
単項演算子には、関連する子が 1 つあります。
次の演算子が単項演算子になります。
- 集計
- ミューテーション適用
- バッチ作成
- コンピューティング
- 構造体計算
- DataBlockToRowAdapter
- フィルタ
- 上限
- ローカル分割ユニオン
- ランダムな ID の割り当て
- RowToDataBlockAdapter
- 結果のシリアル化
- 並べ替え
- TVF
- ユニオン入力
データベース スキーマ
このページのクエリと実行プランは、次のデータベース スキーマに基づいています。
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY(SingerId);
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
MarketingBudget INT64
) PRIMARY KEY(SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget);
CREATE TABLE Songs (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
TrackId INT64 NOT NULL,
SongName STRING(MAX),
Duration INT64,
SongGenre STRING(25)
) PRIMARY KEY(SingerId, AlbumId, TrackId),
INTERLEAVE IN PARENT Albums ON DELETE CASCADE;
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC), INTERLEAVE IN Albums;
CREATE INDEX SongsBySongName ON Songs(SongName);
CREATE TABLE Concerts (
VenueId INT64 NOT NULL,
SingerId INT64 NOT NULL,
ConcertDate DATE NOT NULL,
BeginTime TIMESTAMP,
EndTime TIMESTAMP,
TicketPrices ARRAY<INT64>
) PRIMARY KEY(VenueId, SingerId, ConcertDate);
次のデータ操作言語(DML)ステートメントを使用して、これらのテーブルにデータを追加できます。
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate)
VALUES (1, "Marc", "Richards", "1970-09-03"),
(2, "Catalina", "Smith", "1990-08-17"),
(3, "Alice", "Trentor", "1991-10-02"),
(4, "Lea", "Martin", "1991-11-09"),
(5, "David", "Lomond", "1977-01-29");
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle)
VALUES (1, 1, "Total Junk"),
(1, 2, "Go, Go, Go"),
(2, 1, "Green"),
(2, 2, "Forever Hold Your Peace"),
(2, 3, "Terrified"),
(3, 1, "Nothing To Do With Me"),
(4, 1, "Play");
INSERT INTO Songs (SingerId, AlbumId, TrackId, SongName, Duration, SongGenre)
VALUES (2, 1, 1, "Let's Get Back Together", 182, "COUNTRY"),
(2, 1, 2, "Starting Again", 156, "ROCK"),
(2, 1, 3, "I Knew You Were Magic", 294, "BLUES"),
(2, 1, 4, "42", 185, "CLASSICAL"),
(2, 1, 5, "Blue", 238, "BLUES"),
(2, 1, 6, "Nothing Is The Same", 303, "BLUES"),
(2, 1, 7, "The Second Time", 255, "ROCK"),
(2, 3, 1, "Fight Story", 194, "ROCK"),
(3, 1, 1, "Not About The Guitar", 278, "BLUES");
集計
集計演算子は、GROUP BY SQL ステートメントと集計関数(COUNT など)を実装します。集計演算子の入力は論理的に分割され、キー列でグループ化されます。GROUP BY が存在しない場合、単一のグループに配置されます。各グループで、ゼロ個以上の集計が計算されます。
次のクエリは、この演算子を示しています。
SELECT s.singerid,
Avg(s.duration) AS average,
Count(*) AS count
FROM songs AS s
GROUP BY singerid;
/*----------+---------+-------+
| SingerId | average | count |
+----------+---------+-------+
| 3 | 278 | 1 |
| 2 | 225.875 | 8 |
+----------+---------+-------*/
このクエリは、SingerId でグループ化し、AVG 集計と COUNT 集計を実行します。
実行プランのセグメントは次のようになります。
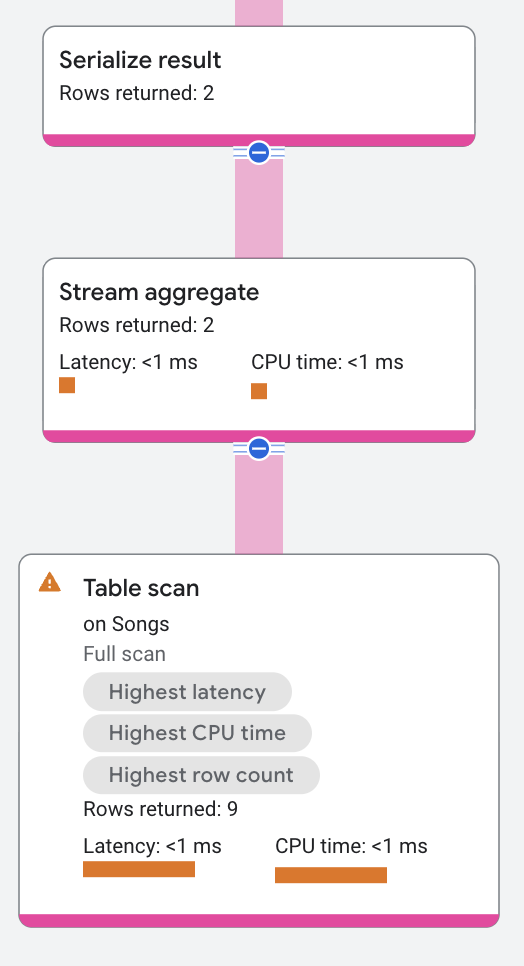
集計演算子はストリームベースまたはハッシュベースになります。上の実行プランでは、ストリームベースの集計になっています。ストリームベースの集計は、並べ替え済みの入力(GROUP BY がある場合)から読み取り、ブロック化を行わずにグループを計算します。ハッシュベースの集計は、ハッシュ テーブルを作成し、複数の入力行の増分集計を同時に維持します。ハッシュベースの集計よりもストリームベースの集計のほうが高速で、メモリの使用量も少なくなりますが、キー列またはセカンダリ インデックスのいずれかを使用して入力の並べ替えが必要になります。
分散環境では、集計演算子はローカルとグローバルに分かれます。それぞれのリモート サーバーがローカルで入力行に集計を実行し、結果をルートサーバーに返します。全体の集計はルートサーバーで行います。
プロパティと実行統計情報
演算子のプロパティは、演算子の実行時に使用される特性を表します。実行統計情報は、クエリ実行中に収集される値で、オペレーターのパフォーマンスを評価するのに役立ちます。
プロパティ
| 名前 | 説明 |
|---|---|
| 実行メソッド | 行実行では、演算子は一度に 1 行を処理します。バッチ実行では、演算子は一度に複数の行を処理します。 |
実行統計情報
| 名前 | 説明 |
|---|---|
| レイテンシ | 演算子で実行されたすべての実行の経過時間。 |
| 累積レイテンシ | 現在の演算子とその子孫の合計時間。 |
| CPU 時間 | 演算子の実行に費やされた CPU 時間の合計。 |
| 累積 CPU 時間 | オペレーターとその子孫の実行に費やされた合計 CPU 時間。 |
| 実行時間 | クエリの実行と結果の処理にかかった合計時間。 |
| 返された行数 | この演算子によって出力された行数 |
| 実行数 | 演算子が実行された回数。一部の実行は並行して実行できます。 |
ミューテーション適用
ミューテーション適用演算子は、データ操作言語(DML)ステートメントのミューテーションをテーブルに適用します。これは、DML ステートメントのクエリプランの最上位演算子です。
次のクエリは、この演算子を示しています。
DELETE FROM singers
WHERE firstname = 'Alice';
/*
4 rows deleted This statement deleted 4 rows and did not return any rows.
