientas completo y listo para producción: la pila de IA de JAX proporciona un conjunto completo de bibliotecas para todo el proceso de desarrollo: Flax para la creación de modelos flexibles, Optax para estrategias de optimización componibles y Grain para las canalizaciones de datos deterministas esenciales para ejecuciones reproducibles a gran escala.
Rendimiento especializado y óptimo: para conseguir el máximo uso del hardware, la pila de IA de JAX ofrece bibliotecas especializadas, como Tokamax, para kernels personalizados de vanguardia; Qwix, para una cuantización no intrusiva que aumenta la velocidad de entrenamiento e inferencia; y XProf, para una creación de perfiles de rendimiento profunda e integrada en el hardware.
Ruta completa a la producción: la pila de IA de JAX proporciona una transición fluida de la investigación a la implementación. Esto incluye MaxText como referencia escalable para el entrenamiento de modelos fundacionales, Tunix para el aprendizaje reforzado (RL) y la alineación de vanguardia, y una solución de inferencia unificada con la integración de vLLM TPU y el tiempo de ejecución de servicio de JAX.
La filosofía de la pila de IA de JAX se basa en componentes poco acoplados, cada uno de los cuales hace una cosa bien. En lugar de ser un framework de aprendizaje automático monolítico, JAX tiene un ámbito reducido y se centra en operaciones de arrays eficientes y transformaciones de programas. El ecosistema se basa en este marco principal para proporcionar una amplia gama de funciones relacionadas tanto con el entrenamiento de modelos de aprendizaje automático como con otros tipos de cargas de trabajo, como la computación científica.
Este sistema de componentes poco acoplados te permite seleccionar y combinar bibliotecas de la forma que mejor se adapte a tus requisitos. Desde el punto de vista de la ingeniería de software, esta arquitectura también te permite actualizar de forma iterativa funciones que tradicionalmente se considerarían componentes principales del framework (por ejemplo, las canalizaciones de datos y la creación de puntos de control) sin el riesgo de desestabilizar el framework principal ni de quedarte atrapado en los ciclos de lanzamiento. Dado que la mayoría de las funciones se implementan en bibliotecas en lugar de en cambios en un framework monolítico, esto hace que la biblioteca numérica principal sea más duradera y adaptable a los cambios futuros en el panorama tecnológico.
En las siguientes secciones se ofrece una descripción técnica general de la pila de IA de JAX, sus principales funciones, las decisiones de diseño que se han tomado y cómo se combinan para crear una plataforma duradera para las cargas de trabajo de aprendizaje automático modernas.
La pila de IA de JAX y otros componentes del ecosistema
| Componente | Función o descripción |
|---|---|
| Componentes y núcleo de la pila de IA de JAX1 | |
| JAX | Cálculo de arrays y transformación de programas orientados a aceleradores (JIT, grad, vmap, pmap). |
| Lino | Biblioteca flexible de creación de redes neuronales para crear y modificar modelos de forma intuitiva. |
| Optax | Una biblioteca de transformaciones de procesamiento y optimización de gradientes componibles. |
| Orbax | Biblioteca de creación de puntos de control distribuidos a cualquier escala para la resiliencia del entrenamiento a gran escala. |
| Grano | Una biblioteca de flujo de procesamiento de datos de entrada escalable, determinista y con puntos de control. |
| Pila de IA de JAX: infraestructura | |
| XLA | Compilador de aprendizaje automático de código abierto para TPUs, CPUs y GPUs. |
| Pathways | Tiempo de ejecución distribuido para orquestar la computación en decenas de miles de chips. |
| Pila de IA de JAX - Avanzado Desarrollo | |
| Palas | Una extensión de JAX para escribir kernels personalizados de bajo nivel y alto rendimiento implementados en Python. |
| Tokamax | Una biblioteca seleccionada de kernels personalizados de alto rendimiento y vanguardistas (por ejemplo, Attention). |
| Qwix | Una biblioteca completa y no intrusiva para la cuantización (PTQ, QAT y QLoRA). |
| Pila de IA de JAX: aplicación | |
| MaxText o MaxDiffusion | Frameworks de referencia emblemáticos y escalables para entrenar modelos fundacionales (por ejemplo, LLM y Diffusion). |
| Tunix | Un framework para el entrenamiento posterior y la alineación (RLHF y DPO) de última generación. |
| vLLM | Una solución de inferencia de LLM de alto rendimiento que usa la integración integrada del framework vLLM. |
| XProf | Un profiler integrado en el hardware para analizar el rendimiento de todo el sistema. |
1 Incluido en el paquete de Python jax-ai-stack.
Imagen 1: Componentes de la pila de IA y del ecosistema de JAX
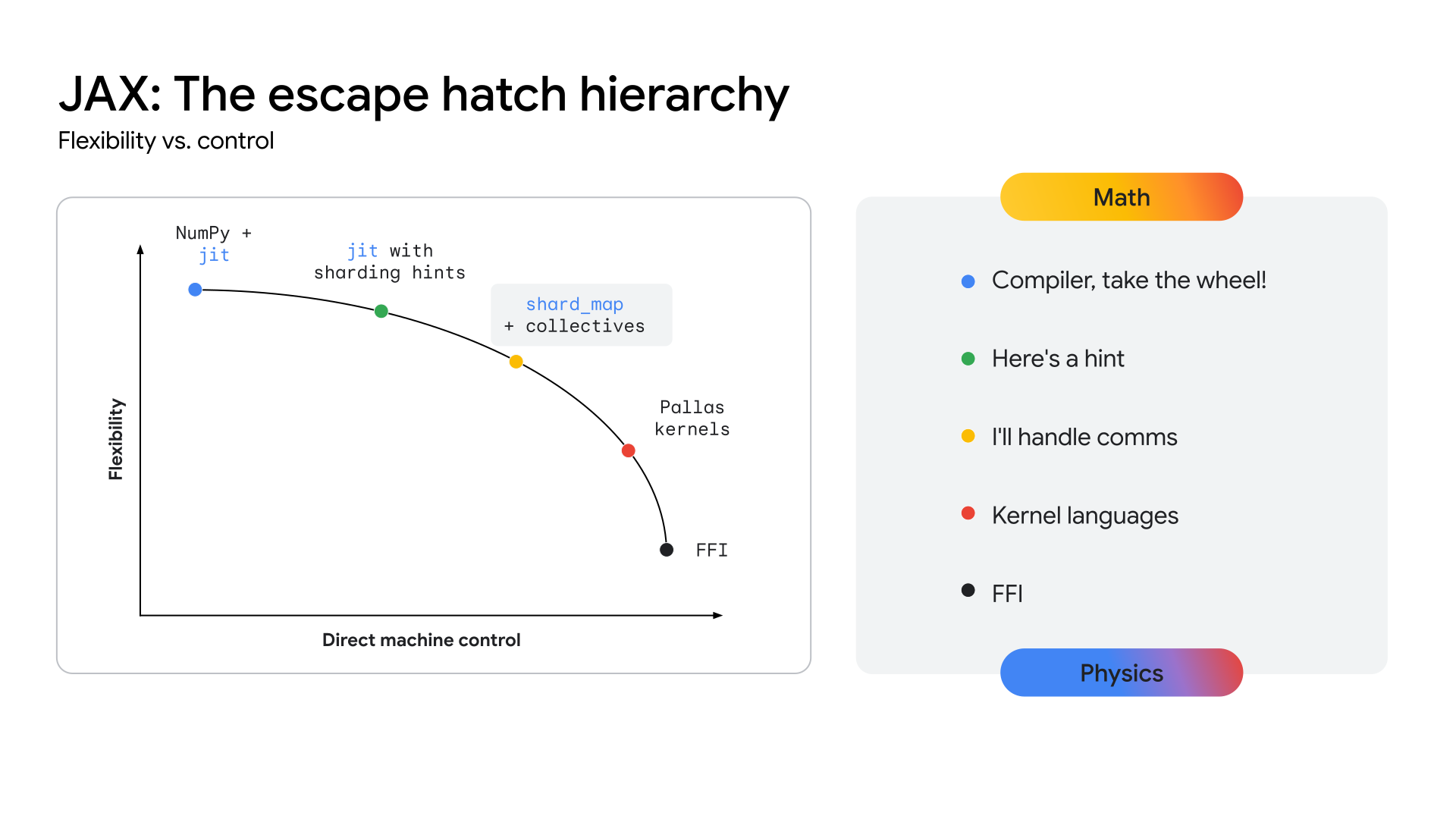
El imperativo arquitectónico: rendimiento más allá de los frameworks
A medida que las arquitecturas de los modelos convergen (por ejemplo, en los Transformers multimodales de Mixture-of-Experts [MoE]), la búsqueda del máximo rendimiento está dando lugar a la aparición de megakernels. Un megakernel es, en esencia, todo el pase hacia delante (o una gran parte) de un modelo específico, codificado manualmente con una API de nivel inferior, como el SDK de CUDA en GPUs NVIDIA. Este enfoque consigue una utilización máxima del hardware superponiendo de forma agresiva el cálculo, la memoria y la comunicación. En trabajos recientes de la comunidad investigadora se ha demostrado que este enfoque puede proporcionar mejoras significativas en el rendimiento, de más del 22% en algunos casos, para la inferencia en GPUs. Esta tendencia no se limita a la inferencia. Hay pruebas que sugieren que algunas iniciativas de entrenamiento a gran escala han implicado un control de hardware de bajo nivel para lograr mejoras sustanciales en la eficiencia.
