
使用控制台根據文字內容建立音訊
本快速入門導覽課程介紹 Cloud Text-to-Speech 控制台。在課程中,您將根據文字內容建立音訊,並瞭解如何播放、下載及更新該音訊,供自己的應用程式使用。
如要進一步瞭解 Text-to-Speech 的基本概念,請參閱這篇文章。
事前準備
您必須先在 Google Cloud 控制台啟用 API,才能開始使用 Text-to-Speech 控制台。下方步驟將逐步說明如何執行各個動作:
- 在專案中啟用 Text-to-Speech。
- 確認已啟用 Text-to-Speech 的計費功能。
設定 Google Cloud 專案
-
您可以選擇現有專案或建立新專案。如要進一步瞭解如何建立專案,請參閱 Google Cloud Platform 說明文件。
如果選擇建立新專案,系統會提示您將帳單帳戶連結到該專案;如果選擇使用現有專案,請確認已啟用計費功能。
選取專案並連結到帳單帳戶後,即可啟用 Text-to-Speech API。請前往頁面頂端的「Search products and resources」(搜尋產品和資源) 列,輸入「text-to-speech」。
從結果清單中選取「Cloud Text-to-Speech API」。
如要試用 Text-to-Speech,但不想將這項工具連結到專案,請選擇「TRY THIS API」(試用這個 API) 選項。如要啟用 Text-to-Speech API,以便搭配專案使用,請按一下「ENABLE」(啟用)。
根據文字內容建立音訊
使用 Google Cloud 控制台,根據文字內容建立音訊:
輸入文字或 SSML
開啟「Text-to-Speech Synthesize」(Text-to-Speech 合成) 頁面。
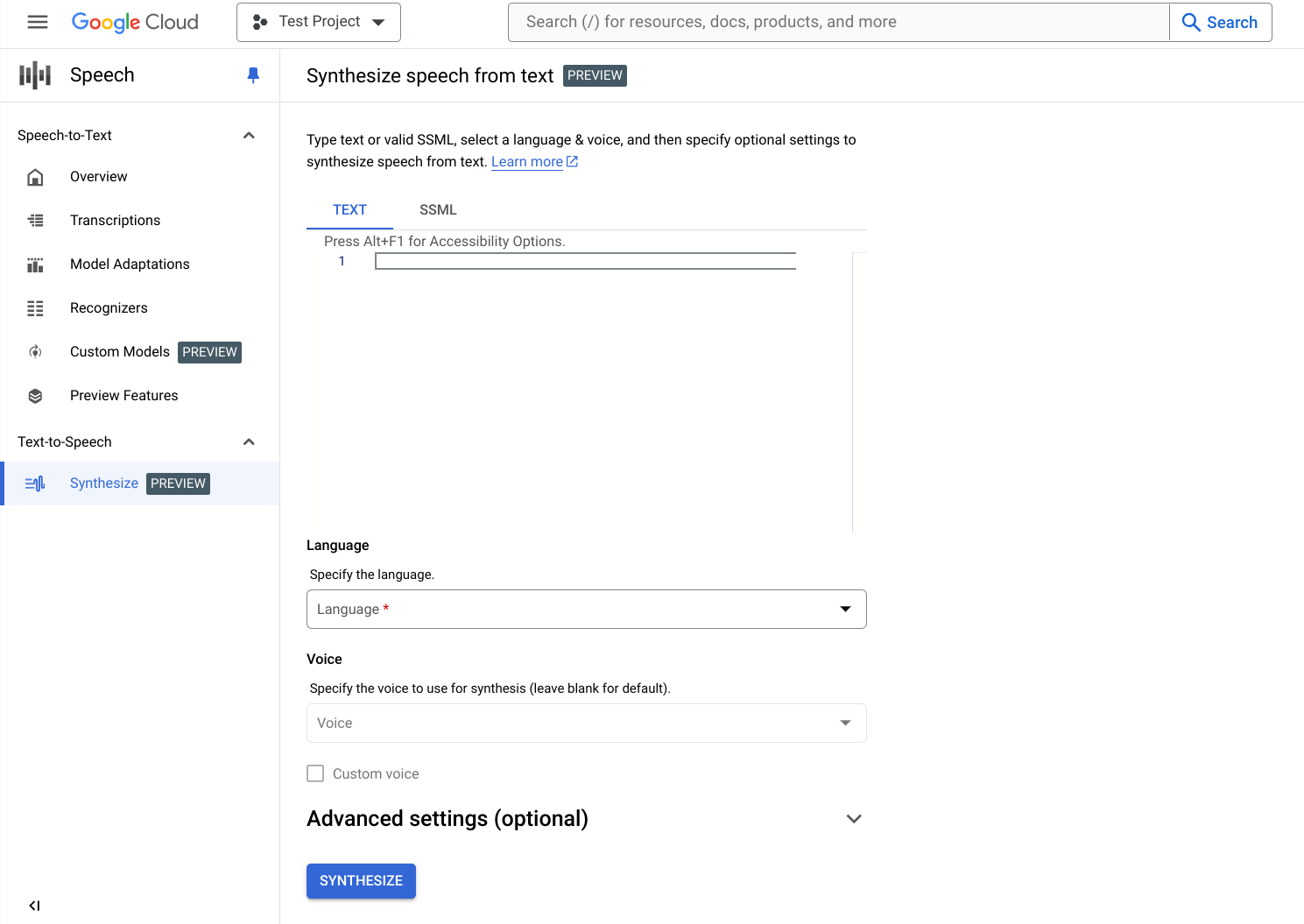
輸入文字或 SSML。您可以合成純文字,也可以使用語音合成標記語言 (SSML),讓音訊回覆有更多彈性調整空間。
