
KI für die Produktion mit JAX auf Cloud TPUs entwickeln
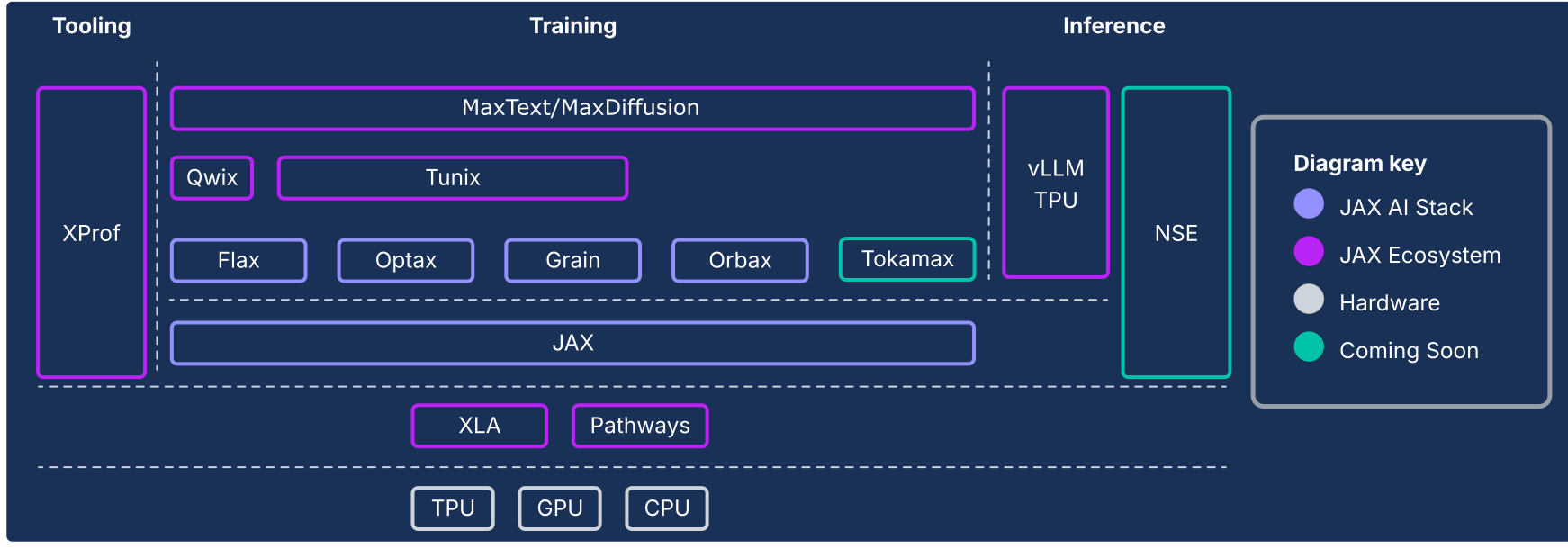
Der JAX AI-Stack erweitert den numerischen JAX-Kern um eine Sammlung von von Google unterstützten, zusammensetzbaren Bibliotheken und entwickelt ihn zu einer robusten, End-to-End-Open-Source-Plattform für maschinelles Lernen in extremen Größenordnungen. Der JAX-KI-Stack besteht daher aus einem umfassenden und robusten Ökosystem, das den gesamten ML-Lebenszyklus abdeckt:
Grundlage für den industriellen Maßstab:Der JAX AI-Stack ist für den massiven Maßstab konzipiert und nutzt ML Pathways für die Orchestrierung des Trainings auf Zehntausenden von Chips und Orbax für robustes, asynchrones Checkpointing mit hohem Durchsatz, das das Training von hochmodernen Modellen in Produktionsqualität ermöglicht.
Vollständiges, produktionsreifes Toolkit:Der JAX AI-Stack bietet eine umfassende Reihe von Bibliotheken für den gesamten Entwicklungsprozess: Flax für die flexible Modellerstellung, Optax für zusammensetzbare Optimierungsstrategien und Grain für die deterministischen Datenpipelines, die für reproduzierbare groß angelegte Ausführungen unerlässlich sind.
Spitzenleistung: Um eine maximale Hardwareauslastung zu erreichen, bietet der JAX AI-Stack spezielle Bibliotheken wie Tokamax für hochmoderne benutzerdefinierte Kernel, Qwix für nicht aufdringliche Quantisierung, die die Trainings- und Inferenzgeschwindigkeit erhöht, und XProf für eine detaillierte, hardwareintegrierte Leistungsprofilierung.
Vollständiger Pfad zur Produktion:Der JAX AI-Stack ermöglicht einen nahtlosen Übergang von der Forschung zur Bereitstellung. Dazu gehören MaxText als skalierbare Referenz für das Training von Foundation Models, Tunix für modernes Reinforcement Learning (RL) und Alignment sowie eine einheitliche Inferenzlösung mit vLLM-TPU-Integration> und der JAX-Serving-Laufzeit.
Die Philosophie des JAX AI-Stacks basiert auf lose gekoppelten Komponenten, die jeweils eine Sache gut machen. JAX ist kein monolithisches ML-Framework, sondern konzentriert sich auf effiziente Array-Operationen und Programmtransformationen. Das Ökosystem basiert auf diesem Kern-Framework und bietet eine Vielzahl von Funktionen, die sich sowohl auf das Training von ML-Modellen als auch auf andere Arten von Arbeitslasten wie wissenschaftliches Computing beziehen.
Dieses System aus lose gekoppelten Komponenten ermöglicht es Ihnen, Bibliotheken so auszuwählen und zu kombinieren, dass sie Ihren Anforderungen am besten entsprechen. Aus Software-Engineering-Sicht können Sie mit dieser Architektur auch Funktionen aktualisieren, die traditionell als Kernframework-Komponenten gelten (z. B. Datenpipelines und Checkpointing), ohne das Kernframework zu destabilisieren oder in Releasezyklen gefangen zu sein. Da die meisten Funktionen in Bibliotheken implementiert werden und nicht in einem monolithischen Framework, ist die numerische Kernbibliothek robuster und lässt sich besser an zukünftige Veränderungen in der Technologielandschaft anpassen.
In den folgenden Abschnitten finden Sie einen technischen Überblick über den JAX-KI-Stack, seine wichtigsten Funktionen, die Designentscheidungen, die dahinter stehen, und wie sie zusammen eine robuste Plattform für moderne ML-Arbeitslasten bilden.
Der JAX AI-Stack und andere Ökosystemkomponenten
| Komponente | Funktion / Beschreibung |
|---|---|
| JAX AI-Stack – Kern und Komponenten1 | |
| JAX | Beschleunigerorientierte Array-Berechnung und Programmtransformation (JIT, grad, vmap, pmap). |
| Flax | Flexible Bibliothek zum Erstellen neuronaler Netzwerke für die intuitive Modellerstellung und ‑änderung. |
| Optax | Eine Bibliothek mit zusammensetzbaren Transformationen für die Gradientenverarbeitung und ‑optimierung. |
| Orbax | „Any-scale“-Bibliothek für verteiltes Checkpointing für die Resilienz von Hero-Scale-Training. |
| Körnung | Eine skalierbare, deterministische und checkpointfähige Bibliothek für Eingabedatenpipelines. |
| JAX AI-Stack – Infrastruktur | |
| XLA | Open-Source-Compiler für maschinelles Lernen für TPUs, CPUs und GPUs. |
| Pathways | Verteilte Laufzeitumgebung für die Orchestrierung von Berechnungen auf Zehntausenden von Chips. |
| JAX AI Stack – Adv. Entwicklung | |
| Pallas | Eine JAX-Erweiterung zum Schreiben von leistungsstarken benutzerdefinierten Kernels auf niedriger Ebene, die in Python implementiert sind. |
| Tokamax | Eine kuratierte Bibliothek mit hochmodernen, leistungsstarken benutzerdefinierten Kernels (z. B. Attention). |
| Qwix | Eine umfassende, nicht aufdringliche Bibliothek für die Quantisierung (PTQ, QAT, QLoRA). |
| JAX AI-Stack – Anwendung | |
| MaxText / MaxDiffusion | Skalierbare Referenzframeworks für das Training von Foundation Models (z. B. LLM und Diffusion) |
| Tunix | Ein Framework für modernes Post-Training und Alignment (RLHF, DPO). |
| vLLM | Eine leistungsstarke LLM-Inferenzlösung mit integrierter Integration des vLLM-Frameworks. |
| XProf | Ein umfassender, hardwareintegrierter Profiler für die systemweite Leistungsanalyse. |
