
分散演算子は、リーフ演算子、単項演算子、二項演算子、n 項演算子とは異なり、複数のサーバー間で実行されます。
次の演算子は分散演算子です。
データベース スキーマ
このページのクエリと実行プランは、次のデータベース スキーマに基づいています。
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY(SingerId);
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
MarketingBudget INT64
) PRIMARY KEY(SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget);
CREATE TABLE Songs (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
TrackId INT64 NOT NULL,
SongName STRING(MAX),
Duration INT64,
SongGenre STRING(25)
) PRIMARY KEY(SingerId, AlbumId, TrackId),
INTERLEAVE IN PARENT Albums ON DELETE CASCADE;
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC), INTERLEAVE IN Albums;
CREATE INDEX SongsBySongName ON Songs(SongName);
CREATE TABLE Concerts (
VenueId INT64 NOT NULL,
SingerId INT64 NOT NULL,
ConcertDate DATE NOT NULL,
BeginTime TIMESTAMP,
EndTime TIMESTAMP,
TicketPrices ARRAY<INT64>
) PRIMARY KEY(VenueId, SingerId, ConcertDate);
次のデータ操作言語(DML)ステートメントを使用して、これらのテーブルにデータを追加できます。
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate)
VALUES (1, "Marc", "Richards", "1970-09-03"),
(2, "Catalina", "Smith", "1990-08-17"),
(3, "Alice", "Trentor", "1991-10-02"),
(4, "Lea", "Martin", "1991-11-09"),
(5, "David", "Lomond", "1977-01-29");
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle)
VALUES (1, 1, "Total Junk"),
