
Seperti yang dijelaskan dalam Rencana eksekusi kueri, compiler SQL mengubah pernyataan SQL menjadi rencana eksekusi kueri, yang digunakan untuk mendapatkan hasil kueri. Halaman ini menjelaskan praktik terbaik untuk menyusun pernyataan SQL guna membantu Spanner menemukan rencana eksekusi yang efisien.
Pernyataan SQL contoh yang ditampilkan di halaman ini menggunakan skema contoh berikut:
GoogleSQL
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY (SingerId);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
ReleaseDate DATE
) PRIMARY KEY (SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
Untuk referensi SQL lengkap, lihat Sintaksis pernyataan, Fungsi dan operator, serta Struktur dan sintaksis leksikal.
PostgreSQL
CREATE TABLE Singers (
SingerId BIGINT PRIMARY KEY,
FirstName VARCHAR(1024),
LastName VARCHAR(1024),
SingerInfo BYTEA,
BirthDate TIMESTAMPTZ
);
CREATE TABLE Albums (
SingerId BIGINT NOT NULL,
AlbumId BIGINT NOT NULL,
AlbumTitle VARCHAR(1024),
ReleaseDate DATE,
PRIMARY KEY(SingerId, AlbumId),
FOREIGN KEY (SingerId) REFERENCES Singers(SingerId)
) INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
Untuk mengetahui informasi selengkapnya, lihat Bahasa PostgreSQL di Spanner.
Menggunakan parameter kueri
Spanner mendukung parameter kueri untuk meningkatkan performa dan membantu mencegah injeksi SQL saat kueri dibuat menggunakan input pengguna. Anda dapat menggunakan parameter kueri sebagai pengganti ekspresi arbitrer, tetapi bukan sebagai pengganti ID, nama kolom, nama tabel, atau bagian lain dari kueri.
Parameter dapat muncul di mana saja nilai literal diharapkan. Nama parameter yang sama dapat digunakan lebih dari sekali dalam satu pernyataan SQL.
Singkatnya, parameter kueri mendukung eksekusi kueri dengan cara berikut:
- Rencana yang telah dioptimalkan: Kueri yang menggunakan parameter dapat dieksekusi lebih cepat pada setiap pemanggilan karena parameterisasi memudahkan Spanner untuk menyimpan rencana eksekusi dalam cache.
- Komposisi kueri yang disederhanakan: Anda tidak perlu melakukan escape pada nilai string saat memberikannya di parameter kueri. Parameter kueri juga mengurangi risiko kesalahan sintaksis.
- Keamanan: Parameter kueri membuat kueri Anda lebih aman dengan melindungi Anda dari berbagai serangan injeksi SQL. Perlindungan ini sangat penting untuk kueri yang Anda buat dari input pengguna.
Memahami cara Spanner menjalankan kueri
Spanner memungkinkan Anda mengkueri database menggunakan pernyataan SQL deklaratif yang menentukan data yang ingin Anda ambil. Jika Anda ingin memahami cara Spanner mendapatkan hasil, periksa rencana eksekusi untuk kueri. Rencana eksekusi kueri menampilkan biaya komputasi yang terkait dengan setiap langkah kueri. Dengan biaya tersebut, Anda dapat men-debug masalah performa kueri dan mengoptimalkan kueri. Untuk mempelajari lebih lanjut, lihat Rencana eksekusi kueri.
Anda dapat mengambil rencana eksekusi kueri melalui konsol Google Cloud atau library klien.
Untuk mendapatkan rencana eksekusi kueri untuk kueri tertentu menggunakan konsolGoogle Cloud , ikuti langkah-langkah berikut:
Buka halaman instance Spanner.
Pilih nama instance Spanner dan database yang ingin Anda kueri.
Klik Spanner Studio di panel navigasi kiri.
Ketik kueri di kolom teks, lalu klik Run query.
Klik Penjelasan
. Konsol Google Cloud menampilkan rencana eksekusi visual untuk kueri Anda.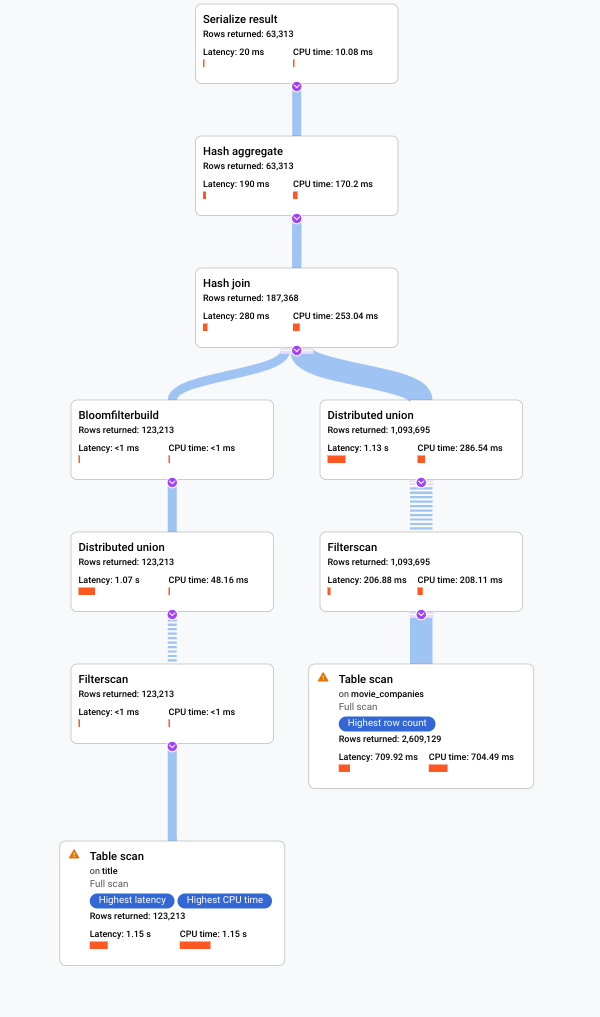
Untuk mengetahui informasi selengkapnya tentang cara memahami rencana visual dan menggunakannya untuk men-debug kueri, lihat Menyesuaikan kueri menggunakan visualisasi rencana kueri.