1 Im Python-Paket jax-ai-stack enthalten.
Abbildung 1: Der JAX AI-Stack und die Ökosystemkomponenten
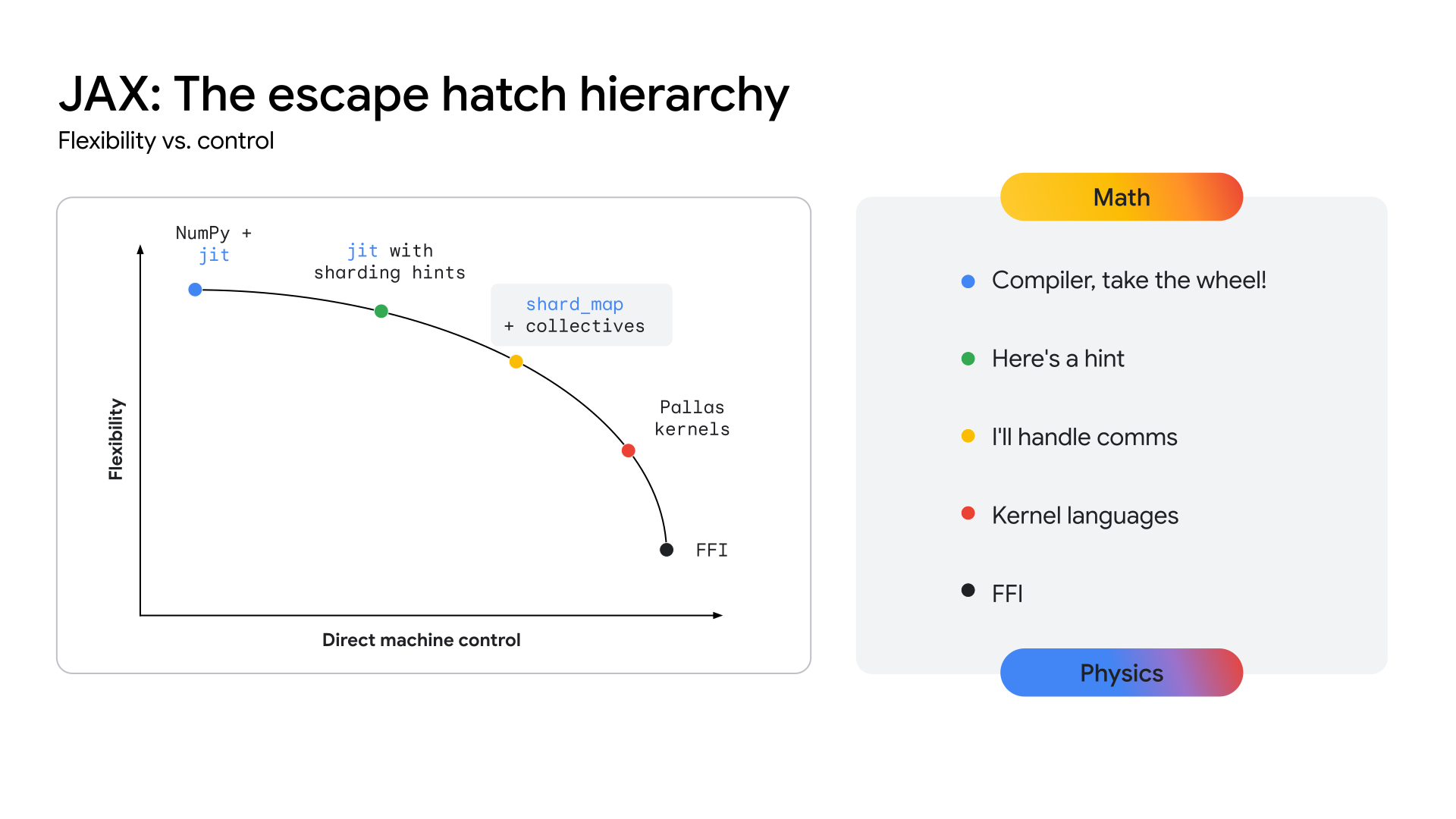
Das architektonische Imperativ: Leistung über Frameworks hinaus
Da sich die Modellarchitekturen angleichen, z. B. an multimodale Mixture-of-Experts-Transformer (MoE), führt das Streben nach Spitzenleistung zur Entstehung von Megakernels. Ein Megakernel ist im Grunde der gesamte Forward Pass (oder ein großer Teil davon) eines bestimmten Modells, der mit einer Low-Level-API wie dem CUDA SDK auf NVIDIA-GPUs manuell codiert wurde. Dieser Ansatz ermöglicht eine maximale Hardwareauslastung durch aggressives Überlappen von Berechnungen, Speicher und Kommunikation. Aktuelle Arbeiten aus der Forschungsgemeinschaft haben gezeigt, dass dieser Ansatz den Durchsatz bei der Inferenz auf GPUs deutlich steigern kann, in einigen Fällen um über 22 %. Dieser Trend ist nicht auf die Inferenz beschränkt. Es gibt Hinweise darauf, dass bei einigen groß angelegten Trainingsbemühungen eine Hardwaresteuerung auf niedriger Ebene eingesetzt wurde, um erhebliche Effizienzsteigerungen zu erzielen.
Wenn sich dieser Trend beschleunigt, besteht die Gefahr, dass alle Frameworks auf hoher Ebene, wie sie heute existieren, an Relevanz verlieren, da der Zugriff auf die Hardware auf niedriger Ebene letztendlich für die Leistung auf ausgereiften, stabilen Architekturen entscheidend ist. Das ist eine Herausforderung für alle modernen ML-Stacks: Wie lässt sich Hardware auf Expertenniveau steuern, ohne die Produktivität und Flexibilität eines Frameworks auf hoher Ebene zu beeinträchtigen?
Damit TPUs einen klaren Weg zu dieser Leistungsstufe bieten, muss das Ökosystem eine API-Ebene bereitstellen, die näher an der Hardware ist und die Entwicklung dieser hochspezialisierten Kernels ermöglicht. Der JAX-Stack wurde entwickelt, um dieses Problem zu lösen, indem er ein Kontinuum der Abstraktion bietet (siehe Abbildung 2), von den automatisierten, allgemeinen Optimierungen des XLA-Compilers bis hin zur detaillierten, manuellen Steuerung der Pallas-Bibliothek zur Erstellung von Kernels.
Abbildung 2: Das JAX-Kontinuum der Abstraktion
Der JAX AI-Kernstack
Der JAX AI Stack besteht aus fünf wichtigen Bibliotheken, die die Grundlage für die Modellentwicklung bilden:
JAX: Eine Grundlage für zusammensetzbare, leistungsstarke Programmtransformationen
JAX ist eine Python-Bibliothek für die beschleunigerorientierte Array-Berechnung und Programmtransformation, die für numerisches Hochleistungs-Computing und Machine Learning im großen Maßstab entwickelt wurde. Mit seinem funktionalen Programmiermodell und der NumPy-ähnlichen API bietet JAX eine solide Grundlage für Bibliotheken auf höherer Ebene.
Durch das Compiler-First-Design fördert JAX die Skalierbarkeit, indem es XLA (siehe XLA-Abschnitt) für aggressive Analysen, Optimierungen und Hardware-Targeting des gesamten Programms nutzt. Die Betonung der funktionalen Programmierung (z. B. reine Funktionen) in JAX macht die wichtigsten Programmtransformationen einfacher zu handhaben und vor allem zusammensetzbar.
Diese Kerntransformationen können kombiniert werden, um eine hohe Leistung und Skalierung von Arbeitslasten in Bezug auf Modellgröße, Clustergröße und Hardwaretypen zu erreichen:
- jit: Just-in-time-Kompilierung von Python-Funktionen in optimierte, zusammengeführte XLA-Ausführungsdateien.
- grad: Automatische Differenzierung, die den Vorwärts- und Rückwärtsmodus sowie Ableitungen höherer Ordnung unterstützt.
- vmap: Automatische Vektorisierung, die nahtloses Batching und Datenparallelität ermöglicht, ohne dass die Funktionslogik geändert werden muss.
- pmap / shard_map: Automatische Parallelisierung auf mehreren Geräten (z. B. TPU-Kernen), die die Grundlage für verteiltes Training bildet.
Die nahtlose Integration mit dem GSPMD-Modell (General-purpose SPMD) von XLA ermöglicht es JAX, Berechnungen automatisch über große TPU-Pods hinweg zu parallelisieren, ohne dass der Code wesentlich geändert werden muss. In den meisten Fällen sind für die Skalierung nur Sharding-Anmerkungen auf hoher Ebene erforderlich.
Flax: Flexible Erstellung neuronaler Netzwerke
Flax vereinfacht das Erstellen, Debuggen und Analysieren von neuronalen Netzwerken in JAX, indem es einen intuitiven, objektorientierten Ansatz für die Modellentwicklung bietet. Die funktionale API von JAX ist zwar leistungsstark, bietet aber eine vertrautere schichtbasierte Abstraktion für Entwickler, die an Frameworks wie PyTorch gewöhnt sind, ohne dass die Leistung darunter leidet.
Dieses Design vereinfacht das Ändern oder Kombinieren von trainierten Modellkomponenten.
Techniken wie LoRA und Quantisierung erfordern manipulierbare Modelldefinitionen, die die NNX-API von Flax über eine Python-Schnittstelle bereitstellt. NNX kapselt den Modellstatus, wodurch die kognitive Belastung der Nutzer verringert wird. Außerdem ermöglicht sie das programmatische Durchlaufen und Ändern der Modellhierarchie.
Wichtige Stärken:
- Intuitive objektorientierte API: Vereinfacht die Modellerstellung und ermöglicht erweiterte Anwendungsfälle wie den Austausch von Untermodulen und die teilweise Initialisierung.
- Konsistent mit Core JAX: Flax bietet Lifted-Transformationen, die vollständig mit dem funktionalen Paradigma von JAX kompatibel sind. So wird die volle Leistung von JAX mit verbesserter Entwicklerfreundlichkeit geboten.
Optax: Zusammensetzbare Strategien für die Verarbeitung und Optimierung von Gradienten
Optax ist eine Bibliothek zur Verarbeitung und Optimierung von Gradienten für JAX. Es soll Modellentwicklern Bausteine zur Verfügung stellen, die auf benutzerdefinierte Weise neu kombiniert werden können, um unter anderem Deep-Learning-Modelle zu trainieren. Sie baut auf den Funktionen der JAX-Kernbibliothek auf und bietet eine gut getestete, leistungsstarke Bibliothek mit Verlust- und Optimierungsfunktionen sowie zugehörigen Techniken, die zum Trainieren von ML-Modellen verwendet werden können.
Motivation
Die Berechnung und Minimierung von Verlusten ist das Herzstück des Trainings von ML-Modellen. Die JAX-Kernbibliothek unterstützt die automatische Differenzierung und bietet damit die numerischen Funktionen zum Trainieren von Modellen. Sie enthält jedoch keine Standardimplementierungen beliebter Optimierer (z. B. RMSProp oder Adam) oder Verluste (z. B. CrossEntropy oder MSE). Sie könnten diese Funktionen zwar implementieren (und einige fortgeschrittene Entwickler werden dies auch tun), aber ein Fehler in einer Optimiererimplementierung würde schwer zu diagnostizierende Probleme mit der Modellqualität verursachen. Anstatt dass der Nutzer solche kritischen Teile implementieren muss, bietet Optax Implementierungen dieser Algorithmen, die auf Richtigkeit und Leistung getestet wurden.