(1, 2, "Go, Go, Go"),
(2, 1, "Green"),
(2, 2, "Forever Hold Your Peace"),
(2, 3, "Terrified"),
(3, 1, "Nothing To Do With Me"),
(4, 1, "Play");
INSERT INTO Songs (SingerId, AlbumId, TrackId, SongName, Duration, SongGenre)
VALUES (2, 1, 1, "Let's Get Back Together", 182, "COUNTRY"),
(2, 1, 2, "Starting Again", 156, "ROCK"),
(2, 1, 3, "I Knew You Were Magic", 294, "BLUES"),
(2, 1, 4, "42", 185, "CLASSICAL"),
(2, 1, 5, "Blue", 238, "BLUES"),
(2, 1, 6, "Nothing Is The Same", 303, "BLUES"),
(2, 1, 7, "The Second Time", 255, "ROCK"),
(2, 3, 1, "Fight Story", 194, "ROCK"),
(3, 1, 1, "Not About The Guitar", 278, "BLUES");
分散ユニオン演算子はプリミティブ演算子で、この演算子から分散クロス適用、分散外部適用が派生しています。
実行プランでは、1 個以上のローカル分散ユニオン変数の上に分散演算子が分散ユニオン変数と一緒に存在します。分散ユニオン変数は、サブプランのリモート分散を実行します。
ローカル分散ユニオン変数は、クエリで実行されるスキャンの上に存在します。ローカル分散ユニオン変数により、スプリットの境界が動的に変更され、再起動が発生してもクエリが安定して実行されます。この演算子はビジュアル プランには表示されませんが、常に存在します。
可能であれば、分散ユニオン変数ではスプリットのプルーニングにスプリット述語が使用されます。スプリットのプルーニングとは、リモート サーバーが述語の条件を満たすスプリットに対してのみサブプランを実行することです。これにより、レイテンシとクエリのパフォーマンスが向上します。
分散ユニオン
概念的には、分散ユニオン演算子は、1 つ以上のテーブルを複数のスプリットに分割し、各スプリットのサブクエリをリモートで個別に評価してから、すべての結果を結合します。
次のクエリは、この演算子を示しています。
SELECT s.songname,
s.songgenre
FROM songs AS s
WHERE s.singerid = 2
AND s.songgenre = 'ROCK';
/*-----------------+-----------+
| SongName | SongGenre |
+-----------------+-----------+