Si esta tendencia se acelera, todos los frameworks de alto nivel tal como existen hoy en día corren el riesgo de perder relevancia, ya que el acceso de bajo nivel al hardware es lo que importa en última instancia para el rendimiento en arquitecturas estables y maduras. Esto supone un reto para todas las pilas de AA modernas: cómo proporcionar un control de hardware de nivel experto sin sacrificar la productividad y la flexibilidad de un framework de alto nivel.
Para que las TPUs proporcionen una ruta clara a este nivel de rendimiento, el ecosistema debe exponer una capa de API más cercana al hardware, lo que permitirá desarrollar estos kernels altamente especializados. La pila JAX se ha diseñado para resolver este problema ofreciendo un continuo de abstracción (consulta la figura 2), desde las optimizaciones automatizadas de alto nivel del compilador XLA hasta el control manual y preciso de la biblioteca de creación de kernels de Pallas.
Imagen 2: Continuo de abstracción de JAX
La pila de IA principal de JAX
La pila de IA de JAX consta de cinco bibliotecas clave que proporcionan la base para el desarrollo de modelos:
JAX: una base para la transformación de programas componibles y de alto rendimiento
JAX es una biblioteca de Python para la computación de arrays orientada a aceleradores y la transformación de programas, diseñada para la computación numérica de alto rendimiento y el aprendizaje automático a gran escala. Gracias a su modelo de programación funcional y a su API similar a NumPy, JAX proporciona una base sólida para bibliotecas de nivel superior.
Gracias a su diseño basado en el compilador, JAX promueve la escalabilidad de forma inherente aprovechando XLA (consulta la sección de XLA) para realizar análisis, optimizaciones y segmentaciones de hardware agresivos de todo el programa. El énfasis de JAX en la programación funcional (por ejemplo, las funciones puras) hace que sus transformaciones de programas principales sean más manejables y, lo que es más importante, combinables.
Estas transformaciones principales se pueden combinar para conseguir un alto rendimiento y escalabilidad de las cargas de trabajo en función del tamaño del modelo, el tamaño del clúster y los tipos de hardware:
- jit: compilación justo a tiempo de funciones de Python en ejecutables de XLA optimizados y fusionados.
- grad: diferenciación automática, compatible con los modos hacia delante y hacia atrás, así como con derivadas de orden superior.
- vmap: vectorización automática que permite agrupar y paralelizar datos sin problemas sin modificar la lógica de las funciones.
- pmap/shard_map: paralelización automática en varios dispositivos (por ejemplo, núcleos de TPU), que constituye la base del entrenamiento distribuido.
La integración perfecta con el modelo GSPMD (SPMD de uso general) de XLA permite a JAX paralelizar automáticamente los cálculos en pods de TPU grandes con cambios mínimos en el código. En la mayoría de los casos, el escalado solo requiere anotaciones de fragmentación de alto nivel.
Flax: creación flexible de redes neuronales
Flax simplifica la creación, la depuración y el análisis de redes neuronales en JAX. Para ello, proporciona un enfoque intuitivo y orientado a objetos para la creación de modelos. Aunque la API funcional de JAX es potente, ofrece una abstracción basada en capas más familiar para los desarrolladores acostumbrados a frameworks como PyTorch, sin que esto suponga una pérdida de rendimiento.
Este diseño simplifica la modificación o la combinación de componentes de modelos entrenados.
Las técnicas como LoRA y la cuantización requieren definiciones de modelos manipulables, que la API NNX de Flax proporciona a través de una interfaz de Python. NNX encapsula el estado del modelo, reduce la carga cognitiva del usuario y permite el recorrido y la modificación programáticos de la jerarquía del modelo.
Puntos fuertes:
- API intuitiva orientada a objetos: simplifica la creación de modelos y permite casos prácticos avanzados, como la sustitución de submódulos y la inicialización parcial.
- Coherente con el JAX principal: Flax proporciona transformaciones elevadas que son totalmente compatibles con el paradigma funcional de JAX, lo que ofrece el rendimiento completo de JAX con una mayor facilidad de uso para los desarrolladores.
Optax: estrategias de optimización y procesamiento de gradientes componibles
Optax es una biblioteca de optimización y procesamiento de gradientes para JAX. Está diseñada para proporcionar a los creadores de modelos elementos de creación que se pueden recombinar de forma personalizada para entrenar modelos de aprendizaje profundo, entre otras aplicaciones. Se basa en las funciones de la biblioteca principal de JAX para proporcionar una biblioteca de alto rendimiento y bien probada de funciones de pérdida y optimizador, así como técnicas asociadas que se pueden usar para entrenar modelos de aprendizaje automático.
Motivación
El cálculo y la minimización de las pérdidas son la base que permite entrenar modelos de aprendizaje automático. Gracias a su compatibilidad con la diferenciación automática, la biblioteca JAX principal proporciona las funciones numéricas necesarias para entrenar modelos, pero no ofrece implementaciones estándar de optimizadores populares (por ejemplo, RMSProp o Adam) ni de pérdidas (por ejemplo, CrossEntropy o MSE). Aunque podrías implementar estas funciones (y algunos desarrolladores avanzados lo harán), un error en la implementación de un optimizador podría provocar problemas de calidad en el modelo difíciles de diagnosticar. En lugar de que el usuario implemente estas partes críticas, Optax proporciona implementaciones de estos algoritmos que se prueban para comprobar su corrección y rendimiento.
El campo de la teoría de la optimización se encuentra directamente en el ámbito de la investigación, pero su papel central en el entrenamiento también lo convierte en una parte indispensable del entrenamiento de modelos de aprendizaje automático de producción. Una biblioteca que cumpla este papel debe ser lo suficientemente flexible para adaptarse a las iteraciones rápidas de investigación, así como lo suficientemente sólida y eficiente para que se pueda usar de forma fiable en el entrenamiento de modelos de producción. También debe proporcionar implementaciones bien probadas de algoritmos de vanguardia que coincidan con las ecuaciones estándar. La biblioteca Optax se ha diseñado para conseguirlo gracias a su arquitectura modular y composable, y a su énfasis en el código legible y correcto.
Diseño
Optax se ha diseñado para mejorar tanto la velocidad de investigación como la transición de la investigación a la producción. Para ello, proporciona implementaciones legibles, bien probadas y eficientes de algoritmos básicos. Optax tiene otros usos además del aprendizaje profundo. Sin embargo, en este contexto, se puede considerar como una colección de funciones de pérdida, algoritmos de optimización y transformaciones de gradiente conocidos que se han implementado de forma puramente funcional de acuerdo con la filosofía de JAX. La colección de funciones de pérdida y optimizadores permite a los usuarios empezar a usar la API con facilidad y confianza.
El enfoque modular de Optax te permite encadenar varios optimizadores seguidos de otras transformaciones comunes (por ejemplo, el recorte de gradiente) y envolverlos con técnicas habituales como MultiStep o Lookahead para conseguir estrategias de optimización eficaces con unas pocas líneas de código. La interfaz flexible te permite investigar nuevos algoritmos de optimización y usar potentes técnicas de optimización de segundo orden, como shampoo o muon.
