
בדף הזה מוסבר על תוכנית התאוששות מאסון (DR) ב-Cloud SQL.
סקירה כללית
ב- Google Cloud, שחזור אחרי אסון (DR) של מסד נתונים נועד לספק המשכיות של העיבוד, במיוחד כשאזור נכשל או הופך ללא זמין. Cloud SQL הוא שירות אזורי (כאשר Cloud SQL מוגדר לזמינות גבוהה (HA)). לכן, אם אזור Google Cloud שמארח מסד נתונים של Cloud SQL הופך ללא זמין, גם מסד הנתונים של Cloud SQL הופך ללא זמין.
כדי להמשיך בעיבוד, עליך להפוך את מסד הנתונים לזמין באזור משני בהקדם האפשרי. תוכנית ה-DR מחייבת הגדרה של רפליקה לקריאה בין אזורים ב-Cloud SQL. אפשר גם לבצע מעבר לגיבוי בעקבות כשל על סמך ייצוא/ייבוא או גיבוי/שחזור, אבל הגישה הזו אורכת זמן רב יותר, במיוחד כשמדובר במסדי נתונים גדולים.
התרחישים העסקיים הבאים הם דוגמאות למצבים שבהם כדאי להגדיר תצורת יתירות כשל בין אזורים:
- הסכם רמת השירות של האפליקציה העסקית גבוה יותר מהסכם רמת השירות האזורי של Cloud SQL (זמינות של 99.99% בהתאם למהדורת Cloud SQL). מעבר לאזור אחר יכול לצמצם את ההשפעה של הפסקה זמנית בשירות.
- כל הרמות של אפליקציית העסק כבר מרובות אזורים, והיא יכולה להמשיך לעבד נתונים כשמתרחש הפסקת שירות באזור מסוים. הגדרת מעבר אוטומטי לגיבוי באזור אחר עוזרת לשמור על זמינות רציפה של מסד נתונים.
- יעד משך ההתאוששות (RTO) ויעד נקודת ההתאוששות (RPO) הנדרשים הם בדקות ולא בשעות. מעבר לגיבוי באזור אחר מהיר יותר מיצירה מחדש של מסד נתונים.
באופן כללי, יש שתי גרסאות לתהליך DR:
- מסד נתונים עובר לגיבוי באזור משני. אחרי שמסד הנתונים מוכן ומשמש אפליקציה, הוא הופך למסד הנתונים הראשי החדש ונשאר כזה.
- מסד נתונים עובר לאזור משני, אבל חוזר לאזור הראשי אחרי שהאזור הראשי מתאושש מהכשל.
בסקירה הכללית הזו של התאוששות מאסון (DR) של מסד נתונים של SQL Google Cloud מתואר הווריאנט השני – כשמסד נתונים שנכשל משוחזר וחוזר לאזור הראשי. הגרסה הזו של תהליך DR רלוונטית במיוחד למסדי נתונים שצריכים לפעול באזור הראשי בגלל חביון ברשת, או בגלל שחלק מהמשאבים זמינים רק באזור הראשי. בגרסה הזו, מסד הנתונים פועל באזור המשני רק למשך ההשבתה באזור הראשי.
