
כפי שמתואר במאמר תוכניות להרצת שאילתות, קומפיילר SQL הופך הצהרת SQL לתוכנית להרצת שאילתות, שמשמשת להשגת תוצאות השאילתה. בדף הזה מתוארות שיטות מומלצות ליצירת הצהרות SQL שיעזרו ל-Spanner למצוא תוכניות ביצוע יעילות.
הצהרות ה-SQL לדוגמה שמוצגות בדף הזה משתמשות בסכימה לדוגמה הבאה:
GoogleSQL
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY (SingerId);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
ReleaseDate DATE
) PRIMARY KEY (SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
לעיון בהפניה המלאה ל-SQL, אפשר לעבור אל תחביר של הצהרות, פונקציות ואופרטורים ומבנה לקסיקלי ותחביר.
PostgreSQL
CREATE TABLE Singers (
SingerId BIGINT PRIMARY KEY,
FirstName VARCHAR(1024),
LastName VARCHAR(1024),
SingerInfo BYTEA,
BirthDate TIMESTAMPTZ
);
CREATE TABLE Albums (
SingerId BIGINT NOT NULL,
AlbumId BIGINT NOT NULL,
AlbumTitle VARCHAR(1024),
ReleaseDate DATE,
PRIMARY KEY(SingerId, AlbumId),
FOREIGN KEY (SingerId) REFERENCES Singers(SingerId)
) INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
מידע נוסף זמין במאמר בנושא שפת PostgreSQL ב-Spanner.
שימוש בפרמטרים של שאילתה
Spanner תומך בפרמטרים של שאילתות כדי לשפר את הביצועים ולעזור למנוע הזרקת SQL כששאילתות נוצרות באמצעות קלט של משתמשים. אפשר להשתמש בפרמטרים של שאילתות כתחליפים לביטויים שרירותיים, אבל לא כתחליפים למזהים, לשמות של עמודות או טבלאות או לחלקים אחרים של השאילתה.
פרמטרים יכולים להופיע בכל מקום שבו צפוי ערך מילולי. אפשר להשתמש באותו שם פרמטר יותר מפעם אחת בהצהרת SQL אחת.
לסיכום, פרמטרים של שאילתות תומכים בהרצת שאילתות בדרכים הבאות:
- תוכניות שעברו אופטימיזציה מראש: אפשר להריץ שאילתות שמשתמשות בפרמטרים מהר יותר בכל הפעלה, כי הפרמטריזציה מקלה על Spanner לשמור במטמון את תוכנית ההפעלה.
- הרכבת שאילתות פשוטה יותר: לא צריך להשתמש בתו בריחה לערכי מחרוזות כשמספקים אותם בפרמטרים של שאילתות. פרמטרים של שאילתה גם מפחיתים את הסיכון לשגיאות תחביר.
- אבטחה: פרמטרים של שאילתות מאבטחים את השאילתות שלכם ומגנים עליכם מפני מתקפות שונות של הזרקת SQL. ההגנה הזו חשובה במיוחד לשאילתות שאתם יוצרים מקלט של משתמשים.
הסבר על האופן שבו Spanner מבצע שאילתות
ב-Spanner אפשר להריץ שאילתות על מסדי נתונים באמצעות הצהרות SQL שמציינות אילו נתונים רוצים לאחזר. אם רוצים להבין איך Spanner משיג את התוצאות, צריך לבדוק את תוכנית הביצוע של השאילתה. בתוכנית להרצת שאילתה מוצגת העלות החישובית שמשויכת לכל שלב בשאילתה. בעזרת העלויות האלה, תוכלו לנפות באגים בביצועי השאילתות ולבצע אופטימיזציה של השאילתה. מידע נוסף זמין במאמר בנושא תוכניות להרצת שאילתות.
אפשר לאחזר תוכניות להרצת שאילתות דרך מסוף Google Cloud או דרך ספריות הלקוח.
כדי לקבל תוכנית להרצת שאילתה עבור שאילתה ספציפית באמצעותGoogle Cloud המסוף, פועלים לפי השלבים הבאים:
פותחים את הדף 'מכונות של Spanner'.
בוחרים את השמות של מופע Spanner ושל מסד הנתונים שרוצים לשלוח להם שאילתה.
בחלונית הניווט הימנית, לוחצים על Spanner Studio.
מקלידים את השאילתה בשדה הטקסט ולוחצים על הפעלת השאילתה.