# Optax implementation of a RMSProp optimizer with a custom learning rate
# schedule, gradient clipping and gradient accumulation.
optimizer = optax.chain(
optax.clip_by_global_norm(GRADIENT_CLIP_VALUE),
optax.rmsprop(learning_rate=optax.cosine_decay_schedule(init_value=lr,decay_steps=decay)),
optax.apply_every(k=ACCUMULATION_STEPS)
)
# The same thing, in PyTorch
optimizer = optim.RMSprop(model_params, lr=LEARNING_RATE)
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=TOTAL_STEPS)
for i, (inputs, targets) in enumerate(data_loader):
# ... Training loop body ...
if (i + 1) % ACCUMULATION_STEPS == 0:
torch.nn.utils.clip_grad_norm_(model.parameters(), GRADIENT_CLIP_VALUE)
optimizer.step()
scheduler.step()
optimizer.zero_grad()
El fragmento de código anterior muestra cómo configurar un optimizador con una tasa de aprendizaje personalizada, un recorte de gradiente y una acumulación de gradiente.
Puntos fuertes principales
- Biblioteca sólida: ofrece una biblioteca completa de pérdidas, optimizadores y algoritmos centrada en la precisión y la legibilidad.
- Transformaciones encadenables modulares: esta API flexible te permite crear estrategias de optimización potentes y complejas de forma declarativa sin modificar el bucle de entrenamiento.
- Funcional y escalable: las implementaciones funcionales puras se integran perfectamente con los mecanismos de paralelización de JAX (por ejemplo, pmap), lo que te permite usar el mismo código para escalar de un solo host a clústeres grandes.
Orbax o TensorStore: creación de puntos de control distribuidos a gran escala
Orbax es una biblioteca de creación de puntos de control para JAX diseñada para cualquier escala, desde un solo dispositivo hasta el entrenamiento distribuido a gran escala. Su objetivo es unificar las implementaciones de puntos de control fragmentadas y ofrecer funciones de rendimiento críticas, como los puntos de control asíncronos y multinivel, a una audiencia más amplia. Orbax permite la resiliencia necesaria para los trabajos de entrenamiento masivos y proporciona un formato flexible para publicar puntos de control.
A diferencia de los sistemas de creación y restauración de puntos de control generalizados que hacen una instantánea de todo el estado del sistema, la creación de puntos de control de aprendizaje automático con Orbax solo conserva de forma selectiva la información esencial para reanudar el entrenamiento: pesos del modelo, estado del optimizador y estado del cargador de datos. Este enfoque específico minimiza el tiempo de inactividad del acelerador. Orbax lo consigue superponiendo las operaciones de E/S con los cálculos, una función fundamental para las cargas de trabajo grandes. El tiempo de inactividad de los aceleradores se reduce a la duración de la transferencia de datos del dispositivo al host, que se puede superponer aún más con el siguiente paso de entrenamiento, lo que hace que la creación de puntos de control sea prácticamente gratuita desde el punto de vista del rendimiento.
En esencia, Orbax usa TensorStore para leer y escribir datos de arrays de forma eficiente y paralela. La API Orbax abstrae esta complejidad y ofrece una interfaz fácil de usar para gestionar PyTrees, que son la representación estándar de los modelos en JAX.
Puntos fuertes:
- Adopción generalizada: con millones de descargas al mes, Orbax sirve como medio común para compartir artefactos de aprendizaje automático.
- Simplifica las complejidades: Orbax abstrae las complejidades de la creación de puntos de control distribuidos, como el guardado asíncrono, la atomicidad y los detalles del sistema de archivos.
- Flexible: aunque ofrece APIs para casos prácticos habituales, Orbax te permite personalizar tu flujo de trabajo para gestionar requisitos especializados.
- Rendimiento y escalabilidad: funciones como la creación de puntos de control asíncrona, un formato de almacenamiento eficiente (OCDBT) y estrategias de carga de datos inteligentes aseguran que Orbax se adapte a entrenamientos que impliquen decenas de miles de nodos.
Grain: flujos de procesamiento de datos de entrada deterministas y escalables
Grain es una biblioteca de Python para leer y procesar datos para entrenar y evaluar modelos de JAX. Es flexible, rápida y determinista, y admite funciones avanzadas como la creación de puntos de control, que son esenciales para entrenar correctamente cargas de trabajo grandes. Admite formatos de datos y back-ends de almacenamiento populares, y también proporciona una API flexible para ampliar la compatibilidad con formatos y back-ends específicos del usuario que no se admiten de forma nativa. Aunque Grain se ha diseñado principalmente para funcionar con JAX, es independiente del framework, no requiere JAX para ejecutarse y también se puede usar con otros frameworks.
Motivación
Las canalizaciones de datos son una parte fundamental de la infraestructura de entrenamiento. Deben ser flexibles para que las transformaciones comunes se puedan expresar de forma eficiente y lo suficientemente eficaces para que los aceleradores estén ocupados en todo momento. También deben poder admitir varios formatos de almacenamiento y back-ends. Debido a sus tiempos de paso más largos, el entrenamiento de modelos grandes a gran escala plantea requisitos adicionales en el flujo de datos, además de los que requieren las cargas de trabajo de entrenamiento habituales, que se centran principalmente en el determinismo y la reproducibilidad.2 La biblioteca Grain se ha diseñado con una arquitectura flexible que aborda estas necesidades.
2En la sección 5.1 del documento de PaLM, los autores señalan que observaron picos de pérdidas muy grandes a pesar de tener habilitado el recorte de gradiente. La solución fue eliminar los lotes de datos problemáticos y reiniciar el entrenamiento desde un punto de control anterior al pico de pérdida. Esto solo es posible con una configuración de entrenamiento totalmente determinista y reproducible.
Diseño
En el nivel más alto, hay dos formas de estructurar una canalización de entrada: como un clúster independiente de trabajadores de datos o colocando los trabajadores de datos en los hosts que controlan los aceleradores. Grain elige esta opción por varios motivos.
Los aceleradores se combinan con hosts potentes que suelen estar inactivos durante los pasos de entrenamiento, lo que los convierte en una opción natural para ejecutar la canalización de datos de entrada. Esta implementación ofrece otras ventajas, como simplificar la vista de la fragmentación de datos, ya que proporciona una vista coherente de la fragmentación en las entradas y los cálculos. Se podría argumentar que colocar el trabajador de datos en el host del acelerador conlleva el riesgo de saturar la CPU del host. Sin embargo, esto no impide descargar las transformaciones intensivas de computación a otro clúster mediante RPCs.3
En cuanto a la API, con una implementación pura de Python que admite varios procesos y una API flexible, Grain te permite implementar transformaciones de datos arbitrariamente complejas componiendo fases de la canalización en función de paradigmas de transformación bien definidos.
De forma predeterminada, Grain admite formatos de datos de acceso aleatorio eficientes, como ArrayRecord y Bagz, junto con otros formatos de datos populares, como Parquet y TFDS. Grain incluye compatibilidad para leer datos de sistemas de archivos locales, así como de Cloud Storage de forma predeterminada. Además de admitir formatos de almacenamiento y back-ends populares, una abstracción limpia de la capa de almacenamiento te permite añadir compatibilidad con tus fuentes de datos o envolverlas para que sean compatibles con la biblioteca Grain.
3Así es como deben funcionar las canalizaciones de datos multimodales: los tokenizadores de imágenes y audio, por ejemplo, son modelos que se ejecutan en sus propios clústeres en sus propios aceleradores, y las canalizaciones de entrada harían llamadas RPC para convertir ejemplos de datos en flujos de tokens.
Puntos fuertes principales
- Introducción de datos determinista: la colocación del trabajador de datos con el acelerador y su combinación con un orden aleatorio global estable e iteradores con puntos de control permiten que el estado del modelo y el estado de la canalización de datos se guarden en un punto de control en una instantánea coherente mediante Orbax, lo que mejora el determinismo del proceso de entrenamiento.
- APIs flexibles para habilitar transformaciones de datos eficaces: una API de transformaciones flexible y pura de Python te permite realizar transformaciones de datos extensas en la canalización de procesamiento de entrada.
- Compatibilidad extensible con varios formatos y back-ends: una API de fuentes de datos extensible admite formatos y back-ends de almacenamiento populares, y te permite añadir compatibilidad con nuevos formatos y back-ends.
- Interfaz de depuración eficaz: las herramientas de visualización de flujos de procesamiento de datos y un modo de depuración te permiten inspeccionar, depurar y optimizar el rendimiento de tus flujos de procesamiento de datos.
Pila de IA de JAX ampliada
Además de la pila principal, un ecosistema completo de bibliotecas especializadas proporciona la infraestructura, las herramientas avanzadas y las soluciones de la capa de aplicación necesarias para el desarrollo de aprendizaje automático integral.