| Starting Again | ROCK |
| The Second Time | ROCK |
| Fight Story | ROCK |
+-----------------+-----------*/
実行プランは次のように表示されます。
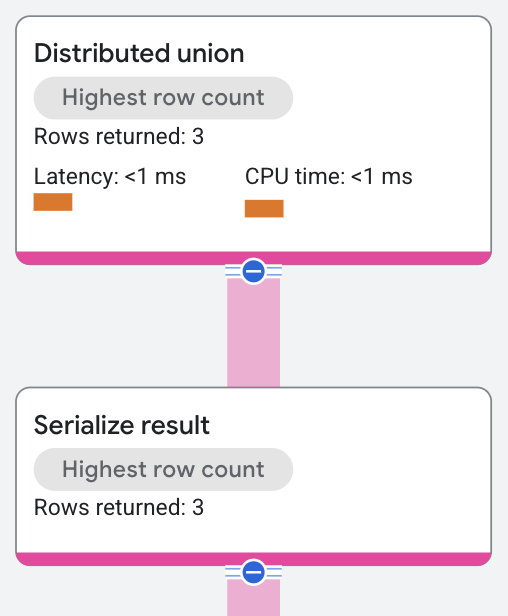
分散ユニオン演算子はリモート サーバーにサブプランを送信します。これにより、スプリット全体にテーブル スキャンを実行し、クエリの述語 WHERE s.SingerId = 2 AND s.SongGenre = 'ROCK' を満たすものを探します。結果のシリアル化演算子は、テーブル スキャンによって返された行から SongName と SongGenre の値を導きます。分散ユニオン演算子は、リモート サーバーから受信し、結合した結果を SQL クエリの結果として返します。
プロパティと実行統計情報
演算子のプロパティは、演算子の実行時に使用される特性を表します。実行統計情報は、クエリ実行中に収集される値で、オペレーターのパフォーマンスを評価するのに役立ちます。
分散ユニオン演算子には、追加の個別の実行統計情報があります。プロパティ
| 名前 | 説明 |
|---|---|
| 実行メソッド | 行実行では、演算子は一度に 1 行を処理します。バッチ実行では、演算子は一度に複数の行を処理します。 |
実行統計情報
| 名前 | 説明 |
|---|---|
| ローカル並列実行数 | 並行して実行されるサブクエリの数。 |
| リモート呼び出し | 実行されたリモート サブクエリの数。 |
| レイテンシ | 演算子で実行されたすべての実行の経過時間。 |
| 累積レイテンシ | 現在の演算子とその子孫の合計時間。 |
| CPU 時間 | 演算子の実行に費やされた CPU 時間の合計。 |
| 累積 CPU 時間 | オペレーターとその子孫の実行に費やされた合計 CPU 時間。 |
| 実行時間 | クエリの実行と結果の処理にかかった合計時間。 |
| 返された行数 | この演算子によって出力された行数 |
| 実行数 | 演算子が実行された回数。一部の実行は並行して実行できます。 |
一般に、実行はクロス適用実行とは異なり、並列で行われます。このため、分散演算子のレイテンシ数は累積されます。ほとんどの演算子は、その演算子が追加したレイテンシの量を報告します。分散ユニオンの実行数は、テーブルの分割境界に基づきます。この境界は、データサイズと負荷によって決まり、use_additional_parallelism ステートメント ヒントが含まれる場合もあります。この統計アプローチは、すべての分散オペレータに適用されます。
分散適用
分散適用(DA)演算子は、複数のサーバー全体で実行することで、適用結合演算子を拡張します。入力側が行をバッチにグループ化します。通常のクロス適用演算子と異なり、同時に複数の入力を処理できます。DA マップ側は、リモート サーバーで実行されるプレーン適用結合演算子のセットです。分散適用結合は、適用結合と同じ適用メソッドをサポートします。