*/
実行プランは次のように表示されます。
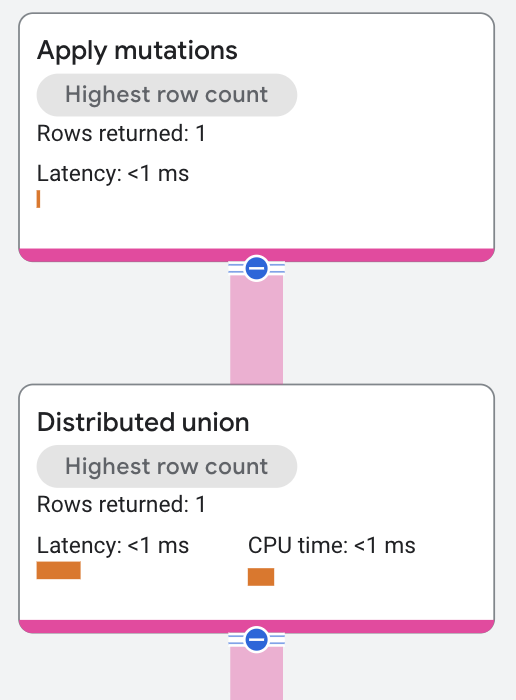
プロパティと実行統計情報
演算子のプロパティは、演算子の実行時に使用される特性を表します。実行統計情報は、クエリ実行中に収集される値で、オペレーターのパフォーマンスを評価するのに役立ちます。
プロパティ
| 名前 | 説明 |
|---|---|
| 実行メソッド | 行実行では、演算子は一度に 1 行を処理します。バッチ実行では、演算子は一度に複数の行を処理します。 |
実行統計情報
| 名前 | 説明 |
|---|---|
| レイテンシ | 演算子で実行されたすべての実行の経過時間。 |
| 累積レイテンシ | 現在の演算子とその子孫の合計時間。 |
| CPU 時間 | 演算子の実行に費やされた CPU 時間の合計。 |
| 累積 CPU 時間 | オペレーターとその子孫の実行に費やされた合計 CPU 時間。 |
| 実行時間 | クエリの実行と結果の処理にかかった合計時間。 |
| 返された行数 | この演算子によって出力された行数 |
| 実行数 | 演算子が実行された回数。一部の実行は並行して実行できます。 |
バッチ作成
バッチ作成演算子は、入力行を 1 つのシーケンスにまとめます。バッチ作成オペレーションは通常、分散クロス適用の中で行われます。バッチ作成時に入力行の並べ替えが再度実行されます。バッチ演算子の 1 回の実行で処理される入力行の数は一定ではありません。
実行プランのバッチ作成演算子の例については、分散クロス適用演算子をご覧ください。
プロパティと実行統計情報
演算子のプロパティは、演算子の実行時に使用される特性を表します。実行統計情報は、クエリ実行中に収集される値で、オペレーターのパフォーマンスを評価するのに役立ちます。
プロパティ
| 名前 | 説明 |
|---|---|
| 実行メソッド | 行実行では、演算子は一度に 1 行を処理します。バッチ実行では、演算子は一度に複数の行を処理します。 |
実行統計情報
| 名前 | 説明 |
|---|---|
| レイテンシ | 演算子で実行されたすべての実行の経過時間。 |
| 累積レイテンシ | 現在の演算子とその子孫の合計時間。 |
| CPU 時間 | 演算子の実行に費やされた CPU 時間の合計。 |
| 累積 CPU 時間 | オペレーターとその子孫の実行に費やされた合計 CPU 時間。 |
| 実行時間 | クエリの実行と結果の処理にかかった合計時間。 |
| 返された行数 | この演算子によって出力された行数 |
| 実行数 | 演算子が実行された回数。一部の実行は並行して実行できます。 |
コンピューティング
計算演算子は、入力行を読み取り、スカラー式で計算される列を追加して結果を生成します。実行プランでの計算演算子の例については、UNION ALL 演算子をご覧ください。
プロパティと実行統計情報
演算子のプロパティは、演算子の実行時に使用される特性を表します。実行統計情報は、クエリ実行中に収集される値で、オペレーターのパフォーマンスを評価するのに役立ちます。
プロパティ
| 名前 | 説明 |
|---|---|
| 実行メソッド | 行実行では、演算子は一度に 1 行を処理します。バッチ実行では、演算子は一度に複数の行を処理します。 |
実行統計情報
| 名前 | 説明 |
|---|---|
| レイテンシ | 演算子で実行されたすべての実行の経過時間。 |
| 累積レイテンシ | 現在の演算子とその子孫の合計時間。 |
| CPU 時間 | 演算子の実行に費やされた CPU 時間の合計。 |