Infraestructura fundamental: compiladores y tiempos de ejecución
XLA: el motor independiente del hardware y centrado en el compilador
Motivación
XLA o álgebra lineal acelerado es el compilador específico de dominio de Google, que está bien integrado en JAX y es compatible con dispositivos de hardware de TPU, CPU y GPU. XLA se diseñó para ser un generador de código independiente del hardware que se dirige a TPUs, GPUs y CPUs.
El diseño del compilador XLA, que se basa en el compilador, es una decisión arquitectónica fundamental que crea una ventaja duradera en un panorama de investigación en rápida evolución. Por el contrario, el enfoque predominante centrado en el kernel de otros ecosistemas se basa en bibliotecas optimizadas manualmente para mejorar el rendimiento. Aunque es muy eficaz para las arquitecturas de modelos estables y bien establecidas, crea un cuello de botella para la innovación. Cuando una nueva investigación introduce arquitecturas novedosas, el ecosistema debe esperar a que se escriban y optimicen nuevos kernels. Sin embargo, nuestro diseño centrado en el compilador a menudo puede generalizarse a nuevos patrones, lo que proporciona una ruta de alto rendimiento para la investigación de vanguardia desde el primer día.
Diseño
XLA funciona compilando en tiempo de ejecución (JIT) los gráficos de cálculo que genera JAX
durante su proceso de seguimiento (por ejemplo, cuando se decora una función
con @jax.jit).
Esta compilación sigue una canalización de varias fases:
- Gráfico de computación de JAX
- Optimizador de alto nivel (HLO)
- Optimizador de bajo nivel (LLO)
- Código de hardware
- De JAX Graph a HLO: el gráfico de computación de JAX se convierte en la representación HLO de XLA. En este nivel alto, se aplican optimizaciones potentes e independientes del hardware, como la fusión de operadores y la gestión eficiente de la memoria. El dialecto StableHLO sirve de interfaz duradera y versionada para esta fase.
- De HLO a LLO: después de las optimizaciones de alto nivel, los back-ends específicos del hardware toman el control y convierten la representación de HLO en un LLO orientado a la máquina.
- De LLO a código de hardware: el LLO se compila finalmente en código de máquina de alta eficiencia. En el caso de las TPUs, este código se agrupa en paquetes Very Long Instruction Word (VLIW) que se envían directamente al hardware.
Para el escalado, el diseño de XLA se basa en el paralelismo. Emplea algoritmos para usar al máximo las unidades de multiplicación de matrices (MXUs) de un chip. Entre los chips, XLA usa SPMD (Single Program Multiple Data), una técnica de paralelización basada en el compilador que usa un solo programa en todos los dispositivos. Este potente modelo se expone a través de las APIs de JAX, lo que te permite gestionar el paralelismo de datos, modelos o pipelines con anotaciones de fragmentación de alto nivel.
Para patrones de paralelismo más complejos, también se puede usar Multiple Program Multiple Data (MPMD)
y bibliotecas como PartIR:MPMD permiten a los usuarios de JAX proporcionar
anotaciones de MPMD.
Puntos fuertes principales
- Compilación: la compilación justo a tiempo del gráfico de computación permite optimizar el diseño de la memoria, la asignación de búferes y la gestión de la memoria. Las alternativas, como las metodologías basadas en el kernel, transfieren esa carga al desarrollador. En la mayoría de los casos, XLA puede ofrecer un rendimiento excelente sin comprometer la velocidad de desarrollo.
- Paralelismo: XLA implementa varias formas de paralelismo con SPMD, y esto se expone a nivel de JAX. Esto te permite expresar estrategias de partición, lo que permite experimentar y escalar modelos en miles de chips.
Pathways: un tiempo de ejecución unificado para la computación distribuida a gran escala
Pathways ofrece abstracciones para el entrenamiento y la inferencia distribuidos con tolerancia a fallos y recuperación integradas, lo que permite a los investigadores de aprendizaje automático programar como si estuvieran usando una sola máquina potente.
Motivación
Para poder entrenar y desplegar modelos grandes, se necesitan entre cientos y miles de chips. Estos chips se distribuyen en numerosos racks y máquinas host. Un trabajo de entrenamiento es un programa síncrono a gran escala que requiere que todos estos chips y sus respectivos hosts trabajen conjuntamente en cálculos de XLA que se hayan paralelizado (fragmentado). En el caso de los modelos de lenguaje extensos, que pueden necesitar más de decenas de miles de chips, este servicio debe poder abarcar varios pods en una estructura de centro de datos, además de usar estructuras de interconexión entre chips (ICI) y de interconexión en el chip (OCI) en un pod.
Diseño
ML Pathways es el sistema que usamos para coordinar los cálculos distribuidos entre hosts y chips TPU. Está diseñado para ofrecer escalabilidad y eficiencia en cientos de miles de aceleradores. Para el entrenamiento a gran escala, proporciona un único cliente de Python para varios trabajos de Pod, integración de Megascale XLA, servicio de compilación y Python remoto. También admite el paralelismo entre slices y la tolerancia a la expropiación, lo que permite la recuperación automática de las expropiaciones de recursos.
Pathways incorpora colectivos entre hosts optimizados que permiten que los gráficos de computación de XLA se extiendan más allá de un solo Pod de TPU. Amplía la compatibilidad de XLA con el paralelismo de datos, modelos y pipelines para que funcione en los límites de los slices de TPU mediante la red de centros de datos (DCN) integrando un tiempo de ejecución distribuido que gestiona la comunicación de la DCN con las primitivas de comunicación de XLA.
Puntos fuertes principales
La arquitectura de un solo controlador, integrada con JAX, es una abstracción clave. Permite a los investigadores explorar varias estrategias de fragmentación y paralelismo para el entrenamiento y la implementación, al tiempo que se adapta a decenas de miles de chips con facilidad.
Desarrollo avanzado: rendimiento, datos y eficiencia
Pallas: escribir kernels personalizados de alto rendimiento en JAX
Aunque JAX es un compilador, hay situaciones en las que puede que quieras tener un control preciso sobre el hardware para conseguir el máximo rendimiento. Pallas es una extensión de JAX que permite escribir kernels personalizados para GPUs y TPUs. Su objetivo es ofrecer un control preciso sobre el código generado, combinado con la ergonomía de alto nivel del seguimiento de JAX y la API jax.numpy.
Pallas expone un modelo de paralelismo basado en una cuadrícula en el que se inicia una función de kernel definida por el usuario en una cuadrícula multidimensional de grupos de trabajo paralelos. Permite gestionar de forma explícita la jerarquía de memoria, ya que te permite definir cómo se organizan en mosaico y se transfieren los tensores entre la memoria más lenta y de mayor tamaño (por ejemplo, HBM) y la memoria en chip más rápida y de menor tamaño (por ejemplo, VMEM en TPU y memoria compartida en GPU). Para ello, se usan mapas de índices que asocian ubicaciones de la cuadrícula con bloques de datos específicos. Pallas puede reducir la misma definición de kernel para que se ejecute de forma eficiente tanto en las TPUs de Google como en varias GPUs. Para ello, compila los kernels en una representación intermedia adecuada para la arquitectura de destino: Mosaic para las TPUs o tecnologías como Triton para las GPUs. Con Pallas, puedes escribir kernels de alto rendimiento que especialicen bloques como la atención para conseguir el mejor rendimiento del modelo en el hardware de destino sin tener que depender de los conjuntos de herramientas específicos del proveedor.
Tokamax: una biblioteca seleccionada de kernels de vanguardia
Si Pallas es una herramienta para crear kernels, Tokamax es una biblioteca de kernels de aceleradores personalizados de vanguardia que admiten tanto TPUs como GPUs. Tokamax se basa en JAX y Pallas, y te permite usar todo el potencial de tu hardware. También proporciona herramientas para crear y ajustar automáticamente kernels personalizados.
Motivación
JAX, que tiene sus raíces en XLA, es un framework que se basa en el compilador. Sin embargo, hay un número reducido de casos en los que es posible que tengas que tomar el control directo del hardware para conseguir el máximo rendimiento.4 Los kernels personalizados son fundamentales para obtener el mejor rendimiento de los recursos de aceleradores de aprendizaje automático caros, como las TPUs y las GPUs. Aunque se usan mucho para permitir la ejecución eficiente de operadores clave, como Attention, su implementación requiere un conocimiento profundo tanto del modelo como de la arquitectura de hardware de destino. Tokamax proporciona una fuente autorizada de kernels seleccionados, bien probados y de alto rendimiento, junto con una infraestructura compartida sólida para su desarrollo, mantenimiento y gestión del ciclo de vida. Esta biblioteca también puede servirte como implementación de referencia para desarrollar y personalizar lo que necesites. De esta forma, puedes centrarte en el modelado sin tener que preocuparte por la infraestructura.
