
2 項演算子には、関係する子が 2 つあります。次の演算子が 2 項演算子になります。
データベース スキーマ
このページのクエリと実行プランは、次のデータベース スキーマに基づいています。
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY(SingerId);
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
MarketingBudget INT64
) PRIMARY KEY(SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget);
CREATE TABLE Songs (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
TrackId INT64 NOT NULL,
SongName STRING(MAX),
Duration INT64,
SongGenre STRING(25)
) PRIMARY KEY(SingerId, AlbumId, TrackId),
INTERLEAVE IN PARENT Albums ON DELETE CASCADE;
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC), INTERLEAVE IN Albums;
CREATE INDEX SongsBySongName ON Songs(SongName);
CREATE TABLE Concerts (
VenueId INT64 NOT NULL,
SingerId INT64 NOT NULL,
ConcertDate DATE NOT NULL,
BeginTime TIMESTAMP,
EndTime TIMESTAMP,
TicketPrices ARRAY<INT64>
) PRIMARY KEY(VenueId, SingerId, ConcertDate);
次のデータ操作言語(DML)ステートメントを使用して、これらのテーブルにデータを追加できます。
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate)
VALUES (1, "Marc", "Richards", "1970-09-03"),
(2, "Catalina", "Smith", "1990-08-17"),
(3, "Alice", "Trentor", "1991-10-02"),
(4, "Lea", "Martin", "1991-11-09"),
(5, "David", "Lomond", "1977-01-29");
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle)
VALUES (1, 1, "Total Junk"),
(1, 2, "Go, Go, Go"),
(2, 1, "Green"),
(2, 2, "Forever Hold Your Peace"),
(2, 3, "Terrified"),
(3, 1, "Nothing To Do With Me"),
(4, 1, "Play");
INSERT INTO Songs (SingerId, AlbumId, TrackId, SongName, Duration, SongGenre)
VALUES (2, 1, 1, "Let's Get Back Together", 182, "COUNTRY"),