Das Feld der Optimierungstheorie fällt eindeutig in den Bereich der Forschung. Seine zentrale Rolle beim Training macht es jedoch auch zu einem unverzichtbaren Bestandteil des Trainings von produktionsreifen ML-Modellen. Eine Bibliothek, die diese Rolle erfüllt, muss sowohl flexibel genug sein, um schnelle Forschungsiterationen zu ermöglichen, als auch robust und leistungsstark genug, um für das Training von Produktionsmodellen zuverlässig zu sein. Außerdem sollten gut getestete Implementierungen von modernen Algorithmen bereitgestellt werden, die den Standardgleichungen entsprechen. Die Optax-Bibliothek wurde mit ihrer modularen, zusammensetzbaren Architektur und dem Schwerpunkt auf korrektem, lesbarem Code entwickelt, um dies zu erreichen.
Design
Optax wurde entwickelt, um sowohl die Forschungsgeschwindigkeit als auch den Übergang von der Forschung zur Produktion zu verbessern. Dazu werden lesbare, gut getestete und effiziente Implementierungen von Kernalgorithmen bereitgestellt. Optax kann auch außerhalb des Kontexts von Deep Learning verwendet werden. In diesem Kontext kann es jedoch als Sammlung bekannter Verlustfunktionen, Optimierungsalgorithmen und Gradiententransformationen betrachtet werden, die in reiner funktionaler Weise gemäß der JAX-Philosophie implementiert werden. Die Sammlung bekannter Verlustfunktionen und Optimierer ermöglicht Nutzern einen einfachen und sicheren Einstieg.
Der modulare Ansatz von Optax ermöglicht es Ihnen, mehrere Optimierer zu verketten, gefolgt von anderen gängigen Transformationen (z. B. Gradient Clipping) und Wrapping> mit gängigen Techniken wie MultiStep oder Lookahead, um leistungsstarke Optimierungsstrategien mit wenigen Zeilen Code zu erreichen. Die flexible Schnittstelle ermöglicht es Ihnen, neue Optimierungsalgorithmen zu untersuchen und leistungsstarke Optimierungstechniken zweiter Ordnung wie Shampoo oder Muon zu verwenden.
# Optax implementation of a RMSProp optimizer with a custom learning rate
# schedule, gradient clipping and gradient accumulation.
optimizer = optax.chain(
optax.clip_by_global_norm(GRADIENT_CLIP_VALUE),
optax.rmsprop(learning_rate=optax.cosine_decay_schedule(init_value=lr,decay_steps=decay)),
optax.apply_every(k=ACCUMULATION_STEPS)
)
# The same thing, in PyTorch
optimizer = optim.RMSprop(model_params, lr=LEARNING_RATE)
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=TOTAL_STEPS)
for i, (inputs, targets) in enumerate(data_loader):
# ... Training loop body ...
if (i + 1) % ACCUMULATION_STEPS == 0:
torch.nn.utils.clip_grad_norm_(model.parameters(), GRADIENT_CLIP_VALUE)
optimizer.step()
scheduler.step()
optimizer.zero_grad()
Das vorherige Code-Snippet zeigt, wie ein Optimierer mit einer benutzerdefinierten Lernrate, Gradientenbeschneidung und Gradientenakkumulierung eingerichtet wird.
Wichtige Stärken
- Umfangreiche Bibliothek:Bietet eine umfassende Bibliothek mit Verlusten, Optimierern und Algorithmen, wobei der Schwerpunkt auf Richtigkeit und Lesbarkeit liegt.
- Modulare, verkettbare Transformationen:Mit dieser flexiblen API können Sie leistungsstarke, komplexe Optimierungsstrategien deklarativ erstellen, ohne den Trainingszyklus zu ändern.
- Funktional und skalierbar:Die rein funktionalen Implementierungen lassen sich nahtlos in die Parallelisierungsmechanismen von JAX einfügen (z. B. pmap). So können Sie denselben Code verwenden, um von einem einzelnen Host auf große Cluster zu skalieren.
Orbax / TensorStore – Verteilte Prüfpunkte in großem Maßstab
Orbax ist eine Checkpointing-Bibliothek für JAX, die für jede Größenordnung entwickelt wurde, von einzelnen Geräten bis hin zu umfangreichen verteilten Trainings. Ziel ist es, fragmentierte Checkpointing-Implementierungen zu vereinheitlichen und wichtige Leistungsfunktionen wie asynchrones und mehrstufiges Checkpointing für eine breitere Zielgruppe bereitzustellen. Orbax bietet die für umfangreiche Trainingsjobs erforderliche Robustheit und ein flexibles Format für die Veröffentlichung von Checkpoints.
Im Gegensatz zu allgemeinen Checkpoint- und Wiederherstellungssystemen, die den gesamten Systemstatus erfassen, werden beim ML-Checkpointing mit Orbax nur die Informationen selektiv gespeichert, die für die Wiederaufnahme des Trainings erforderlich sind: Modellgewichte, Optimierungsstatus und Status des Datenladeprogramms. So werden Ausfallzeiten des Beschleunigers minimiert. Orbax erreicht dies durch die Überlappung von E/A-Vorgängen mit Berechnungen, was für große Arbeitslasten von entscheidender Bedeutung ist. Die Zeit, in der die Zeitbeschleuniger im Leerlauf sind, wird auf die Dauer der Datenübertragung vom Gerät zum Host reduziert. Diese kann weiter mit dem nächsten Trainingsschritt überlappen, sodass das Erstellen von Prüfpunkten aus Leistungssicht nahezu kostenlos ist.
Im Kern verwendet Orbax TensorStore für das effiziente, parallele Lesen und Schreiben von Arraydaten. Die Orbax API abstrahiert diese Komplexität und bietet eine nutzerfreundliche Oberfläche für die Verarbeitung von PyTrees, der Standarddarstellung von Modellen in JAX.
Wichtige Stärken:
- Weitverbreitete Nutzung: Mit Millionen von Downloads pro Monat ist Orbax ein gängiges Medium zum Teilen von ML-Artefakten.
- Vereinfacht Komplexität: Orbax abstrahiert die Komplexität des verteilten Checkpointing, einschließlich asynchronen Speicherns, Atomizität und Dateisystemdetails.
- Flexibel: Orbax bietet APIs für gängige Anwendungsfälle, ermöglicht es Ihnen aber auch, Ihren Workflow an spezielle Anforderungen anzupassen.
- Leistungsstark und skalierbar: Funktionen wie asynchrones Checkpointing, ein effizientes Speicherformat (OCDBT) und intelligente Strategien zum Laden von Daten sorgen dafür, dass Orbax auf Trainingsläufe mit Zehntausenden von Knoten skaliert werden kann.
Grain: Deterministische und skalierbare Eingabedatenpipelines
Grain ist eine Python-Bibliothek zum Lesen und Verarbeiten von Daten für das Training und die Bewertung von JAX-Modellen. Sie ist flexibel, schnell und deterministisch und unterstützt erweiterte Funktionen wie das Erstellen von Prüfpunkten, die für das erfolgreiche Trainieren großer Arbeitslasten unerlässlich sind. Es unterstützt gängige Datenformate und Speicher-Back-Ends und bietet außerdem eine flexible API, um die Unterstützung auf benutzerdefinierte Formate und Back-Ends auszuweiten, die nicht nativ unterstützt werden. Grain wurde zwar hauptsächlich für die Verwendung mit JAX entwickelt, ist aber frameworkunabhängig, erfordert keine JAX-Ausführung und kann auch mit anderen Frameworks verwendet werden.
Motivation
Datenpipelines sind ein wichtiger Bestandteil der Trainingsinfrastruktur. Sie müssen flexibel sein, damit gängige Transformationen effizient ausgedrückt werden können, und leistungsstark genug, um die Beschleuniger jederzeit zu nutzen. Außerdem müssen sie mehrere Speicherformate und ‑backends unterstützen. Aufgrund der längeren Schrittzeiten stellt das Trainieren großer Modelle im großen Maßstab zusätzliche Anforderungen an die Datenpipeline, die über die Anforderungen regulärer Trainingsarbeitslasten hinausgehen. Diese konzentrieren sich hauptsächlich auf Determinismus und Reproduzierbarkeit.2 Die Grain-Bibliothek ist mit einer flexiblen Architektur konzipiert, die diesen Anforderungen gerecht wird.
2 Im Abschnitt 5.1 des PaLM-Papers stellen die Autoren fest, dass sie trotz aktivierter Gradientenbeschneidung sehr große Verlustspitzen beobachtet haben. Die Lösung bestand darin, die fehlerhaften Datenbatches zu entfernen und das Training ab einem Checkpoint vor dem Verlustanstieg neu zu starten. Dies ist nur mit einer vollständig deterministischen und reproduzierbaren Trainingskonfiguration möglich.
Design
Auf höchster Ebene gibt es zwei Möglichkeiten, eine Eingabepipeline zu strukturieren: als separaten Cluster von Daten-Workern oder durch die gemeinsame Platzierung der Daten-Worker auf den Hosts, die die Beschleuniger steuern. Grain hat sich aus verschiedenen Gründen für Letzteres entschieden.
Accelerators werden mit leistungsstarken Hosts kombiniert, die während der Trainingsschritte in der Regel im Leerlauf sind. Daher ist es naheliegend, die Pipeline für Eingabedaten darauf auszuführen. Diese Implementierung bietet weitere Vorteile: Sie vereinfacht die Ansicht der Datenpartitionierung, da die Partitionierung von Eingabe- und Berechnungsdaten einheitlich erfolgt. Es könnte argumentiert werden, dass durch die Platzierung des Data-Workers auf dem Accelerator-Host die Host-CPU überlastet wird. Dies schließt jedoch nicht aus, dass rechenintensive Transformationen mithilfe von RPCs3 auf einen anderen Cluster ausgelagert werden.
Auf der API-Seite bietet Grain mit einer reinen Python-Implementierung, die mehrere Prozesse und eine flexible API unterstützt, die Möglichkeit, beliebig komplexe Datentransformationen zu implementieren, indem Pipelinephasen auf der Grundlage von bekannten Transformations-Paradigmen zusammengestellt werden.