לוחצים על הסבר
. במסוף Google Cloud מוצגת תוכנית ביצוע חזותית של השאילתה.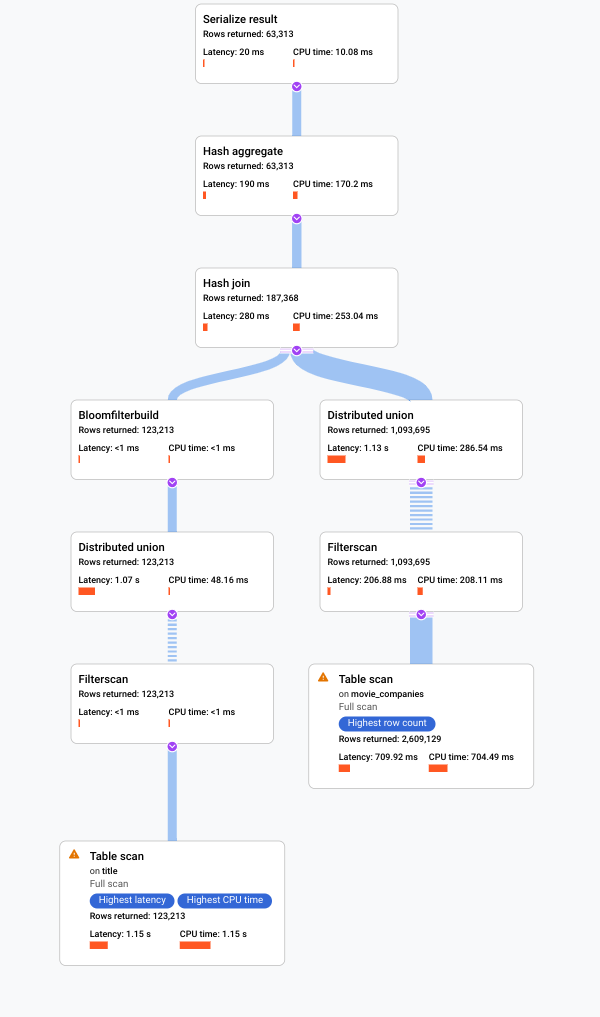
מידע נוסף על הבנת תוכניות חזותיות ושימוש בהן לניפוי באגים בשאילתות זמין במאמר שיפור שאילתה באמצעות כלי להמחזת תוכנית שאילתה.
אפשר גם לראות דוגמאות של תוכניות שאילתות היסטוריות ולהשוות את הביצועים של שאילתה מסוימת לאורך זמן. מידע נוסף זמין במאמר בנושא תוכניות לדוגמה של שאילתות.
שימוש באינדקסים משניים
בדומה למסדי נתונים רלציוניים אחרים, גם Spanner מציע אינדקסים משניים שבהם אפשר להשתמש כדי לאחזר נתונים באמצעות הצהרת SQL או ממשק הקריאה של Spanner. הדרך הנפוצה יותר לאחזור נתונים מאינדקס היא באמצעות Spanner Studio. שימוש באינדקס משני בשאילתת SQL מאפשר לכם לציין איך אתם רוצים ש-Spanner יקבל את התוצאות. ציון של אינדקס משני יכול לזרז את הביצוע של שאילתות.
לדוגמה, נניח שאתם רוצים לאחזר את המזהים של כל הזמרים עם שם משפחה מסוים. אחת הדרכים לכתוב שאילתת SQL כזו היא:
SELECT s.SingerId
FROM Singers AS s
WHERE s.LastName = 'Smith';
השאילתה הזו תחזיר את התוצאות שאתם מצפים להן, אבל יכול להיות שייקח הרבה זמן עד שהתוצאות יוחזרו. התזמון תלוי במספר השורות בטבלה Singers ובמספר השורות שמקיימות את התנאי WHERE s.LastName = 'Smith'.
אם אין אינדקס משני שמכיל את העמודה LastName לקריאה, תוכנית השאילתה תקרא את כל הטבלה Singers כדי למצוא שורות שתואמות לתנאי. קריאת הטבלה כולה נקראת סריקה מלאה של הטבלה. סריקה מלאה של הטבלה היא דרך יקרה להשגת התוצאות, אם הטבלה מכילה רק אחוז קטן של Singers עם שם המשפחה הזה.
כדי לשפר את הביצועים של השאילתה הזו, אפשר להגדיר אינדקס משני בעמודה של שם המשפחה:
CREATE INDEX SingersByLastName ON Singers (LastName);
מכיוון שהאינדקס המשני SingersByLastName מכיל את עמודת הטבלה עם האינדקס LastName ואת עמודת המפתח הראשי SingerId, Spanner יכול לאחזר את כל הנתונים מטבלת האינדקס הקטנה בהרבה, במקום לסרוק את הטבלה המלאה Singers.
בתרחיש הזה, Spanner משתמש אוטומטית באינדקס המשני SingersByLastName כשמריצים את השאילתה (בתנאי שעברו שלושה ימים מאז יצירת מסד הנתונים; ראו הערה לגבי מסדי נתונים חדשים).
עם זאת, מומלץ לציין במפורש ל-Spanner להשתמש באינדקס הזה באמצעות הוראת אינדקס בסעיף FROM:
GoogleSQL
SELECT s.SingerId
FROM Singers@{FORCE_INDEX=SingersByLastName} AS s
WHERE s.LastName = 'Smith';
PostgreSQL
SELECT s.SingerId
FROM Singers /*@ FORCE_INDEX=SingersByLastName */ AS s
WHERE s.LastName = 'Smith';
אם אתם משתמשים בסכימות עם שמות, אתם צריכים להשתמש בתחביר הבא עבור פסוקית FROM:
GoogleSQL
FROM NAMED_SCHEMA_NAME.TABLE_NAME@{FORCE_INDEX="NAMED_SCHEMA_NAME.TABLE_INDEX_NAME"}
PostgreSQL
FROM NAMED_SCHEMA_NAME.TABLE_NAME /*@ FORCE_INDEX = TABLE_INDEX_NAME */
נניח שאתם רוצים לאחזר גם את השם הפרטי של הזמר בנוסף למזהה. גם אם העמודה FirstName לא נכללת באינדקס, עדיין צריך לציין את הוראת האינדקס כמו קודם:
GoogleSQL
SELECT s.SingerId, s.FirstName
FROM Singers@{FORCE_INDEX=SingersByLastName} AS s
WHERE s.LastName = 'Smith';
PostgreSQL
SELECT s.SingerId, s.FirstName
FROM Singers /*@ FORCE_INDEX=SingersByLastName */ AS s
WHERE s.LastName = 'Smith';
עדיין יש יתרון בביצועים כשמשתמשים באינדקס, כי Spanner לא צריך לבצע סריקה מלאה של הטבלה כשמריצים את תוכנית השאילתה. במקום זאת, היא בוחרת את קבוצת המשנה של השורות שעומדות בתנאי מאינדקס SingersByLastName, ואז מבצעת חיפוש בטבלת הבסיס Singers כדי לאחזר את השם הפרטי רק עבור קבוצת המשנה הזו של השורות.