(2, 1, 2, "Starting Again", 156, "ROCK"),
(2, 1, 3, "I Knew You Were Magic", 294, "BLUES"),
(2, 1, 4, "42", 185, "CLASSICAL"),
(2, 1, 5, "Blue", 238, "BLUES"),
(2, 1, 6, "Nothing Is The Same", 303, "BLUES"),
(2, 1, 7, "The Second Time", 255, "ROCK"),
(2, 3, 1, "Fight Story", 194, "ROCK"),
(3, 1, 1, "Not About The Guitar", 278, "BLUES");
結合を適用
適用結合は、Spanner で使用される主要な結合演算子です。適用結合演算子は行単位で処理を行いますが、ハッシュ結合などの演算子はセット単位で処理を行います。適用演算子には、入力(左の子)とマップ(右の子)という 2 つの入力があります。適用演算子は、適用メソッド(cross、outer、semi、anti-semi)を使用して、入力側の各行をマップ側に適用します。また、適用結合のバリエーションも、分散適用のマップ側に表示されます。
Apply 結合演算子は、次の場合に最も効率的です。
- 入力のカーディナリティが低い。
- 結合キーは、マップサイドの主キーの接頭辞です。
- このクエリは、2 つのインターリーブ テーブルを結合します。
プロパティと実行統計情報
演算子のプロパティは、演算子の実行時に使用される特性を表します。実行統計情報は、クエリ実行中に収集される値で、オペレーターのパフォーマンスを評価するのに役立ちます。
プロパティ
| 名前 | 説明 |
|---|---|
| 実行メソッド | 行実行では、演算子は一度に 1 行を処理します。バッチ実行では、演算子は一度に複数の行を処理します。 |
実行統計情報
| 名前 | 説明 |
|---|---|
| レイテンシ | 演算子で実行されたすべての実行の経過時間。 |
| 累積レイテンシ | 現在の演算子とその子孫の合計時間。 |
| CPU 時間 | 演算子の実行に費やされた CPU 時間の合計。 |
| 累積 CPU 時間 | オペレーターとその子孫の実行に費やされた合計 CPU 時間。 |
| 実行時間 | クエリの実行と結果の処理にかかった合計時間。 |
| 返された行数 | この演算子によって出力された行数 |
| 実行数 | 演算子が実行された回数。一部の実行は並行して実行できます。 |
クロス適用
クロス適用は、一致する行のみが返される内部結合を実行します。
次のクエリは、この演算子を示しています。
このクエリは、歌手の名前とその歌手の曲名の 1 つを取得します。
SELECT si.firstname,
(SELECT so.songname
FROM songs AS so
WHERE so.singerid = si.singerid
LIMIT 1)
FROM singers AS si;
/*-----------+--------------------------+
| FirstName | Unspecified |
+-----------+--------------------------+
| Alice | Not About The Guitar |
| Catalina | Let's Get Back Together |
| David | NULL |