למסמך הזה של DR משויכים שני מדריכים:- התאוששות מאסון ב-Cloud SQL ל-MySQL: תהליך מלא של מעבר לגיבוי כשל וחזרה לגיבוי הכשל
- התאוששות מאסון ב-Cloud SQL ל-PostgreSQL: תהליך מלא של מעבר לגיבוי נכשל וחזרה לגיבוי
ארכיטקטורה של תוכנית התאוששות מאסון (DR)
התרשים הבא מציג את הארכיטקטורה המינימלית שתומכת ב-DR של מסד נתונים עבור מופע Cloud SQL עם זמינות גבוהה:
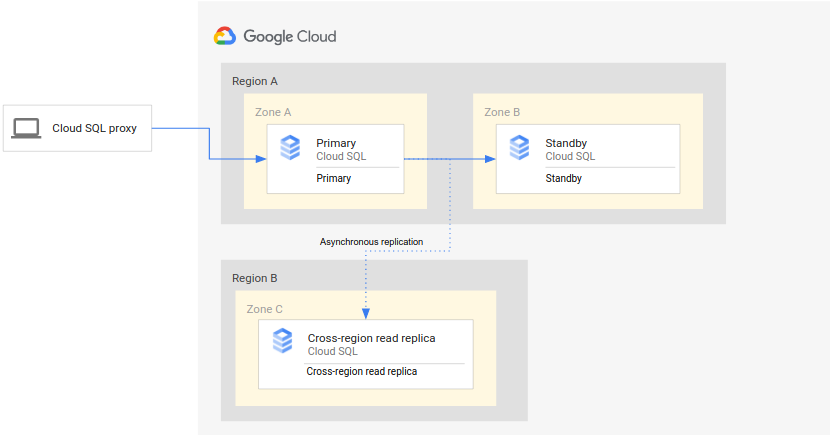
הארכיטקטורה פועלת באופן הבא:
- שני מופעים של Cloud SQL (מופע ראשי ומופע המתנה) ממוקמים בשני אזורים נפרדים באותו אזור (האזור הראשי). המופעים מסונכרנים באמצעות דיסקים לאחסון מתמיד אזוריים.
- מופע אחד של Cloud SQL (הרפליקה לקריאה בין אזורים) נמצא באזור שני (האזור המשני). לצורך DR, העותק לקריאה חוצה-אזורים מוגדר לסנכרון (באמצעות שכפול אסינכרוני) עם המופע הראשי באמצעות הגדרת עותק לקריאה.
למכונות הראשיות ולמכונות ההמתנה יש אותו דיסק אזורי, ולכן המצבים שלהן זהים.
מכיוון שההגדרה הזו משתמשת ברפליקציה אסינכרונית, יכול להיות שהרפליקה לקריאה בין אזורים תהיה מאחורי המופע הראשי. כתוצאה מכך, כשמתרחש מעבר לגיבוי (failover), סביר להניח שערך ה-RPO של העתק לקריאה חוצה אזורים לא יהיה אפס.
תהליך התאוששות מאסון (DR)
תהליך ההתאוששות מאסון (DR) מתחיל כשהאזור הראשי הופך ללא זמין. כדי להמשיך את העיבוד באזור משני, מפעילים יתירות כשל של המופע הראשי על ידי העלאה בדרגה של רפליקה לקריאה בין אזורים. תהליך ה-DR קובע את השלבים התפעוליים שצריך לבצע, באופן ידני או אוטומטי, כדי לצמצם את ההשפעה של הכשל באזור וליצור מופע ראשי פעיל באזור משני.
התרשים הבא מציג את תהליך ה-DR:
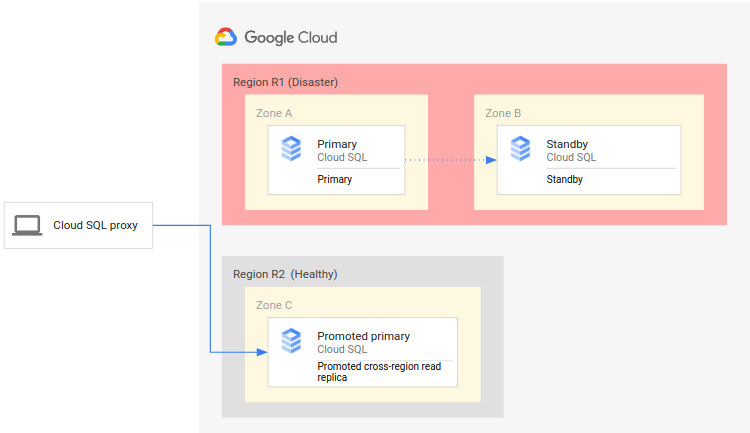
תהליך ה-DR כולל את השלבים הבאים:
- האזור הראשי (R1), שבו פועל המופע הראשי, הופך ללא זמין.
- צוות התפעול מזהה את האסון ומאשר אותו באופן רשמי, ומחליט אם נדרש מעבר לגיבוי.
- אם נדרש מעבר לגיבוי, אפשר להעלות בדרגה את הרפליקה לקריאה חוצה אזורים באזור המשני (R2) כמופע הראשי החדש.