プロパティと実行統計情報
演算子のプロパティは、演算子の実行時に使用される特性を表します。実行統計情報は、クエリ実行中に収集される値で、オペレーターのパフォーマンスを評価するのに役立ちます。
分散適用演算子には、追加の個別の実行統計情報があります。プロパティ
| 名前 | 説明 |
|---|---|
| 実行メソッド | 行実行では、演算子は一度に 1 行を処理します。バッチ実行では、演算子は一度に複数の行を処理します。 |
実行統計情報
| 名前 | 説明 |
|---|---|
| ローカル並列実行数 | 並行して実行されるサブクエリの数。 |
| リモート呼び出し | 実行されたリモート サブクエリの数。 |
| バッチ数 | バッチは、同時に処理される行の動的コレクションです。これは、分散クロス適用によって入力側からマップ側に送信されたバッチの数を示します。 |
| レイテンシ | 演算子で実行されたすべての実行の経過時間。 |
| 累積レイテンシ | 現在の演算子とその子孫の合計時間。 |
| CPU 時間 | 演算子の実行に費やされた CPU 時間の合計。 |
| 累積 CPU 時間 | オペレーターとその子孫の実行に費やされた合計 CPU 時間。 |
| 実行時間 | クエリの実行と結果の処理にかかった合計時間。 |
| 返された行数 | この演算子によって出力された行数 |
| 実行数 | 演算子が実行された回数。一部の実行は並行して実行できます。 |
分散クロス適用
次のクエリは、この演算子を示しています。
SELECT albumtitle
FROM songs
JOIN albums
ON albums.albumid = songs.albumid;
/*-----------------------+
| AlbumTitle |
+-----------------------+
| Green |
| Nothing To Do With Me |
| Play |
| Total Junk |
| Green |
+-----------------------*/
実行プランは次のように表示されます。
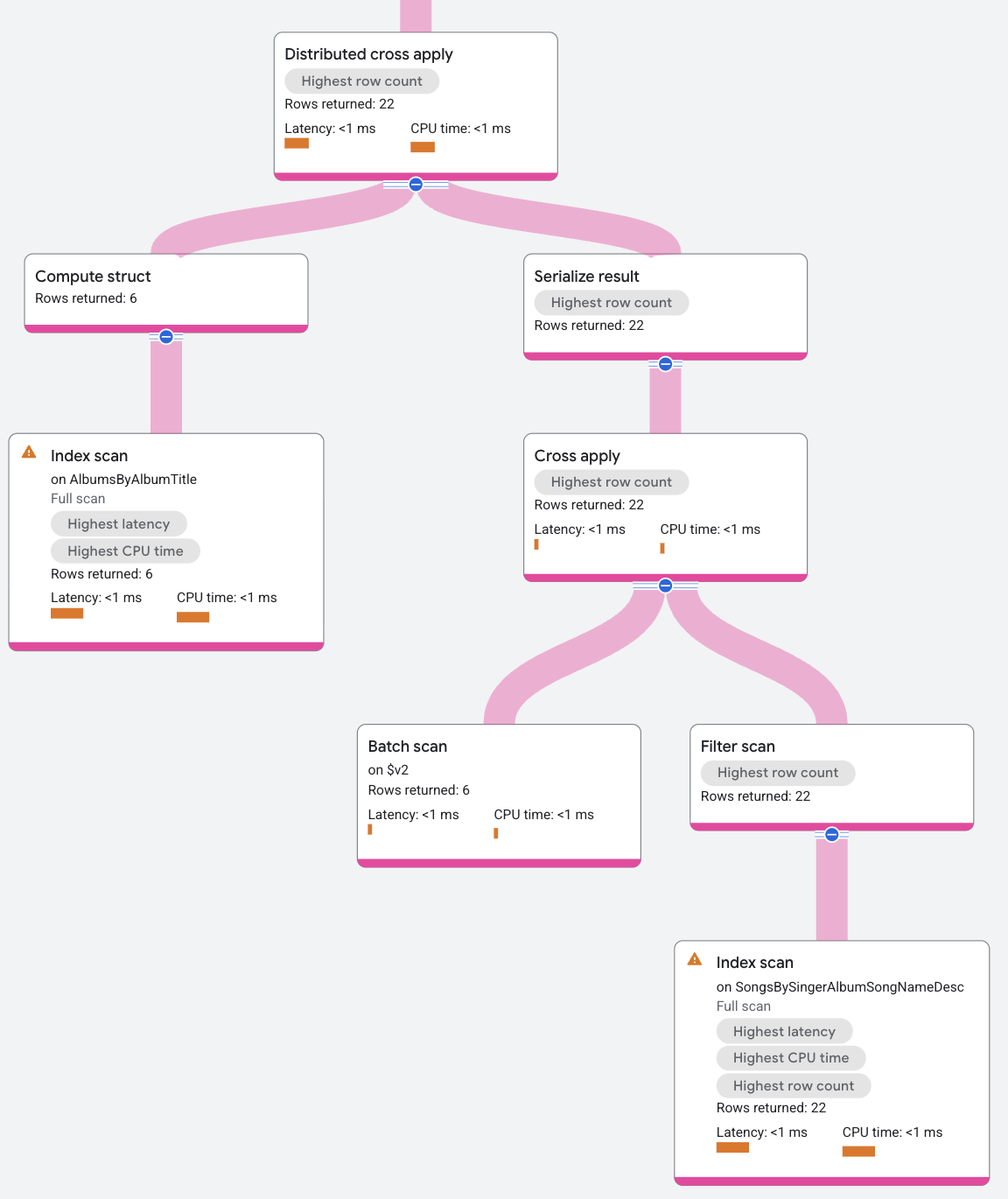
DCA の入力には、AlbumId の行のバッチを作成する SongsBySingerAlbumSongNameDesc インデックスに対するインデックス スキャンが含まれます。DCA のマップ側は標準のクロス適用です。入力は行のバッチで、マップ側はインデックス AlbumsByAlbumTitle に対するインデックス スキャンです。これは、入力行の AlbumId の述語の影響を受け、AlbumsByAlbumTitle インデックスの AlbumId キーと比較されます。マッピングの結果、バッチが作成された入力行の SingerId 値の SongName が返されます。