אם רוצים ש-Spanner לא יצטרך לאחזר שורות מטבלת הבסיס בכלל, אפשר לאחסן עותק של העמודה FirstName באינדקס עצמו:
GoogleSQL
CREATE INDEX SingersByLastName ON Singers (LastName) STORING (FirstName);
PostgreSQL
CREATE INDEX SingersByLastName ON Singers (LastName) INCLUDE (FirstName);
שימוש בסעיף STORING (בניב GoogleSQL) או בסעיף INCLUDE (בניב PostgreSQL) כמו בדוגמה הבאה כרוך בעלות נוספת על אחסון, אבל יש לו את היתרונות הבאים:
- שאילתות SQL שמשתמשות באינדקס ובעמודות שנבחרו ומאוחסנות בסעיף
STORINGאוINCLUDEלא דורשות איחוד נוסף עם טבלת הבסיס. - קריאות קריאה שמשתמשות באינדקס יכולות לקרוא עמודות שמאוחסנות בסעיף
STORINGאוINCLUDE.
הדוגמאות הקודמות ממחישות איך אינדקסים משניים יכולים להאיץ שאילתות
כשהשורות שנבחרו על ידי סעיף WHERE של שאילתה ניתנות לזיהוי מהיר
באמצעות האינדקס המשני.
תרחיש נוסף שבו אינדקסים משניים יכולים לשפר את הביצועים הוא שאילתות מסוימות שמחזירות תוצאות מסודרות. לדוגמה, נניח שאתם רוצים לאחזר את כל שמות האלבומים ואת תאריכי ההפצה שלהם בסדר עולה של תאריך ההפצה ובסדר יורד של שם האלבום. אפשר לכתוב שאילתת SQL באופן הבא:
SELECT a.AlbumTitle, a.ReleaseDate
FROM Albums AS a
ORDER BY a.ReleaseDate, a.AlbumTitle DESC;
בלי אינדקס משני, השאילתה הזו דורשת שלב מיון שעלול להיות יקר בתוכנית הביצוע. כדי להאיץ את הביצוע של השאילתה, אפשר להגדיר את האינדקס המשני הזה:
CREATE INDEX AlbumsByReleaseDateTitleDesc on Albums (ReleaseDate, AlbumTitle DESC);
לאחר מכן, משכתבים את השאילתה כדי להשתמש באינדקס המשני:
GoogleSQL
SELECT a.AlbumTitle, a.ReleaseDate
FROM Albums@{FORCE_INDEX=AlbumsByReleaseDateTitleDesc} AS a
ORDER BY a.ReleaseDate, a.AlbumTitle DESC;
PostgreSQL
SELECT a.AlbumTitle, a.ReleaseDate
FROM Albums /*@ FORCE_INDEX=AlbumsByReleaseDateTitleDesc */ AS s
ORDER BY a.ReleaseDate, a.AlbumTitle DESC;
השאילתה הזו והגדרת האינדקס עומדות בשני הקריטריונים הבאים:
- כדי להסיר את שלב המיון, מוודאים שרשימת העמודות בסעיף
ORDER BYהיא קידומת של רשימת מפתחות האינדקס. - כדי להימנע מחיבור חוזר מטבלת הבסיס כדי לאחזר עמודות חסרות, צריך לוודא שהאינדקס מכסה את כל העמודות בטבלה שבה נעשה שימוש בשאילתה.
למרות שמדדים משניים יכולים להאיץ שאילתות נפוצות, הוספה של מדדים משניים עלולה להוסיף זמן אחזור לפעולות של שליחת נתונים, כי כל מדד משני בדרך כלל דורש מעורבות של צומת נוסף בכל שליחה. ברוב עומסי העבודה, אין בעיה עם כמה אינדקסים משניים. עם זאת, כדאי לשקול מה יותר חשוב לכם: זמן האחזור של קריאה או של כתיבה, ולחשוב אילו פעולות הכי קריטיות לעומס העבודה שלכם. כדאי להשוות את עומס העבודה לביצועים של עומסי עבודה אחרים כדי לוודא שהוא פועל כמצופה.
למידע נוסף על אינדקסים משניים, אפשר לעיין במאמר אינדקסים משניים.
אופטימיזציה של סריקות
יכול להיות ששאילתות מסוימות ב-Spanner יפיקו תועלת משימוש בשיטת עיבוד מבוססת-אצווה לסריקת נתונים, במקום בשיטת העיבוד הנפוצה יותר שמבוססת על שורות. עיבוד סריקות באצוות הוא דרך יעילה יותר לעבד כמויות גדולות של נתונים בבת אחת, והוא מאפשר לשאילתות להשיג שימוש נמוך יותר במעבד (CPU) וזמן אחזור נמוך יותר.
פעולת הסריקה של Spanner תמיד מתחילה את ההרצה בשיטה מבוססת-שורות. במהלך הזמן הזה, Spanner אוסף כמה מדדים של זמן ריצה. לאחר מכן, Spanner מחיל קבוצה של היוריסטיקות שמבוססות על התוצאה של המדדים האלה כדי לקבוע את שיטת הסריקה האופטימלית. במקרים המתאימים, Spanner עובר לשיטת עיבוד מבוססת-אצווה כדי לשפר את קצב העברת הנתונים ואת הביצועים של הסריקה.