- החיבורים של הלקוחות מוגדרים מחדש כדי להמשיך את העיבוד במופע הראשי החדש ולגשת למופע הראשי ב-R2.
התהליך הראשוני הזה יוצר שוב מסד נתונים ראשי תקין. עם זאת, היא לא יוצרת ארכיטקטורה מלאה של DR, שבה למופע הראשי החדש יש מופע המתנה ועותק לקריאה חוצה אזורים.
תהליך DR מלא מבטיח שהמופע היחיד, המופע הראשי החדש, מופעל ל-HA ויש לו רפליקה לקריאה חוצה אזורים. תהליך מלא של DR מספק גם חזרה לפריסה המקורית באזור הראשי המקורי.
מעבר אוטומטי לאזור משני
תהליך מלא של DR מרחיב את תהליך ה-DR הבסיסי על ידי הוספת שלבים ליצירת ארכיטקטורת DR מלאה אחרי יתירות כשל. בתרשים הבא מוצגת ארכיטקטורת DR מלאה של מסד נתונים אחרי המעבר לגיבוי:
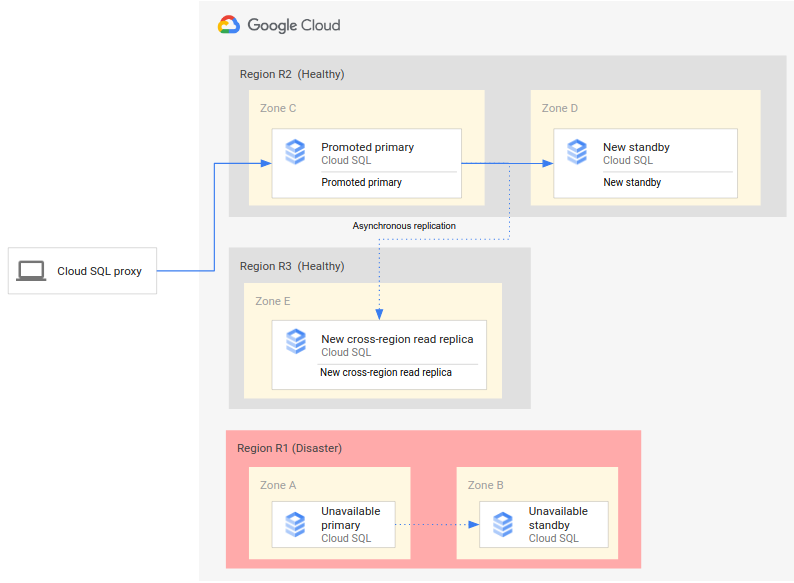
התהליך המלא של DR במסד נתונים כולל את השלבים הבאים:
- האזור הראשי (R1), שבו פועל מסד הנתונים הראשי, הופך ללא זמין.
- צוות התפעול מזהה את האסון ומאשר אותו באופן רשמי, ומחליט אם נדרש מעבר לגיבוי.
- אם נדרש מעבר לגיבוי, אפשר להעלות בדרגה את הרפליקה לקריאה חוצת-אזורים באזור המשני (R2) למופע הראשי החדש.
- החיבורים של הלקוחות מוגדרים מחדש כדי לגשת למופע הראשי החדש (R2) ולעבד בו.
- מופע חדש של מצב המתנה נוצר ומופעל ב-R2 ומתווסף למופע הראשי. מופע הגיבוי נמצא באזור אחר מזה של המופע הראשי. המופע הראשי זמין עכשיו עם זמינות גבוהה כי נוצר עבורו מופע בהמתנה.
- באזור שלישי (R3), נוצרת רפליקה חדשה לקריאה חוצת-אזורים ומצורפת למופע הראשי. בשלב הזה, ארכיטקטורה מלאה של התאוששות מאסון (DR) נוצרת מחדש ומופעלת.
אם האזור הראשי המקורי (R1) יהיה זמין לפני שמיישמים את שלב 6, אפשר יהיה למקם את העותק לקריאה חוצת-אזורים באזור R1 באופן מיידי, במקום באזור R3. במקרה הזה, החזרה לאזור הראשי המקורי (R1) פחות מורכבת ודורשת פחות שלבים.