| Lea | NULL |
| Marc | NULL |
+-----------+--------------------------*/
このクエリは、最初の列に Singers テーブルのデータを入力し、2 番目の列に Songs テーブルのデータを入力します。SingerId が Singers テーブルに存在していますが、Songs テーブルに該当する SingerId が存在しないため、2 番目の列に NULL が入っています。
実行プランは次のように始まります。
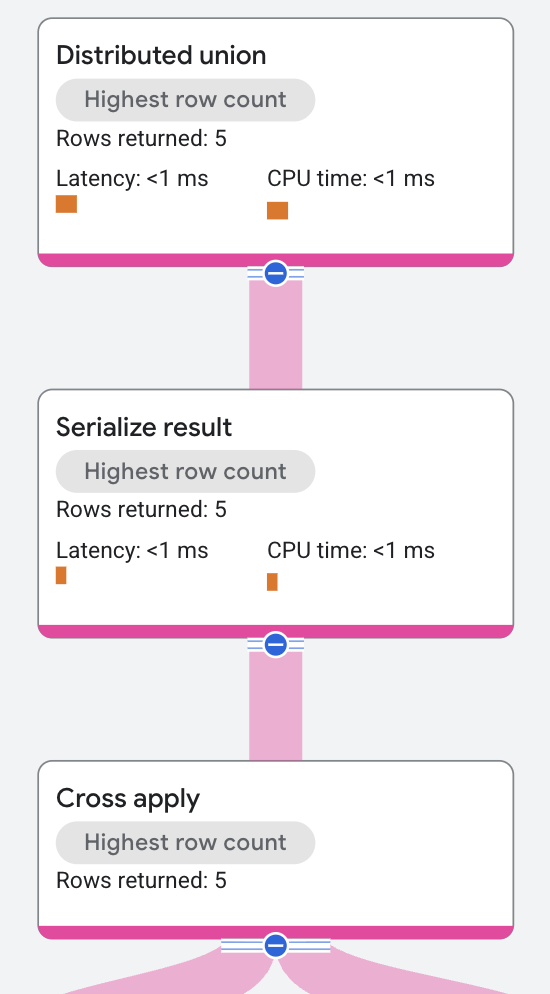
最上位ノードは分散ユニオン演算子です。分散ユニオン演算子は、サブプランをリモート サーバーに分散します。サブプランに含まれている結果のシリアル化演算子が歌手の名前とその歌手の曲名を計算し、出力の各行にまとめて出力します。
結果のシリアル化演算子は、クロス適用演算子から入力を受信します。クロス適用演算子の入力側は Singers テーブルのテーブル スキャンです。
実行プランは次のようになります。
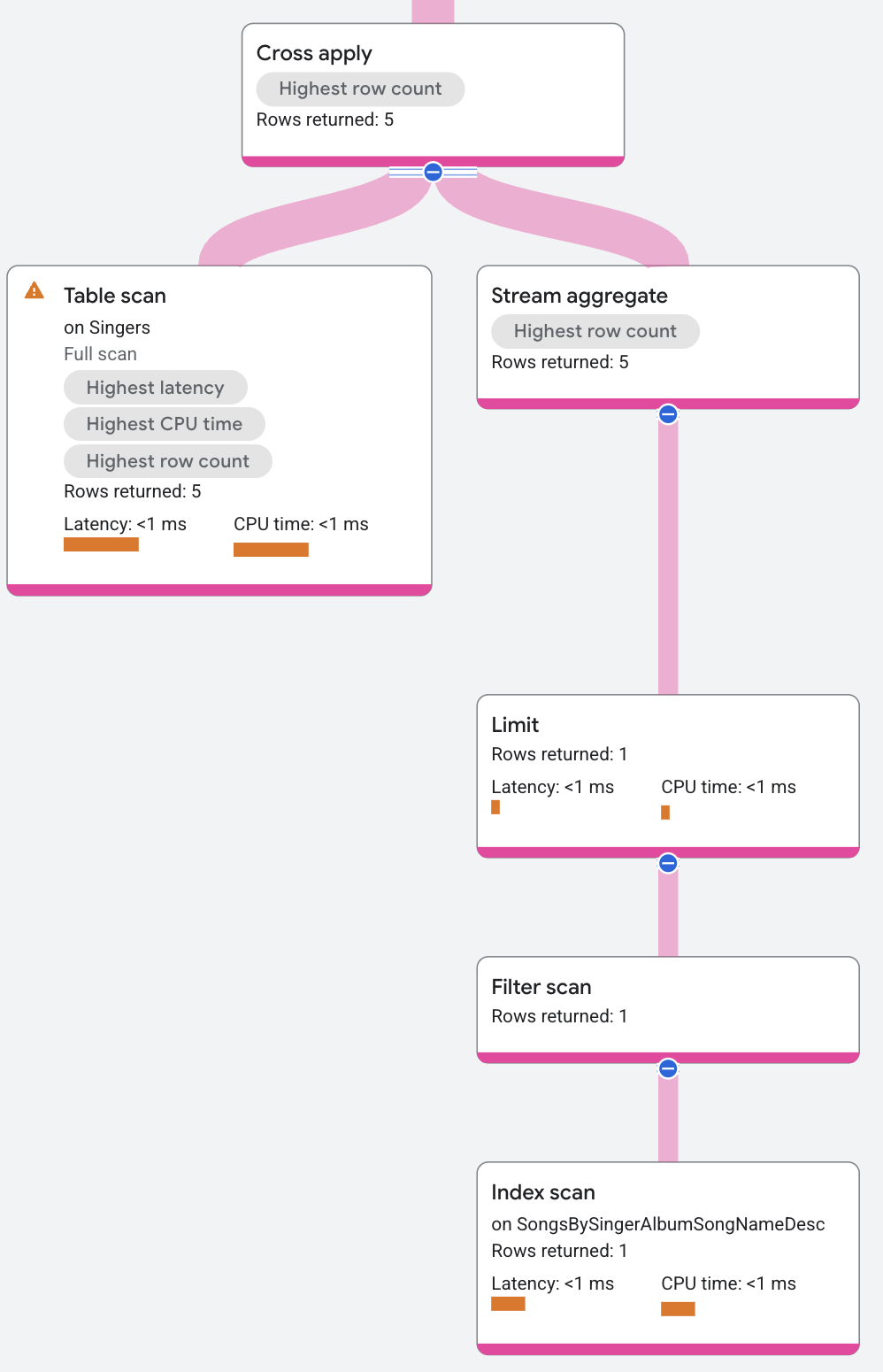
クロス適用演算のマップ側には、次のものが上から順に含まれます。
- 集計演算子。
Songs.SongNameを返します。 - 制限演算子。1 人の歌手につき、返される曲数を 1 に制限しています。
SongsBySingerAlbumSongNameDescインデックスのインデックス スキャン。
クロス適用演算子は、入力側のマップとマップ側で SingerId が同じ行を関連付けます。クロス適用演算子の出力は、入力行からの FirstName 値とマップ行からの SongName 値になります。SingerId に一致するマップ行がない場合、SongName 値は NULL になります。実行プランの最上位にある分散ユニオン演算子は、リモート サーバーからの出力行をすべて結合し、クエリ結果として返します。
外部適用
外部適用は左外部結合セマンティクスを提供します。マップ側で実行するたびに必要に応じて行に NULL を埋め込み、必ず 1 つ以上の行を返します。
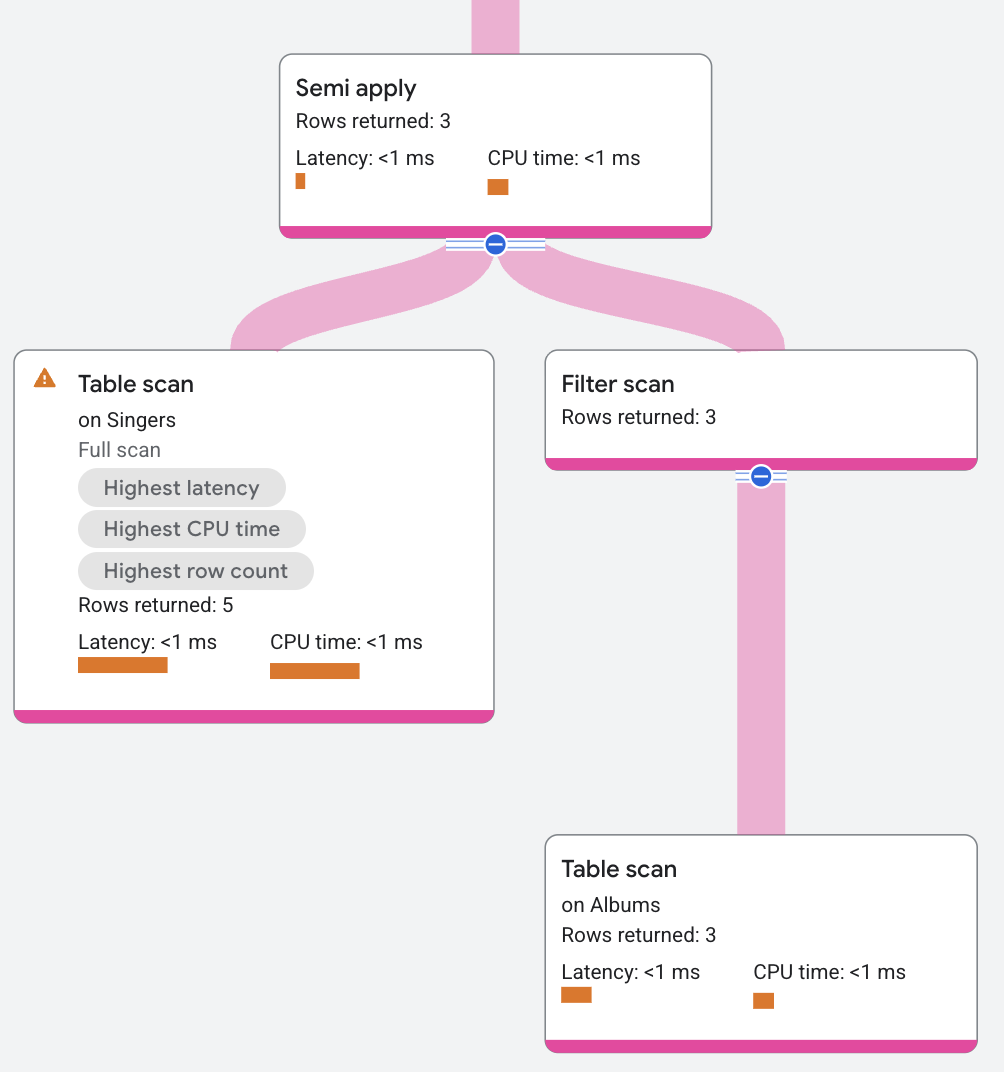
セミ適用
セミ適用演算子は、マップ側で一致が発生した場合にのみ入力列を返します。
次のクエリは、セミ結合を使用して、アルバムを持っている歌手を検索します。
SELECT
FirstName,
LastName
FROM
Singers
WHERE
SingerId IN (
SELECT
SingerId
FROM
Albums);
/*-----------+----------+
| FirstName | LastName |
+-----------+----------+
| Marc | Richards |
| Catalina | Smith |
| Alice | Trentor |
| Lea | Martin |
+-----------+----------*/
プラン セグメントは次のように表示されます。
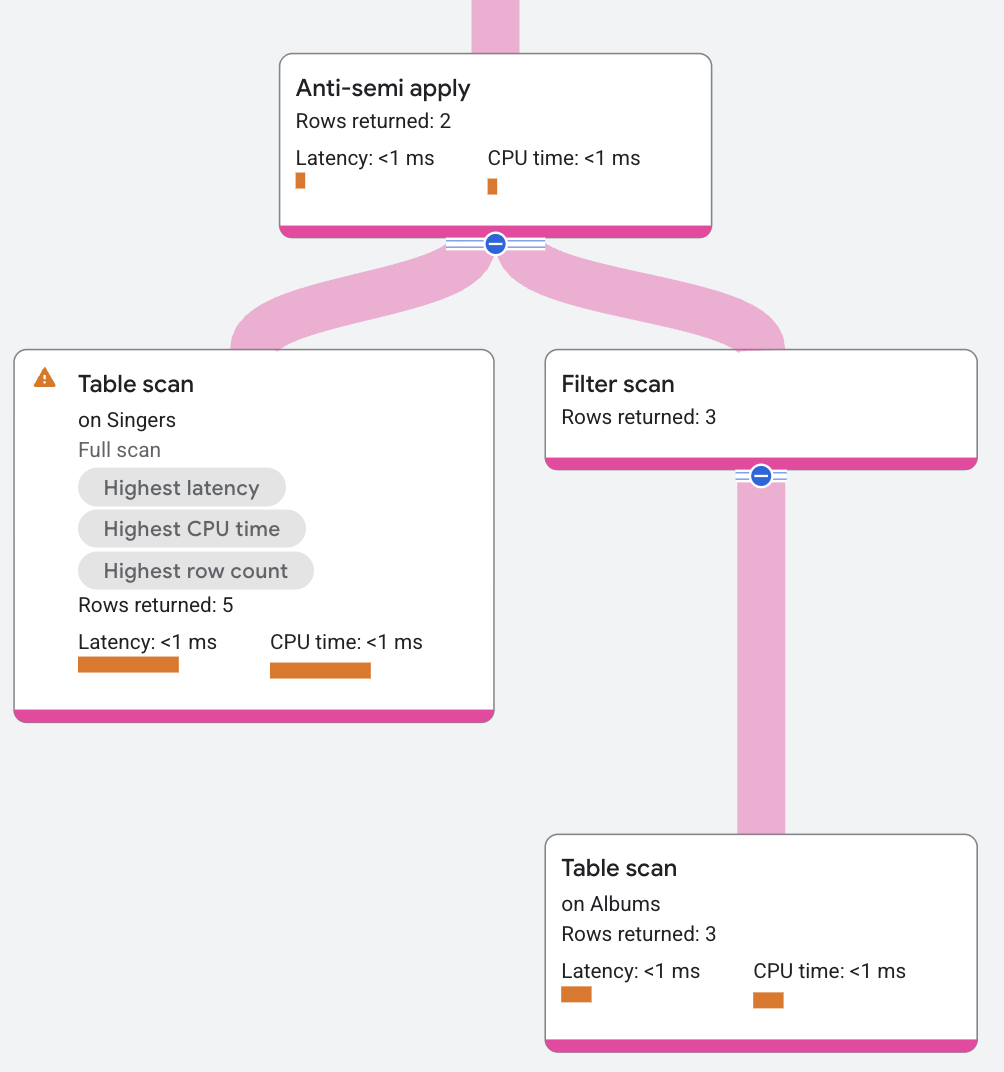
アンチセミ適用
アンチセミ適用演算子は、マップ側で一致が発生しない場合にのみ入力テーブルの列を返す点が、セミ適用演算子と異なります。
次のクエリは、アンチセミ結合を使用して、アルバムがない歌手を検索します。
SELECT
FirstName,
LastName
FROM
