
リーフ演算子には子はありません。リーフ演算子には次の種類があります。
データベース スキーマ
このページのクエリと実行プランは、次のデータベース スキーマに基づいています。
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY(SingerId);
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
MarketingBudget INT64
) PRIMARY KEY(SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget);
CREATE TABLE Songs (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
TrackId INT64 NOT NULL,
SongName STRING(MAX),
Duration INT64,
SongGenre STRING(25)
) PRIMARY KEY(SingerId, AlbumId, TrackId),
INTERLEAVE IN PARENT Albums ON DELETE CASCADE;
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC), INTERLEAVE IN Albums;
CREATE INDEX SongsBySongName ON Songs(SongName);
CREATE TABLE Concerts (
VenueId INT64 NOT NULL,
SingerId INT64 NOT NULL,
ConcertDate DATE NOT NULL,
BeginTime TIMESTAMP,
EndTime TIMESTAMP,
TicketPrices ARRAY<INT64>
) PRIMARY KEY(VenueId, SingerId, ConcertDate);
次のデータ操作言語(DML)ステートメントを使用して、これらのテーブルにデータを追加できます。
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate)
VALUES (1, "Marc", "Richards", "1970-09-03"),
(2, "Catalina", "Smith", "1990-08-17"),
(3, "Alice", "Trentor", "1991-10-02"),
(4, "Lea", "Martin", "1991-11-09"),
(5, "David", "Lomond", "1977-01-29");
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle)
VALUES (1, 1, "Total Junk"),
(1, 2, "Go, Go, Go"),
(2, 1, "Green"),
(2, 2, "Forever Hold Your Peace"),
(2, 3, "Terrified"),
(3, 1, "Nothing To Do With Me"),
(4, 1, "Play");
INSERT INTO Songs (SingerId, AlbumId, TrackId, SongName, Duration, SongGenre)