תרחישים נפוצים לדוגמה
בדרך כלל, שאילתות עם המאפיינים הבאים נהנות משימוש בעיבוד מבוסס-אצווה:
- סריקות גדולות של נתונים שלא מתעדכנים לעיתים קרובות.
- סריקות עם פרדיקטים בעמודות ברוחב קבוע.
- סריקות עם מספרים גבוהים של פעולות חיפוש. (חיפוש משתמש באינדקס כדי לאחזר רשומות).
תרחישי שימוש ללא שיפור בביצועים
לא כל השאילתות מרוויחות מעיבוד מבוסס-אצווה. סוגי השאילתות הבאים פועלים טוב יותר עם עיבוד של סריקה לפי שורות:
- שאילתות לחיפוש נקודתי: שאילתות שמביאות רק שורה אחת.
- שאילתות סריקה קטנות: סריקות טבלה שסורקות רק כמה שורות, אלא אם יש להן מספרים גדולים של פעולות חיפוש.
- שאילתות שמשתמשות ב
LIMIT. - שאילתות שקוראות נתונים עם שיעור נטישה גבוה: שאילתות שבהן יותר מ-10% מהנתונים שנקראים מתעדכנים לעיתים קרובות.
- שאילתות עם שורות שמכילות ערכים גדולים: שורות עם ערכים גדולים הן שורות שמכילות ערכים גדולים מ-32,000 בייט (לפני דחיסה) בעמודה אחת.
בדיקת שיטת הסריקה שבה נעשה שימוש בשאילתה
כדי לבדוק אם השאילתה משתמשת בעיבוד מבוסס-אצווה, בעיבוד מבוסס-שורה או עוברת אוטומטית בין שתי שיטות הסריקה:
נכנסים לדף Instances ב-Spanner במסוףGoogle Cloud .
לוחצים על השם של המכונה עם השאילתה שרוצים לבדוק.
בטבלת מסדי הנתונים, לוחצים על מסד הנתונים עם השאילתה שרוצים לבדוק.
בתפריט הניווט, לוחצים על Spanner Studio.
פותחים כרטיסייה חדשה בלחיצה על New SQL editor tab או על New tab.
כשעורך השאילתות מופיע, כותבים את השאילתה.
לוחצים על Run.
מערכת Spanner מריצה את השאילתה ומציגה את התוצאות.
לוחצים על הכרטיסייה Explanation מתחת לעורך השאילתות.
ב-Spanner מוצג כלי להמחשת תוכנית ביצוע של שאילתות. כל כרטיס בתרשים מייצג איטרטור.
לוחצים על כרטיס האיטרטור Table scan כדי לפתוח חלונית מידע.
בחלונית המידע מוצג מידע הקשרי על הסריקה שנבחרה. שיטת הסריקה מוצגת בכרטיס הזה. אוטומטי מציין ש-Spanner קובע את שיטת הסריקה. ערכים אפשריים אחרים כוללים Batch לעיבוד מבוסס-batch ו-Row לעיבוד מבוסס-שורה.
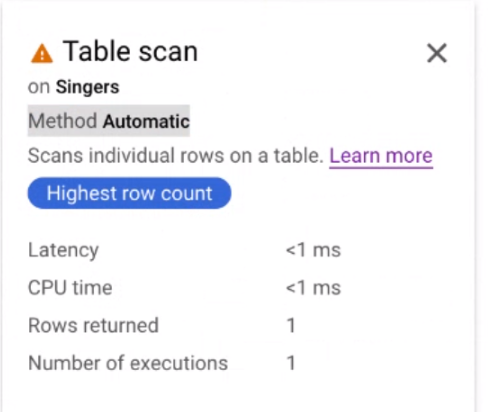
הגדרת שיטת הסריקה שבה תשתמש שאילתה
כדי לבצע אופטימיזציה של ביצועי השאילתות, Spanner בוחר את שיטת הסריקה האופטימלית עבור השאילתה. מומלץ להשתמש בשיטת הסריקה הזו שמוגדרת כברירת מחדל. עם זאת, יכול להיות שיהיו תרחישים שבהם תרצו לאכוף שימוש בשיטת סריקה ספציפית.
אכיפה של סריקה מבוססת-אצווה
אפשר לאכוף סריקה מבוססת-אצווה ברמת הטבלה וברמת ההצהרה.
כדי לאכוף את שיטת הסריקה מבוססת-האצווה ברמת הטבלה, משתמשים ברמז לטבלה בשאילתה:
GoogleSQL
SELECT ...
FROM (t1@{SCAN_METHOD=BATCH} JOIN t2 ON ...)
WHERE ...
PostgreSQL
SELECT ...
FROM (t1/*@ scan_method=batch */ JOIN t2 on ...)
WHERE ...
כדי לאכוף את שיטת הסריקה מבוססת-האצווה ברמת ההצהרה, משתמשים ברמז להצהרה בשאילתה:
GoogleSQL
@{SCAN_METHOD=BATCH}
SELECT ...
FROM ...
WHERE ...
PostgreSQL
/*@ scan_method=batch */
SELECT ...
FROM ...
WHERE ...
השבתה של סריקה אוטומטית ואכיפה של סריקה לפי שורות
אמנם אנחנו לא ממליצים להשבית את שיטת הסריקה האוטומטית שמוגדרת על ידי Spanner, אבל יכול להיות שתחליטו להשבית אותה ולהשתמש בשיטת הסריקה לפי שורות למטרות פתרון בעיות, כמו אבחון של זמן האחזור.