| 累積 CPU 時間 | オペレーターとその子孫の実行に費やされた合計 CPU 時間。 |
| 実行時間 | クエリの実行と結果の処理にかかった合計時間。 |
| 返された行数 | この演算子によって出力された行数 |
| 実行数 | 演算子が実行された回数。一部の実行は並行して実行できます。 |
構造体計算
構造体計算演算子は、入力列のフィールドを含む構造体の変数を作成します。
次のクエリは、この演算子を示しています。
SELECT FirstName,
ARRAY(SELECT AS STRUCT song.SongName, song.SongGenre
FROM Songs AS song
WHERE song.SingerId = singer.SingerId)
FROM singers AS singer
WHERE singer.SingerId = 3;
/*-----------+------------------------------------------------------+
| FirstName | Unspecified |
+-----------+------------------------------------------------------+
| Alice | [["Not About The Guitar","BLUES"]] |
+-----------+------------------------------------------------------*/
実行プランは次のように表示されます。
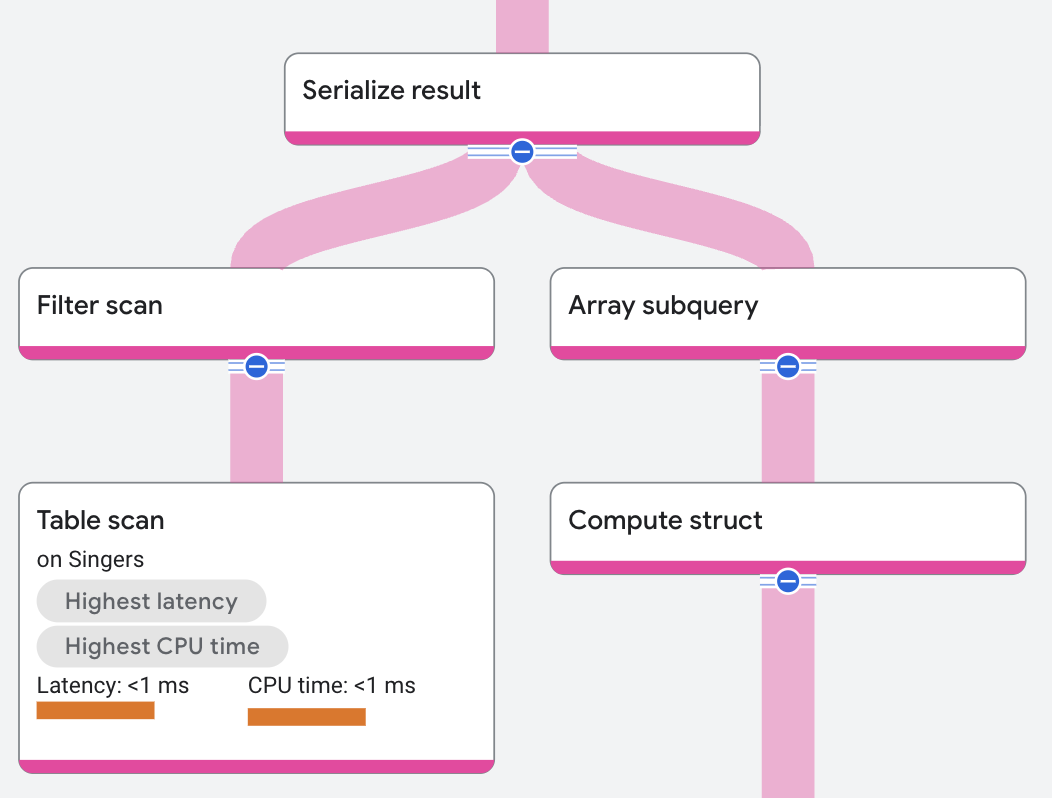
実行プランでは、配列サブクエリ演算子が構造体計算演算子から入力を受信しています。構造体計算演算子は、Songs テーブルの SongName 列と SongGenre 列から構造体を作成します。
プロパティと実行統計情報
演算子のプロパティは、演算子の実行時に使用される特性を表します。実行統計情報は、クエリ実行中に収集される値で、オペレーターのパフォーマンスを評価するのに役立ちます。
プロパティ
| 名前 | 説明 |
|---|---|
| 実行メソッド | 行実行では、演算子は一度に 1 行を処理します。バッチ実行では、演算子は一度に複数の行を処理します。 |
実行統計情報
| 名前 | 説明 |
|---|---|
| レイテンシ | 演算子で実行されたすべての実行の経過時間。 |
| 累積レイテンシ | 現在の演算子とその子孫の合計時間。 |
| CPU 時間 | 演算子の実行に費やされた CPU 時間の合計。 |
| 累積 CPU 時間 | オペレーターとその子孫の実行に費やされた合計 CPU 時間。 |
| 実行時間 | クエリの実行と結果の処理にかかった合計時間。 |
| 返された行数 | この演算子によって出力された行数 |
| 実行数 | 演算子が実行された回数。一部の実行は並行して実行できます。 |
フィルタ
フィルタ演算子は、入力からすべての行を読み取り、各行にスカラー述語を適用して、述語の条件を満たす行のみを返します。
次のクエリは、この演算子を示しています。
SELECT s.lastname
FROM (SELECT s.lastname
FROM singers AS s
LIMIT 3) s
WHERE s.lastname LIKE 'Rich%';
/*----------+
| LastName |
+----------+
| Richards |
+----------*/
実行プランは次のように表示されます。
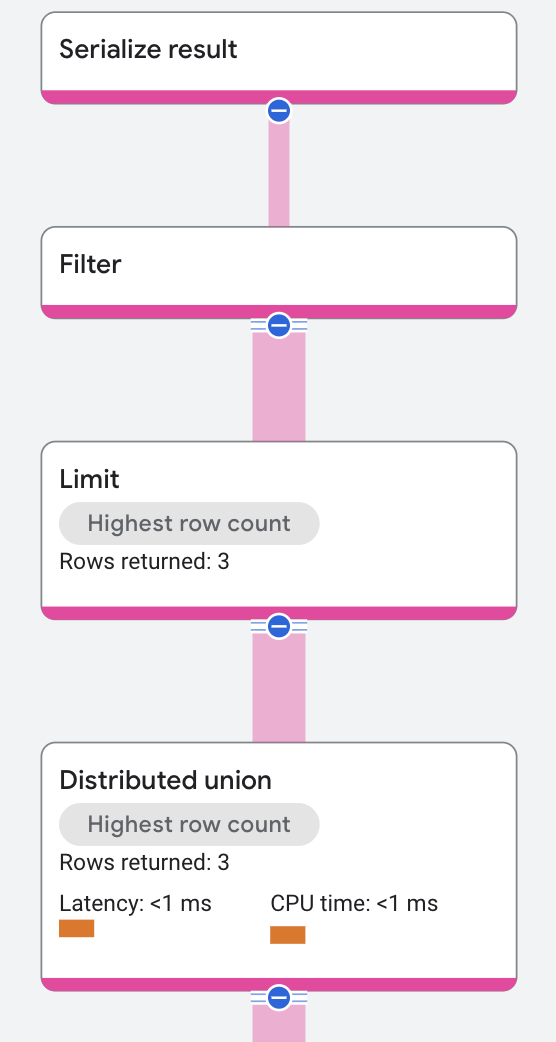