Singers
WHERE
SingerId NOT IN (
SELECT
SingerId
FROM
Albums);
/*-----------+----------+
| FirstName | LastName |
+-----------+----------+
| David | Lomond |
+-----------+----------*/
プラン セグメントは次のように表示されます。
ハッシュ結合
ハッシュ結合演算子はハッシュベースで行う SQL 結合です。ハッシュ結合はセット単位の処理を実行します。ハッシュ結合演算子は、build(左の子)とマークされた入力行を読み取り、結合条件に基づいてハッシュ テーブルに挿入します。次に、probe(右の子)とマークされた行を読み取ります。ハッシュ結合演算子は、プローブ入力から読み取った各行に対して、ハッシュ テーブル内で一致する行を探します。一致した行を結果として返します。
ハッシュ結合には次の利点があります。
- 入力の並べ替えは必要ありません
- ハッシュテーブルの作成時にブルーム フィルタを計算します。この演算子は、フィルタを使用して、一致するものが存在しないプローブ側の行を除外します。これはシーク フィルタではなく、残差フィルタです。
次のクエリは、この演算子を示しています。
SELECT a.albumtitle,
s.songname
FROM albums AS a join@{join_method=hash_join} songs AS s
ON a.singerid = s.singerid
AND a.albumid = s.albumid;
/*-----------------------+--------------------------+
| AlbumTitle | SongName |
+-----------------------+--------------------------+
| Nothing To Do With Me | Not About The Guitar |
| Green | The Second Time |
| Green | Starting Again |
| Green | Nothing Is The Same |
| Green | Let's Get Back Together |
| Green | I Knew You Were Magic |
| Green | Blue |
| Green | 42 |
| Terrified | Fight Story |
+-----------------------+--------------------------*/
実行プランのセグメントは次のようになります。
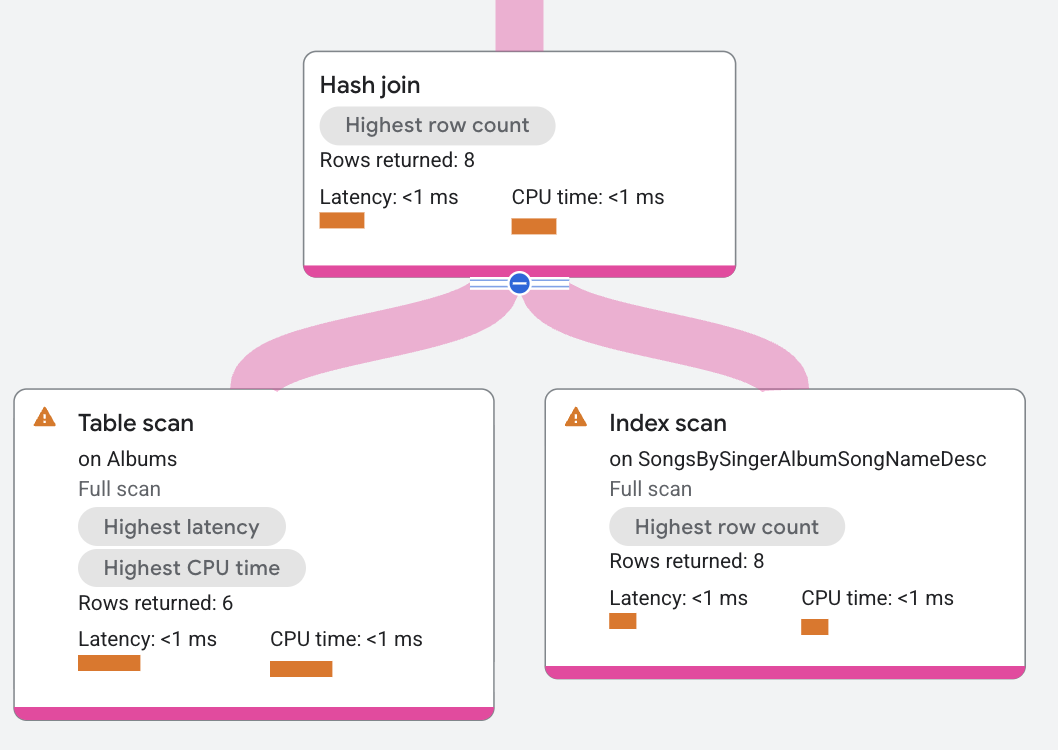
この実行プランで、ビルドはテーブル Albums に対するスキャンを分散する分散ユニオンです。プローブは、インデックス SongsBySingerAlbumSongNameDesc に対するスキャンを分散する分散ユニオン演算子です。ハッシュ結合演算子がビルド側からすべての行を読み取ります。各ビルド行が、条件 a.SingerId =
s.SingerId AND a.AlbumId = s.AlbumId の列に基づいてハッシュ テーブルに配置されます。次に、ハッシュ結合演算子はプローブ側からすべての行を読み取ります。各プローブ行に対して、ハッシュ結合演算子はハッシュ テーブル内で一致する行を探し、一致した結果を返します。