איך נמנעים ממצב של פיצול מוח
אם יש כשל באזור הראשי (R1), זה לא אומר שהמופע הראשי המקורי ומופע ההמתנה שלו מושבתים אוטומטית, מוסרים או הופכים ללא נגישים כש-R1 חוזר להיות זמין. אם R1 יהיה זמין, יכול להיות שהלקוחות יקראו ויכתבו נתונים (גם בטעות) במופע הראשי המקורי. במקרה כזה, יכול להתפתח מצב של פיצול נתונים, שבו חלק מהלקוחות ניגשים לנתונים לא עדכניים במסד הנתונים הראשי הישן, ולקוחות אחרים ניגשים לנתונים עדכניים במסד הנתונים הראשי החדש, מה שמוביל לבעיות בעסק.
כדי להימנע ממצב של פיצול, צריך לוודא שהלקוחות לא יוכלו יותר לגשת למופע הראשי המקורי אחרי ש-R1 יהיה זמין. מומלץ להפוך את המופע הראשי המקורי ללא נגיש לפני שהלקוחות מתחילים להשתמש במופע הראשי החדש, ואז למחוק את המופע הראשי המקורי מיד אחרי שהופכים אותו ללא נגיש.
יצירת גיבוי ראשוני אחרי מעבר לגיבוי (failover)
כשמקדמים את הרפליקה לקריאה בין אזורים להיות העותק הראשי החדש ביתירות כשל, יכול להיות שהעסקאות בעותק הראשי החדש לא יסונכרנו באופן מלא עם העסקאות מהעותק הראשי המקורי. לכן, העסקאות האלה לא זמינות במופע החדש.
מומלץ לגבות מיד את המופע הראשי החדש בתחילת המעבר לגיבוי, ולפני שהלקוחות ניגשים למסד הנתונים. הגיבוי הזה מייצג מצב עקבי וידוע בנקודת המעבר לגיבוי. גיבויים כאלה יכולים להיות חשובים למטרות רגולטוריות או לשחזור למצב מוכר אם לקוחות נתקלים בבעיות בגישה לשרת הראשי החדש.
חזרה לאזור הראשי המקורי
כמו שצוין קודם, במסמך הזה מפורטים השלבים לחזרה לאזור המקורי (R1). יש שתי גרסאות שונות של תהליך הגיבוי.
- אם יצרתם את העותק החדש לקריאה בין אזורים באזור משני (R3), אתם צריכים ליצור עוד (שני) עותק לקריאה בין אזורים באזור הראשי (R1).
- אם יצרתם את העותק החדש לקריאה בין אזורים באזור הראשי (R1), אתם לא צריכים ליצור עוד עותק לקריאה בין אזורים ב-R1.
אחרי שנוצר העתק לקריאה בין-אזורי באזור R1, מופע Cloud SQL יכול לחזור לאזור R1. מכיוון שהמעבר לגיבוי הזה מופעל באופן ידני ולא מבוסס על הפסקת שירות, אתם יכולים לבחור את היום והשעה המתאימים לפעילות התחזוקה הזו.
לכן, כדי להשיג DR מלא עם רפליקה לקריאה ראשית, רפליקה לקריאה במצב המתנה ורפליקה לקריאה חוצה אזורים, צריך לבצע שני מעברים אוטומטיים לשירות גיבוי. המעבר הראשון לגיבוי מופעל בגלל ההפסקה הזמנית בשירות (מעבר לגיבוי אמיתי), והמעבר השני לגיבוי מחזיר את הפריסה למצב ההתחלתי (חזרה למצב הקודם).
החזרה לאזור הראשי המקורי (R1) כוללת את השלבים הבאים:
- קידום הרפליקה החדשה שנוצרה באזור הראשי המקורי (R1).
- אם המופע שקודם לא נוצר במקור כרפליקה של זמינות גבוהה, צריך להפעיל זמינות גבוהה במופע כדי להגן עליו מפני כשלים אזוריים.
- מגדירים מחדש את האפליקציות כך שיתחברו למופע הראשי החדש.
- יוצרים רפליקה חוצת-אזורים עבור המופע הראשי החדש באזור DR (R2).