כדי להשבית את שיטת הסריקה האוטומטית ולאלץ עיבוד שורות ברמת הטבלה, משתמשים ברמז לטבלה בשאילתה:
GoogleSQL
SELECT ...
FROM (t1@{SCAN_METHOD=ROW} JOIN t2 ON ...)
WHERE ...
PostgreSQL
SELECT ...
FROM (t1/*@ scan_method=row */ JOIN t2 on ...)
WHERE ...
כדי להשבית את שיטת הסריקה האוטומטית ולאכוף עיבוד שורות ברמת ההצהרה, משתמשים ברמז להצהרה בשאילתה:
GoogleSQL
@{SCAN_METHOD=ROW}
SELECT ...
FROM ...
WHERE ...
PostgreSQL
/*@ scan_method=row */
SELECT ...
FROM ...
WHERE ...
אופטימיזציה של ביצוע שאילתות
בנוסף לאופטימיזציה של סריקות, אפשר גם לבצע אופטימיזציה של ביצוע שאילתות על ידי הגדרת שיטת הביצוע ברמת ההצהרה. האפשרות הזו פועלת רק עבור חלק מהאופרטורים, והיא לא תלויה בשיטת הסריקה, שמשמשת רק את אופרטור הסריקה.
כברירת מחדל, רוב האופרטורים פועלים בשיטה של עיבוד נתונים לפי שורות, כלומר שורה אחת בכל פעם. אופרטורים וקטוריים פועלים בשיטה מבוססת-אצווה כדי לשפר את קצב העברת הנתונים והביצועים. האופרטורים האלה מעבדים נתונים בלוק אחד בכל פעם. בדרך כלל, אם אופרטור צריך לעבד הרבה שורות, שיטת ההפעלה מבוססת-הקבוצות יעילה יותר.
שיטת ההפעלה לעומת שיטת הסריקה
שיטת הרצת השאילתה לא תלויה בשיטת הסריקה של השאילתה. אפשר להגדיר אחת מהשיטות האלה, את שתיהן או אף אחת מהן ברמז לשאילתה.
שיטת ההפעלה של השאילתה מתייחסת לאופן שבו אופרטורים של שאילתות מעבדים תוצאות ביניים ולאופן שבו האופרטורים מקיימים אינטראקציה זה עם זה. שיטת הסריקה מתייחסת לאופן שבו אופרטור הסריקה מקיים אינטראקציה עם שכבת האחסון של Spanner.
אכיפת שיטת הביצוע שבה נעשה שימוש בשאילתה
כדי לשפר את ביצועי השאילתות, מערכת Spanner בוחרת את שיטת הביצוע האופטימלית לשאילתה על סמך היוריסטיקות שונות. מומלץ להשתמש בשיטת ההפעלה הזו שמוגדרת כברירת מחדל. עם זאת, יכולים להיות תרחישים שבהם תרצו לאכוף סוג מסוים של שיטת ביצוע.
אפשר לאכוף את שיטת ההפעלה ברמת ההצהרה. התג
EXECUTION_METHOD הוא רמז לשאילתה ולא הנחיה. בסופו של דבר, הכלי לאופטימיזציה של שאילתות קובע באיזו שיטה להשתמש עבור כל אופרטור בנפרד.
כדי לאכוף את שיטת ההפעלה מבוססת-האצווה ברמת ההצהרה, משתמשים ברמז להצהרה בשאילתה:
GoogleSQL
@{EXECUTION_METHOD=BATCH}
SELECT ...
FROM ...
WHERE ...
PostgreSQL
/*@ execution_method=batch */
SELECT ...
FROM ...
WHERE ...
אמנם אנחנו לא ממליצים להשבית את שיטת ההפעלה האוטומטית שמוגדרת על ידי Spanner, אבל יכול להיות שתחליטו להשבית אותה ולהשתמש בשיטת ההפעלה לפי שורות למטרות פתרון בעיות, כמו אבחון של זמן האחזור.
כדי להשבית את שיטת ההפעלה האוטומטית ולאכוף את שיטת ההפעלה לפי שורה ברמת ההצהרה, משתמשים ברמז להצהרה בשאילתה:
GoogleSQL
@{EXECUTION_METHOD=ROW}
SELECT ...
FROM ...
WHERE ...
PostgreSQL
/*@ execution_method=row */
SELECT ...
FROM ...
WHERE ...
בדיקה של שיטת ההפעלה שמופעלת
לא כל האופרטורים של Spanner תומכים בשיטות ביצוע מבוססות-batch ומבוססות-שורה. עבור כל אופרטור, כלי ההמחשה של תוכנית הביצוע של השאילתה מציג את שיטת הביצוע בכרטיס האיטרטור. אם שיטת ההפעלה היא מבוססת-אצווה, יופיע Batch. אם הוא מבוסס על שורות, מוצגת האפשרות שורה.
אם האופרטורים בשאילתה מופעלים באמצעות שיטות הפעלה שונות, האופרטורים DataBlockToRowAdapter ו-RowToDataBlockAdapter מופיעים ביניהם כדי להציג את השינוי בשיטת ההפעלה.
אופטימיזציה של חיפושים במפתח טווח
שימוש נפוץ בשאילתת SQL הוא קריאה של כמה שורות מ-Spanner על סמך רשימה של מפתחות ידועים.