VALUES (2, 1, 1, "Let's Get Back Together", 182, "COUNTRY"),
(2, 1, 2, "Starting Again", 156, "ROCK"),
(2, 1, 3, "I Knew You Were Magic", 294, "BLUES"),
(2, 1, 4, "42", 185, "CLASSICAL"),
(2, 1, 5, "Blue", 238, "BLUES"),
(2, 1, 6, "Nothing Is The Same", 303, "BLUES"),
(2, 1, 7, "The Second Time", 255, "ROCK"),
(2, 3, 1, "Fight Story", 194, "ROCK"),
(3, 1, 1, "Not About The Guitar", 278, "BLUES");
配列フラット化
配列フラット化演算子は、入力配列を要素の行にフラット化します。各行は、配列の値が入る列と配列内での位置(先頭は 0)が入る列から構成されます。配列内の位置を表す列はない場合もあります。
次のクエリは、この演算子を示しています。
SELECT a, b FROM UNNEST([1,2,3]) a WITH OFFSET b;
/*---+---+
| a | b |
+---+---+
| 1 | 0 |
| 2 | 1 |
| 3 | 2 |
+---+---*/
このクエリは、配列 [1,2,3] の値を列 a にフラット化し、配列内での位置を列 b に示します。
実行プランは次のように表示されます。
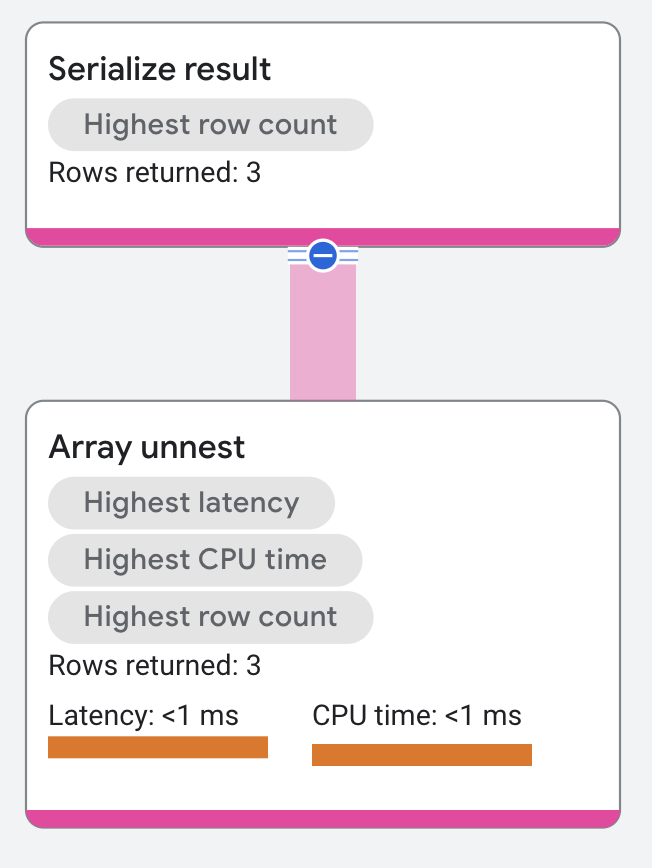
プロパティと実行統計情報
演算子のプロパティは、演算子の実行時に使用される特性を表します。実行統計情報は、クエリ実行中に収集される値で、オペレーターのパフォーマンスを評価するのに役立ちます。
プロパティ
| 名前 | 説明 |
|---|---|
| 実行メソッド | 行実行では、演算子は一度に 1 行を処理します。バッチ実行では、演算子は一度に複数の行を処理します。 |
実行統計情報
| 名前 | 説明 |
|---|---|
| レイテンシ | 演算子で実行されたすべての実行の経過時間。 |
| 累積レイテンシ | 現在の演算子とその子孫の合計時間。 |
| CPU 時間 | 演算子の実行に費やされた CPU 時間の合計。 |
| 累積 CPU 時間 | オペレーターとその子孫の実行に費やされた合計 CPU 時間。 |
| 実行時間 | クエリの実行と結果の処理にかかった合計時間。 |
| 返された行数 | この演算子によって出力された行数 |
| 実行数 | 演算子が実行された回数。一部の実行は並行して実行できます。 |
生成関係
生成関係演算子は 0 個以上の行を返します。
プロパティと実行統計情報
演算子のプロパティは、演算子の実行時に使用される特性を表します。実行統計情報は、クエリ実行中に収集される値で、オペレーターのパフォーマンスを評価するのに役立ちます。
プロパティ
| 名前 | 説明 |
|---|---|
| 実行メソッド | 行実行では、演算子は一度に 1 行を処理します。バッチ実行では、演算子は一度に複数の行を処理します。 |
実行統計情報
| 名前 | 説明 |
|---|---|
| レイテンシ | 演算子で実行されたすべての実行の経過時間。 |