- (אופציונלי) כדי להימנע מהפעלת כמה מופעים ראשיים עצמאיים, צריך לנקות את המופע הראשי באזור DR (R2).
תוכנית התאוששות מאסון (DR) מתקדמת
אם אתם משתמשים במהדורת Cloud SQL Enterprise Plus, אתם יכולים ליהנות מ-DR מתקדם. DR מתקדם מפשט את השחזור והחזרה למצב הקודם אחרי מעבר לגיבוי בעת כשל חוצה אזורים. כמו שמתואר בתהליך ההתאוששות מאסון, כשמבצעים DR, מסירים את החיבור בין האזור שנכשל של המופע הראשי הישן לבין האזור התפעולי של המופע הראשי החדש. כדי לשחזר את החיבורים לאזור הפריסה המקורי ולחזור למופע הראשי הישן, צריך לבצע סדרה של שלבי חזרה ידנית.
ב-DR מתקדם, כשמתרחש כשל באזור, אפשר להפעיל יתירות כשל של רפליקה. במעבר ליתירות כשל של רפליקה, מעלים בדרגה רפליקה לקריאה באזור אחר, בדומה לביצוע תוכנית התאוששות מאסון (DR) רגילה, אלא שמעלים בדרגה את הרפליקה המיועדת לתוכנית התאוששות מאסון (DR). הקידום של רפליקת ה-DR הוא מיידי.
במקום להסיר את המופע הראשי הישן, המופע נשאר חלק מטופולוגיית השכפול האסינכרוני של Cloud SQL. בסופו של דבר, המופע הראשי הישן (מופע א') הופך לרפליקה של רפליקת ה-DR שלו (מופע ב'), אחרי שרפליקת ה-DR קודמה למופע הראשי החדש.
אחרי שהמופע הראשי הישן (A) הופך למופע משוכפל, אפשר לבצע את השלב האחרון של התאוששות מתקדמת מאסון. אפשר להחזיר את הפריסה של Cloud SQL למצב המקורי ולשחזר את המופע הראשי הישן (A) לתפקיד הקודם שלו כמופע הראשי ללא אובדן נתונים. כדי לבצע שחזור של המופע הראשי הישן (A) ללא אובדן נתונים, אפשר להשתמש בפעולת ההעברה. כשמבצעים מעבר לגיבוי, לא מתרחש אובדן נתונים כי המופע הראשי (B) נשאר במצב קריאה בלבד עד שהרפליקה המיועדת שלו להתאוששות מאסון (A) מתעדכנת עם המופע הראשי (B). אחרי שרפליקת ה-DR (A) מקבלת את כל עדכוני הרפליקציה, היא מקבלת את התפקיד של המופע הראשי, והמופע הראשי הקודם (B) מוגדר מחדש באופן אוטומטי כרפליקת ה-DR של המופע הראשי הנוכחי (A). המופעים יחזרו לתפקידים המקוריים שלהם, וכך הטופולוגיה תחזור למצב המקורי שלה לפני ה-DR והמעבר ליתירות כשל.
במהלך DR מתקדם, כל המופעים שמשתתפים בפעולות של יתירות כשל (failover) ומעבר חזרה (switchover) של הרפליקה שומרים על כתובות ה-IP שלהם.
אפשר גם להשתמש בפעולת המעבר של התאוששות מתקדמת מאסון כדי לבצע תרגילי DR שגרתיים, במטרה לבדוק ולהכין את הטופולוגיה של Cloud SQL למעבר לגיבוי בעקבות כשל חוצה אזורים לפני שמתרחש אסון. אם מתרחש אסון אמיתי, אפשר לבצע מעבר לגיבוי חם של רפליקה חוצה-אזורים שכבר נבדק.
רפליקת התאוששות מאסון (DR)
כחלק חובה מפתרון מתקדם להתאוששות מאסון, רפליקת ה-DR כוללת את המאפיינים הבאים:
- שכפול DR הוא שכפול לקריאה באזור אחר שמחובר ישירות.
- אפשר לשנות את ייעוד רפליקת ה-DR כמה פעמים.