Grain unterstützt standardmäßig effiziente Datenformate für den Direktzugriff wie ArrayRecord und Bagz sowie andere gängige Datenformate wie Parquet und TFDS. Grain unterstützt standardmäßig das Lesen aus lokalen Dateisystemen und aus Cloud Storage. Neben der Unterstützung gängiger Speicherformate und ‑Back-Ends ermöglicht eine saubere Abstraktion der Speicherebene, Unterstützung für Ihre vorhandenen Datenquellen hinzuzufügen oder sie so zu umschließen, dass sie mit der Grain-Bibliothek kompatibel sind.
3 So müssen multimodale Datenpipelines funktionieren: Bild- und Audio-Tokenisierung sind beispielsweise Modelle, die in eigenen Clustern auf eigenen Beschleunigern ausgeführt werden. Die Eingabepipelines würden RPC-Aufrufe ausführen, um Datenbeispiele in Streams von Tokens zu konvertieren.
Wichtige Stärken
- Deterministische Datenzuführung:Durch die gemeinsame Platzierung des Data-Workers mit dem Beschleuniger und die Kopplung mit einem stabilen globalen Shuffle und Checkpointable-Iteratoren können der Modellstatus und der Datenpipelinestatus mit Orbax in einem konsistenten Snapshot zusammen gespeichert werden, was die Deterministik des Trainingsprozesses verbessert.
- Flexible APIs für leistungsstarke Datentransformationen:Mit einer flexiblen, reinen Python-API für Transformationen können Sie umfangreiche Datentransformationen in der Pipeline für die Eingabeverarbeitung durchführen.
- Erweiterbare Unterstützung für mehrere Formate und Back-Ends:Eine erweiterbare API für Datenquellen unterstützt gängige Speicherformate und Back-Ends und ermöglicht es Ihnen, Unterstützung für neue Formate und Back-Ends hinzuzufügen.
- Leistungsstarke Debugging-Schnittstelle:Mit Visualisierungstools für Datenpipelines und einem Debug-Modus können Sie die Leistung Ihrer Datenpipelines analysieren, debuggen und optimieren.
Der erweiterte JAX AI-Stack
Über den Kern-Stack hinaus bietet ein umfangreiches Ökosystem spezialisierter Bibliotheken die Infrastruktur, die fortschrittlichen Tools und die Lösungen auf Anwendungsebene, die für die End-to-End-ML-Entwicklung erforderlich sind.
Grundlegende Infrastruktur: Compiler und Runtimes
XLA: Die hardwareunabhängige, compilerzentrierte Engine
Motivation
XLA oder Accelerated Linear Algebra ist der domänenspezifische Compiler von Google, der gut in JAX integriert ist und TPU-, CPU- und GPU-Hardwaregeräte unterstützt. XLA wurde als hardwareunabhängiger Codegenerator für TPUs, GPUs und CPUs entwickelt.
Das Compiler-First-Design des XLA-Compilers ist eine grundlegende architektonische Entscheidung, die in einer sich schnell entwickelnden Forschungslandschaft einen dauerhaften Vorteil schafft. Im Gegensatz dazu basiert der vorherrschende kernelzentrierte Ansatz in anderen Ökosystemen auf manuell optimierten Bibliotheken für die Leistung. Das ist zwar sehr effektiv für stabile, etablierte Modellarchitekturen, stellt aber ein Hindernis für Innovationen dar. Wenn durch neue Forschung neuartige Architekturen eingeführt werden, muss das Ökosystem auf das Schreiben und Optimieren neuer Kernel warten. Unser compilerzentriertes Design kann jedoch oft auf neue Muster verallgemeinert werden und bietet von Anfang an einen leistungsstarken Pfad für innovative Forschung.
Design
XLA funktioniert durch die Just-In-Time-Kompilierung (JIT) der Berechnungsdiagramme, die JAX während des Tracing-Prozesses generiert (z. B. wenn eine Funktion mit @jax.jit dekoriert wird).
Die Kompilierung erfolgt in einer mehrstufigen Pipeline:
- JAX-Berechnungsgraph
- High-Level-Optimizer (HLO)
- Low-Level Optimizer (LLO)
- Hardwarecode
- Von JAX-Graph zu HLO: Der JAX-Berechnungsgraph wird in die HLO-Darstellung von XLA konvertiert. Auf dieser hohen Ebene werden leistungsstarke, hardwareunabhängige Optimierungen wie die Operator-Zusammenführung und das effiziente Speichermanagement angewendet. Der StableHLO-Dialekt dient als dauerhafte, versionierte Schnittstelle für diese Phase.
- Von HLO zu LLO:Nach den High-Level-Optimierungen übernehmen hardwarespezifische Back-Ends und wandeln die HLO-Darstellung in eine maschinenorientierte LLO um.
- Von LLO zu Hardware-Code:Der LLO wird schließlich in hocheffizienten Maschinencode kompiliert. Bei TPUs wird dieser Code als Very Long Instruction Word (VLIW)-Pakete gebündelt, die direkt an die Hardware gesendet werden.
Für die Skalierung ist das Design von XLA auf Parallelität ausgelegt. Dabei werden Algorithmen verwendet, um die Matrix-Multiplikationseinheiten (Matrix Multiplication Units, MXUs) auf einem Chip optimal zu nutzen. Zwischen Chips verwendet XLA SPMD (Single Program Multiple Data), eine compilerbasierte Parallelisierungstechnik, bei der ein einzelnes Programm auf allen Geräten verwendet wird. Dieses leistungsstarke Modell wird über JAX-APIs bereitgestellt. So können Sie Daten-, Modell- oder Pipeline-Parallelität mit Sharding-Annotationen auf hoher Ebene verwalten.
Für komplexere Parallelitätsmuster ist auch Multiple Program Multiple Data (MPMD) möglich. Mit Bibliotheken wie PartIR:MPMD können JAX-Nutzer auch MPMD-Annotationen bereitstellen.
Wichtige Stärken
- Kompilierung: Die Just-in-Time-Kompilierung des Berechnungsdiagramms ermöglicht Optimierungen des Speicherlayouts, der Pufferzuweisung und der Speicherverwaltung. Bei Alternativen wie kernelbasierten Methoden liegt diese Last beim Entwickler. In den meisten Fällen kann XLA eine hervorragende Leistung erzielen, ohne die Entwicklungsgeschwindigkeit zu beeinträchtigen.
- Parallelität:XLA implementiert verschiedene Formen der Parallelität mit SPMD, die auf JAX-Ebene verfügbar sind. So können Sie Sharding-Strategien ausdrücken und Modelle auf Tausenden von Chips testen und skalieren.
Pathways: Eine einheitliche Laufzeitumgebung für verteilte Berechnungen in großem Maßstab
Pathways bietet Abstraktionen für verteiltes Training und Inferenz mit integrierter Fehlertoleranz und ‑behebung, sodass ML-Forscher so programmieren können, als würden sie eine einzelne, leistungsstarke Maschine verwenden.
Motivation
Um große Modelle trainieren und bereitstellen zu können, sind Hunderte bis Tausende von Chips erforderlich. Diese Chips sind auf zahlreiche Racks und Host-Computer verteilt. Ein Trainingsjob ist ein groß angelegtes synchrones Programm, für das alle diese Chips und die entsprechenden Hosts zusammen an parallelisierten (sharded) XLA-Berechnungen arbeiten müssen. Bei großen Sprachmodellen, für die möglicherweise mehr als zehntausend Chips erforderlich sind, muss dieser Dienst in der Lage sein, mehrere Pods in einem Rechenzentrumsnetzwerk zu umfassen und zusätzlich Interchip Interconnect (ICI) und On-Chip Interconnect (OCI) innerhalb eines Pods zu verwenden.
Design
ML Pathways ist das System, das wir zum Koordinieren verteilter Berechnungen auf Hosts und TPU-Chips verwenden. Sie ist für Skalierbarkeit und Effizienz bei Hunderttausenden von Beschleunigern konzipiert. Für das Training im großen Maßstab bietet es einen einzelnen Python-Client für mehrere Pod-Jobs, die Megascale XLA-Integration, einen Kompilierungsdienst und Remote-Python. Außerdem werden Parallelität über mehrere Slices hinweg und Toleranz gegenüber Unterbrechungen unterstützt, sodass eine automatische Wiederherstellung nach Ressourcenunterbrechungen möglich ist.
Pathways enthält optimierte kollektive Vorgänge für mehrere Hosts, mit denen sich XLA-Berechnungsdiagramme über einen einzelnen TPU-Pod hinaus erstrecken können. Es erweitert die Unterstützung von XLA für Daten-, Modell- und Pipeline-Parallelität, um über TPU-Slice-Grenzen hinweg zu arbeiten. Dazu wird das Rechenzentrumsnetzwerk (Data Center Network, DCN) verwendet, indem eine verteilte Laufzeitumgebung integriert wird, die die DCN-Kommunikation mit XLA-Kommunikationsprimitiven verwaltet.
Wichtige Stärken
Die Architektur mit einem einzelnen Controller, die in JAX integriert ist, ist eine wichtige Abstraktion. Damit können Forscher verschiedene Sharding- und Parallelisierungsstrategien für das Training und die Bereitstellung untersuchen und gleichzeitig problemlos auf Zehntausende von Chips skalieren.
Erweiterte Entwicklung: Leistung, Daten und Effizienz
Pallas: Benutzerdefinierte leistungsstarke Kernel in JAX schreiben
JAX ist zwar in erster Linie ein Compiler, aber es gibt Situationen, in denen Sie die Hardware genau steuern möchten, um maximale Leistung zu erzielen. Pallas ist eine Erweiterung von JAX, mit der benutzerdefinierte Kernel für GPUs und TPUs geschrieben werden können. Ziel ist es, eine präzise Steuerung des generierten Codes mit der Ergonomie von JAX-Tracing und der jax.numpy-API zu kombinieren.