ハッシュ テーブルで一致した結果は、残余条件でフィルタリングされてから返される場合があります(たとえば、非等値結合に残余条件がある場合)。ハッシュ結合の実行プランは、メモリ管理や結合が一定でないため、複雑になる可能性があります。メインのハッシュ結合アルゴリズムが内部結合、半結合、反結合、外部結合の変数処理に使用されます。
プロパティと実行統計情報
演算子のプロパティは、演算子の実行時に使用される特性を表します。実行統計情報は、クエリ実行中に収集される値で、オペレーターのパフォーマンスを評価するのに役立ちます。
プロパティ
| 名前 | 説明 |
|---|---|
| 実行メソッド | 行実行では、演算子は一度に 1 行を処理します。バッチ実行では、演算子は一度に複数の行を処理します。 |
実行統計情報
| 名前 | 説明 |
|---|---|
| レイテンシ | 演算子で実行されたすべての実行の経過時間。 |
| 累積レイテンシ | 現在の演算子とその子孫の合計時間。 |
| CPU 時間 | 演算子の実行に費やされた CPU 時間の合計。 |
| 累積 CPU 時間 | オペレーターとその子孫の実行に費やされた合計 CPU 時間。 |
| 実行時間 | クエリの実行と結果の処理にかかった合計時間。 |
| 返された行数 | この演算子によって出力された行数 |
| 実行数 | 演算子が実行された回数。一部の実行は並行して実行できます。 |
マージ結合
マージ結合演算子はマージベースで行う SQL 結合です。結合の両側は、結合条件で使用される列の順に並んだ行を生成します。マージ結合は、両方の入力ストリームを並行して使用し、結合条件が満たされると行を出力します。入力が並べ替えられていない場合、オプティマイザーは明示的に Sort 演算子をプランに追加します。
マージ結合には次の利点があります。
- データがすでに並べ替えられている場合、メモリは必要ありません。
- データが並べ替えられていない場合でも、分散結合では、ルートに大きなハッシュテーブルを作成するのではなく、個々の分割で並べ替えを実行できます。
マージ結合は、オプティマイザーによって自動的に選択されることはありません。この演算子を使用するには、次の例に示すように、クエリヒントの結合メソッドを MERGE_JOIN に設定します。
SELECT a.albumtitle,
s.songname
FROM albums AS a join@{join_method=merge_join} songs AS s
ON a.singerid = s.singerid
AND a.albumid = s.albumid;
/*-----------------------+--------------------------+
| AlbumTitle | SongName |
+-----------------------+--------------------------+
| Green | The Second Time |
| Green | Starting Again |
| Green | Nothing Is The Same |
| Green | Let's Get Back Together |
| Green | I Knew You Were Magic |
| Green | Blue |
| Green | 42 |
| Terrified | Fight Story |
| Nothing To Do With Me | Not About The Guitar |