Anda juga dapat melihat contoh paket kueri historis dan membandingkan performa kueri dari waktu ke waktu untuk kueri tertentu. Untuk mempelajari lebih lanjut, lihat Rencana kueri yang diambil sampelnya.
Menggunakan indeks sekunder
Seperti database relasional lainnya, Spanner menawarkan indeks sekunder, yang dapat Anda gunakan untuk mengambil data menggunakan pernyataan SQL atau antarmuka baca Spanner. Cara yang lebih umum untuk mengambil data dari indeks adalah dengan menggunakan Spanner Studio. Dengan menggunakan indeks sekunder dalam kueri SQL, Anda dapat menentukan cara Spanner mendapatkan hasil. Menentukan indeks sekunder dapat mempercepat eksekusi kueri.
Misalnya, Anda ingin mengambil ID semua penyanyi dengan nama belakang tertentu. Salah satu cara untuk menulis kueri SQL tersebut adalah:
SELECT s.SingerId
FROM Singers AS s
WHERE s.LastName = 'Smith';
Kueri ini akan menampilkan hasil yang Anda harapkan, tetapi mungkin memerlukan waktu yang lama untuk menampilkan hasilnya. Waktunya akan bergantung pada jumlah baris dalam tabel Singers dan jumlah baris yang memenuhi predikat WHERE s.LastName = 'Smith'.
Jika tidak ada indeks sekunder yang berisi kolom LastName untuk dibaca,
rencana kueri akan membaca seluruh tabel Singers untuk menemukan baris yang cocok dengan
predikat. Membaca seluruh tabel disebut pemindaian tabel penuh. Pemindaian tabel lengkap adalah cara yang mahal untuk mendapatkan hasil saat tabel hanya berisi sebagian kecil Singers dengan nama belakang tersebut.
Anda dapat meningkatkan performa kueri ini dengan menentukan indeks sekunder pada kolom nama belakang:
CREATE INDEX SingersByLastName ON Singers (LastName);
Karena indeks sekunder SingersByLastName berisi kolom tabel yang diindeks LastName dan kolom kunci utama SingerId, Spanner dapat mengambil semua data dari tabel indeks yang jauh lebih kecil, bukan memindai tabel Singers lengkap.
Dalam skenario ini, Spanner secara otomatis menggunakan indeks sekunder
SingersByLastName saat menjalankan kueri (selama tiga hari telah berlalu
sejak pembuatan database; lihat Catatan tentang database baru).
Namun, sebaiknya beri tahu Spanner secara eksplisit untuk menggunakan indeks tersebut
dengan menentukan direktif indeks dalam klausa FROM:
GoogleSQL
SELECT s.SingerId
FROM Singers@{FORCE_INDEX=SingersByLastName} AS s
WHERE s.LastName = 'Smith';
PostgreSQL
SELECT s.SingerId
FROM Singers /*@ FORCE_INDEX=SingersByLastName */ AS s
WHERE s.LastName = 'Smith';
Jika Anda menggunakan skema bernama,
gunakan sintaksis berikut untuk klausa FROM:
GoogleSQL
FROM NAMED_SCHEMA_NAME.TABLE_NAME@{FORCE_INDEX="NAMED_SCHEMA_NAME.TABLE_INDEX_NAME"}
PostgreSQL
FROM NAMED_SCHEMA_NAME.TABLE_NAME /*@ FORCE_INDEX = TABLE_INDEX_NAME */
Sekarang, misalkan Anda juga ingin mengambil nama depan penyanyi selain ID. Meskipun kolom FirstName tidak ada dalam indeks, Anda tetap harus menentukan direktif indeks seperti sebelumnya:
GoogleSQL
SELECT s.SingerId, s.FirstName
FROM Singers@{FORCE_INDEX=SingersByLastName} AS s
WHERE s.LastName = 'Smith';
PostgreSQL
SELECT s.SingerId, s.FirstName
FROM Singers /*@ FORCE_INDEX=SingersByLastName */ AS s
WHERE s.LastName = 'Smith';
Anda tetap mendapatkan manfaat performa dari penggunaan indeks karena
Spanner tidak perlu melakukan pemindaian tabel lengkap saat menjalankan
rencana kueri. Sebagai gantinya, kueri ini memilih subset baris yang memenuhi predikat
dari indeks SingersByLastName, lalu melakukan pencarian dari tabel dasar
Singers untuk mengambil nama depan hanya untuk subset baris tersebut.