この例の DCA プロセスを要約すると、DCA の入力は Albums テーブルから抽出された行で、DCA の出力はインデックス スキャンのマップに一致する行になります。
分散外部適用
分散外部適用は、左外部結合セマンティクスを使用する DA です。セマンティクスの詳細については、外部適用をご覧ください。
次のクエリは、この演算子を示しています。
SELECT lastname,
concertdate
FROM singers LEFT OUTER join@{JOIN_TYPE=APPLY_JOIN} concerts
ON singers.singerid=concerts.singerid;
/*----------+-------------+
| LastName | ConcertDate |
+----------+-------------+
| Trentor | 2014-02-18 |
| Smith | 2011-09-03 |
| Smith | 2010-06-06 |
| Lomond | 2005-04-30 |
| Martin | 2015-11-04 |
| Richards | |
+----------+-------------*/
実行プランは次のように表示されます。
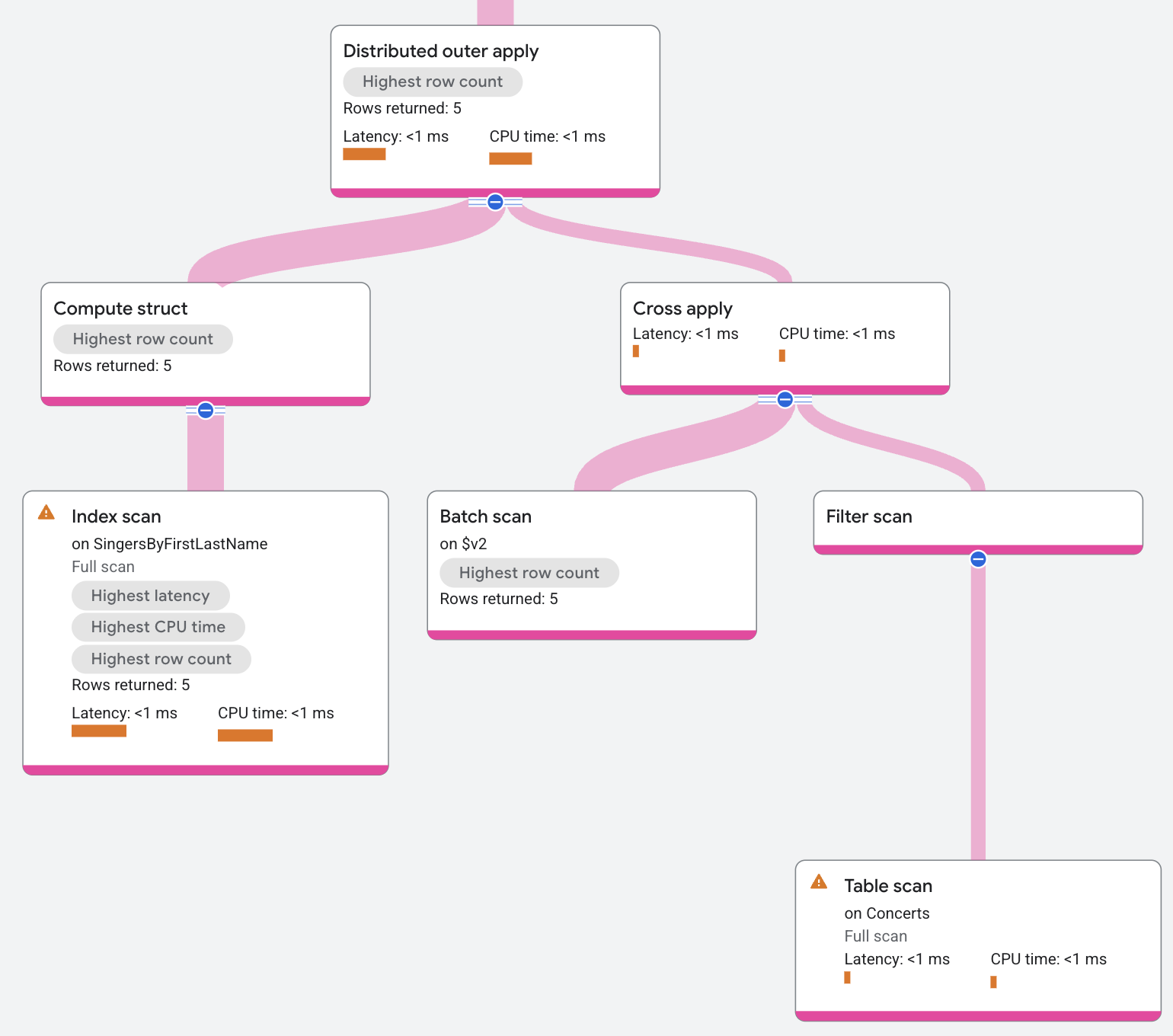
分散セミ適用
分散セミ適用は、セミ結合セマンティクスを持つ DA です。セマンティクスの詳細については、semi apply をご覧ください。
分散アンチセミ適用
分散アンチセミ適用は、アンチセミ結合セマンティクスを持つ DA です。セマンティクスの詳細については、anti-semi apply をご覧ください。
分散マージユニオン
分散マージユニオン演算子は、複数のリモート サーバー間でクエリを分散します。その後、クエリ結果を結合して、並べ替えられた結果を生成します。これは、分散マージソートと呼ばれます。
分散マージユニオンでは、次の処理が実行されます。
ルートサーバーは、クエリされたデータのスプリットをホストする各リモート サーバーにサブクエリを送信します。サブクエリには、結果を特定の順序で並べ替える指示が含まれています。
各リモート サーバーは、そのスプリットに対してサブクエリを実行し、結果をリクエストされた順序で返します。
ルートサーバーは、並べ替えられたサブクエリを統合して、完全に並べ替えられた結果を生成します。
Spanner バージョン 3 以降では、分散マージ結合がデフォルトで有効になっています。
プロパティと実行統計情報
演算子のプロパティは、演算子の実行時に使用される特性を表します。実行統計情報は、クエリ実行中に収集される値で、オペレーターのパフォーマンスを評価するのに役立ちます。
分散適用演算子には、追加の個別の実行統計情報があります。プロパティ
| 名前 | 説明 |
|---|---|