- אפשר לשנות את ייעוד הרפליקה של DR בכל שלב, למעט במהלך פעולת מעבר או פעולת יתירות כשל של רפליקה.
בנוסף, כדי לצמצם את זמן ההשבתה (RTO) אחרי שימוש ב-DR מתקדם, מומלץ לבצע את הפעולות הבאות:
- מגדירים את הרפליקה של DR באותו גודל כמו המכונה הראשית.
- אם מופעלת זמינות גבוהה במופע הראשי, מומלץ להפעיל זמינות גבוהה גם ברפליקת DR. כדי לעשות זאת, קודם מוודאים שה-HA מופעל בשרת הראשי. לאחר מכן, מבצעים את המעבר לרפליקת DR. אחרי שפעולת המעבר מסתיימת, מפעילים את הזמינות הגבוהה במופע הראשי החדש. אחר כך תוכלו לחזור למופע הראשי הקודם. ההגדרה של הזמינות הגבוהה נשמרת ברפליקה של DR גם אחרי שהיא הופכת שוב לרפליקה.
יתירות כשל של רפליקה
לסיכום, יתירות כשל של רפליקה כוללת את האירועים הבאים:
- יוצרים ומקצים רפליקה של DR.
- האזור הראשי לא זמין.
- מבצעים יתירות כשל של הרפליקה ל-DR.
- נקודת הקצה של הכתיבה מתעדכנת ומתחילה להצביע על המופע הראשי החדש.
- כשהמופע הראשי המקורי חוזר למצב אונליין, הוא הופך לרפליקת קריאה של המופע הראשי החדש.
- אתם יכולים להשתמש בפעולת המעבר כדי לשחזר את הפריסה לטופולוגיה המקורית שלה.
כדי לראות את הפרטים והדיאגרמות של פעולת יתירות כשל של רפליקה, לוחצים על הכרטיסיות הבאות.
הקצאת רפליקת DR
לפני שמבצעים יתירות כשל של רפליקה, צריך להקצות רפליקת DR למופע הראשי, ואולי גם לבדוק את התהליך על ידי ביצוע מעבר.

מתרחשת הפסקה זמנית בשירות
האזור הראשי שבו פועל מסד הנתונים הראשי הופך ללא זמין.

יתירות כשל של רפליקה
אחרי שקובעים שנדרשת תוכנית התאוששות מאסון (DR), מבצעים יתירות כשל של הרפליקה ל-DR שמוגדר באזור אחר.
העתק ה-DR שמוגדר בין אזורים הופך באופן מיידי למופע הראשי ומתחיל לקבל קריאות וכתיבות נכנסות. נקודת הקצה לכתיבה מתעדכנת ומתחילה להצביע על המופע הראשי החדש.

השרת הראשי המקורי הופך לרפליקה
אחרי שהרפליקה קודמה, Cloud SQL בודק מעת לעת אם המופע הראשי המקורי חזר למצב אונליין. אם המכונה הראשית המקורית מחוברת לאינטרנט, Cloud SQL יוצר מחדש את המכונה הראשית הישנה כרפליקה של המכונה שודרגה. כתובת ה-IP של המופע הראשי הישן נשמרת.

חזרה לגרסה המקורית
אחרי שמבצעים יתירות כשל של רפליקה, אפשר לשחזר את המופע הראשי באזור המקורי על ידי ביצוע פעולת המעבר, והיפוך של אותה רפליקה של DR וזוג מופעים ראשיים.

מעבר
לסיכום, פעולת מעבר כוללת את האירועים הבאים:
- יוצרים ומקצים רפליקה של DR.
- אתם מתחילים את תהליך המעבר.
- כשפיגור הרפליקציה יורד לאפס, המופעים הראשיים החדשים מתחילים לקבל חיבורים נכנסים.
- המופע הראשי הישן הופך למופע משוכפל לקריאה בלבד.
- אם נעשה שימוש בנקודת קצה לכתיבת DNS, נקודת הקצה לכתיבת DNS מתעדכנת כך שתפנה למופע הראשי החדש.
כדי לראות את הפרטים והתרשימים של פעולת מעבר, לוחצים על הכרטיסיות הבאות.