選取文字或 SSML 的「language」(語言)。這是合成語音時使用的語言。
選取要用於合成的「voice」(語音)。請注意,語音功能、特徵和費用會有所不同。
進階設定 (選用)
(選用) 展開「Advanced settings」(進階設定) 部分,設定所建立音訊的其他屬性。
指定合成音訊的其他特徵,例如「speed」(速度) 和「pitch」(音調)。
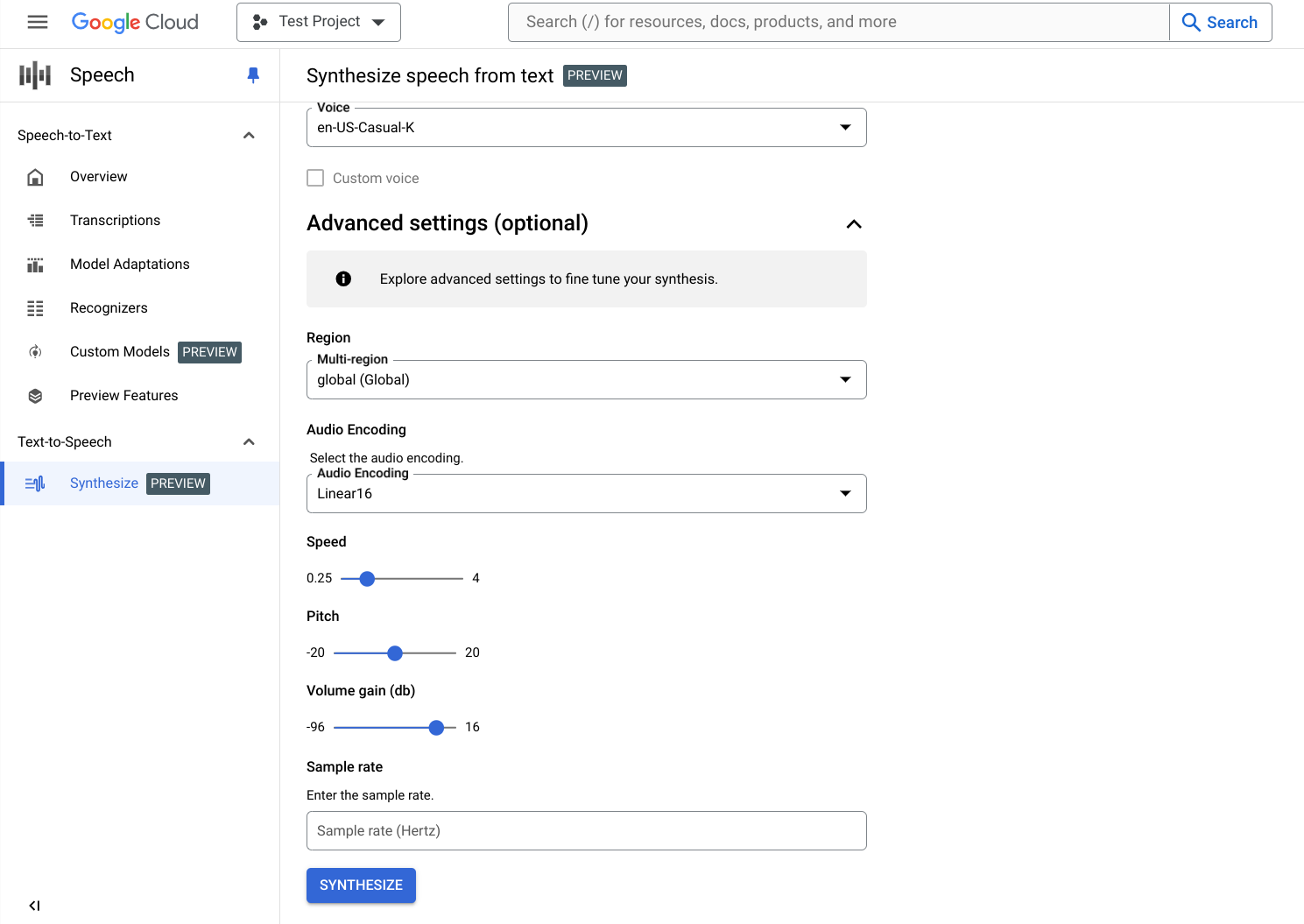
按一下底部的「Synthesize」(合成),即可建立合成音訊。
檢查音訊
視輸入內容而定,合成音訊可能需要幾秒到幾分鐘才能建立完成。您可以在建立完成後檢查音訊。
按一下播放器控制項即可播放音訊。
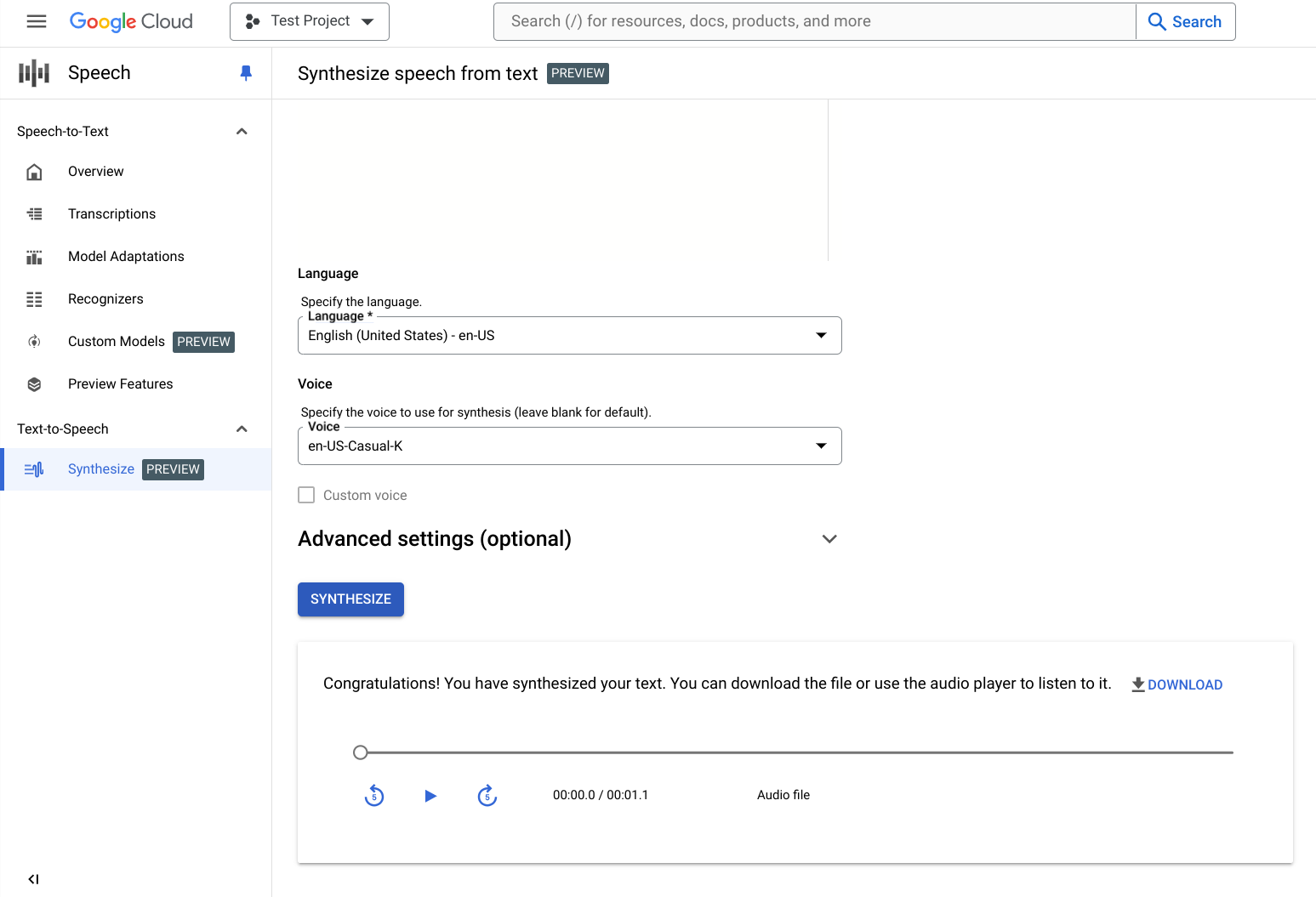
點選「Download」(下載) 即可將音訊檔案下載到本機。
清除所用資源
如要避免不必要的 Google Cloud 費用,請前往 Google Cloud console 刪除不需要的專案。
後續步驟