Jika Anda ingin Spanner tidak perlu mengambil baris apa pun dari tabel dasar, Anda dapat menyimpan salinan kolom FirstName dalam indeks itu sendiri:
GoogleSQL
CREATE INDEX SingersByLastName ON Singers (LastName) STORING (FirstName);
PostgreSQL
CREATE INDEX SingersByLastName ON Singers (LastName) INCLUDE (FirstName);
Menggunakan klausa STORING (untuk dialek GoogleSQL) atau klausa INCLUDE (untuk dialek PostgreSQL) seperti ini akan dikenai biaya penyimpanan tambahan, tetapi
memberikan keuntungan berikut:
- Kueri SQL yang menggunakan indeks dan memilih kolom yang disimpan dalam klausa
STORINGatauINCLUDEtidak memerlukan gabungan tambahan ke tabel dasar. - Panggilan baca yang menggunakan indeks dapat membaca kolom yang disimpan dalam klausa
STORINGatauINCLUDE.
Contoh sebelumnya menggambarkan cara indeks sekunder dapat mempercepat kueri
saat baris yang dipilih oleh klausa WHERE dari kueri dapat diidentifikasi dengan cepat
menggunakan indeks sekunder.
Skenario lain saat indeks sekunder dapat menawarkan manfaat performa adalah untuk kueri tertentu yang menampilkan hasil yang diurutkan. Misalnya, Anda ingin mengambil semua judul album dan tanggal rilisnya dalam urutan menaik tanggal rilis dan urutan menurun judul album. Anda dapat menulis kueri SQL sebagai berikut:
SELECT a.AlbumTitle, a.ReleaseDate
FROM Albums AS a
ORDER BY a.ReleaseDate, a.AlbumTitle DESC;
Tanpa indeks sekunder, kueri ini memerlukan langkah pengurutan yang berpotensi mahal dalam rencana eksekusi. Anda dapat mempercepat eksekusi kueri dengan menentukan indeks sekunder ini:
CREATE INDEX AlbumsByReleaseDateTitleDesc on Albums (ReleaseDate, AlbumTitle DESC);
Kemudian, tulis ulang kueri untuk menggunakan indeks sekunder:
GoogleSQL
SELECT a.AlbumTitle, a.ReleaseDate
FROM Albums@{FORCE_INDEX=AlbumsByReleaseDateTitleDesc} AS a
ORDER BY a.ReleaseDate, a.AlbumTitle DESC;
PostgreSQL
SELECT a.AlbumTitle, a.ReleaseDate
FROM Albums /*@ FORCE_INDEX=AlbumsByReleaseDateTitleDesc */ AS s
ORDER BY a.ReleaseDate, a.AlbumTitle DESC;
Kueri dan definisi indeks ini memenuhi kedua kriteria berikut:
- Untuk menghapus langkah pengurutan, pastikan daftar kolom dalam klausa
ORDER BYadalah awalan dari daftar kunci indeks. - Untuk menghindari penggabungan kembali dari tabel dasar guna mengambil kolom yang tidak ada, pastikan indeks mencakup semua kolom dalam tabel yang digunakan kueri.
Meskipun indeks sekunder dapat mempercepat kueri umum, penambahan indeks sekunder dapat menambah latensi pada operasi commit Anda, karena setiap indeks sekunder biasanya memerlukan keterlibatan node tambahan dalam setiap commit. Untuk sebagian besar workload, memiliki beberapa indeks sekunder tidak masalah. Namun, Anda harus mempertimbangkan apakah Anda lebih mementingkan latensi baca atau tulis, dan mempertimbangkan operasi mana yang paling penting untuk workload Anda. Lakukan tolok ukur beban kerja Anda untuk memastikan beban kerja tersebut berfungsi seperti yang Anda harapkan.
Untuk referensi lengkap tentang indeks sekunder, lihat Indeks sekunder.
Mengoptimalkan pemindaian
Kueri Spanner tertentu mungkin diuntungkan dengan menggunakan metode pemrosesan berorientasi batch saat memindai data, bukan metode pemrosesan berorientasi baris yang lebih umum. Memproses pemindaian dalam batch adalah cara yang lebih efisien untuk memproses data dalam jumlah besar sekaligus, dan memungkinkan kueri mencapai latensi dan pemanfaatan CPU yang lebih rendah.