| 累積レイテンシ | 現在の演算子とその子孫の合計時間。 |
| CPU 時間 | 演算子の実行に費やされた CPU 時間の合計。 |
| 累積 CPU 時間 | オペレーターとその子孫の実行に費やされた合計 CPU 時間。 |
| 実行時間 | クエリの実行と結果の処理にかかった合計時間。 |
| 返された行数 | この演算子によって出力された行数 |
| 実行数 | 演算子が実行された回数。一部の実行は並行して実行できます。 |
単位関係
単位関係は 1 行を返します。これは、生成関係演算子の特殊なケースです。
次のクエリは、この演算子を示しています。
SELECT 1 + 2 AS Result;
/*--------+
| Result |
+--------+
| 3 |
+--------*/
実行プランは次のように表示されます。
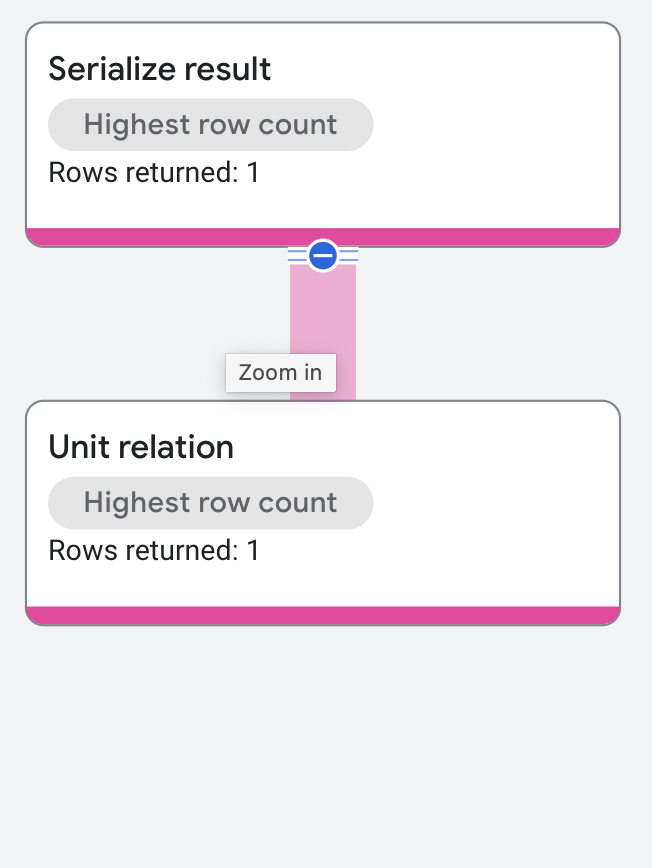
プロパティと実行統計情報
演算子のプロパティは、演算子の実行時に使用される特性を表します。実行統計情報は、クエリ実行中に収集される値で、オペレーターのパフォーマンスを評価するのに役立ちます。
プロパティ
| 名前 | 説明 |
|---|---|
| 実行メソッド | 行実行では、演算子は一度に 1 行を処理します。バッチ実行では、演算子は一度に複数の行を処理します。 |
実行統計情報
| 名前 | 説明 |
|---|---|
| レイテンシ | 演算子で実行されたすべての実行の経過時間。 |
| 累積レイテンシ | 現在の演算子とその子孫の合計時間。 |
| CPU 時間 | 演算子の実行に費やされた CPU 時間の合計。 |
| 累積 CPU 時間 | オペレーターとその子孫の実行に費やされた合計 CPU 時間。 |
| 実行時間 | クエリの実行と結果の処理にかかった合計時間。 |
| 返された行数 | この演算子によって出力された行数 |
| 実行数 | 演算子が実行された回数。一部の実行は並行して実行できます。 |
空の関係
空の関係は行を返しません。これは、生成関係演算子の特殊なケースです。
次のクエリは、この演算子を示しています。
SELECT *
FROM albums
LIMIT 0
/*
No result
*/
実行プランは次のように表示されます。
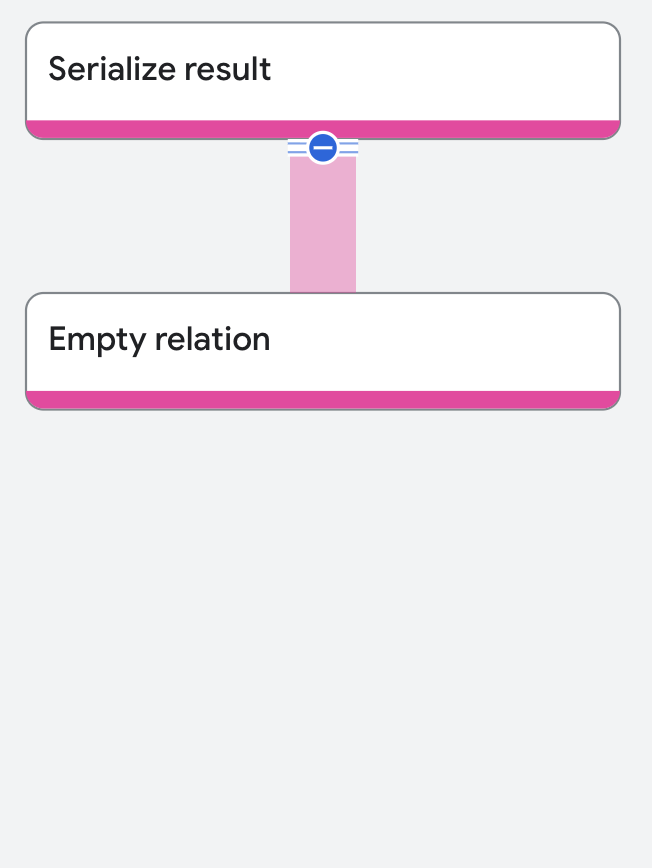
プロパティと実行統計情報
演算子のプロパティは、演算子の実行時に使用される特性を表します。実行統計情報は、クエリ実行中に収集される値で、オペレーターのパフォーマンスを評価するのに役立ちます。
プロパティ
| 名前 | 説明 |
|---|---|
| 実行メソッド | 行実行では、演算子は一度に 1 行を処理します。バッチ実行では、演算子は一度に複数の行を処理します。 |
実行統計情報
| 名前 | 説明 |
|---|---|
| レイテンシ | 演算子で実行されたすべての実行の経過時間。 |
| 累積レイテンシ | 現在の演算子とその子孫の合計時間。 |
| CPU 時間 | 演算子の実行に費やされた CPU 時間の合計。 |
| 累積 CPU 時間 | オペレーターとその子孫の実行に費やされた合計 CPU 時間。 |
| 実行時間 | クエリの実行と結果の処理にかかった合計時間。 |
| 返された行数 | この演算子によって出力された行数 |