Spanner は、名前が Rich で始まる歌手の述語をフィルタとして実装します。フィルタはインデックス スキャンから入力を受け取り、LastName が Rich で始まる行を出力します。
プロパティと実行統計情報
演算子のプロパティは、演算子の実行時に使用される特性を表します。実行統計情報は、クエリ実行中に収集される値で、オペレーターのパフォーマンスを評価するのに役立ちます。
Filter 演算子には、追加の個別のプロパティがあります。プロパティ
| 名前 | 説明 |
|---|---|
| 条件 | 各入力行に適用される述語。true の場合、行は次の演算子に渡されます。false の場合、行は破棄されます。 |
| 実行メソッド | 行実行では、演算子は一度に 1 行を処理します。バッチ実行では、演算子は一度に複数の行を処理します。 |
実行統計情報
| 名前 | 説明 |
|---|---|
| レイテンシ | 演算子で実行されたすべての実行の経過時間。 |
| 累積レイテンシ | 現在の演算子とその子孫の合計時間。 |
| CPU 時間 | 演算子の実行に費やされた CPU 時間の合計。 |
| 累積 CPU 時間 | オペレーターとその子孫の実行に費やされた合計 CPU 時間。 |
| 実行時間 | クエリの実行と結果の処理にかかった合計時間。 |
| 返された行数 | この演算子によって出力された行数 |
| 実行数 | 演算子が実行された回数。一部の実行は並行して実行できます。 |
上限
制限演算子は、返される行数を制限します。OFFSET パラメータに開始行を指定します(このパラメータは省略可能です)。分散環境では、制限演算子はローカルとグローバルに分かれます。それぞれのリモート サーバーが出力行にローカルの制限を適用し、結果をルートサーバーに返します。ルートサーバーがリモート サーバーから受信した行を集計し、全体の制限を適用します。
次のクエリは、この演算子を示しています。
SELECT s.songname
FROM songs AS s
LIMIT 3;
/*----------------------+
| SongName |
+----------------------+
| Not About The Guitar |
| The Second Time |
| Starting Again |
+----------------------*/
実行プランは次のように表示されます。
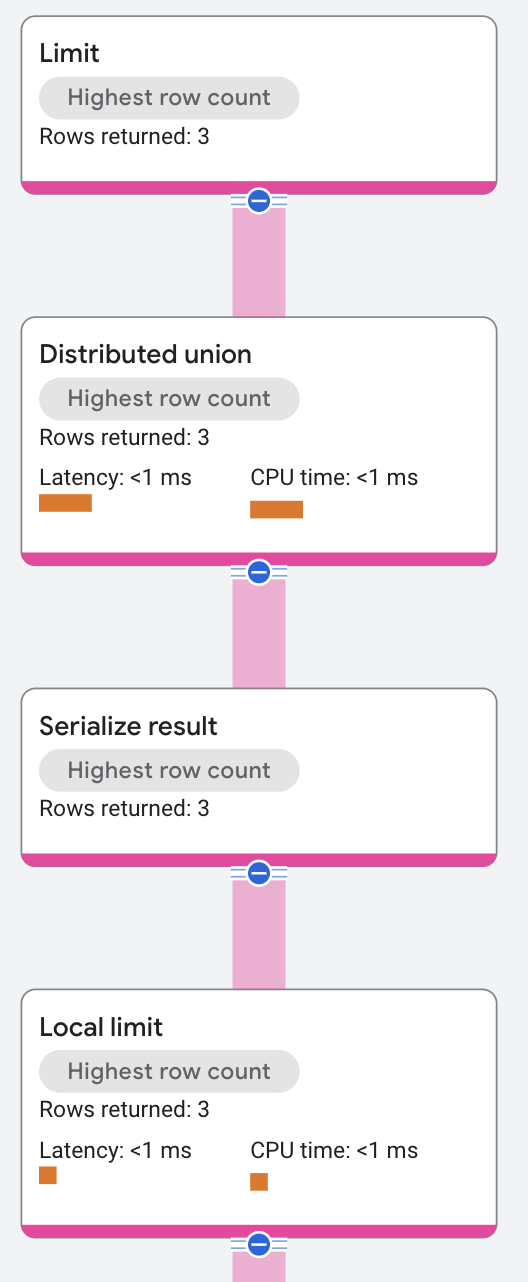
ローカルの制限は、それぞれのリモート サーバーの制限です。ルートサーバーは、リモート サーバーから受信した行を集計し、全体の制限を適用します。
プロパティと実行統計情報
演算子のプロパティは、演算子の実行時に使用される特性を表します。実行統計情報は、クエリ実行中に収集される値で、オペレーターのパフォーマンスを評価するのに役立ちます。
Filter 演算子には、追加の個別のプロパティがあります。プロパティ
| 名前 | 説明 |
|---|---|
| 条件 | 各入力行に適用される述語。true の場合、行は次の演算子に渡されます。false の場合、行は破棄されます。 |
| 実行メソッド | 行実行では、演算子は一度に 1 行を処理します。バッチ実行では、演算子は一度に複数の行を処理します。 |
実行統計情報
| 名前 | 説明 |
|---|---|
| レイテンシ | 演算子で実行されたすべての実行の経過時間。 |
| 累積レイテンシ | 現在の演算子とその子孫の合計時間。 |