Operasi pemindaian Spanner selalu memulai eksekusi dalam metode berorientasi baris. Selama waktu ini, Spanner mengumpulkan beberapa metrik runtime. Kemudian, Spanner menerapkan serangkaian heuristik berdasarkan hasil metrik ini untuk menentukan metode pemindaian yang optimal. Jika sesuai, Spanner beralih ke metode pemrosesan berorientasi batch untuk membantu meningkatkan throughput dan performa pemindaian.
Kasus penggunaan umum
Kueri dengan karakteristik berikut umumnya diuntungkan dari penggunaan pemrosesan berorientasi batch:
- Pemindaian besar pada data yang jarang diperbarui.
- Pemindaian dengan predikat pada kolom lebar tetap.
- Pemindaian dengan jumlah pencarian yang besar. (Pencarian menggunakan indeks untuk mengambil record.)
Kasus penggunaan tanpa peningkatan performa
Tidak semua kueri mendapatkan manfaat dari pemrosesan berorientasi batch. Jenis kueri berikut berperforma lebih baik dengan pemrosesan pemindaian berorientasi baris:
- Kueri penelusuran titik: kueri yang hanya mengambil satu baris.
- Kueri pemindaian kecil: pemindaian tabel yang hanya memindai beberapa baris kecuali jika memiliki jumlah pencarian yang besar.
- Kueri yang menggunakan
LIMIT. - Kueri yang membaca data churn tinggi: kueri yang lebih dari ~10% data yang dibaca sering diperbarui.
- Kueri dengan baris yang berisi nilai besar: baris nilai besar adalah baris yang berisi nilai lebih besar dari 32.000 byte (sebelum kompresi) dalam satu kolom.
Memeriksa metode pemindaian yang digunakan oleh kueri
Untuk memeriksa apakah kueri Anda menggunakan pemrosesan berorientasi batch, pemrosesan berorientasi baris, atau otomatis beralih di antara dua metode pemindaian:
Buka halaman Instances Spanner di konsolGoogle Cloud .
Klik nama instance dengan kueri yang ingin Anda selidiki.
Di bagian tabel Database, klik database dengan kueri yang ingin Anda selidiki.
Di Navigation menu, klik Spanner Studio.
Buka tab baru dengan mengklik New SQL editor tab atau New tab.
Saat editor kueri muncul, tulis kueri Anda.
Klik Run.
Spanner menjalankan kueri dan menampilkan hasilnya.
Klik tab Penjelasan di bawah editor kueri.
Spanner menampilkan visualizer rencana eksekusi kueri. Setiap kartu pada grafik mewakili iterator.
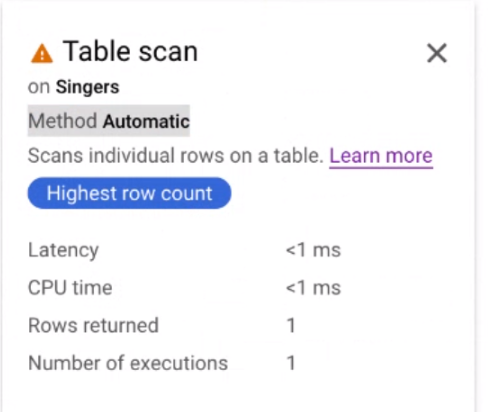
Klik kartu iterator Pemindaian tabel untuk membuka panel informasi.
Panel informasi menampilkan informasi kontekstual tentang pemindaian yang dipilih. Metode pemindaian ditampilkan di kartu ini. Otomatis menunjukkan bahwa Spanner menentukan metode pemindaian. Nilai lain yang mungkin mencakup Batch untuk pemrosesan berorientasi batch dan Baris untuk pemrosesan berorientasi baris.
Menerapkan metode pemindaian yang digunakan oleh kueri
Untuk mengoptimalkan performa kueri, Spanner memilih metode pemindaian yang optimal untuk kueri Anda. Sebaiknya gunakan metode pemindaian default ini. Namun, mungkin ada skenario saat Anda ingin menerapkan jenis metode pemindaian tertentu.
Menerapkan pemindaian berorientasi batch
Anda dapat menerapkan pemindaian berorientasi batch di tingkat tabel dan tingkat pernyataan.
Untuk menerapkan metode pemindaian berorientasi batch di tingkat tabel, gunakan petunjuk tabel dalam kueri Anda:
GoogleSQL
SELECT ...
FROM (t1@{SCAN_METHOD=BATCH} JOIN t2 ON ...)
WHERE ...
PostgreSQL
SELECT ...
FROM (t1/*@ scan_method=batch */ JOIN t2 on ...)
WHERE ...
Untuk menerapkan metode pemindaian berorientasi batch di tingkat pernyataan, gunakan petunjuk pernyataan dalam kueri Anda:
GoogleSQL
@{SCAN_METHOD=BATCH}
SELECT ...
FROM ...
WHERE ...
PostgreSQL
/*@ scan_method=batch */
SELECT ...
FROM ...
WHERE ...