השיטות המומלצות הבאות יעזרו לכם לכתוב שאילתות יעילות כשאתם מאחזרים נתונים לפי טווח של מפתחות:
אם רשימת המפתחות דלילה ולא סמוכה, משתמשים בפרמטרים של שאילתה וב-
UNNESTכדי ליצור את השאילתה.לדוגמה, אם רשימת המפתחות היא
{1, 5, 1000}, כותבים את השאילתה כך:GoogleSQL
SELECT * FROM Table AS t WHERE t.Key IN UNNEST (@KeyList)
PostgreSQL
SELECT * FROM Table AS t WHERE t.Key IN UNNEST ($1)
הערות:
האופרטור UNNEST של מערך משטח מערך קלט לשורות של רכיבים.
פרמטר השאילתה, שהוא
@KeyListב-GoogleSQL ו-$1ב-PostgreSQL, יכול להאיץ את השאילתה כמו שמוסבר בשיטה המומלצת הקודמת.
אם רשימת המפתחות סמוכה ונמצאת בטווח, מציינים את הגבולות התחתון והעליון של טווח המפתחות בסעיף
WHERE.לדוגמה, אם רשימת מילות המפתח שלכם היא
{1,2,3,4,5}, השאילתה תהיה:GoogleSQL
SELECT * FROM Table AS t WHERE t.Key BETWEEN @min AND @max
PostgreSQL
SELECT * FROM Table AS t WHERE t.Key BETWEEN $1 AND $2
השאילתה הזו יעילה יותר רק אם המפתחות בטווח המפתחות סמוכים. במילים אחרות, אם רשימת המפתחות שלכם היא
{1, 5, 1000}, אל תציינו את הגבולות התחתון והעליון כמו בשאילתה הקודמת, כי השאילתה שתתקבל תסרוק כל ערך בין 1 ל-1000.
אופטימיזציה של הצטרפות
פעולות של צירוף יכולות להיות יקרות כי הן יכולות להגדיל באופן משמעותי את מספר השורות שהשאילתה צריכה לסרוק, וכתוצאה מכך השאילתות פועלות לאט יותר. בנוסף לטכניקות שאתם רגילים להשתמש בהן במסדי נתונים רלציוניים אחרים כדי לבצע אופטימיזציה של שאילתות איחוד (join), הנה כמה שיטות מומלצות לביצוע איחוד (join) יעיל יותר כשמשתמשים ב-Spanner SQL:
אם אפשר, מאחדים נתונים בטבלאות משולבות לפי מפתח ראשי. לדוגמה:
SELECT s.FirstName, a.ReleaseDate FROM Singers AS s JOIN Albums AS a ON s.SingerId = a.SingerId;
השורות בטבלה המשולבת
Albumsמובטחות להיות מאוחסנות פיזית באותם פיצולים כמו שורת האב בטבלהSingers, כפי שמוסבר במאמר סכימה ומודל נתונים. לכן, אפשר לבצע את הפעולות האלה באופן מקומי בלי לשלוח הרבה נתונים ברשת.משתמשים בהוראת הצירוף אם רוצים לכפות את סדר הצירוף. לדוגמה:
GoogleSQL
SELECT * FROM Singers AS s JOIN@{FORCE_JOIN_ORDER=TRUE} Albums AS a ON s.SingerId = a.Singerid WHERE s.LastName LIKE '%x%' AND a.AlbumTitle LIKE '%love%';
PostgreSQL
SELECT * FROM Singers AS s JOIN/*@ FORCE_JOIN_ORDER=TRUE */ Albums AS a ON s.SingerId = a.Singerid WHERE s.LastName LIKE '%x%' AND a.AlbumTitle LIKE '%love%';
ההנחיה לצירוף
FORCE_JOIN_ORDERאומרת ל-Spanner להשתמש בסדר הצירוף שצוין בשאילתה (כלומר,Singers JOIN Albums, ולאAlbums JOIN Singers). התוצאות שמוחזרות זהות, ללא קשר לסדר ש-Spanner בוחר. עם זאת, יכול להיות שתרצו להשתמש בהנחיית הצירוף הזו אם תבחינו בתוכנית השאילתה ש-Spanner שינה את סדר הצירוף וגרם לתוצאות לא רצויות, כמו תוצאות ביניים גדולות יותר, או אם הוא פספס הזדמנויות לחיפוש שורות.משתמשים בהנחיית הצטרפות כדי לבחור הטמעה של הצטרפות. כשמשתמשים ב-SQL כדי לשלוח שאילתה למספר טבלאות, Spanner משתמש באופן אוטומטי בשיטת join שיש סיכוי שתהפוך את השאילתה ליעילה יותר. עם זאת, מומלץ לבצע בדיקות עם אלגוריתמים שונים של הצטרפות. בחירה באלגוריתם הנכון לצירוף יכולה לשפר את זמן האחזור, את צריכת הזיכרון או את שניהם. השאילתה הזו מדגימה את התחביר לשימוש בהנחיית JOIN עם הרמז
JOIN_METHODכדי לבחורHASH JOIN:GoogleSQL
SELECT * FROM Singers s JOIN@{JOIN_METHOD=HASH_JOIN} Albums AS a ON a.SingerId = a.SingerId
PostgreSQL
SELECT * FROM Singers s JOIN/*@ JOIN_METHOD=HASH_JOIN */ Albums AS a ON a.SingerId = a.SingerId
אם אתם משתמשים ב-
HASH JOINאו ב-APPLY JOINויש לכם פסקהWHEREשהיא סלקטיבית מאוד בצד אחד שלJOIN, צריך להציב את הטבלה שמפיקה את המספר הקטן ביותר של שורות כטבלה הראשונה בפסקהFROMשל הצירוף. המבנה הזה עוזר כי ב-HASH JOIN, Spanner תמיד בוחר את הטבלה בצד ימין כטבלה לבנייה ואת הטבלה בצד שמאל כטבלה לבדיקה. באופן דומה, עבורAPPLY JOIN, Spanner בוחר בטבלה בצד ימין כחיצונית ובטבלה בצד שמאל כפנימית. מידע נוסף על סוגי הצירופים האלה: Hash join ו-Apply join.כדי לשפר את העקביות בביצועים של שאילתות שחשובות לעומס העבודה שלכם, כדאי לציין בהצהרות SQL את שיטת ה-join עם הביצועים הכי טובים ואת סדר ה-join.