| CPU 時間 | 演算子の実行に費やされた CPU 時間の合計。 |
| 累積 CPU 時間 | オペレーターとその子孫の実行に費やされた合計 CPU 時間。 |
| 実行時間 | クエリの実行と結果の処理にかかった合計時間。 |
| 返された行数 | この演算子によって出力された行数 |
| 実行数 | 演算子が実行された回数。一部の実行は並行して実行できます。 |
ランダムな ID の割り当て
ランダムな ID の割り当て演算子は、入力行を読み取り、各行に乱数を追加することで出力を生成します。サンプリング方法を実現するには Filter または Sort 演算子を使用します。サポートされているサンプリング方法は Bernoulli と Reservoir です。
たとえば、次のクエリは、サンプリング レートが 10% の Bernoulli サンプリングを使用しています。
SELECT s.songname
FROM songs AS s TABLESAMPLE bernoulli (10 PERCENT);
/*----------------+
| SongName |
+----------------+
| Starting Again |
+----------------*/
この結果はサンプルで、クエリを実行するたびに変わります。同じクエリを実行しても変わる場合があります。
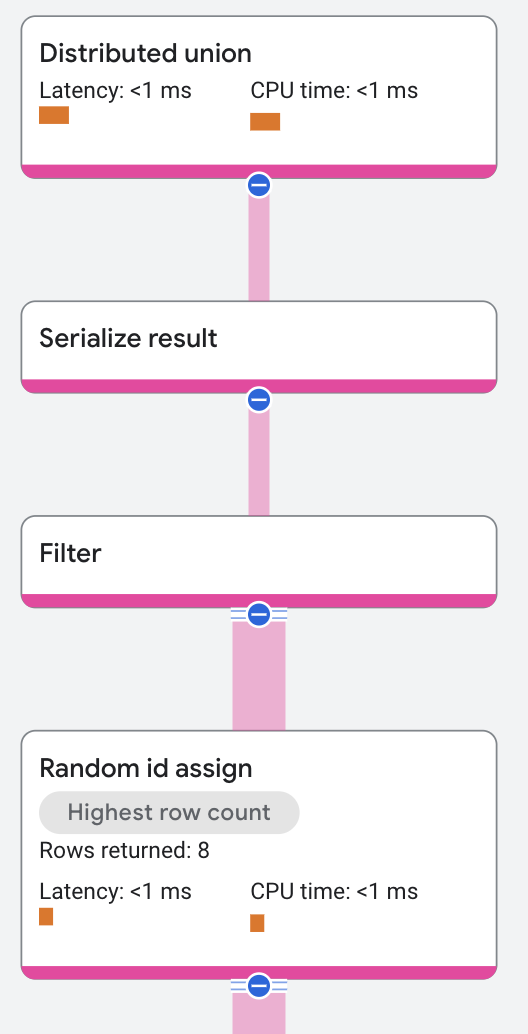
この実行プランでは、Random Id Assign 演算子が分散ユニオン演算子から入力を受信します。分散ユニオン演算子はインデックス スキャンから入力を受信します。演算子はランダムな ID を持つ行を返します。Filter 演算子はランダムな ID にスカラー述語を適用し、行の約 10% を返します。
次の例では、サンプリング レートが 2 行の Reservoir
を使用しています。
SELECT s.songname
FROM songs AS s TABLESAMPLE reservoir (2 rows);
/*------------------------+
| SongName |
+------------------------+
| I Knew You Were Magic |
| The Second Time |
+------------------------*/
この結果はサンプルで、クエリを実行するたびに変わります。同じクエリを実行しても変わる場合があります。
実行プランは次のとおりです。
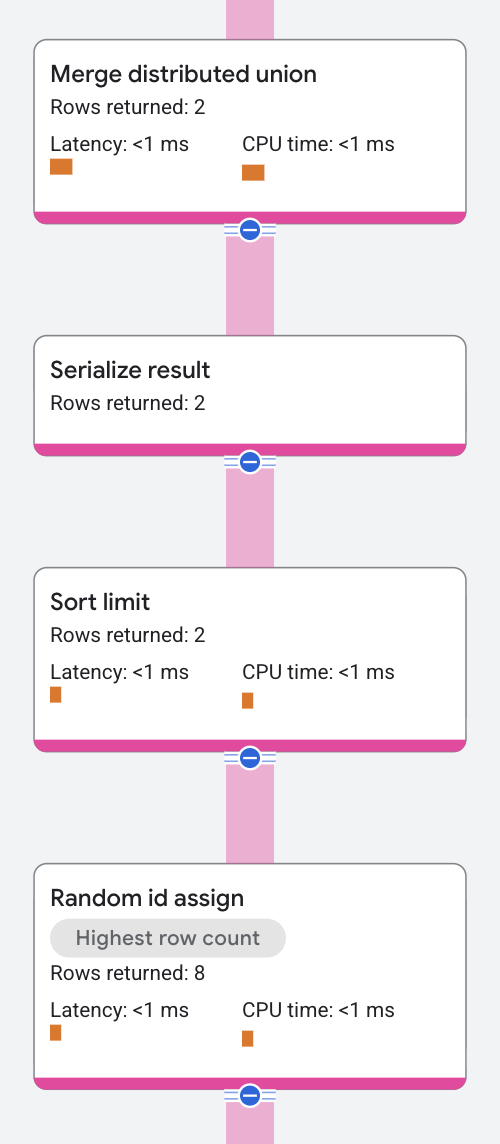
この実行プランでは、Random Id Assign 演算子が分散ユニオン演算子から入力を受信します。分散ユニオン演算子はインデックス スキャンから入力を受信します。演算子はランダムな ID を持つ行を返し、Sort 演算子はランダムな ID に並べ替え順序を適用し、LIMIT に 2 行を適用します。
プロパティと実行統計情報
演算子のプロパティは、演算子の実行時に使用される特性を表します。実行統計情報は、クエリ実行中に収集される値で、オペレーターのパフォーマンスを評価するのに役立ちます。
Filter 演算子には、追加の個別のプロパティがあります。プロパティ
| 名前 | 説明 |
|---|---|
| 条件 | 各入力行に適用される述語。true の場合、行は次の演算子に渡されます。false の場合、行は破棄されます。 |
| 実行メソッド | 行実行では、演算子は一度に 1 行を処理します。バッチ実行では、演算子は一度に複数の行を処理します。 |
実行統計情報
| 名前 | 説明 |