Menonaktifkan pemindaian otomatis dan menerapkan pemindaian berorientasi baris
Meskipun kami tidak merekomendasikan penonaktifan metode pemindaian otomatis yang ditetapkan oleh Spanner, Anda dapat menonaktifkannya dan menggunakan metode pemindaian berorientasi baris untuk tujuan pemecahan masalah, seperti mendiagnosis latensi.
Untuk menonaktifkan metode pemindaian otomatis dan menerapkan pemrosesan baris di tingkat tabel, gunakan petunjuk tabel dalam kueri Anda:
GoogleSQL
SELECT ...
FROM (t1@{SCAN_METHOD=ROW} JOIN t2 ON ...)
WHERE ...
PostgreSQL
SELECT ...
FROM (t1/*@ scan_method=row */ JOIN t2 on ...)
WHERE ...
Untuk menonaktifkan metode pemindaian otomatis dan menerapkan pemrosesan baris di tingkat pernyataan, gunakan petunjuk pernyataan dalam kueri Anda:
GoogleSQL
@{SCAN_METHOD=ROW}
SELECT ...
FROM ...
WHERE ...
PostgreSQL
/*@ scan_method=row */
SELECT ...
FROM ...
WHERE ...
Mengoptimalkan eksekusi kueri
Selain mengoptimalkan pemindaian, Anda juga dapat mengoptimalkan eksekusi kueri dengan menerapkan metode eksekusi di tingkat pernyataan. Hal ini hanya berfungsi untuk beberapa operator, dan tidak bergantung pada metode pemindaian, yang hanya digunakan oleh operator pemindaian.
Secara default, sebagian besar operator dijalankan dengan metode berorientasi baris, yang memproses data satu baris dalam satu waktu. Operator yang di-vektorisasi dieksekusi dalam metode berorientasi batch untuk membantu meningkatkan throughput dan performa eksekusi. Operator ini memproses data satu blok dalam satu waktu. Jika operator perlu memproses banyak baris, metode eksekusi berorientasi batch biasanya lebih efisien.
Metode eksekusi versus metode pemindaian
Metode eksekusi kueri tidak bergantung pada metode pemindaian kueri. Anda dapat menetapkan salah satu, kedua, atau tidak satu pun dari metode ini dalam petunjuk kueri.
Metode eksekusi kueri mengacu pada cara operator kueri memproses hasil sementara dan cara operator berinteraksi satu sama lain, sedangkan metode pemindaian mengacu pada cara operator pemindaian berinteraksi dengan lapisan penyimpanan Spanner.
Menerapkan metode eksekusi yang digunakan oleh kueri
Untuk mengoptimalkan performa kueri, Spanner memilih metode eksekusi yang optimal untuk kueri Anda berdasarkan berbagai heuristik. Sebaiknya Anda menggunakan metode eksekusi default ini. Namun, mungkin ada skenario saat Anda ingin menerapkan jenis metode eksekusi tertentu.
Anda dapat menerapkan metode eksekusi di tingkat pernyataan. EXECUTION_METHOD adalah petunjuk kueri, bukan perintah. Pada akhirnya, pengoptimal kueri memutuskan metode yang akan digunakan untuk setiap operator.
Untuk menerapkan metode eksekusi berorientasi batch di tingkat pernyataan, gunakan hint pernyataan dalam kueri Anda:
GoogleSQL
@{EXECUTION_METHOD=BATCH}
SELECT ...
FROM ...
WHERE ...
PostgreSQL
/*@ execution_method=batch */
SELECT ...
FROM ...
WHERE ...
Meskipun kami tidak menyarankan untuk menonaktifkan metode eksekusi otomatis yang ditetapkan oleh Spanner, Anda dapat menonaktifkannya dan menggunakan metode eksekusi berorientasi baris untuk tujuan pemecahan masalah, seperti mendiagnosis latensi.
Untuk menonaktifkan metode eksekusi otomatis dan menerapkan metode eksekusi berorientasi baris di tingkat pernyataan, gunakan petunjuk pernyataan dalam kueri Anda:
GoogleSQL
@{EXECUTION_METHOD=ROW}
SELECT ...
FROM ...
WHERE ...
PostgreSQL
/*@ execution_method=row */
SELECT ...
FROM ...
WHERE ...
Memeriksa metode eksekusi yang diaktifkan
Tidak semua operator Spanner mendukung metode eksekusi berorientasi batch dan berorientasi baris. Untuk setiap operator, visualizer paket eksekusi kueri menampilkan metode eksekusi di kartu iterator. Jika metode eksekusi berorientasi batch, metode ini akan menampilkan Batch. Jika berorientasi baris, Baris akan ditampilkan.
Jika operator dalam kueri Anda dieksekusi menggunakan metode eksekusi yang berbeda, maka adaptor metode eksekusi DataBlockToRowAdapter dan RowToDataBlockAdapter akan muncul di antara operator untuk menunjukkan perubahan metode eksekusi.
Mengoptimalkan pencarian kunci rentang
Penggunaan umum kueri SQL adalah untuk membaca beberapa baris dari Spanner berdasarkan daftar kunci yang diketahui.