+-----------------------+--------------------------*/
実行プランは次のように表示されます。
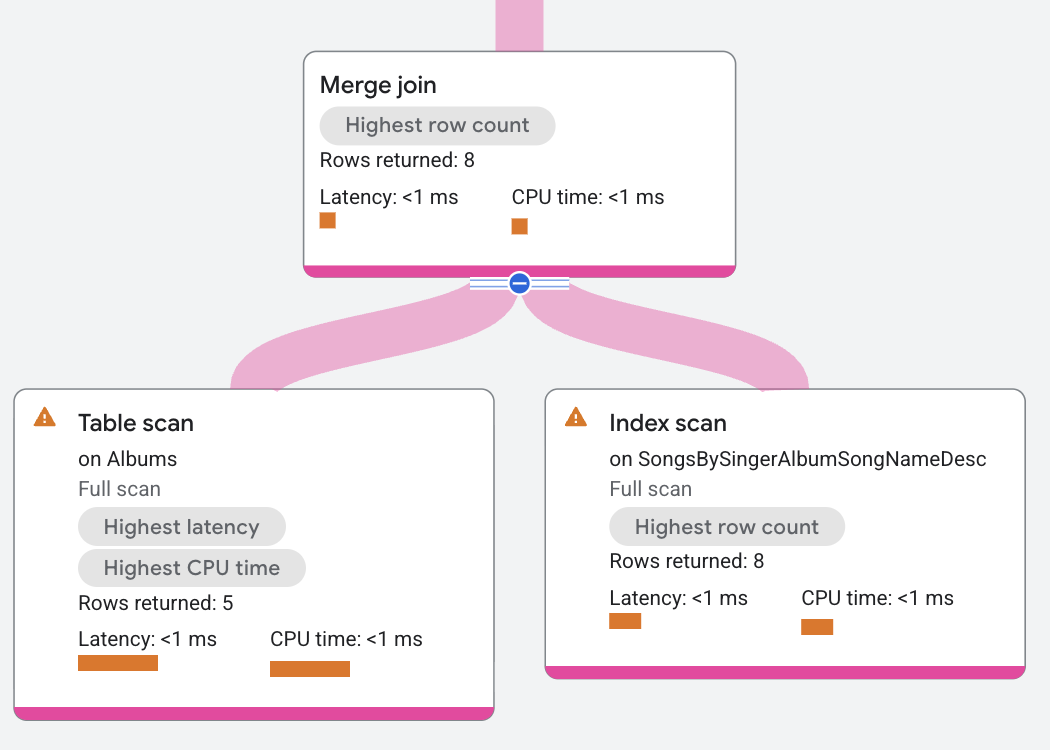
この実行プランでは、データが存在する場所で結合が行われるようにマージ結合が分散されます。また、両方のテーブル スキャンはあらかじめ結合条件の SingerId と AlbumId によってソートされるため、この例のマージ結合は、追加の並べ替え演算子を導入しなくても動作します。このプランでは、Albums テーブルの左側のスキャンは、左側の SingerId、AlbumId が右側のスキャンの SingerId_1、AlbumId_1 の値よりも少ない場合に進みます。同様に、右側のスキャンは、その値が左側のスキャンの値よりも小さい場合に進みます。こうして、一致する行を返すことができるよう、等値を検索し続ける形でマージが進みます。
次のクエリを使用して、マージ結合の例を考えてみましょう。
SELECT a.albumtitle,
s.songname
FROM albums AS a join@{join_method=merge_join} songs AS s
ON a.albumid = s.albumid;
/*-----------------------+--------------------------+
| AlbumTitle | SongName |
+-----------------------+--------------------------+
| Total Junk | The Second Time |
| Total Junk | Starting Again |
| Total Junk | Nothing Is The Same |
| Total Junk | Let's Get Back Together |
| Total Junk | I Knew You Were Magic |
| Total Junk | Blue |
| Total Junk | 42 |
| Total Junk | Not About The Guitar |
| Green | The Second Time |
| Green | Starting Again |
| Green | Nothing Is The Same |
| Green | Let's Get Back Together |
| Green | I Knew You Were Magic |
| Green | Blue |
| Green | 42 |
| Green | Not About The Guitar |
| Nothing To Do With Me | The Second Time |
| Nothing To Do With Me | Starting Again |
| Nothing To Do With Me | Nothing Is The Same |
| Nothing To Do With Me | Let's Get Back Together |
| Nothing To Do With Me | I Knew You Were Magic |
| Nothing To Do With Me | Blue |
| Nothing To Do With Me | 42 |
| Nothing To Do With Me | Not About The Guitar |
| Play | The Second Time |