|---|---|
| レイテンシ | 演算子で実行されたすべての実行の経過時間。 |
| 累積レイテンシ | 現在の演算子とその子孫の合計時間。 |
| CPU 時間 | 演算子の実行に費やされた CPU 時間の合計。 |
| 累積 CPU 時間 | オペレーターとその子孫の実行に費やされた合計 CPU 時間。 |
| 実行時間 | クエリの実行と結果の処理にかかった合計時間。 |
| 返された行数 | この演算子によって出力された行数 |
| 実行数 | 演算子が実行された回数。一部の実行は並行して実行できます。 |
ローカル分割ユニオン
ローカル分割ユニオン演算子は、ローカル サーバーに保存されているテーブルのスプリットを見つけ、各スプリットに対してサブクエリを実行し、すべての結果を結合するユニオンを作成します。
ローカル分割ユニオンは、プレースメント テーブルをスキャンする実行プランに含まれます。プレースメントを使用すると、テーブル内のスプリット数を増やすことができます。これにより、物理ストレージのロケーションに基づいてバッチ内のスプリットをより効率的にスキャンできます。
たとえば、Singers テーブルでプレースメント キーを使用して歌手データをパーティショニングするとします。
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
SingerName STRING(MAX) NOT NULL,
...
Location STRING(MAX) NOT NULL PLACEMENT KEY
) PRIMARY KEY (SingerId);
次のクエリについて考えてみましょう。
SELECT BirthDate FROM Singers;
実行プランは次のとおりです。
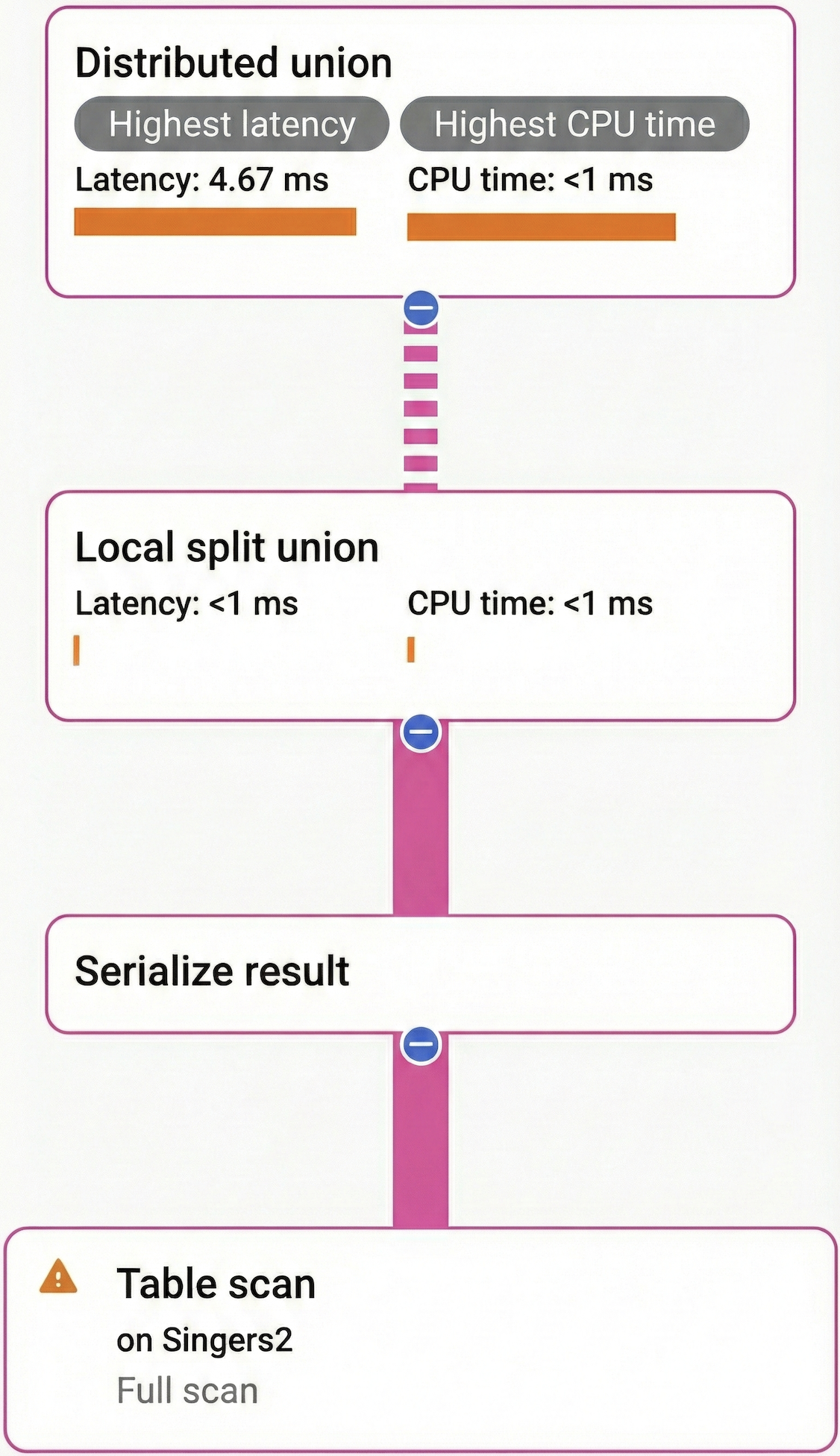
分散ユニオンは、同じサーバーに物理的に一緒に保存されているスプリットのバッチごとにサブクエリを送信します。各サーバーで、ローカル分割ユニオンは Singers データを保存するスプリットを見つけ、各スプリットに対してサブクエリを実行し、結合された結果を返します。このように、分散ユニオンとローカル分割ユニオンが連携して、Singers テーブルを効率的にスキャンします。ローカル分割ユニオンがない場合、分散ユニオンは分割バッチごとにではなく、スプリットごとに 1 つの RPC を送信します。このため、バッチごとに複数のスプリットがある場合は、RPC ラウンド トリップが冗長になります。
プロパティと実行統計情報
演算子のプロパティは、演算子の実行時に使用される特性を表します。実行統計情報は、クエリ実行中に収集される値で、オペレーターのパフォーマンスを評価するのに役立ちます。
Filter 演算子には、追加の個別のプロパティがあります。プロパティ
| 名前 | 説明 |
|---|---|
| 条件 | 各入力行に適用される述語。true の場合、行は次の演算子に渡されます。false の場合、行は破棄されます。 |
| 実行メソッド | 行実行では、演算子は一度に 1 行を処理します。バッチ実行では、演算子は一度に複数の行を処理します。 |
実行統計情報
| 名前 | 説明 |
|---|---|
| レイテンシ | 演算子で実行されたすべての実行の経過時間。 |
| 累積レイテンシ | 現在の演算子とその子孫の合計時間。 |
| CPU 時間 | 演算子の実行に費やされた CPU 時間の合計。 |
| 累積 CPU 時間 | オペレーターとその子孫の実行に費やされた合計 CPU 時間。 |
| 実行時間 | クエリの実行と結果の処理にかかった合計時間。 |