Praktik terbaik berikut membantu Anda menulis kueri yang efisien saat mengambil data berdasarkan rentang kunci:
Jika daftar kunci jarang dan tidak berdekatan, gunakan parameter kueri dan
UNNESTuntuk membuat kueri.Misalnya, jika daftar kunci Anda adalah
{1, 5, 1000}, tulis kueri seperti ini:GoogleSQL
SELECT * FROM Table AS t WHERE t.Key IN UNNEST (@KeyList)
PostgreSQL
SELECT * FROM Table AS t WHERE t.Key IN UNNEST ($1)
Catatan:
Operator UNNEST array meratakan array input menjadi baris elemen.
Parameter kueri, yaitu
@KeyListuntuk GoogleSQL dan$1untuk PostgreSQL, dapat mempercepat kueri Anda seperti yang dibahas dalam praktik terbaik sebelumnya.
Jika daftar kunci berdekatan dan berada dalam rentang, tentukan batas bawah dan atas rentang kunci dalam klausa
WHERE.Misalnya, jika daftar kunci Anda adalah
{1,2,3,4,5}, buat kueri sebagai berikut:GoogleSQL
SELECT * FROM Table AS t WHERE t.Key BETWEEN @min AND @max
PostgreSQL
SELECT * FROM Table AS t WHERE t.Key BETWEEN $1 AND $2
Kueri ini hanya lebih efisien jika kunci dalam rentang kunci berdekatan. Dengan kata lain, jika daftar kunci Anda adalah
{1, 5, 1000}, jangan tentukan batas bawah dan atas seperti dalam kueri sebelumnya karena kueri yang dihasilkan akan memindai setiap nilai antara 1 dan 1000.
Mengoptimalkan penggabungan
Operasi gabungan bisa mahal karena dapat meningkatkan jumlah baris yang perlu dipindai kueri Anda secara signifikan, sehingga menghasilkan kueri yang lebih lambat. Selain teknik yang biasa Anda gunakan di database relasional lain untuk mengoptimalkan kueri gabungan, berikut beberapa praktik terbaik untuk JOIN yang lebih efisien saat menggunakan Spanner SQL:
Jika memungkinkan, gabungkan data dalam tabel yang diselingi berdasarkan kunci utama. Contoh:
SELECT s.FirstName, a.ReleaseDate FROM Singers AS s JOIN Albums AS a ON s.SingerId = a.SingerId;
Baris dalam tabel yang disisipkan
Albumsdijamin disimpan secara fisik dalam pemisahan yang sama dengan baris induk diSingers, seperti yang dibahas dalam Skema dan Model Data. Oleh karena itu, penggabungan dapat diselesaikan secara lokal tanpa mengirim banyak data melalui jaringan.Gunakan direktif gabungan jika Anda ingin memaksa urutan gabungan. Misalnya:
GoogleSQL
SELECT * FROM Singers AS s JOIN@{FORCE_JOIN_ORDER=TRUE} Albums AS a ON s.SingerId = a.Singerid WHERE s.LastName LIKE '%x%' AND a.AlbumTitle LIKE '%love%';
PostgreSQL
SELECT * FROM Singers AS s JOIN/*@ FORCE_JOIN_ORDER=TRUE */ Albums AS a ON s.SingerId = a.Singerid WHERE s.LastName LIKE '%x%' AND a.AlbumTitle LIKE '%love%';
Arahan gabungan
FORCE_JOIN_ORDERmemberi tahu Spanner untuk menggunakan urutan gabungan yang ditentukan dalam kueri (yaitu,Singers JOIN Albums, bukanAlbums JOIN Singers). Hasil yang ditampilkan sama, terlepas dari urutan yang dipilih Spanner. Namun, Anda mungkin ingin menggunakan direktif gabungan ini jika Anda melihat dalam rencana kueri bahwa Spanner telah mengubah urutan gabungan dan menyebabkan konsekuensi yang tidak diinginkan, seperti hasil perantara yang lebih besar, atau telah melewatkan peluang untuk mencari baris.Gunakan direktif gabungan untuk memilih penerapan gabungan. Saat Anda menggunakan SQL untuk membuat kueri beberapa tabel, Spanner secara otomatis menggunakan metode penggabungan yang cenderung membuat kueri lebih efisien. Namun, Google menyarankan Anda untuk melakukan pengujian dengan algoritma penggabungan yang berbeda. Memilih algoritma penggabungan yang tepat dapat meningkatkan latensi, penggunaan memori, atau keduanya. Kueri ini menunjukkan sintaksis untuk menggunakan petunjuk JOIN dengan petunjuk
JOIN_METHODuntuk memilihHASH JOIN:GoogleSQL
SELECT * FROM Singers s JOIN@{JOIN_METHOD=HASH_JOIN} Albums AS a ON a.SingerId = a.SingerId
PostgreSQL
SELECT * FROM Singers s JOIN/*@ JOIN_METHOD=HASH_JOIN */ Albums AS a ON a.SingerId = a.SingerId
Jika Anda menggunakan
HASH JOINatauAPPLY JOINdan memiliki klausaWHEREyang sangat selektif di satu sisiJOIN, letakkan tabel yang menghasilkan jumlah baris terkecil sebagai tabel pertama dalam klausaFROMgabungan. Struktur ini membantu karena diHASH JOIN, Spanner selalu memilih tabel di sisi kiri sebagai build dan tabel di sisi kanan sebagai probe. Demikian pula, untukAPPLY JOIN, Spanner memilih tabel sisi kiri sebagai luar dan tabel sisi kanan sebagai dalam. Lihat informasi selengkapnya tentang jenis gabungan ini: Gabungan hash dan Terapkan gabungan.Untuk kueri yang penting bagi workload Anda, tentukan metode gabungan dan urutan gabungan yang paling berperforma dalam pernyataan SQL Anda untuk performa yang lebih konsisten.