4Se trata de un paradigma bien establecido que tiene precedentes en el mundo de las CPUs, donde el código compilado constituye la mayor parte del programa y los desarrolladores recurren a funciones intrínsecas o a ensamblador insertado para optimizar las secciones críticas para el rendimiento.
Diseño
Para cualquier kernel, Tokamax proporciona una API común que puede estar respaldada por varias implementaciones. Por ejemplo, los kernels de TPU se pueden implementar mediante la reducción estándar de XLA o explícitamente con Pallas o Mosaic-TPU. Los kernels de GPU se pueden implementar mediante la reducción estándar de XLA, con Mosaic-GPU o Triton. De forma predeterminada, la API Tokamax elige la implementación más conocida para una configuración determinada, que se determina mediante los resultados almacenados en caché de las ejecuciones periódicas de ajuste automático y de pruebas comparativas, aunque puedes elegir implementaciones específicas si es necesario. Se pueden añadir nuevas implementaciones con el tiempo para aprovechar mejor las funciones específicas de las nuevas generaciones de hardware y conseguir un rendimiento aún mejor.
Un componente clave de la biblioteca Tokamax, además de los propios kernels, es la infraestructura de asistencia que te permite escribir kernels personalizados. Por ejemplo, la infraestructura de ajuste automático te permite definir un conjunto de parámetros configurables (por ejemplo, tamaños de los mosaicos) en los que Tokamax puede realizar un análisis exhaustivo para determinar y almacenar en caché los mejores ajustes posibles. Las regresiones nocturnas te protegen de problemas inesperados de rendimiento y numéricos causados por cambios en la infraestructura del compilador subyacente u otras dependencias.
Puntos fuertes principales
- Experiencia de desarrollo fluida: una biblioteca unificada y seleccionada proporciona implementaciones de alto rendimiento y de calidad de kernels clave, con expresiones claras de las generaciones de hardware admitidas y el rendimiento esperado, tanto de forma programática como en la documentación. De esta forma, se minimizan la fragmentación y la rotación.
- Flexibilidad y gestión del ciclo de vida: puedes elegir diferentes implementaciones e incluso cambiarlas con el tiempo si es necesario. Por ejemplo, si el compilador de XLA mejora la compatibilidad con determinadas operaciones y ya no requiere kernels personalizados, se puede retirar y migrar.
- Extensibilidad: puedes implementar tus propios kernels y, al mismo tiempo, aprovechar la infraestructura compartida, que cuenta con un buen soporte, lo que te permite centrarte en las funciones y optimizaciones de valor añadido. Las implementaciones estándar claramente creadas sirven como punto de partida para que los usuarios aprendan y las amplíen.
Qwix: cuantización completa y no intrusiva
Qwix es una biblioteca de cuantización integral para la pila de IA de JAX que admite tanto LLMs como otros tipos de modelos en todas las fases, incluido el entrenamiento (entrenamiento con reconocimiento de cuantización [QAT], técnica de cuantización [QT] y adaptación de rango bajo cuantificada [QLoRA]) y la inferencia posterior al entrenamiento (PTQ), que se dirige a los tiempos de ejecución de XLA y de los dispositivos.
Motivación
Las bibliotecas de cuantización actuales, sobre todo en el ecosistema de PyTorch, suelen tener fines limitados (por ejemplo, solo PTQ o solo QLoRA). Este panorama fragmentado te obliga a cambiar de herramienta, lo que impide que se use el código de forma coherente y que se produzca una coincidencia numérica precisa entre el entrenamiento y la inferencia. Además, muchas soluciones requieren modificaciones sustanciales en el modelo, lo que acopla estrechamente la lógica del modelo a la lógica de cuantización.
Diseño
La filosofía de diseño de Qwix se centra en ofrecer una solución integral y, lo que es más importante, una integración de modelos no intrusiva. Se ha diseñado con una arquitectura jerárquica y extensible basada en APIs funcionales reutilizables.
Esta integración no intrusiva se consigue mediante un mecanismo de intercepción diseñado meticulosamente que redirige las funciones de JAX a sus equivalentes cuantizados. Esto le permite integrar sus modelos sin realizar ninguna modificación, ya que desacopla por completo el código de cuantización de las definiciones de los modelos.
En el siguiente ejemplo se muestra cómo aplicar la cuantización w4a4 (un peso de 4 bits y una activación de 4 bits) a las capas MLP de un LLM y la cuantización w8 (un peso de 8 bits) al insertador. Para cambiar la receta de cuantización, solo tienes que actualizar la lista de reglas.
fp_model = ModelWithoutQuantization(...)
rules = [
qwix.QuantizationRule(
module_path=r'embedder',
weight_qtype='int8',
),
qwix.QuantizationRule(
module_path=r'layers_\d+/mlp',
weight_qtype='int4',
act_qtype='int4',
tile_size=128,
weight_calibration_method='rms,7',
),
]
quantized_model = qwix.quantize_model(fp_model, qwix.PtqProvider(rules))
Puntos fuertes principales
- Solución integral: Qwix se puede aplicar en una amplia variedad de escenarios de cuantización, lo que garantiza un uso coherente del código entre el entrenamiento y la inferencia.
- Integración de modelos no intrusiva: como se muestra en el ejemplo, puedes integrar modelos con una sola línea de código. De esta forma, puedes usar hiperparámetros en muchos esquemas de cuantización para encontrar el mejor equilibrio entre calidad y rendimiento.
- Federada con otras bibliotecas: Qwix se integra a la perfección con la pila de IA de JAX. Por ejemplo, Tokamax se adapta automáticamente para usar versiones cuantificadas de los kernels, sin código de usuario adicional, cuando el modelo se cuantifica con Qwix.
- Apto para la investigación: las APIs básicas y la arquitectura extensible de Qwix permiten a los investigadores explorar nuevos algoritmos y facilitan las comparaciones directas con herramientas de evaluación y de referencia integradas.
La capa de aplicación: formación y alineación
Entrenamiento de modelos fundacionales: MaxText y MaxDiffusion
MaxText y MaxDiffusion son los frameworks de entrenamiento de modelos de difusión y LLMs estrella de Google, respectivamente. Estos repositorios contienen una selección de implementaciones altamente optimizadas de modelos populares de código abierto. Tienen un doble propósito: funcionan como una base de código de entrenamiento de modelos lista para usar y como una referencia que los creadores de modelos fundacionales pueden usar como base.
Motivación
El interés por entrenar modelos de IA generativa está creciendo rápidamente en todo el sector. La popularidad de los modelos abiertos ha acelerado esta tendencia, ya que ofrecen arquitecturas probadas. Para entrenar y adaptar estos modelos, se necesita un alto rendimiento, eficiencia, escalabilidad a un gran número de chips y un código claro y comprensible. MaxText y MaxDiffusion son soluciones completas que se pueden usar en TPUs o GPUs y que se han diseñado para satisfacer estas necesidades.
Diseño
MaxText y MaxDiffusion] son bases de código de modelos fundacionales diseñadas para ofrecer legibilidad y rendimiento. Están estructurados con componentes reutilizables y bien probados: definiciones de modelos que usan kernels personalizados (como Tokamax) para obtener el máximo rendimiento, un arnés de entrenamiento para la orquestación y la monitorización, y un potente sistema de configuración que te permite controlar detalles como la fragmentación y la cuantificación (con Qwix) a través de una interfaz intuitiva. Se han incorporado funciones de fiabilidad avanzadas, como la creación de puntos de control de varios niveles, para asegurar un buen rendimiento sostenido.
MaxText y MaxDiffusion usan las mejores bibliotecas de JAX, como Qwix, Tunix, Orbax y Optax, para ofrecer funciones básicas. Estas bibliotecas proporcionan una infraestructura sólida y escalable, lo que reduce la sobrecarga de desarrollo y te permite centrarte en la tarea de modelado. Para la inferencia, el código del modelo se comparte para permitir un servicio eficiente y escalable.
Puntos fuertes principales
- Rendimiento desde el diseño: con una infraestructura de entrenamiento configurada para ofrecer un "goodput" (rendimiento útil) alto y unas implementaciones de modelos optimizadas para conseguir un MFU (Model Flops Utilization) alto, MaxText y MaxDiffusion ofrecen un alto rendimiento a gran escala desde el primer momento.