| 実行数 | 演算子が実行された回数。一部の実行は並行して実行できます。 |
スキャン
スキャン演算子は、行の取得元をスキャンして行を返します。スキャン演算子の種類は次のとおりです。
- テーブル スキャン: テーブルをスキャンします。
- インデックス スキャン: インデックスをスキャンします。
- バッチスキャン: 他の関係演算子が作成した中間テーブル(たとえば、分散クロス適用によって作成されたテーブル)をスキャンします。
可能であれば、Spanner はスキャン中に述語をキーに適用します。Spanner が述語を適用すると、テーブルまたはインデックス全体を読み取る必要がなくなるため、スキャンが効率的に実行されます。実行プランでは、述語は次のように表示されます。
- シーク可能な条件: この条件は、Spanner がテーブル内でアクセスする行を特定したときに適用されます。これは通常、フィルタが主キーのプレフィックスにある場合に発生します。たとえば、主キーが
Col1とCol2で構成されている場合、Col1またはCol1とCol2に明示的な値を含むWHERE句がシーク可能になります。この場合、Spanner はキー範囲内のデータのみを読み取ります。
クエリでテーブルのすべての行を検索する必要がある場合は、フルスキャンが実行され、実行プランに full scan: true と表示されます。
次のクエリは、この演算子を示しています。
SELECT s.lastname
FROM singers@{FORCE_INDEX=SingersByFirstLastName} as s
WHERE s.firstname = 'Catalina';
/*----------+
| LastName |
+----------+
| Smith |
+----------*/
実行プランのセグメントは次のようになります。
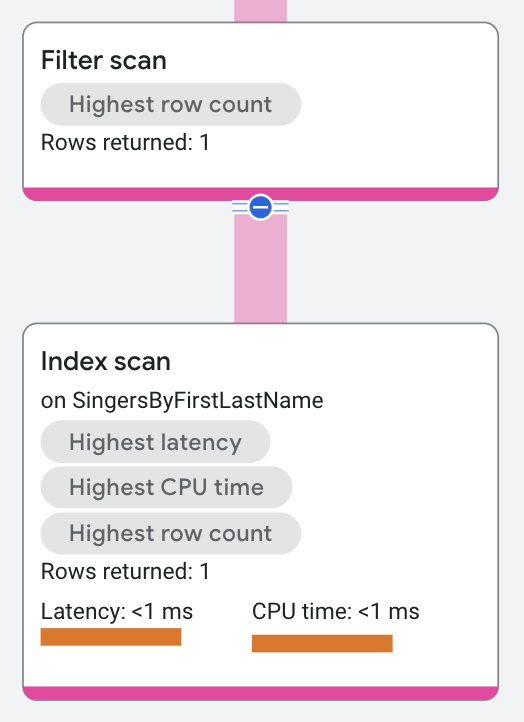
実行プランで、最上位の分散ユニオン演算子がリモート サーバーにサブプランを送信します。各サブプランには、結果のシリアル化演算子とインデックス スキャン演算子が含まれます。述語 Key Predicate: FirstName = 'Catalina' は、スキャンの範囲をインデックス SingersByFirstLastname で FirstName が Catalina の行に限定します。インデックス スキャンは、出力を結果のシリアル化演算子に返します。
Spanner はスキャンを フィルタ スキャンと密接に結合し、単一の演算子と見なします。シーク条件がない場合、演算子はフルスキャンとして表示されます。
プロパティと実行統計情報
演算子のプロパティは、演算子の実行時に使用される特性を表します。実行統計情報は、クエリ実行中に収集される値で、オペレーターのパフォーマンスを評価するのに役立ちます。
スキャン オペレーターには、追加の個別のプロパティと実行統計情報があります。プロパティ
| 名前 | 説明 |
|---|---|
| スキャン方法 | Row、Batch、Automatic のいずれかになります。行実行では、演算子は一度に 1 行を処理します。バッチ実行では、演算子は一度に複数の行を処理します。自動実行では、オペレーターは Row メソッドを使用してスキャンを開始しますが、必要に応じて Batch に変更できます。 |