Pallas bietet ein rasterbasiertes Parallelitätsmodell, bei dem eine nutzerdefinierte Kernelfunktion in einem mehrdimensionalen Raster paralleler Arbeitsgruppen gestartet wird. Damit lässt sich die Speicherhierarchie explizit verwalten, da Sie definieren können, wie Tensoren gekachelt und zwischen langsamerem, größerem Speicher (z. B. HBM) und schnellerem, kleinerem On-Chip-Speicher (z. B. VMEM auf TPU, Shared Memory auf GPU) übertragen werden. Dazu werden Indexzuordnungen verwendet, um Rasterpositionen bestimmten Datenblöcken zuzuordnen. Mit Pallas kann dieselbe Kerneldefinition so reduziert werden, dass sie sowohl auf Google-TPUs als auch auf verschiedenen GPUs effizient ausgeführt werden kann. Dazu werden Kerne in eine Zwischenrepräsentation kompiliert, die für die Zielarchitektur geeignet ist – Mosaic für TPUs oder Technologien wie Triton für GPUs. Mit Pallas können Sie leistungsstarke Kernel schreiben, die Blöcke wie Attention optimieren, um die beste Modellleistung auf der Zielhardware zu erzielen, ohne auf anbieterspezifische Toolkits angewiesen zu sein.
Tokamax: Eine kuratierte Bibliothek mit hochmodernen Kernels
Wenn Pallas ein Tool zum Erstellen von Kernels ist, ist Tokamax eine Bibliothek mit hochmodernen benutzerdefinierten Beschleuniger-Kernels, die sowohl TPUs als auch GPUs unterstützen. Tokamax basiert auf JAX und Pallas und ermöglicht es Ihnen, die volle Leistung Ihrer Hardware zu nutzen. Außerdem bietet es Tools zum Erstellen und automatischen Optimieren benutzerdefinierter Kernel.
Motivation
JAX, das auf XLA basiert, ist ein Compiler-First-Framework. Es gibt jedoch einige wenige Fälle, in denen Sie die Hardware direkt steuern müssen, um maximale Leistung zu erzielen.4 Benutzerdefinierte Kernel sind entscheidend, um die beste Leistung aus teuren ML-Beschleunigerressourcen wie TPUs und GPUs zu erzielen. Sie werden häufig eingesetzt, um die leistungsstarke Ausführung wichtiger Operatoren wie „Attention“ zu ermöglichen. Die Implementierung erfordert jedoch ein tiefes Verständnis sowohl des Modells als auch der Zielhardwarearchitektur. Tokamax bietet eine autoritative Quelle für kuratierte, gut getestete und leistungsstarke Kernel in Verbindung mit einer robusten gemeinsamen Infrastruktur für ihre Entwicklung, Wartung und Lebenszyklusverwaltung. Eine solche Bibliothek kann auch als Referenzimplementierung dienen, auf der Sie aufbauen und die Sie nach Bedarf anpassen können. So können Sie sich auf die Modellierung konzentrieren, ohne sich um die Infrastruktur kümmern zu müssen.
4Dies ist ein etabliertes Paradigma, das es auch in der CPU-Welt gibt. Dort bildet kompilierter Code den Großteil des Programms und Entwickler greifen auf intrinsische Funktionen oder Inline-Assembly zurück, um leistungsrelevante Abschnitte zu optimieren.
Design
Für jeden Kernel bietet Tokamax eine gemeinsame API, die von mehreren Implementierungen unterstützt werden kann. TPU-Kernel können beispielsweise entweder durch standardmäßiges XLA-Lowering oder explizit mit Pallas/Mosaic-TPU implementiert werden. GPU-Kernels können durch standardmäßiges XLA-Lowering, mit Mosaic-GPU oder mit Triton implementiert werden. Standardmäßig wählt die Tokamax API die beste bekannte Implementierung für eine bestimmte Konfiguration aus. Diese wird anhand von Zwischenspeicherergebnissen aus regelmäßigen Autotuning- und Benchmarking-Läufen ermittelt. Bei Bedarf können Sie jedoch auch bestimmte Implementierungen auswählen. Im Laufe der Zeit können neue Implementierungen hinzugefügt werden, um bestimmte Funktionen in neuen Hardwaregenerationen für eine noch bessere Leistung zu nutzen.
Ein wichtiger Bestandteil der Tokamax-Bibliothek ist neben den Kernels selbst die unterstützende Infrastruktur, mit der Sie benutzerdefinierte Kernels schreiben können. Mit der Infrastruktur für die automatische Optimierung können Sie beispielsweise eine Reihe konfigurierbarer Parameter (z. B. Kachelgrößen) definieren, die Tokamax umfassend durchlaufen kann, um die bestmöglichen optimierten Einstellungen zu ermitteln und im Cache zu speichern. Nächtliche Regressionen schützen Sie vor unerwarteten Leistungs- und numerischen Problemen, die durch Änderungen an der zugrunde liegenden Compiler-Infrastruktur oder anderen Abhängigkeiten verursacht werden.
Wichtige Stärken
- Reibungsloser Entwicklungsprozess: Eine einheitliche, kuratierte Bibliothek bietet bewährte, leistungsstarke Implementierungen wichtiger Kernels mit klaren Angaben zu unterstützten Hardwaregenerationen und erwarteter Leistung, sowohl programmatisch als auch in der Dokumentation. So werden Fragmentierung und Abwanderung minimiert.
- Flexibilität und Lebenszyklusverwaltung:Sie können verschiedene Implementierungen auswählen und diese bei Bedarf im Laufe der Zeit ändern. Wenn der XLA-Compiler beispielsweise die Unterstützung für bestimmte Vorgänge verbessert, sodass keine benutzerdefinierten Kernel mehr erforderlich sind, gibt es einen Pfad für die Einstellung und Migration.
- Erweiterbarkeit:Sie können Ihre eigenen Kernel implementieren und gleichzeitig die gut unterstützte gemeinsame Infrastruktur nutzen. So können Sie sich auf Mehrwertfunktionen und Optimierungen konzentrieren. Klar formulierte Standardimplementierungen dienen als Ausgangspunkt, von dem Nutzer lernen und den sie erweitern können.
Qwix: Unaufdringliche, umfassende Quantisierung
Qwix ist eine umfassende Quantisierungsbibliothek für den JAX AI-Stack, die sowohl LLMs als auch andere Modelltypen in allen Phasen unterstützt, einschließlich Training (Quantization Aware Training (QAT), Quantization Technique (QT), Quantized Low-Rank Adaptation (QLoRA)) und Inferenz (Post Training Quantization (PTQ)), die sowohl auf XLA- als auch auf On-Device-Runtimes ausgerichtet ist.
Motivation
Vorhandene Quantisierungsbibliotheken, insbesondere im PyTorch-Ökosystem, dienen oft nur begrenzten Zwecken (z. B. nur PTQ oder nur QLoRA). Diese fragmentierte Landschaft zwingt Sie, Tools zu wechseln, was die konsistente Verwendung von Code und den präzisen numerischen Abgleich zwischen Training und Inferenz behindert. Außerdem erfordern viele Lösungen erhebliche Modelländerungen, wodurch die Modelllogik eng mit der Quantisierungslogik verknüpft wird.
Design
Die Designphilosophie von Qwix legt den Schwerpunkt auf eine umfassende Lösung und, was entscheidend ist, auf eine nicht aufdringliche Modellintegration. Es ist hierarchisch und erweiterbar aufgebaut und basiert auf wiederverwendbaren funktionalen APIs.
Diese nicht aufdringliche Integration wird durch einen sorgfältig entwickelten Abfangmechanismus erreicht, der JAX-Funktionen an ihre quantisierten Gegenstücke weiterleitet. So können Sie Ihre Modelle ohne Änderungen einbinden und den Quantisierungscode vollständig von den Modelldefinitionen entkoppeln.
Im folgenden Beispiel wird gezeigt, wie die w4a4-Quantisierung (4-Bit-Gewichtung, 4-Bit-Aktivierung) auf die MLP-Ebenen eines LLM und die w8-Quantisierung (8-Bit-Gewichtung) auf den Embedder angewendet wird. Wenn Sie das Quantisierungsrezept ändern möchten, müssen Sie nur die Regelliste aktualisieren.
fp_model = ModelWithoutQuantization(...)
rules = [
qwix.QuantizationRule(
module_path=r'embedder',
weight_qtype='int8',
),
qwix.QuantizationRule(
module_path=r'layers_\d+/mlp',
weight_qtype='int4',
act_qtype='int4',
tile_size=128,
weight_calibration_method='rms,7',
),
]
quantized_model = qwix.quantize_model(fp_model, qwix.PtqProvider(rules))
Wichtige Stärken
- Umfassende Lösung:Qwix ist in zahlreichen Quantisierungsszenarien breit anwendbar und sorgt für eine einheitliche Codeverwendung zwischen Training und Inferenz.
- Unaufdringliche Modellintegration:Wie das Beispiel zeigt, können Sie Modelle mit einer einzigen Codezeile einbinden. So können Sie Hyperparameter für viele Quantisierungsschemas verwenden, um das beste Verhältnis zwischen Qualität und Leistung zu finden.
- Mit anderen Bibliotheken zusammengeführt:Qwix lässt sich nahtlos in den JAX-KI-Stack einbinden. Tokamax passt sich beispielsweise automatisch an, um quantisierte Versionen von Kernels zu verwenden, ohne dass zusätzlicher Nutzercode erforderlich ist, wenn das Modell mit Qwix quantisiert wird.
- Forschungsfreundlich:Die grundlegenden APIs und die erweiterbare Architektur von Qwix ermöglichen es Forschern, neue Algorithmen zu untersuchen und mit integrierten Benchmark- und Bewertungstools unkomplizierte Vergleiche durchzuführen.
Die Anwendungsebene: Training und Anpassung
Foundation Model-Training: MaxText und MaxDiffusion
MaxText und MaxDiffusion sind die wichtigsten Frameworks von Google für das Training von LLMs bzw. Diffusionsmodellen. Diese Repositories enthalten eine Auswahl hochoptimierter Implementierungen beliebter Open-Weight-Modelle. Sie haben einen doppelten Zweck: Sie dienen sowohl als sofort einsatzbereite Codebasis für das Modelltraining als auch als Referenz, auf die Foundation Model-Entwickler aufbauen können.