- Diseñados para escalar: estos frameworks aprovechan la potencia de la pila de IA de JAX (especialmente Pathways) para que puedas escalar sin problemas de decenas de chips a decenas de miles de chips.
- Base sólida para los creadores de modelos fundacionales: las implementaciones de alta calidad y legibles sirven como punto de partida sólido para que los desarrolladores las utilicen como solución integral o como implementación de referencia para sus propias personalizaciones.
Después del entrenamiento y la alineación: el framework Tunix
Tunix ofrece algoritmos de aprendizaje por refuerzo (RL) de código abierto de vanguardia, junto con un framework y una infraestructura sólidos, lo que proporciona a los desarrolladores una forma sencilla de experimentar con técnicas de post-entrenamiento de LLMs, como el ajuste fino supervisado (SFT) y la alineación mediante JAX y TPUs.
Motivación
El postentrenamiento es un paso fundamental para aprovechar todo el potencial de los LLMs. La fase de aprendizaje por refuerzo es especialmente importante para desarrollar la alineación y las capacidades de razonamiento. El desarrollo de código abierto en este ámbito se ha basado casi exclusivamente en PyTorch y GPUs, lo que ha dejado un vacío fundamental en las soluciones de JAX y TPU. Tunix (Tune-in-JAX) es una biblioteca de alto rendimiento nativa de JAX diseñada para cubrir esta necesidad.
Diseño
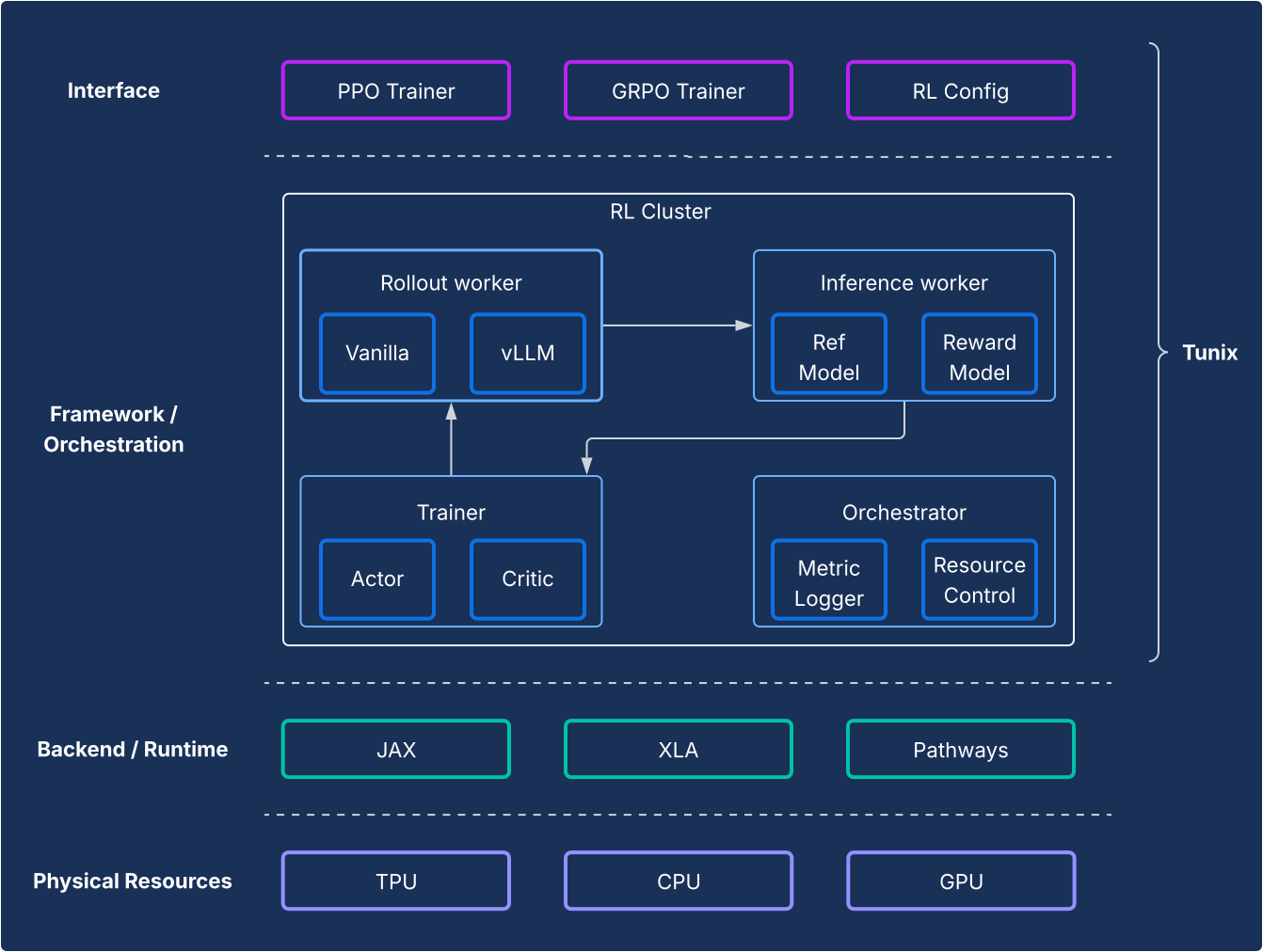
Desde el punto de vista del framework, Tunix permite una configuración de vanguardia que separa claramente los algoritmos de RL de la infraestructura. Ofrece una API ligera similar a un cliente que oculta la complejidad de la infraestructura de RL, lo que te permite desarrollar nuevos algoritmos. Tunix ofrece soluciones listas para usar para algoritmos populares, como la optimización de políticas proximales (PPO), la optimización de preferencias directas (DPO) y otros.
En cuanto a la infraestructura, Tunix se integra con Pathways, lo que permite una arquitectura de un solo controlador que hace que el entrenamiento de RL multinodo sea accesible. En cuanto al entrenamiento, Tunix admite de forma nativa el entrenamiento eficiente de parámetros (por ejemplo, LoRA) y aprovecha el fragmentado de JAX y XLA (paralelización general y escalable para el gráfico de computación de aprendizaje automático [GSPMD]) para generar un gráfico de computación eficiente. Admite modelos populares de código abierto, como Gemma y Llama, de forma predeterminada.
Puntos fuertes principales
- Sencillez: proporciona una API de alto nivel similar a un cliente que abstrae las complejidades de la infraestructura distribuida subyacente.
- Eficiencia de los desarrolladores: Tunix acelera el ciclo de vida de I+D con algoritmos y "recetas" integrados, lo que te proporciona un modelo funcional y te permite iterar rápidamente.
- Rendimiento y escalabilidad: Tunix permite una infraestructura de entrenamiento altamente eficiente y escalable horizontalmente aprovechando Pathways como un único controlador en el backend.
Capa de aplicación: producción e inferencia
Históricamente, uno de los retos de la adopción de JAX ha sido el paso de la investigación a la producción. La pila de IA de JAX ahora ofrece una historia de producción madura y doble que proporciona compatibilidad con el ecosistema y rendimiento de JAX.
Inferencia de LLMs de alto rendimiento: la solución vLLM
vLLM-TPU es la pila de inferencia de alto rendimiento de Google diseñada para ejecutar modelos de lenguaje extenso (LLMs) de PyTorch y JAX de forma eficiente en las TPUs de Cloud. Para ello, integra de forma nativa el popular framework de código abierto vLLM con el ecosistema JAX y TPU de Google.
Motivación
El sector está evolucionando rápidamente y cada vez hay más demanda de soluciones de inferencia fluidas, de alto rendimiento y fáciles de usar. Los desarrolladores suelen enfrentarse a problemas importantes debido a herramientas complejas e incoherentes, un rendimiento deficiente y una compatibilidad de modelos limitada. La pila de vLLM aborda estos problemas proporcionando una plataforma unificada, eficiente e intuitiva.
Diseño
Esta solución amplía el framework vLLM en lugar de reinventarlo. vLLM-TPU es un motor de servicio de LLMs de código abierto muy optimizado que destaca por su alto rendimiento, que se consigue mediante funciones clave como PagedAttention (que gestiona las cachés de clave-valor como la memoria virtual para minimizar la fragmentación) y Continuous Batching (que añade solicitudes de forma dinámica al lote para mejorar la utilización).
vLLM-TPU se basa en esta base y desarrolla componentes principales para la gestión de solicitudes, la programación y la gestión de memoria. Introduce un backend basado en JAX que actúa como puente, traduciendo el gráfico computacional y las operaciones de memoria de vLLM en código ejecutable en TPU. Este backend gestiona las interacciones con los dispositivos, la ejecución de modelos de JAX y los detalles de la gestión de la caché de clave-valor en el hardware de TPU. Incorpora optimizaciones específicas de las TPU, como mecanismos de atención eficientes (por ejemplo, el uso de kernels de JAX Pallas para Ragged Paged Attention) y la cuantización, todo ello adaptado a la arquitectura de las TPU.