הקצאת רפליקת DR
לפני שמתחילים את פעולת ה *העברה* צריך להקצות רפליקה של DR למופע הראשי.
מוודאים שהמופע הראשי תקין. אפשר לבצע מעבר לגיבוי רק אם גם המופע הראשי וגם רפליקת ה-DR מחוברים לאינטרנט.
הפעלת המעבר
אתם מתחילים את המעבר. כשמתחילים בהעברה אוטומטית, המופע הראשי מפסיק לקבל פעולות כתיבה והופך לקריאה בלבד. Cloud SQL מחכה שהעתקה של יומני העסקאות תתבצע אל Cloud Storage. ההעתק המשוכפל שמוגדר ל-DR מתעדכן בהתאם למופע הראשי.
כשהשהיית הרפליקציה יורדת לאפס, העותק המשוכפל של DR מקודם כמופע הראשי החדש. המופע הראשי החדש מתחיל לקבל חיבורים נכנסים, כולל קריאות וכתיבות של אפליקציות.
נקודת הקצה עודכנה
אחרי שמשדרגים את הרפליקה של DR למופע הראשי החדש, נקודת הקצה של כתיבת ה-DNS מתעדכנת ומתחילה להצביע על המופע הראשי החדש. אם אתם לא משתמשים בנקודת קצה לכתיבת DNS, אתם צריכים להגדיר את האפליקציות כך שיפנו לכתובת ה-IP של המופע הראשי החדש.
המופע הראשי הישן מוגדר מחדש כרפליקה לקריאה.
האפשרות PITR מופעלת אוטומטית במופע הראשי החדש. אפשר לבצע PITR רק אחרי הגיבוי האוטומטי הראשון.
נקודת קצה לכתיבה
נקודת קצה לכתיבה היא שם גלובלי של Domain Name Service (DNS) שמקבל באופן אוטומטי את כתובת ה-IP של המופע הראשי הנוכחי. נקודת הקצה הזו מפנה אוטומטית חיבורים נכנסים למופע הראשי החדש במקרה של יתירות כשל או מעבר לגיבוי פעיל של רפליקה. אפשר להשתמש בנקודת הקצה לכתיבה במחרוזת חיבור SQL במקום בכתובת IP. שימוש בנקודת קצה לכתיבה מאפשר לכם להימנע משינויים בחיבור האפליקציה במקרה של הפסקה זמנית בשירות באזור.
כדי להשתמש בנקודת קצה לכתיבה, צריך להפעיל את Cloud DNS API בפרויקט שבו יוצרים את המכונה הראשית של מהדורת Cloud SQL Enterprise Plus או שבו היא קיימת. כשיוצרים מכונה במהדורת Cloud SQL Enterprise Plus עם כתובת IP פרטית ורשתות מורשות, מערכת Cloud SQL יוצרת באופן אוטומטי נקודת קצה (endpoint) לכתיבה עבור המכונה. אם כבר יש לכם מופע ראשי במהדורת Cloud SQL Enterprise Plus, מערכת Cloud SQL תיצור את נקודת הקצה לכתיבה כשתיצרו את העותק המשוכפל לצורך התאוששות מאסון (עותק משוכפל חוצה אזורים שאתם מגדירים למופע הראשי). אם המופע הראשי משתנה בגלל פעולת מעבר או פעולת יתירות כשל של רפליקה, Cloud SQL מקצה את נקודת הקצה של הכתיבה לרפליקת DR כשרפליקת DR הופכת למופע הראשי החדש.
מידע נוסף על שימוש בנקודת קצה לכתיבה כדי להתחבר למופע זמין במאמר בנושא התחברות למופע באמצעות נקודת קצה לכתיבה.
המאמרים הבאים
- שימוש בתכונות מתקדמות של התאוששות מאסון (DR).
- כדאי לעיין במדריך בנושא תוכנית התאוששות מאסון (DR) ב-Cloud SQL ל-MySQL.
- כדאי להעמיק את הקריאה ולהכיר דוגמאות לארכיטקטורות, תרשימים, מדריכים ושיטות מומלצות בנושאי Google Cloud. כל אלה זמינים במרכז הארכיטקטורה של Cloud.