| Play | Starting Again |
| Play | Nothing Is The Same |
| Play | Let's Get Back Together |
| Play | I Knew You Were Magic |
| Play | Blue |
| Play | 42 |
| Play | Not About The Guitar |
| Terrified | Fight Story |
+-----------------------+--------------------------*/
実行プランは次のように表示されます。
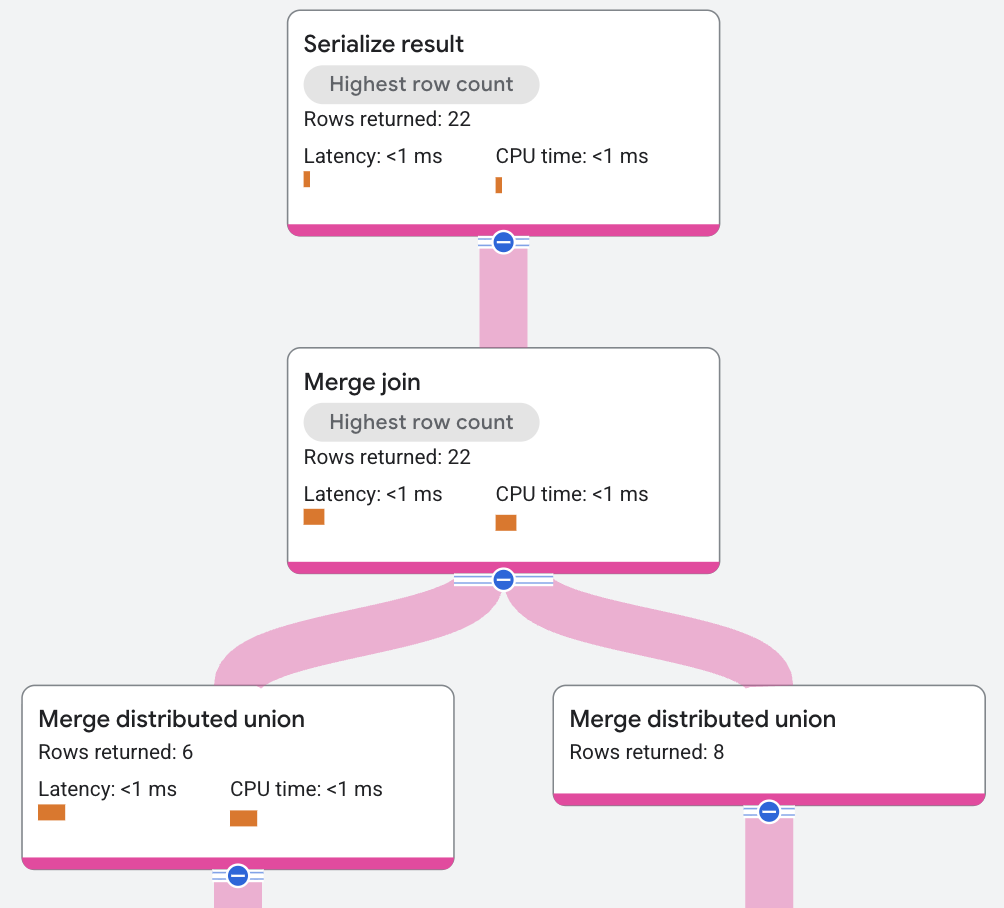
上記の実行プランでは、マージ結合を実行するために、クエリ オプティマイザーによって追加の並べ替え演算子が導入されています。この例のクエリの JOIN 条件は AlbumId の条件のみでデータの格納方法ではありません。よって、並べ替えを追加する必要があります。クエリエンジンは分散マージ アルゴリズムをサポートしており、並べ替えをグローバルではなくローカルで実行することで、CPU コストを分散して並列化します。
一致した結果は、残余条件でフィルタリングされることもあります。たとえば、非等値結合に残余条件があります。マージ結合プランは、追加の並べ替え要件が原因で複雑になる場合があります。メインのマージ結合アルゴリズムは、内部結合、半結合、反結合、外部結合の変数を処理します。
プロパティと実行統計情報
演算子のプロパティは、演算子の実行時に使用される特性を表します。実行統計情報は、クエリ実行中に収集される値で、オペレーターのパフォーマンスを評価するのに役立ちます。
プロパティ
| 名前 | 説明 |
|---|---|
| 実行メソッド | 行実行では、演算子は一度に 1 行を処理します。バッチ実行では、演算子は一度に複数の行を処理します。 |
実行統計情報
| 名前 | 説明 |
|---|---|
| レイテンシ | 演算子で実行されたすべての実行の経過時間。 |
| 累積レイテンシ | 現在の演算子とその子孫の合計時間。 |
| CPU 時間 | 演算子の実行に費やされた CPU 時間の合計。 |
| 累積 CPU 時間 | オペレーターとその子孫の実行に費やされた合計 CPU 時間。 |
| 実行時間 | クエリの実行と結果の処理にかかった合計時間。 |
| 返された行数 | この演算子によって出力された行数 |
| 実行数 | 演算子が実行された回数。一部の実行は並行して実行できます。 |
再帰ユニオン
再帰ユニオン演算子は、2 つの入力の結合を実行します。1 つは base ケースを表し、もう 1 つは recursive ケースを表します。これは、定量化されたパス走査を含むグラフクエリで使用されます。ベース入力は最初に 1 回だけ処理されます。再帰が終了するまで、再帰入力が処理されます。再帰は、上限(指定されている場合)に達するか、再帰で新しい結果が生成されなくなると終了します。次の例では、Collaborations テーブルがスキーマに追加され、MusicGraph というプロパティ グラフが作成されます。
CREATE TABLE Collaborations (
SingerId INT64 NOT NULL,
FeaturingSingerId INT64 NOT NULL,
AlbumTitle STRING(MAX) NOT NULL,