| 返された行数 | この演算子によって出力された行数 |
| 実行数 | 演算子が実行された回数。一部の実行は並行して実行できます。 |
DataBlockToRowAdapter
Spanner クエリ オプティマイザーは、異なる実行方法を使用して動作する演算子のペアの間に DataBlockToRowAdapter 演算子を自動的に挿入します。入力はバッチ指向の実行方法を使用する演算子であり、出力は行指向の実行方法で実行される演算子にフィードされます。詳細については、クエリの実行を最適化するをご覧ください。
プロパティと実行統計情報
演算子のプロパティは、演算子の実行時に使用される特性を表します。実行統計情報は、クエリ実行中に収集される値で、オペレーターのパフォーマンスを評価するのに役立ちます。
Filter 演算子には、追加の個別のプロパティがあります。プロパティ
| 名前 | 説明 |
|---|---|
| 条件 | 各入力行に適用される述語。true の場合、行は次の演算子に渡されます。false の場合、行は破棄されます。 |
| 実行メソッド | 行実行では、演算子は一度に 1 行を処理します。バッチ実行では、演算子は一度に複数の行を処理します。 |
実行統計情報
| 名前 | 説明 |
|---|---|
| レイテンシ | 演算子で実行されたすべての実行の経過時間。 |
| 累積レイテンシ | 現在の演算子とその子孫の合計時間。 |
| CPU 時間 | 演算子の実行に費やされた CPU 時間の合計。 |
| 累積 CPU 時間 | オペレーターとその子孫の実行に費やされた合計 CPU 時間。 |
| 実行時間 | クエリの実行と結果の処理にかかった合計時間。 |
| 返された行数 | この演算子によって出力された行数 |
| 実行数 | 演算子が実行された回数。一部の実行は並行して実行できます。 |
RowToDataBlockAdapter
Spanner クエリ オプティマイザーは、異なる実行方法を使用して動作する演算子のペアの間に RowToDataBlockAdapter 演算子を自動的に挿入します。入力は行指向の実行方法を使用する演算子であり、出力はバッチ指向の実行方法で実行される演算子にフィードされます。詳細については、クエリの実行を最適化するをご覧ください。
プロパティと実行統計情報
演算子のプロパティは、演算子の実行時に使用される特性を表します。実行統計情報は、クエリ実行中に収集される値で、オペレーターのパフォーマンスを評価するのに役立ちます。
Filter 演算子には、追加の個別のプロパティがあります。プロパティ
| 名前 | 説明 |
|---|---|
| 条件 | 各入力行に適用される述語。true の場合、行は次の演算子に渡されます。false の場合、行は破棄されます。 |
| 実行メソッド | 行実行では、演算子は一度に 1 行を処理します。バッチ実行では、演算子は一度に複数の行を処理します。 |
実行統計情報
| 名前 | 説明 |
|---|---|
| レイテンシ | 演算子で実行されたすべての実行の経過時間。 |
| 累積レイテンシ | 現在の演算子とその子孫の合計時間。 |
| CPU 時間 | 演算子の実行に費やされた CPU 時間の合計。 |
| 累積 CPU 時間 | オペレーターとその子孫の実行に費やされた合計 CPU 時間。 |
| 実行時間 | クエリの実行と結果の処理にかかった合計時間。 |
| 返された行数 | この演算子によって出力された行数 |
| 実行数 | 演算子が実行された回数。一部の実行は並行して実行できます。 |