Motivation
Das Interesse an der Entwicklung von Modellen, die auf generativer KI basieren, wächst in der gesamten Branche rasant. Die Beliebtheit offener Modelle hat diesen Trend beschleunigt und bewährte Architekturen bereitgestellt. Für das Training und die Anpassung dieser Modelle sind hohe Leistung, Effizienz, Skalierbarkeit auf eine große Anzahl von Chips und klarer, verständlicher Code erforderlich. MaxText und MaxDiffusion sind umfassende Lösungen, die auf TPUs oder GPUs verwendet werden können und auf diese Anforderungen zugeschnitten sind.
Design
MaxText und MaxDiffusion sind Codebases für Fundierungsmodelle, die auf Lesbarkeit und Leistung ausgelegt sind. Sie sind mit gut getesteten, wiederverwendbaren Komponenten strukturiert: Modelldefinitionen, die benutzerdefinierte Kerne (z. B. Tokamax) für maximale Leistung verwenden, ein Trainings-Harness für Orchestrierung und Monitoring sowie ein leistungsstarkes Konfigurationssystem, mit dem Sie Details wie Sharding und Quantisierung (mit Qwix) über eine intuitive Benutzeroberfläche steuern können. Es werden erweiterte Zuverlässigkeitsfunktionen wie das mehrstufige Checkpointing verwendet, um einen nachhaltigen Durchsatz zu gewährleisten.
MaxText und MaxDiffusion nutzen die besten JAX-Bibliotheken – Qwix, Tunix, Orbax und Optax –, um Kernfunktionen bereitzustellen. Diese Bibliotheken bieten eine robuste, skalierbare Infrastruktur, die den Entwicklungsaufwand reduziert und es Ihnen ermöglicht, sich auf die Modellierungsaufgabe zu konzentrieren. Für die Inferenz wird der Modellcode freigegeben, um eine effiziente und skalierbare Bereitstellung zu ermöglichen.
Wichtige Stärken
- Leistungsstark von Grund auf:Die Trainingsinfrastruktur ist für einen hohen „Goodput“ (nützlicher Durchsatz) eingerichtet und die Modellimplementierungen sind für eine hohe MFU (Model Flops Utilization) optimiert. MaxText und MaxDiffusion bieten von Haus aus eine hohe Leistung bei der Skalierung.
- Für Skalierung entwickelt:Diese Frameworks nutzen die Leistungsfähigkeit des JAX AI-Stacks (insbesondere Pathways) und ermöglichen eine nahtlose Skalierung von zehn auf Zehntausende von Chips.
- Solide Grundlage für Foundation Model-Entwickler:Die hochwertigen, lesbaren Implementierungen dienen als solide Grundlage für Entwickler, die sie entweder als End-to-End-Lösung oder als Referenzimplementierung für ihre eigenen Anpassungen verwenden können.
Post-Training und ‑Abstimmung: Das Tunix-Framework
Tunix bietet modernste Open-Source-Algorithmen für Reinforcement Learning (RL) sowie ein robustes Framework und eine robuste Infrastruktur. So können Entwickler LLM-Post-Training-Techniken wie Supervised Fine-Tuning (SFT) und Alignment mit JAX und TPUs optimieren.
Motivation
Das Post-Training ist ein wichtiger Schritt, um das volle Potenzial von LLMs auszuschöpfen. Die Phase des bestärkenden Lernens (Reinforcement Learning, RL) ist besonders wichtig für die Entwicklung von Fähigkeiten zur Ausrichtung und zum logischen Denken. Die Open-Source-Entwicklung in diesem Bereich basiert fast ausschließlich auf PyTorch und GPUs, was eine grundlegende Lücke für JAX- und TPU-Lösungen hinterlässt. Tunix (Tune-in-JAX) ist eine leistungsstarke, JAX-native Bibliothek, die genau für diesen Zweck entwickelt wurde.
Design
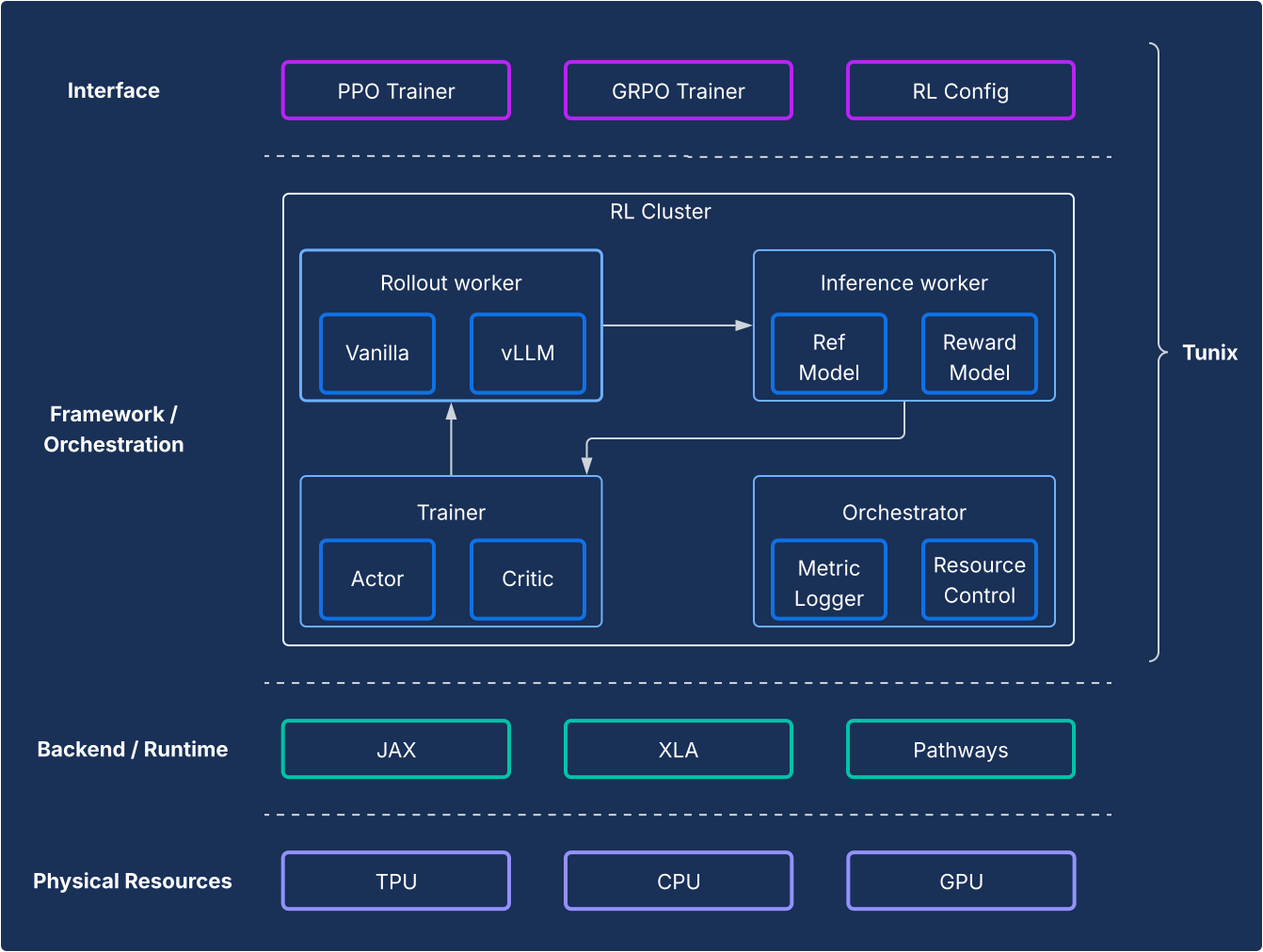
Aus Framework-Sicht ermöglicht Tunix eine moderne Einrichtung, die RL-Algorithmen klar von der Infrastruktur trennt. Sie bietet eine einfache, clientähnliche API, die die Komplexität der RL-Infrastruktur verbirgt, sodass Sie neue Algorithmen entwickeln können. Tunix bietet sofort einsatzbereite Lösungen für beliebte Algorithmen wie Proximal Policy Optimization (PPO), Direct Preference Optimization (DPO) und andere.
Auf der Infrastrukturseite ist Tunix in Pathways integriert, was eine Architektur mit einem Controller ermöglicht, die das RL-Training mit mehreren Knoten zugänglich macht. Beim Training unterstützt Tunix nativ parameter-effizientes Training (z. B. LoRA) und nutzt JAX-Sharding und XLA (General and Scalable Parallelization for ML Computation Graph, GSPMD), um einen leistungsstarken Berechnungsdiagramm zu generieren. Beliebte Open-Source-Modelle wie Gemma und Llama werden sofort unterstützt.
Wichtige Stärken
- Einfachheit:Die Bibliothek bietet eine Client-ähnliche API auf hoher Ebene, die die Komplexität der zugrunde liegenden verteilten Infrastruktur abstrahiert.
- Entwicklereffizienz:Tunix beschleunigt den Forschungs- und Entwicklungszyklus durch integrierte Algorithmen und „Rezepte“. So erhalten Sie ein funktionierendes Modell und können schnell Iterationen durchführen.
- Leistung und Skalierbarkeit:Tunix ermöglicht eine hocheffiziente und horizontal skalierbare Trainingsinfrastruktur, indem Pathways als einzelner Controller im Backend verwendet wird.
Die Anwendungsebene: Produktion und Inferenz
Eine historische Herausforderung bei der Einführung von JAX war der Weg von der Forschung zur Produktion. Der JAX-KI-Stack bietet jetzt eine ausgereifte, zweigleisige Produktionsgeschichte, die sowohl Ökosystemkompatibilität als auch JAX-Leistung bietet.
Hochleistungs-LLM-Inferenz: Die vLLM-Lösung
vLLM-TPU ist der leistungsstarke Inferenz-Stack von Google, der für die effiziente Ausführung von PyTorch- und JAX-LLMs (Large Language Models) auf Cloud TPUs entwickelt wurde. Das wird durch die native Integration des beliebten Open-Source-Frameworks vLLM in das JAX- und TPU-Ökosystem von Google erreicht.