אופטימיזציה של שאילתות באמצעות העברת פרדיקטים של חותמות זמן
העברת פרדיקטים של חותמות זמן (timestamp predicate pushdown) היא טכניקה לאופטימיזציה של שאילתות שמשמשת ב-Spanner כדי לשפר את היעילות של שאילתות שמשתמשות בחותמות זמן ובנתונים עם מדיניות אחסון מדורגת לפי גיל. כשמפעילים את האופטימיזציה הזו, פעולות הסינון בעמודות של חותמות זמן מבוצעות בשלב מוקדם ככל האפשר בתוכנית הביצוע של השאילתה. הפעולה הזו יכולה לצמצם באופן משמעותי את כמות הנתונים שעוברים עיבוד ולשפר את הביצועים הכוללים של השאילתות.
בעזרת העברת מסננים של חותמות זמן למטה, מנוע מסד הנתונים מנתח את השאילתה ומזהה את המסנן של חותמת הזמן. המסנן הזה מועבר לשכבת האחסון, כך שרק הנתונים הרלוונטיים על סמך קריטריוני חותמת הזמן נקראים מ-SSD. כך מצמצמים את כמות הנתונים שמעובדים ומועברים, והשאילתה מתבצעת מהר יותר.
כדי לבצע אופטימיזציה של שאילתות כך שהן יגשו רק לנתונים שמאוחסנים ב-SSD, צריך לוודא שהתנאים הבאים מתקיימים:
- צריך להפעיל את האפשרות 'העברת פרדיקט של חותמת זמן' בשאילתה. למידע נוסף, ראו הערות לגבי הצהרות GoogleSQL והערות לגבי הצהרות PostgreSQL
השאילתה צריכה להשתמש בהגבלה לפי גיל ששווה לגיל שצוין במדיניות השמירה של הנתונים (שמוגדרת באמצעות האפשרות
ssd_to_hdd_spill_timespanבהצהרת ה-DDLCREATE LOCALITY GROUPאוALTER LOCALITY GROUP) או קטנה ממנו. מידע נוסף זמין במאמרים בנושא הצהרות של GoogleSQLLOCALITY GROUPוהצהרות של PostgreSQLLOCALITY GROUP.העמודה שמסננים בשאילתה חייבת להיות עמודה של חותמת זמן שמכילה את חותמת הזמן של השמירה. פרטים על יצירת עמודה של חותמת זמן של השמירה זמינים במאמרים בנושא חותמות זמן של השמירה ב-GoogleSQL וחותמות זמן של השמירה ב-PostgreSQL. צריך לעדכן את העמודות האלה יחד עם עמודת חותמת הזמן, והן צריכות להיות באותה קבוצת מיקום, שמוגדרת בה מדיניות אחסון מדורגת לפי גיל.
אם בשורה מסוימת חלק מהעמודות שנכללות בשאילתה נמצאות ב-SSD וחלק מהעמודות נמצאות ב-HDD (בגלל שהעמודות מתעדכנות בזמנים שונים ועוברות ל-HDD בזמנים שונים), הביצועים של השאילתה עשויים להיות גרועים יותר כשמשתמשים ברמז. הסיבה לכך היא שהשאילתה צריכה למלא נתונים משכבות האחסון השונות. כתוצאה מהשימוש ברמז, מערכת Spanner מזהה נתונים ישנים ברמת התא הבודד (רמת גרנולריות של שורה ועמודה) על סמך חותמת הזמן של כל תא, וכך מאטה את השאילתה. כדי למנוע את הבעיה הזו, חשוב לעדכן באופן שוטף את כל העמודות שמתבצעת עליהן שאילתה באמצעות טכניקת האופטימיזציה הזו באותה טרנזקציה, כדי שלכל העמודות יהיה אותו חותמת זמן של ביצוע, ושהן ייהנו מהאופטימיזציה.
כדי להפעיל את ההעברה של פרדיקטים של חותמות זמן ברמת ההצהרה, משתמשים ברמז להצהרה בשאילתה. לדוגמה:
GoogleSQL
@{allow_timestamp_predicate_pushdown=TRUE}
SELECT s.SingerInfo
FROM Singers s
WHERE s.ModificationTime > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 12 HOUR);
PostgreSQL
/*@allow_timestamp_predicate_pushdown=TRUE*/
SELECT s.SingerInfo
FROM Singers s
WHERE s.ModificationTime > CURRENT_TIMESTAMP - INTERVAL '12 hours';
הימנעות מקריאות גדולות בתוך טרנזקציות של קריאה וכתיבה
טרנזקציות של קריאה וכתיבה מאפשרות רצף של אפס או יותר קריאות או שאילתות SQL, ויכולות לכלול קבוצה של שינויים לפני קריאה ל-commit. כדי לשמור על עקביות הנתונים, Spanner מקבל נעילות כשקוראים וכותבים שורות בטבלאות ובאינדקסים. מידע נוסף על נעילה זמין במאמר משך החיים של פעולות קריאה וכתיבה.