) PRIMARY KEY(SingerId, FeaturingSingerId, AlbumTitle);
CREATE OR REPLACE PROPERTY GRAPH MusicGraph
NODE TABLES(
Singers
KEY(SingerId)
LABEL Singers PROPERTIES(
BirthDate,
FirstName,
LastName,
SingerId,
SingerInfo)
)
EDGE TABLES(
Collaborations AS CollabWith
KEY(SingerId, FeaturingSingerId, AlbumTitle)
SOURCE KEY(SingerId) REFERENCES Singers(SingerId)
DESTINATION KEY(FeaturingSingerId) REFERENCES Singers(SingerId)
LABEL CollabWith PROPERTIES(
AlbumTitle,
FeaturingSingerId,
SingerId),
);
次のグラフクエリは、特定の歌手とコラボレーションした歌手、またはそのコラボレーションした歌手を見つけます。
GRAPH MusicGraph
MATCH (singer:Singers {singerId:42})-[c:CollabWith]->{1,2}(featured:Singers)
RETURN singer.SingerId AS singer, featured.SingerId AS featured
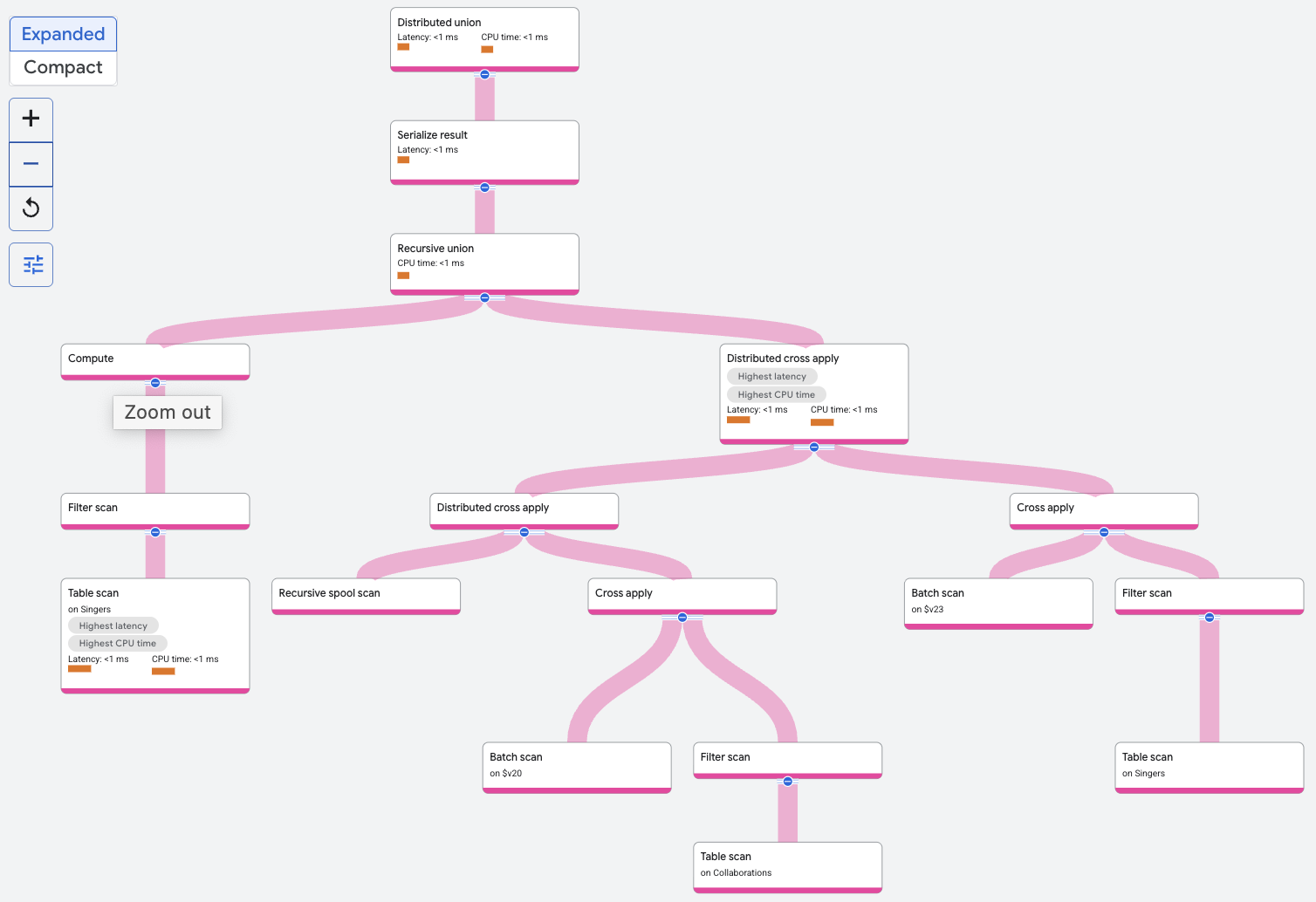
再帰ユニオン演算子は、Singers テーブルをフィルタして、指定された SingerId を持つ歌手を見つけます。これは、再帰ユニオンの基本入力です。再帰結合への再帰入力は、Collaborations テーブルを結合の前の反復処理の結果と繰り返し結合する、他のクエリに対する分散クロス適用または他の結合演算子で構成されます。ベース入力の行が 0 回目の反復処理を形成します。反復処理ごとに、反復処理の出力が再帰スプール スキャンによって保存されます。再帰スプール スキャンの行は、spoolscan.featuredSingerId = Collaborations.SingerId の Collaborations テーブルと結合されます。2 回目の反復処理が完了すると、再帰は終了します。これは、クエリで指定された上限です。
プロパティと実行統計情報
演算子のプロパティは、演算子の実行時に使用される特性を表します。実行統計情報は、クエリ実行中に収集される値で、オペレーターのパフォーマンスを評価するのに役立ちます。
プロパティ
| 名前 | 説明 |
|---|---|
| 実行メソッド | 行実行では、演算子は一度に 1 行を処理します。バッチ実行では、演算子は一度に複数の行を処理します。 |
実行統計情報
| 名前 | 説明 |
|---|---|
| レイテンシ | 演算子で実行されたすべての実行の経過時間。 |
| 累積レイテンシ | 現在の演算子とその子孫の合計時間。 |
| CPU 時間 | 演算子の実行に費やされた CPU 時間の合計。 |
| 累積 CPU 時間 | オペレーターとその子孫の実行に費やされた合計 CPU 時間。 |
| 実行時間 | クエリの実行と結果の処理にかかった合計時間。 |
| 返された行数 | この演算子によって出力された行数 |
| 実行数 | 演算子が実行された回数。一部の実行は並行して実行できます。 |