Motivation
Die Branche entwickelt sich rasant und die Nachfrage nach nahtlosen, leistungsstarken und benutzerfreundlichen Inferenzlösungen steigt. Entwickler stehen oft vor großen Herausforderungen, die durch komplexe und inkonsistente Tools, eine schlechte Leistung und eine eingeschränkte Modellkompatibilität entstehen. Der vLLM-Stack bietet eine einheitliche, leistungsstarke und intuitive Plattform, um diese Probleme zu beheben.
Design
Diese Lösung erweitert das vLLM-Framework, anstatt es neu zu entwickeln. vLLM-TPU ist eine hoch optimierte Open-Source-LLM-Bereitstellungs-Engine, die für ihren hohen Durchsatz bekannt ist. Dieser wird durch wichtige Funktionen wie PagedAttention (die KV-Caches wie virtuellen Speicher verwaltet, um die Fragmentierung zu minimieren) und Continuous Batching (die Anfragen dynamisch dem Batch hinzufügt, um die Auslastung zu verbessern) erreicht.
vLLM-TPU baut auf dieser Grundlage auf und entwickelt Kernkomponenten für die Verarbeitung von Anfragen, die Planung und die Speicherverwaltung. Es wird ein JAX-basiertes Backend eingeführt, das als Brücke dient und den Berechnungsdiagramm und die Speicheroperationen von vLLM in TPU-ausführbaren Code übersetzt. Dieses Backend übernimmt die Geräteinteraktionen, die Ausführung von JAX-Modellen und die Besonderheiten der Verwaltung des KV-Cache auf TPU-Hardware. Sie enthält TPU-spezifische Optimierungen wie effiziente Attention-Mechanismen (z. B. die Nutzung von JAX-Pallas-Kernen für Ragged Paged Attention) und Quantisierung, die alle auf die TPU-Architektur zugeschnitten sind.
Wichtige Stärken
- Keine Kosten für das Onboarding/Offboarding von Nutzern:Nutzer können diese Lösung ohne großen Aufwand nutzen. Aus Sicht der Nutzerfreundlichkeit sollte die Verarbeitung von Inferenzanfragen auf TPUs genauso wie auf GPUs erfolgen. Die CLI zum Starten des Servers, zum Akzeptieren von Aufforderungen und zum Zurückgeben von Ausgaben wird gemeinsam genutzt.
- Ökosystem vollständig nutzen:Bei diesem Ansatz wird die vLLM-Schnittstelle und ‑Nutzerfreundlichkeit genutzt und weiterentwickelt, um Kompatibilität und Benutzerfreundlichkeit zu gewährleisten.
- Austauschbarkeit zwischen TPUs und GPUs:Die Lösung funktioniert effizient auf TPUs und GPUs und bietet Ihnen so Flexibilität.
- Kosteneffizient (Best Perf/$): Optimiert die Leistung, um das beste Leistungs-/Kostenverhältnis für beliebte Modelle zu bieten.
JAX-Bereitstellung: Orbax-Serialisierung und Neptune-Bereitstellungs-Engine
Für andere Modelle als LLMs oder für Nutzer, die eine vollständig JAX-native Pipeline wünschen, bieten die Orbax-Serialisierungsbibliothek und das Neptune Serving Engine (NSE)-System eine End-to-End-Lösung mit hoher Leistung.
Motivation
Bisher mussten JAX-Modelle oft einen umständlichen Weg zur Produktion durchlaufen, z. B. indem sie in TensorFlow-Graphen eingebunden und mit TensorFlow Serving bereitgestellt wurden. Dieser Ansatz führte zu erheblichen Einschränkungen und Ineffizienzen, da Entwickler mit einem separaten Ökosystem interagieren mussten, was die Iteration verlangsamte. Ein dediziertes JAX-natives Bereitstellungssystem ist entscheidend für Nachhaltigkeit, weniger Komplexität und optimierte Leistung.
Design
Diese Lösung besteht aus zwei Kernkomponenten, wie im folgenden Diagramm dargestellt.
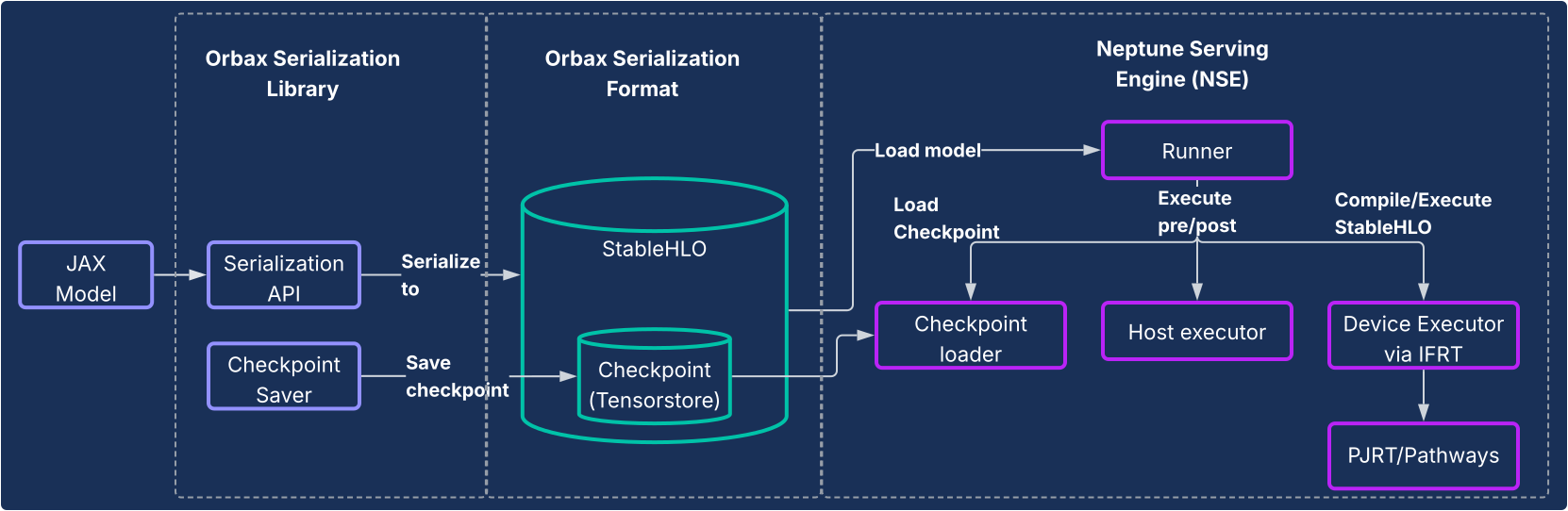
- Orbax Serialization Library:Bietet nutzerfreundliche APIs zum Serialisieren von JAX-Modellen in ein neues, robustes Orbax-Serialisierungsformat. Dieses Format ist für die Bereitstellung in der Produktion optimiert. Es stellt JAX-Modellberechnungen direkt mit StableHLO dar, sodass der Berechnungsdiagramm nativ dargestellt werden kann. Außerdem wird TensorStore zum Speichern von Gewichten verwendet, was ein schnelles Laden von Checkpoints für die Bereitstellung ermöglicht.
- Neptune Serving Engine (NSE): Dies ist die zugehörige leistungsstarke, flexible Bereitstellungs-Engine (wird in der Regel als C++-Binärdatei bereitgestellt), die für die native Ausführung von JAX-Modellen im Orbax-Format entwickelt wurde. NSE bietet produktionswichtige Funktionen wie schnelles Laden von Modellen, gleichzeitige Bereitstellung mit hohem Durchsatz mit integrierter Batchverarbeitung, Unterstützung für mehrere Modellversionen sowie die Bereitstellung auf einem einzelnen Host und auf mehreren Hosts (mit PJRT und Pathways). Die Neptune Serving Engine kann für Folgendes verwendet werden:
- Nicht-LLM-Modelle: Dies ist eine Lösung für allgemeine Zwecke, die sich ideal für Arbeitslasten wie Empfehlungssysteme, Diffusionsmodelle und andere KI-Modelle eignet.
- Kleine LLMs und „One-Shot“-Bereitstellung: Die Architektur ist für nicht autoregressive Modelle oder kleinere Modelle konzipiert, die „unär“ bereitgestellt werden. Dabei wird die gesamte Ausgabe in einem einzigen Durchlauf generiert, ohne dass ein komplexes Statusmanagement wie ein KV-Cache erforderlich ist.
Kurz gesagt: Die Neptune Serving Engine schließt die Lücke für die Bereitstellung der Vielzahl von Modellen, die keine großen, autoregressiven Sprachmodelle sind, und bietet eine leistungsstarke TPU-native Lösung für das breitere ML-Ökosystem.
Wichtige Stärken
- JAX Native Serving:Die Lösung ist nativ für JAX konzipiert, wodurch der Overhead zwischen Frameworks bei der Modellserialisierung und -bereitstellung entfällt. So wird ein schnelles Laden des Modells und eine optimierte Ausführung auf CPUs, GPUs und TPUs gewährleistet.
- Einfache Bereitstellung in der Produktion:Serialisierte Modelle bieten einen hermetischen Bereitstellungspfad, der nicht durch Abweichungen bei Python-Abhängigkeiten beeinträchtigt wird und Laufzeit-Integritätsprüfungen des Modells ermöglicht. Das bietet einen nahtlosen, intuitiven Weg für die Produktion von JAX-Modellen.
- Verbesserte Entwicklerfreundlichkeit:Da kein umständliches Framework-Wrapping erforderlich ist, werden Abhängigkeiten und Systemkomplexität deutlich reduziert, was die Iteration für JAX-Entwickler beschleunigt.
Systemweite Analyse und Profilerstellung
XProf: Detaillierte, hardwareintegrierte Leistungsprofilierung
XProf ist ein Tool zur Profilerstellung und Leistungsanalyse, das detaillierte Einblicke in verschiedene Aspekte der Ausführung von ML-Arbeitslasten bietet. So können Sie die Leistung debuggen und optimieren. Sie ist umfassend in die JAX- und TPU-Ökosysteme integriert.