Puntos fuertes principales
- Coste de incorporación o baja de usuarios cero: los usuarios pueden adoptar esta solución sin apenas problemas. Desde el punto de vista de la experiencia de usuario, el procesamiento de solicitudes de inferencia en TPUs debería ser el mismo que en GPUs. Se comparten la CLI para iniciar el servidor, aceptar las peticiones y devolver los resultados.
- Aprovecha al máximo el ecosistema: esta estrategia utiliza la interfaz y la experiencia de usuario de los vLLMs y contribuye a ellas, lo que garantiza la compatibilidad y la facilidad de uso.
- Fungibilidad entre TPUs y GPUs: la solución funciona de forma eficiente tanto en TPUs como en GPUs, lo que te ofrece flexibilidad.
- Rentable (mejor rendimiento/coste): optimiza el rendimiento para ofrecer la mejor relación entre rendimiento y coste de los modelos populares.
Servicio de JAX: serialización de Orbax y motor de servicio de Neptune
En el caso de los modelos que no son LLMs o de los usuarios que quieran una canalización totalmente nativa de JAX, la biblioteca de serialización Orbax y el sistema del motor de servicio Neptune (NSE) proporcionan una solución de servicio integral y de alto rendimiento.
Motivación
Históricamente, los modelos de JAX a menudo se basaban en una ruta indirecta a la producción, como envolverse en gráficos de TensorFlow y desplegarse mediante TensorFlow Serving. Este enfoque introdujo limitaciones e ineficiencias significativas, lo que obligó a los desarrolladores a interactuar con un ecosistema independiente y ralentizó la iteración. Un sistema de publicación nativo de JAX dedicado es fundamental para la sostenibilidad, la reducción de la complejidad y la optimización del rendimiento.
Diseño
Esta solución consta de dos componentes principales, tal como se muestra en el siguiente diagrama.
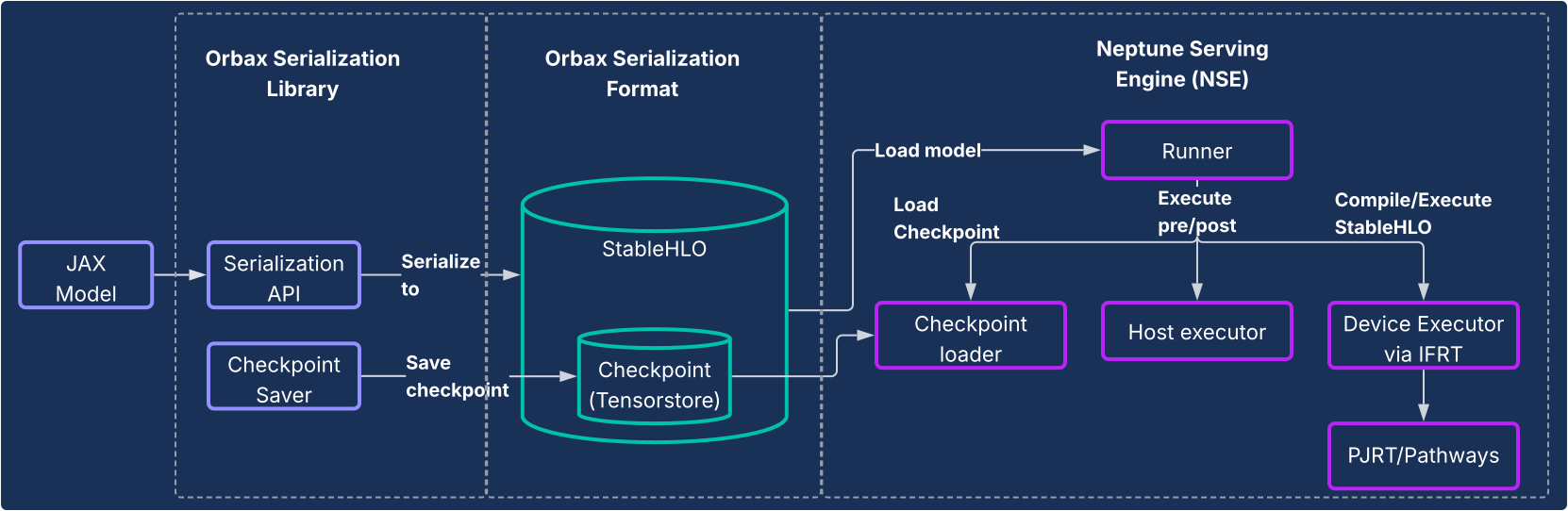
- Biblioteca de serialización de Orbax: proporciona APIs fáciles de usar para serializar modelos de JAX en un nuevo formato de serialización de Orbax robusto. Este formato está optimizado para los despliegues de producción. Representa directamente los cálculos del modelo JAX mediante StableHLO, lo que permite que el gráfico de cálculo se represente de forma nativa. También utiliza TensorStore para almacenar pesos, lo que permite cargar rápidamente los puntos de control para el servicio.
- Neptune Serving Engine (NSE): es el motor de servicio de alto rendimiento y flexible que acompaña a Neptune (normalmente, se implementa como un archivo binario de C++) y que se ha diseñado para ejecutar de forma nativa modelos de JAX en formato Orbax. NSE ofrece funciones esenciales para la producción, como la carga rápida de modelos, el servicio simultáneo de alto rendimiento con procesamiento por lotes integrado, la compatibilidad con varias versiones de modelos y el servicio de uno o varios hosts (con PJRT y Pathways). Usa el Neptune
Serving Engine para:
- Modelos que no son LLMs: es una solución de uso general ideal para cargas de trabajo como sistemas de recomendación, modelos de difusión y otros modelos de IA.
- LLMs pequeños y servicio "one-shot": se ha diseñado para modelos no autorregresivos o modelos más pequeños que se sirven de forma "unaria", donde toda la salida se genera en una sola pasada sin necesidad de una gestión de estados compleja, como una caché de valores clave.
En resumen, Neptune Serving Engine cubre las necesidades de los modelos que no son modelos de lenguaje autorregresivos extensos, y proporciona una solución nativa de TPU de alto rendimiento para el ecosistema de aprendizaje automático en general.
Puntos fuertes principales
- Servicio nativo de JAX: la solución se ha creado de forma nativa para JAX, lo que elimina la sobrecarga entre frameworks en la serialización y el servicio de modelos. De esta forma, se garantiza una carga rápida de los modelos y una ejecución optimizada en CPUs, GPUs y TPUs.
- Despliegue de producción sencillo: los modelos serializados proporcionan una ruta de despliegue hermética que no se ve afectada por las variaciones en las dependencias de Python y permite realizar comprobaciones de integridad del modelo en tiempo de ejecución. De esta forma, se ofrece un proceso fluido e intuitivo para la puesta en producción de modelos de JAX.
- Experiencia de desarrollo mejorada: al eliminar la necesidad de envolver frameworks engorrosos, esta solución reduce significativamente las dependencias y la complejidad del sistema, lo que acelera la iteración para los desarrolladores de JAX.
Análisis y creación de perfiles en todo el sistema
XProf: creación de perfiles de rendimiento detallada e integrada en el hardware
XProf es una herramienta de creación de perfiles y análisis del rendimiento que proporciona una visibilidad detallada de varios aspectos de la ejecución de cargas de trabajo de aprendizaje automático, lo que te permite depurar y optimizar el rendimiento. Está totalmente integrado en los ecosistemas de JAX y TPU.
Motivación
Por un lado, las cargas de trabajo de aprendizaje automático son cada vez más complicadas. Por otro lado, hay una explosión de funciones de hardware especializadas dirigidas a estas cargas de trabajo. Es fundamental combinar ambos elementos de forma eficaz para asegurar un rendimiento y una eficiencia óptimos, teniendo en cuenta los enormes costes de la infraestructura de aprendizaje automático. Para ello, es necesario tener una visibilidad profunda tanto de la carga de trabajo como del hardware, presentada de forma que se pueda consultar rápidamente. XProf destaca en este aspecto.