| 実行メソッド | 行実行では、演算子は一度に 1 行を処理します。バッチ実行では、演算子は一度に複数の行を処理します。 |
実行統計情報
| 名前 | 説明 |
|---|---|
| ローカル並列実行数 | 並行して実行されるサブクエリの数。 |
| リモート呼び出し | 実行されたリモート サブクエリの数。 |
| バッチ数 | バッチは、同時に処理される行の動的コレクションです。これは、分散クロス適用によって入力側からマップ側に送信されたバッチの数を示します。 |
| レイテンシ | 演算子で実行されたすべての実行の経過時間。 |
| 累積レイテンシ | 現在の演算子とその子孫の合計時間。 |
| CPU 時間 | 演算子の実行に費やされた CPU 時間の合計。 |
| 累積 CPU 時間 | オペレーターとその子孫の実行に費やされた合計 CPU 時間。 |
| 実行時間 | クエリの実行と結果の処理にかかった合計時間。 |
| 返された行数 | この演算子によって出力された行数 |
| 実行数 | 演算子が実行された回数。一部の実行は並行して実行できます。 |
プッシュ ブロードキャストのハッシュ結合
プッシュ ブロードキャストのハッシュ結合演算子は、分散ハッシュ結合ベースで行う SQL 結合です。プッシュ ブロードキャストのハッシュ結合演算子は、入力側から行を読み取り、データのバッチを作成します。演算子は、マップ側のデータを含むすべてのサーバーにそのバッチをブロードキャストします。データのバッチを受信する宛先サーバーでは、演算子はバッチをビルド側のデータとして使用してハッシュ結合を構築し、ハッシュ結合のプローブ側としてローカルデータをスキャンします。
プッシュ ブロードキャストのハッシュ結合には、次の利点があります。
- ビルドテーブルが小さい場合は、すべてのマップサイド分割に送信できます。
- マップサイドテーブルは、残余フィルタの有無にかかわらずスキャンできます。これは、結合キーがマップテーブルの主キーと同じでない場合に発生します。
オプティマイザーでは、プッシュ ブロードキャストのハッシュ結合は自動的には選択されません。この演算子を使用するには、次の例に示すように、クエリヒントの結合メソッドを PUSH_BROADCAST_HASH_JOIN に設定します。
SELECT a.albumtitle,
s.songname
FROM albums AS a join@{join_method=push_broadcast_hash_join} songs AS s
ON a.singerid = s.singerid
AND a.albumid = s.albumid;
/*-----------------------+--------------------------+
| AlbumTitle | SongName |
+-----------------------+--------------------------+