Motivation
Einerseits werden ML-Arbeitslasten immer komplexer. Andererseits gibt es eine Explosion von spezialisierten Hardwarefunktionen, die auf diese Arbeitslasten ausgerichtet sind. Angesichts der enormen Kosten für die ML-Infrastruktur ist es entscheidend, die beiden effektiv aufeinander abzustimmen, um Spitzenleistung und Effizienz zu gewährleisten. Dazu sind detaillierte Informationen sowohl zur Arbeitslast als auch zur Hardware erforderlich, die schnell verfügbar sind. XProf ist dafür bestens geeignet.
Design
XProf besteht aus zwei Hauptkomponenten: Erfassung und Analyse.
- Erfassung:XProf erfasst Informationen aus verschiedenen Quellen: Anmerkungen in Ihrem JAX-Code, Kostenmodelle für Vorgänge im XLA-Compiler und speziell entwickelte Hardware-Profilerstellungsfunktionen in der TPU. Diese Erfassung kann programmatisch oder auf Anfrage ausgelöst werden und generiert ein umfassendes Ereignisartefakt.
- Analyse:XProf verarbeitet die erfassten Daten nach und erstellt eine Reihe leistungsstarker Visualisierungen, auf die über einen Browser zugegriffen werden kann.
Wichtige Stärken
Die wahre Stärke von XProf liegt in der tiefen Integration in den gesamten Stack. Das bietet eine Breite und Tiefe der Analyse, die ein greifbarer Vorteil des gemeinsam entwickelten JAX/TPU-Ökosystems ist.
- Speziell für die TPU entwickelt:XProf nutzt Hardwarefunktionen, die speziell für die nahtlose Profilerstellung entwickelt wurden. Dadurch ist der Overhead für die Erfassung weniger als 1%. So kann das Profiling ein einfacher, iterativer Teil der Entwicklung sein.
- Breite und Tiefe der Analyse:XProf bietet detaillierte Analysen über mehrere Achsen hinweg. Zu den Tools gehören:
- Trace Viewer:Eine Zeitachse der Ausführung von Vorgängen auf verschiedenen Hardwareeinheiten (z. B. TensorCores).
- HLO-Vorgangsprofil:Die Gesamtzeit wird in verschiedene Kategorien von Vorgängen unterteilt.
- Memory Viewer (Speicheransicht): Hier werden Details zu Speicherzuweisungen nach verschiedenen Vorgängen während des profilierten Zeitraums angezeigt.
- Roofline-Analyse:Damit können Sie ermitteln, ob bestimmte Vorgänge rechen- oder speichergebunden sind und wie weit sie von den Spitzenfunktionen der Hardware entfernt sind.
- Graph Viewer:Bietet eine Ansicht des vollständigen HLO-Graphen, der von der Hardware ausgeführt wird.
Vergleichsperspektive: Der JAX/TPU-Stack als attraktive Option
Die moderne Landschaft des maschinellen Lernens bietet viele hervorragende, ausgereifte Toolchains. Der JAX AI-Stack bietet eine einzigartige und überzeugende Reihe von Vorteilen für Entwickler, die sich auf umfangreiches, leistungsstarkes ML konzentrieren. Diese Vorteile ergeben sich direkt aus dem modularen Design und der engen Hardware-Zusammenarbeit.
Viele Frameworks bieten eine Vielzahl von Funktionen, aber der JAX AI Stack bietet spezifische, leistungsstarke Differenzierungsmerkmale in wichtigen Bereichen des Entwicklungslebenszyklus:
- Einfachere, leistungsstärkere Entwicklerumgebung:Das verkettbare Gradiententransformationsparadigma von Optax ermöglicht leistungsstärkere und flexiblere Optimierungsstrategien, die einmal deklariert werden, anstatt imperativ im Trainingszyklus verwaltet zu werden. Auf Systemebene abstrahiert die einfache Single-Controller-Schnittstelle von Pathways die Komplexität des Multislice-Trainings, was eine erhebliche Vereinfachung für Forscher darstellt.
- Für extreme Skalierbarkeit entwickelt:Der JAX-Stack ist für das Training in extremem Maßstab konzipiert. Orbax bietet Funktionen für „heroische Trainingsresilienz“ wie Notfall- und mehrstufige Prüfpunkte. Grain bietet vollständige Unterstützung für die Reproduzierbarkeit mit deterministischen globalen Shuffles und Checkpoint-fähigen Datenloadern. Die Möglichkeit, den Status der Datenpipeline (Grain) und den Modellstatus (Orbax) atomar zu sichern, ist eine wichtige Funktion, um die Reproduzierbarkeit bei Jobs mit langer Ausführungszeit zu gewährleisten.
- Vollständiges End-to-End-Ökosystem:Der Stack bietet eine zusammenhängende End-to-End-Lösung. Entwickler können MaxText als SOTA-Referenz für das Training, Tunix für die Ausrichtung und einen klaren, dualen Pfad zur Produktion mit vLLM-TPU (für vLLM-Kompatibilität) und NSE (für JAX-Leistung) verwenden.
Viele Stacks sind aus Software-Sicht auf hoher Ebene ähnlich. Der entscheidende Faktor ist jedoch oft Leistung/Gesamtbetriebskosten. Hier bietet das Co-Design von JAX und TPUs einen deutlichen Vorteil. Dieser Leistungs-/TCO-Vorteil ist ein direktes Ergebnis der vertikalen Integration von Software und TPU-Hardware. Die Fähigkeit des XLA-Compilers, Vorgänge speziell für die TPU-Architektur zusammenzuführen, oder des XProf-Profilers, Hardware-Hooks für die Profilerstellung mit einem Overhead von unter 1% zu verwenden, sind greifbare Vorteile dieser tiefen Integration.
Für Organisationen, die diesen Stack einführen, minimiert die umfassende Natur des JAX AI-Stacks die Migrationskosten. Für Kunden, die beliebte Open-Model-Architekturen verwenden, ist der Wechsel von anderen Frameworks zu MaxText oft nur eine Frage der Einrichtung von Konfigurationsdateien. Außerdem können mit dem Stack beliebte Prüfpunktformate wie „safetensors“ aufgenommen werden, sodass vorhandene Prüfpunkte migriert werden können, ohne dass ein kostspieliges erneutes Training erforderlich ist.
In der folgenden Tabelle finden Sie eine Zuordnung der Komponenten des JAX AI-Stacks und ihrer Entsprechungen in anderen Frameworks oder Bibliotheken.
| Funktion | JAX | Alternativen/Äquivalente in anderen Frameworks5 |
| Compiler / Laufzeit | XLA | Induktor, eifrig |
| MultiPod-Training | Pathways | Torch-Blitzstrategien, Ray Train, Monarch (neu). |
| Kern-Framework | JAX | PyTorch |
| Modellerstellung | Flax-, Max*-Modelle | torch.nn.*,
NVidia TransformerEngine, HuggingFace Transformers
|
| Optimierer und Verluste | Optax | torch.optim.*, torch.nn.*Loss |
| Data Loader | Körnung | Ray Data, HuggingFace-Dataloader |
| Prüfpunkte | Orbax | Verteilte Prüfpunktausführung von PyTorch, NeMo-Prüfpunktausführung |
| Quantisierung | Qwix | TorchAO, bitsandbytes |
| Kernel-Erstellung und bekannte Implementierungen | Pallas / Tokamax | Triton/Helion, Liger-Kernel, TransformerEngine |
| Nach dem Training / der Abstimmung | Tunix | VERL, NeMoRL |
| Profilerstellung | XProf | PyTorch-Profiler, NSight Systems, NSight Compute |
| Foundation Model-Training | MaxText, MaxDiffusion | NeMo-Megatron, DeepSpeed, TorchTitan |
| LLM-Inferenz | vLLM | SGLang |
| Inferenz ohne LLM | NSE | Triton Inference Server, RayServe |
5 Einige der Äquivalente hier sind nicht immer echte Vergleiche, da andere Frameworks API-Grenzen anders ziehen als JAX. Die Liste der Äquivalente ist nicht vollständig und es kommen häufig neue Bibliotheken hinzu.
Fazit: Eine robuste, produktionsreife Plattform für die Zukunft der KI
Die Daten in der vorherigen Tabelle veranschaulichen eine selbstverständliche Schlussfolgerung: Diese Stacks haben in einer kleinen Anzahl von Bereichen ihre eigenen Stärken und Schwächen, sind aber insgesamt aus Softwaresicht sehr ähnlich. Beide Stacks bieten schlüsselfertige Lösungen für das Vortraining, die Anpassung nach dem Training und die Bereitstellung von Fundierungsmodellen.
Der JAX-KI-Stack bietet eine überzeugende und robuste Lösung für das Trainieren und Bereitstellen von ML-Modellen in beliebigem Maßstab. Dabei wird eine umfassende vertikale Integration von Software und TPU-Hardware genutzt, um eine erstklassige Leistung und Gesamtbetriebskosten zu erzielen.
Die Entwicklung des Stacks basiert auf bewährten internen Systemen. Er bietet von Natur aus Zuverlässigkeit und Skalierbarkeit, sodass Nutzer auch die größten Modelle bedenkenlos entwickeln und bereitstellen können. Das modulare und zusammensetzbare Design, das auf der Philosophie des JAX-KI-Stacks basiert, bietet Nutzern beispiellose Freiheit und Kontrolle. Sie können den Stack an ihre spezifischen Anforderungen anpassen, ohne die Einschränkungen eines monolithischen Frameworks.
Mit XLA und Pathways als skalierbare und fehlertolerante Basis, JAX als leistungsstarke und ausdrucksstarke numerische Bibliothek, leistungsstarken Kernentwicklungsbibliotheken wie Flax, Optax, Grain und Orbax, erweiterten Leistungstools wie Pallas, Tokamax und Qwix sowie einer robusten Anwendungs- und Produktionsschicht in MaxText, vLLM und NSE bietet der JAX AI-Stack eine solide Grundlage für Nutzer, auf der sie aufbauen und modernste Forschung schnell in die Produktion bringen können.