Diseño
XProf consta de dos componentes principales: la recogida y el análisis.
- Recogida: XProf recoge información de varias fuentes: anotaciones en tu código JAX, modelos de costes de las operaciones del compilador XLA y funciones de creación de perfiles de hardware específicas de la TPU. Esta recogida se puede activar de forma programática o bajo demanda, lo que genera un artefacto de evento completo.
- Análisis: XProf post-procesa los datos recogidos y crea un conjunto de visualizaciones potentes a las que se accede con un navegador.
Puntos fuertes
La verdadera potencia de XProf reside en su profunda integración con la pila completa, lo que proporciona una amplitud y una profundidad de análisis que son una ventaja tangible del ecosistema JAX/TPU diseñado conjuntamente.
- Diseñado conjuntamente con la TPU: XProf aprovecha las funciones de hardware diseñadas específicamente para recoger perfiles sin problemas, lo que permite que la sobrecarga de la recogida sea inferior al 1%. De esta forma, la creación de perfiles se convierte en una parte ligera e iterativa del desarrollo.
- Amplitud y profundidad del análisis: XProf ofrece un análisis en profundidad en varios ejes. Entre sus herramientas se incluyen las siguientes:
- Trace Viewer: una vista cronológica de las operaciones de ejecución en diferentes unidades de hardware (por ejemplo, TensorCores).
- Perfil de operaciones de HLO: desglosa el tiempo total dedicado a las diferentes categorías de operaciones.
- Visor de memoria: muestra los detalles de las asignaciones de memoria por diferentes operaciones durante el periodo analizado.
- Análisis de la envolvente de rendimiento: te ayuda a identificar si determinadas operaciones están limitadas por la computación o la memoria, y a determinar a qué distancia se encuentran de las capacidades máximas del hardware.
- Visor de gráficos: ofrece una vista del gráfico HLO completo ejecutado por el hardware.
Una perspectiva comparativa: la pila JAX/TPU como opción atractiva
El panorama actual del aprendizaje automático ofrece muchas cadenas de herramientas excelentes y consolidadas. La pila de IA de JAX ofrece un conjunto de ventajas único y atractivo para los desarrolladores que se centran en el aprendizaje automático de alto rendimiento a gran escala, derivado directamente de su diseño modular y su profundo diseño conjunto de hardware.
Aunque muchos frameworks ofrecen una amplia gama de funciones, la pila de IA de JAX proporciona elementos diferenciadores específicos y potentes en áreas clave del ciclo de vida del desarrollo:
- Una experiencia de desarrollo más sencilla y potente: el paradigma de transformación de gradiente encadenable de Optax permite estrategias de optimización más potentes y flexibles que se declaran una vez, en lugar de gestionarse de forma imperativa en el bucle de entrenamiento. A nivel de sistema, la interfaz de controlador único más sencilla de Pathways abstrae la complejidad del entrenamiento multirebanada, lo que supone una simplificación significativa para los investigadores.
- Diseñado para ofrecer una gran resiliencia: la pila de JAX se ha diseñado para el entrenamiento a gran escala. Orbax ofrece funciones de "resistencia de entrenamiento a gran escala", como la creación de puntos de control de emergencia y multinivel. Esto se complementa con Grain, que ofrece compatibilidad total con la reproducibilidad mediante aleatorizaciones globales deterministas y cargadores de datos con puntos de control. La capacidad de registrar el estado de la canalización de datos (Grain) y el estado del modelo (Orbax) de forma atómica es fundamental para garantizar la reproducibilidad en las tareas de larga duración.
- Un ecosistema completo e integral: la pila proporciona una solución integral y coherente. Los desarrolladores pueden usar MaxText como referencia de SOTA para el entrenamiento, Tunix para la alineación y seguir una ruta de producción clara de dos vías con vLLM-TPU (para la compatibilidad con vLLM) y NSE (para el rendimiento de JAX).
Aunque muchas pilas son similares desde el punto de vista del software de alto nivel, el factor decisivo suele ser el rendimiento o el coste total de propiedad, donde el diseño conjunto de JAX y las TPUs ofrece una ventaja clara. Esta ventaja de rendimiento o coste total de propiedad es el resultado directo de la integración vertical del software y el hardware de TPU. La capacidad del compilador XLA para fusionar operaciones específicamente para la arquitectura de TPU o para que el generador de perfiles XProf use hooks de hardware para generar perfiles con una sobrecarga inferior al 1% son ventajas tangibles de esta integración profunda.
En el caso de las organizaciones que adopten esta pila, la naturaleza completa de la pila de IA de JAX minimiza el coste de la migración. Para los clientes que utilizan arquitecturas de modelos abiertos populares, el cambio de otros frameworks a MaxText suele consistir en configurar archivos de configuración. Además, la capacidad de la pila para ingerir formatos de puntos de control populares, como safetensors, permite migrar los puntos de control existentes sin necesidad de volver a entrenar los modelos, lo que supone un coste elevado.
En la siguiente tabla se muestra una asignación de los componentes proporcionados por la pila de IA de JAX y sus equivalentes en otros frameworks o bibliotecas.
| Función | JAX | Alternativas o equivalentes en otros frameworks5 |
| Compilador o tiempo de ejecución | XLA | Inductor, entusiasta |
| Entrenamiento MultiPod | Pathways | Estrategias de iluminación de Torch, Ray Train y Monarch (nuevo). |
| Framework principal | JAX | PyTorch |
| Creación de modelos | Modelos Flax y Max* | torch.nn.*,
TransformerEngine de NVIDIA, Transformers de Hugging Face
|
| Optimizadores y pérdidas | Optax | torch.optim.*, torch.nn.*Loss |
| Cargadores de datos | Textura | Ray Data y cargadores de datos de Hugging Face |
| Creación de puntos de control | Orbax | Puntos de control distribuidos de PyTorch Puntos de control de NeMo |
| Cuantización | Qwix | TorchAO, bitsandbytes |
| Creación de kernels e implementaciones conocidas | Pallas/Tokamax | Triton/Helion, Liger-kernel, TransformerEngine |
| Después del entrenamiento o el ajuste | Tunix | VERL, NeMoRL |
| Elaboración de perfiles | XProf | Profiler de PyTorch, NSight Systems y NSight Compute |
| Entrenamiento de modelos fundacionales | MaxText y MaxDiffusion | NeMo-Megatron, DeepSpeed y TorchTitan |
| Inferencia de LLM | vLLM | SGLang |
| Inferencia sin LLM | NSE | Servidor de inferencia de Triton y RayServe |
5Algunos de los equivalentes que se muestran aquí no siempre son comparaciones exactas, ya que otros frameworks definen los límites de las APIs de forma diferente a JAX. La lista de equivalentes no es exhaustiva y aparecen nuevas bibliotecas con frecuencia.
Conclusión: una plataforma duradera y lista para producción para el futuro de la IA
Los datos de la tabla anterior ilustran una conclusión evidente: estas pilas tienen sus propios puntos fuertes y débiles en un número reducido de áreas, pero, en general, son muy similares desde el punto de vista del software. Ambas pilas proporcionan soluciones listas para usar para el preentrenamiento, la adaptación posterior al entrenamiento y el despliegue de modelos fundacionales.
La pila de IA de JAX ofrece una solución atractiva y robusta para entrenar y desplegar modelos de aprendizaje automático a cualquier escala. Aprovecha la integración vertical profunda en el software y el hardware de las TPU para ofrecer un rendimiento líder en su clase y un coste total de propiedad.
Al basarse en sistemas internos probados, la pila ha evolucionado para ofrecer fiabilidad y escalabilidad inherentes, lo que permite a los usuarios desarrollar e implementar con confianza incluso los modelos más grandes. Su diseño modular y componible, basado en la filosofía de la pila de IA de JAX, ofrece a los usuarios una libertad y un control sin precedentes, lo que les permite adaptar la pila a sus necesidades específicas sin las limitaciones de un framework monolítico.
Con XLA y Pathways, que proporcionan una base escalable y tolerante a fallos, JAX, que ofrece una biblioteca numérica eficaz y expresiva, potentes bibliotecas de desarrollo principales como Flax, Optax, Grain y Orbax, herramientas de rendimiento avanzadas como Pallas, Tokamax y Qwix, y una capa de aplicación y producción robusta en MaxText, vLLM y NSE, la pila de IA de JAX proporciona una base duradera para que los usuarios desarrollen y lleven rápidamente a producción investigaciones de vanguardia.