| Green | The Second Time |
| Green | Starting Again |
| Green | Nothing Is The Same |
| Green | Let's Get Back Together |
| Green | I Knew You Were Magic |
| Green | Blue |
| Green | 42 |
| Terrified | Fight Story |
| Nothing To Do With Me | Not About The Guitar |
+-----------------------+--------------------------*/
実行プランは次のように表示されます。
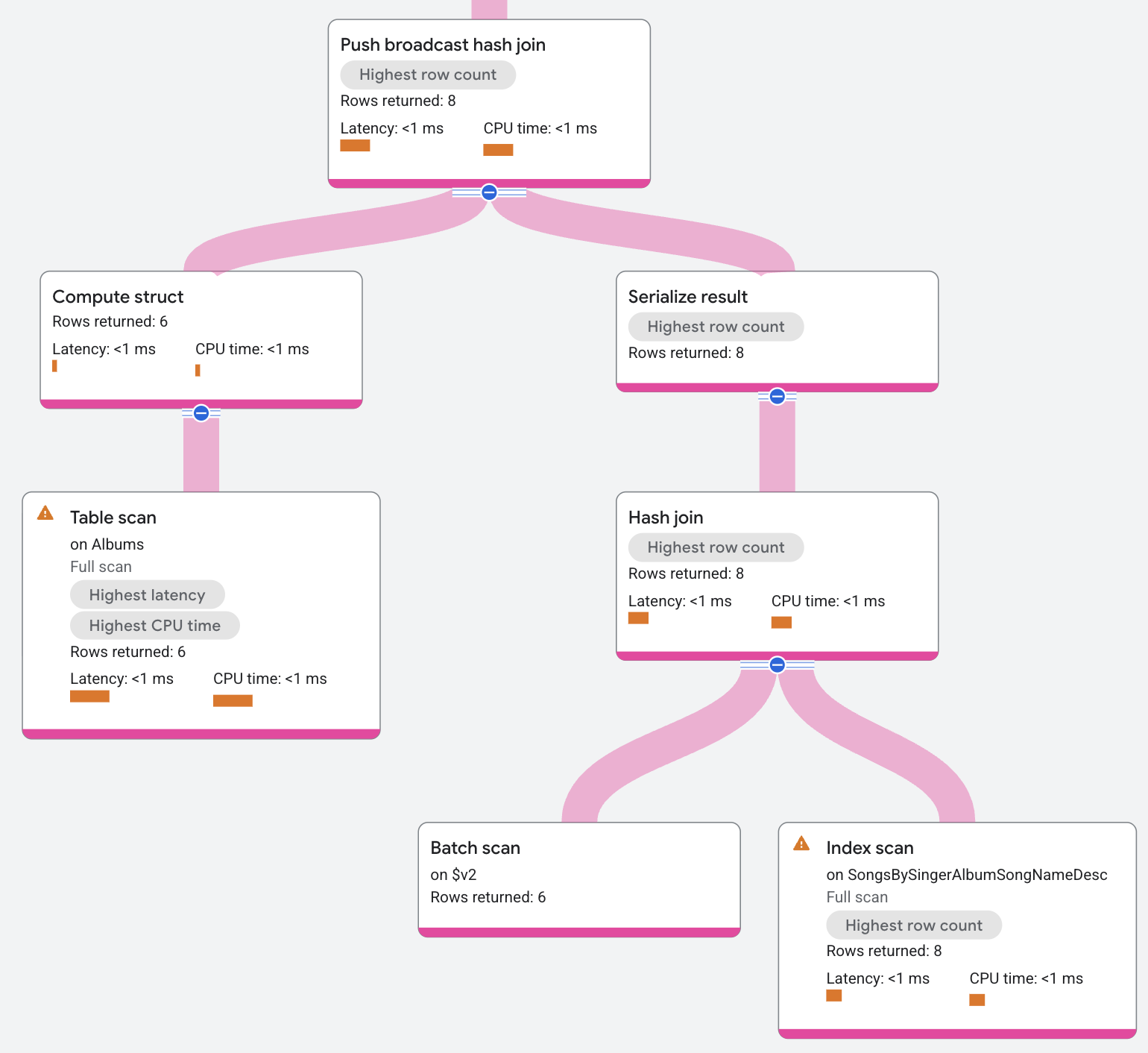
プッシュ ブロードキャストのハッシュ結合への入力は AlbumsByAlbumTitle インデックスです。この演算子は、この入力をデータのバッチにシリアル化します。演算子は、そのバッチをインデックス SongsBySingerAlbumSongNameDesc のすべてのローカル スプリットに送信します。演算子は、バッチをシリアル化解除し、ハッシュ テーブルを作成します。ハッシュ テーブルは、ローカル インデックス データをプローブとして使用し、一致した結果を返します。
一致した結果は、残余条件でフィルタリングされてから返される場合があります(たとえば、非等値結合に残余条件がある場合)。
プロパティと実行統計情報
演算子のプロパティは、演算子の実行時に使用される特性を表します。実行統計情報は、クエリ実行中に収集される値で、オペレーターのパフォーマンスを評価するのに役立ちます。
分散適用演算子には、追加の個別の実行統計情報があります。プロパティ
| 名前 | 説明 |
|---|---|
| 実行メソッド | 行実行では、演算子は一度に 1 行を処理します。バッチ実行では、演算子は一度に複数の行を処理します。 |
実行統計情報
| 名前 | 説明 |
|---|---|
| ローカル並列実行数 | 並行して実行されるサブクエリの数。 |
| リモート呼び出し | 実行されたリモート サブクエリの数。 |
| バッチ数 | バッチは、同時に処理される行の動的コレクションです。これは、分散クロス適用によって入力側からマップ側に送信されたバッチの数を示します。 |
| レイテンシ | 演算子で実行されたすべての実行の経過時間。 |
| 累積レイテンシ | 現在の演算子とその子孫の合計時間。 |
| CPU 時間 | 演算子の実行に費やされた CPU 時間の合計。 |
| 累積 CPU 時間 | オペレーターとその子孫の実行に費やされた合計 CPU 時間。 |
| 実行時間 | クエリの実行と結果の処理にかかった合計時間。 |
| 返された行数 | この演算子によって出力された行数 |
| 実行数 | 演算子が実行された回数。一部の実行は並行して実行できます。 |