Mengoptimalkan kueri dengan pushdown predikat stempel waktu
Pushdown predikat stempel waktu adalah teknik pengoptimalan kueri yang digunakan di Spanner untuk meningkatkan efisiensi kueri yang menggunakan stempel waktu dan data dengan kebijakan penyimpanan bertingkat berbasis usia. Saat Anda mengaktifkan pengoptimalan ini, operasi pemfilteran pada kolom stempel waktu dilakukan sedini mungkin dalam rencana eksekusi kueri. Hal ini dapat mengurangi jumlah data yang diproses secara signifikan dan meningkatkan performa kueri secara keseluruhan.
Dengan pushdown predikat stempel waktu, mesin database menganalisis kueri dan mengidentifikasi filter stempel waktu. Kemudian, filter ini "didorong ke bawah" ke lapisan penyimpanan, sehingga hanya data yang relevan berdasarkan kriteria stempel waktu yang dibaca dari SSD. Hal ini meminimalkan jumlah data yang diproses dan ditransfer, sehingga menghasilkan eksekusi kueri yang lebih cepat.
Untuk mengoptimalkan kueri agar hanya mengakses data yang disimpan di SSD, hal berikut harus berlaku:
- Kueri harus mengaktifkan bentang bawah predikat stempel waktu. Untuk mengetahui informasi selengkapnya, lihat Petunjuk pernyataan GoogleSQL dan Petunjuk pernyataan PostgreSQL
Kueri harus menggunakan pembatasan berbasis usia yang sama dengan atau kurang dari usia yang ditentukan dalam kebijakan tumpahan data (ditetapkan dengan opsi
ssd_to_hdd_spill_timespandalam pernyataan DDLCREATE LOCALITY GROUPatauALTER LOCALITY GROUP). Untuk mengetahui informasi selengkapnya, lihat pernyataanLOCALITY GROUPGoogleSQL dan pernyataanLOCALITY GROUPPostgreSQL.Kolom yang difilter dalam kueri harus berupa kolom stempel waktu yang berisi stempel waktu commit. Untuk mengetahui detail tentang cara membuat kolom stempel waktu commit, lihat Stempel waktu commit di GoogleSQL dan Stempel waktu commit di PostgreSQL. Kolom ini harus diperbarui bersama dengan kolom stempel waktu, dan berada dalam grup lokalitas yang sama, yang memiliki kebijakan penyimpanan bertingkat berbasis usia.
Jika, untuk baris tertentu, beberapa kolom yang dikueri berada di SSD dan beberapa kolom berada di HDD (karena kolom diperbarui pada waktu yang berbeda dan menjadi HDD pada waktu yang berbeda), maka performa kueri mungkin lebih buruk saat Anda menggunakan petunjuk. Hal ini karena kueri harus mengisi data dari berbagai lapisan penyimpanan. Akibat penggunaan petunjuk, Spanner akan mengelola data di tingkat sel individual (tingkat perincian baris dan kolom) berdasarkan stempel waktu commit setiap sel, sehingga memperlambat kueri. Untuk mencegah masalah ini, pastikan untuk memperbarui semua kolom yang dikueri secara rutin menggunakan teknik pengoptimalan ini dalam transaksi yang sama sehingga semua kolom memiliki stempel waktu penerapan yang sama dan mendapatkan manfaat dari pengoptimalan.
Untuk mengaktifkan pushdown predikat stempel waktu di tingkat pernyataan, gunakan petunjuk pernyataan dalam kueri Anda. Contoh:
GoogleSQL
@{allow_timestamp_predicate_pushdown=TRUE}
SELECT s.SingerInfo
FROM Singers s
WHERE s.ModificationTime > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 12 HOUR);
PostgreSQL
/*@allow_timestamp_predicate_pushdown=TRUE*/
SELECT s.SingerInfo
FROM Singers s
WHERE s.ModificationTime > CURRENT_TIMESTAMP - INTERVAL '12 hours';
Menghindari pembacaan besar di dalam transaksi baca-tulis
Transaksi baca-tulis memungkinkan urutan nol atau lebih pembacaan atau kueri SQL, dan dapat mencakup serangkaian mutasi, sebelum panggilan ke commit. Untuk menjaga konsistensi data Anda, Spanner mendapatkan kunci saat membaca dan menulis baris dalam tabel dan indeks Anda. Untuk mengetahui informasi selengkapnya tentang penguncian, lihat Masa Aktif Operasi Baca dan Tulis.