| シーク条件 | テーブルの効率的なルックアップを実行するために使用される主キーの述語。このプロパティは、必要な行セットを生成するためにテーブル全体をスキャンする必要がないことを意味します。このプロパティは Table Scans と Index Scans にのみ適用されます。 |
| 変数の割り当て | テーブルから読み取られた列のリスト。 |
| 実行メソッド | 行実行では、演算子は一度に 1 行を処理します。バッチ実行では、演算子は一度に複数の行を処理します。 |
実行統計情報
| 名前 | 説明 |
|---|---|
| スキャンされた行数 | スキャン中に読み取られた行数。 |
| シーク回数 | このスキャン オペレータによって実行されたルックアップまたはシークの数。 |
| レイテンシ | 演算子で実行されたすべての実行の経過時間。 |
| 累積レイテンシ | 現在の演算子とその子孫の合計時間。 |
| CPU 時間 | 演算子の実行に費やされた CPU 時間の合計。 |
| 累積 CPU 時間 | オペレーターとその子孫の実行に費やされた合計 CPU 時間。 |
| 実行時間 | クエリの実行と結果の処理にかかった合計時間。 |
| 返された行数 | この演算子によって出力された行数 |
| 実行数 | 演算子が実行された回数。一部の実行は並行して実行できます。 |
フィルタ スキャン
フィルタ スキャン演算子は、常にテーブル スキャンまたはインデックス スキャンよりも上位で実行されます。スキャンとの連携により、データベースから読み込まれる行数が少なくなります。結果として、フィルタを使用する場合よりもスキャンが高速になります。Spanner は特定の条件でフィルタ スキャンを適用します。
- 残存条件: Spanner がスキャン結果を評価し、読み取るデータの量を制限する条件。
次のクエリは、この演算子を示しています。
SELECT lastname
FROM singers
WHERE singerid = 1
/*----------+
| LastName |
+----------+
| Richards |
+----------*/
実行プランは次のように表示されます。

プロパティと実行統計情報
演算子のプロパティは、演算子の実行時に使用される特性を表します。実行統計情報は、クエリ実行中に収集される値で、オペレーターのパフォーマンスを評価するのに役立ちます。
フィルタ スキャン演算子には、追加の個別のプロパティがあります。プロパティ
| 名前 | 説明 |
|---|---|
| 残留条件 | 行の読み取り後に適用される述語。 |
| 実行メソッド | 行実行では、演算子は一度に 1 行を処理します。バッチ実行では、演算子は一度に複数の行を処理します。 |
実行統計情報
| 名前 | 説明 |
|---|---|
| レイテンシ | 演算子で実行されたすべての実行の経過時間。 |
| 累積レイテンシ | 現在の演算子とその子孫の合計時間。 |
| CPU 時間 | 演算子の実行に費やされた CPU 時間の合計。 |
| 累積 CPU 時間 | オペレーターとその子孫の実行に費やされた合計 CPU 時間。 |
| 実行時間 | クエリの実行と結果の処理にかかった合計時間。 |
| 返された行数 | この演算子によって出力された行数 |
| 実行数 | 演算子が実行された回数。一部の実行は並行して実行できます。 |