בגלל האופן שבו נעילה פועלת ב-Spanner, ביצוע קריאה או שאילתת SQL שקוראת מספר גדול של שורות (לדוגמה SELECT * FROM
Singers) פירושו שאף טרנזקציה אחרת לא יכולה לכתוב לשורות שקראתם עד שהטרנזקציה שלכם תאושר או תבוטל.
בנוסף, מכיוון שהעסקה מעבדת מספר גדול של שורות, סביר להניח שהיא תימשך זמן רב יותר מעסקה שקוראת טווח קטן בהרבה של שורות (לדוגמה SELECT LastName FROM Singers WHERE SingerId = 7), מה שמחמיר עוד יותר את הבעיה ומקטין את קצב העברת הנתונים של המערכת.
לכן, כדאי להימנע מקריאות גדולות (לדוגמה, סריקות מלאות של טבלאות או פעולות join גדולות) בעסקאות, אלא אם אתם מוכנים לקבל תפוקת כתיבה נמוכה יותר.
במקרים מסוימים, התבנית הבאה יכולה להניב תוצאות טובות יותר:
- כדאי לבצע קריאות גדולות בתוך טרנזקציה לקריאה בלבד. עסקאות לקריאה בלבד מאפשרות תפוקה מצטברת גבוהה יותר כי הן לא משתמשות בנעילות.
- אופציונלי: מבצעים את העיבוד הנדרש על הנתונים שזה עתה קראתם.
- מתחילים טרנזקציה עם הרשאת קריאה וכתיבה.
- מוודאים שהערכים בשורות הקריטיות לא השתנו מאז שביצעתם את העסקה לקריאה בלבד בשלב 1.
- אם השורות השתנו, מבטלים את העסקה ומתחילים מחדש משלב 1.
- אם הכול נראה בסדר, מאשרים את השינויים.
דרך אחת לוודא שאתם נמנעים מקריאות גדולות בעסקאות קריאה-כתיבה היא לבדוק את תוכניות הביצוע שהשאילתות שלכם יוצרות.
שימוש ב-ORDER BY כדי להבטיח את הסדר של תוצאות ה-SQL
אם אתם מצפים לסדר מסוים של תוצאות של שאילתת SELECT, כדאי לכלול במפורש את פסוקית ORDER BY. לדוגמה, אם רוצים להציג רשימה של כל הזמרים לפי סדר המפתח הראשי, משתמשים בשאילתה הבאה:
SELECT * FROM Singers
ORDER BY SingerId;
מערכת Spanner מבטיחה את סדר התוצאות רק אם יש בבקשת השאילתה את פסוקית ORDER BY. במילים אחרות, כדאי לשקול את השאילתה הזו בלי ORDER
BY:
SELECT * FROM Singers;
Spanner לא מבטיח שהתוצאות של השאילתה הזו יהיו מסודרות לפי מפתח ראשי. בנוסף, סדר התוצאות יכול להשתנות בכל שלב, ואין הבטחה שהוא יהיה עקבי בין הפעלות שונות. אם לשאילתה יש פסוקית ORDER BY, ו-Spanner משתמש באינדקס שמספק את הסדר הנדרש, אז Spanner לא ממיין את הנתונים באופן מפורש. לכן, אין צורך לדאוג לגבי ההשפעה על הביצועים כתוצאה מהכללת הסעיף הזה. כדי לבדוק אם פעולת מיון מפורשת נכללת בהרצה, אפשר לעיין בתוכנית השאילתה.
שימוש בפונקציה STARTS_WITH במקום בפונקציה LIKE
מכיוון ש-Spanner לא מעריך דפוסי LIKE עם פרמטרים עד זמן הביצוע, הוא צריך לקרוא את כל השורות ולהעריך אותן לפי הביטוי LIKE כדי לסנן שורות שלא תואמות.
אם דפוס LIKE הוא מהצורה foo% (לדוגמה, הוא מתחיל במחרוזת קבועה ומסתיים בתו כללי יחיד של אחוז) והעמודה היא אינדקס, צריך להשתמש ב-STARTS_WITH במקום ב-LIKE. האפשרות הזו מאפשרת ל-Spanner לבצע אופטימיזציה של תוכנית ההפעלה של השאילתה בצורה יעילה יותר.
לא מומלץ:
GoogleSQL
SELECT a.AlbumTitle FROM Albums a WHERE a.AlbumTitle LIKE @like_clause;
PostgreSQL
SELECT a.AlbumTitle FROM Albums a WHERE a.AlbumTitle LIKE $1;
מומלץ:
GoogleSQL
SELECT a.AlbumTitle FROM Albums a WHERE STARTS_WITH(a.AlbumTitle, @prefix);
PostgreSQL
SELECT a.AlbumTitle FROM Albums a WHERE STARTS_WITH(a.AlbumTitle, $2);
שימוש בחותמות זמן של ביצוע שינויים
אם האפליקציה שלכם צריכה לשלוח שאילתות לגבי נתונים שנכתבו אחרי זמן מסוים, צריך להוסיף עמודות של חותמות זמן של ביצוע פעולות (commit) לטבלאות הרלוונטיות. חותמות הזמן של ביצוע השינויים מאפשרות לבצע אופטימיזציה ב-Spanner, שיכולה לצמצם את פעולות הקלט/פלט של שאילתות שהסעיפים WHERE שלהן מגבילים את התוצאות לשורות שנכתבו לאחרונה, אחרי זמן מסוים.
מידע נוסף על האופטימיזציה הזו במסדי נתונים של ניב GoogleSQL או במסדי נתונים של ניב PostgreSQL.