Karena cara kerja penguncian di Spanner, melakukan pembacaan atau kueri SQL yang membaca sejumlah besar baris (misalnya SELECT * FROM
Singers) berarti tidak ada transaksi lain yang dapat menulis ke baris yang telah Anda baca hingga transaksi Anda di-commit atau dibatalkan.
Selain itu, karena transaksi Anda memproses sejumlah besar baris, kemungkinan akan memerlukan waktu lebih lama daripada transaksi yang membaca rentang baris yang jauh lebih kecil (misalnya SELECT LastName FROM Singers WHERE SingerId = 7), yang semakin memperburuk masalah dan mengurangi throughput sistem.
Jadi, coba hindari pembacaan dalam jumlah besar (misalnya, pemindaian seluruh tabel atau operasi gabungan besar) dalam transaksi Anda, kecuali jika Anda bersedia menerima throughput penulisan yang lebih rendah.
Dalam beberapa kasus, pola berikut dapat memberikan hasil yang lebih baik:
- Lakukan pembacaan besar Anda di dalam transaksi hanya baca. Transaksi hanya baca memungkinkan throughput agregat yang lebih tinggi karena tidak menggunakan kunci.
- Opsional: Lakukan pemrosesan yang diperlukan pada data yang baru saja Anda baca.
- Mulai transaksi baca-tulis.
- Pastikan baris penting tidak berubah nilainya sejak Anda melakukan transaksi hanya baca di langkah 1.
- Jika baris telah berubah, batalkan transaksi Anda dan mulai lagi di langkah 1.
- Jika semuanya sudah beres, lakukan mutasi.
Salah satu cara untuk memastikan bahwa Anda menghindari pembacaan besar dalam transaksi baca-tulis adalah dengan melihat paket eksekusi yang dihasilkan kueri Anda.
Menggunakan ORDER BY untuk memastikan pengurutan hasil SQL Anda
Jika Anda mengharapkan urutan tertentu untuk hasil kueri SELECT, sertakan klausa ORDER BY secara eksplisit. Misalnya, jika Anda ingin mencantumkan semua
penyanyi dalam urutan kunci utama, gunakan kueri ini:
SELECT * FROM Singers
ORDER BY SingerId;
Spanner menjamin pengurutan hasil hanya jika klausa ORDER BY
ada dalam kueri. Dengan kata lain, pertimbangkan kueri ini tanpa ORDER
BY:
SELECT * FROM Singers;
Spanner tidak menjamin bahwa hasil kueri ini akan
berada dalam urutan kunci utama. Selain itu, urutan hasil dapat berubah kapan saja dan tidak dijamin konsisten dari pemanggilan ke pemanggilan. Jika kueri memiliki klausa ORDER BY, dan Spanner menggunakan indeks yang memberikan urutan yang diperlukan, maka Spanner tidak secara eksplisit mengurutkan data. Oleh karena itu, jangan khawatir tentang dampak performa dari penyertaan klausul ini. Anda dapat memeriksa apakah operasi pengurutan eksplisit disertakan dalam
eksekusi dengan melihat rencana kueri.
Gunakan STARTS_WITH, bukan LIKE
Karena Spanner tidak mengevaluasi pola LIKE yang diberi parameter
hingga waktu eksekusi, Spanner harus membaca semua baris dan mengevaluasinya
terhadap ekspresi LIKE untuk memfilter baris yang tidak cocok.
Jika pola LIKE memiliki bentuk foo% (misalnya, dimulai dengan string tetap dan diakhiri dengan satu persen wildcard) dan kolom diindeks, gunakan STARTS_WITH, bukan LIKE. Opsi ini memungkinkan Spanner mengoptimalkan rencana eksekusi kueri secara lebih efektif.
Tidak direkomendasikan:
GoogleSQL
SELECT a.AlbumTitle FROM Albums a WHERE a.AlbumTitle LIKE @like_clause;
PostgreSQL
SELECT a.AlbumTitle FROM Albums a WHERE a.AlbumTitle LIKE $1;
Direkomendasikan:
GoogleSQL
SELECT a.AlbumTitle FROM Albums a WHERE STARTS_WITH(a.AlbumTitle, @prefix);
PostgreSQL
SELECT a.AlbumTitle FROM Albums a WHERE STARTS_WITH(a.AlbumTitle, $2);
Menggunakan stempel waktu commit
Jika aplikasi Anda perlu membuat kueri data yang ditulis setelah waktu tertentu, tambahkan kolom stempel waktu penerapan ke tabel yang relevan. Stempel waktu penerapan memungkinkan pengoptimalan Spanner yang dapat mengurangi I/O kueri yang klausul WHERE-nya membatasi hasil ke baris yang ditulis lebih baru daripada waktu tertentu.
Pelajari lebih lanjut pengoptimalan ini dengan database dialek GoogleSQL atau dengan database dialek PostgreSQL.