結果のシリアル化
結果のシリアル化演算子は構造体演算子の特別なケースで、クライアントに返す前にクエリの最終結果の各行をシリアル化します。
次のクエリは、この演算子を示しています。
SELECT array
(
select as struct so.songname,
so.songgenre
FROM songs AS so
WHERE so.singerid = s.singerid)
FROM singers AS s;
/*------------------------------------------------------------------+
| Unspecified |
+------------------------------------------------------------------+
| [] |
| [[Let's Get Back Together, COUNTRY], [Starting Again, ROCK]] |
| [["Not About The Guitar", "BLUES"]] |
| [] |
| [] |
+------------------------------------------------------------------*/
実行プランは次のように表示されます。
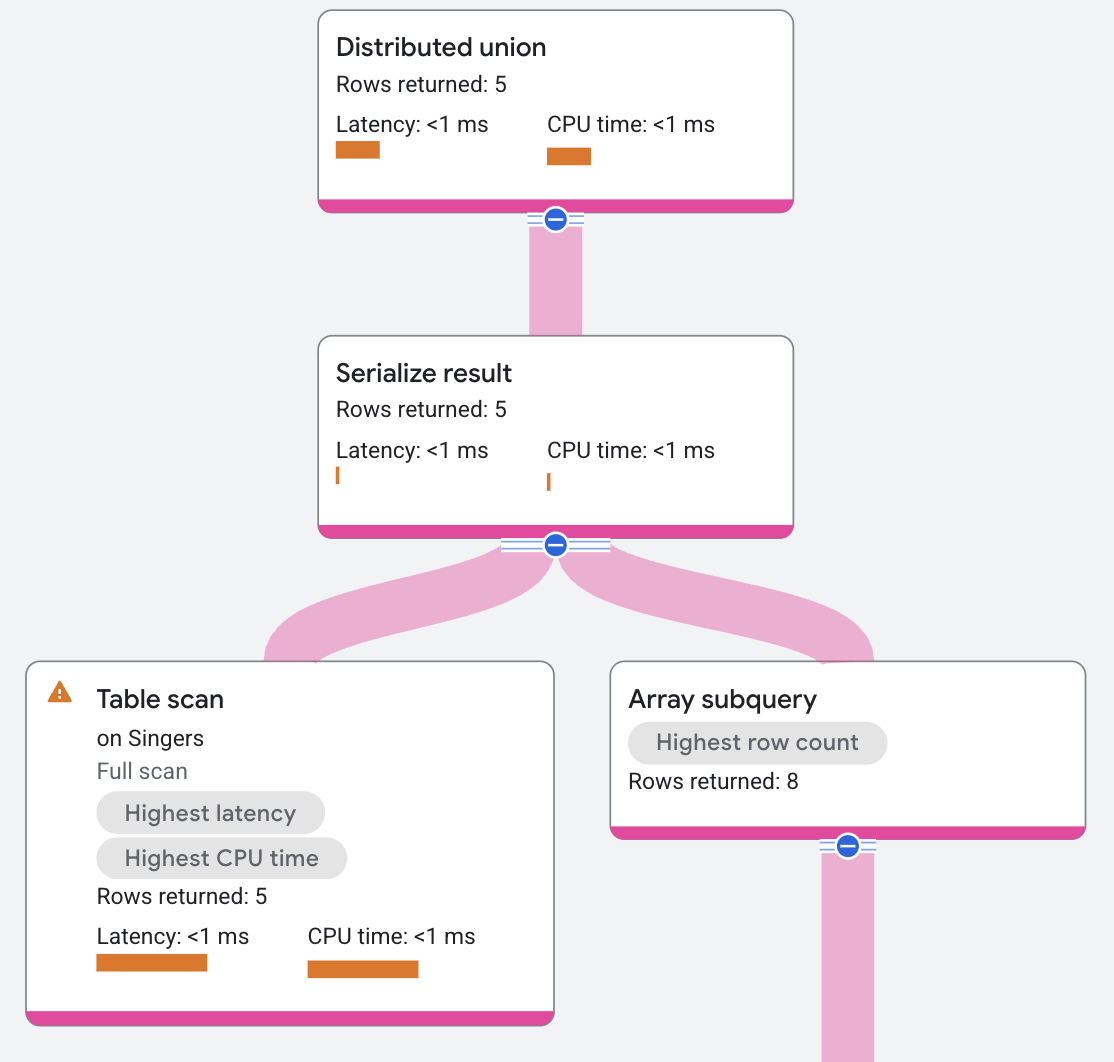
結果のシリアル化演算子は、Singers テーブルの各行に、曲の SongName と SongGenre のペアの配列を歌手ごとに含む結果を作成します。
プロパティと実行統計情報
演算子のプロパティは、演算子の実行時に使用される特性を表します。実行統計情報は、クエリ実行中に収集される値で、オペレーターのパフォーマンスを評価するのに役立ちます。
Filter 演算子には、追加の個別のプロパティがあります。プロパティ
| 名前 | 説明 |
|---|---|
| 条件 | 各入力行に適用される述語。true の場合、行は次の演算子に渡されます。false の場合、行は破棄されます。 |
| 実行メソッド | 行実行では、演算子は一度に 1 行を処理します。バッチ実行では、演算子は一度に複数の行を処理します。 |
実行統計情報
| 名前 | 説明 |
|---|---|
| レイテンシ | 演算子で実行されたすべての実行の経過時間。 |
| 累積レイテンシ | 現在の演算子とその子孫の合計時間。 |
| CPU 時間 | 演算子の実行に費やされた CPU 時間の合計。 |
| 累積 CPU 時間 | オペレーターとその子孫の実行に費やされた合計 CPU 時間。 |
| 実行時間 | クエリの実行と結果の処理にかかった合計時間。 |
| 返された行数 | この演算子によって出力された行数 |
| 実行数 | 演算子が実行された回数。一部の実行は並行して実行できます。 |
並べ替え
並べ替え演算子は、入力行を読み取り、列で並べ替えて結果を返します。
次のクエリは、この演算子を示しています。
SELECT s.songgenre
FROM songs AS s
ORDER BY songgenre;
/*--------------------------+
| SongGenre |
+--------------------------+
| BLUES |
| BLUES |
| BLUES |
| BLUES |
| CLASSICAL |
| COUNTRY |
| ROCK |
| ROCK |
| ROCK |
+--------------------------*/
実行プランは次のように表示されます。
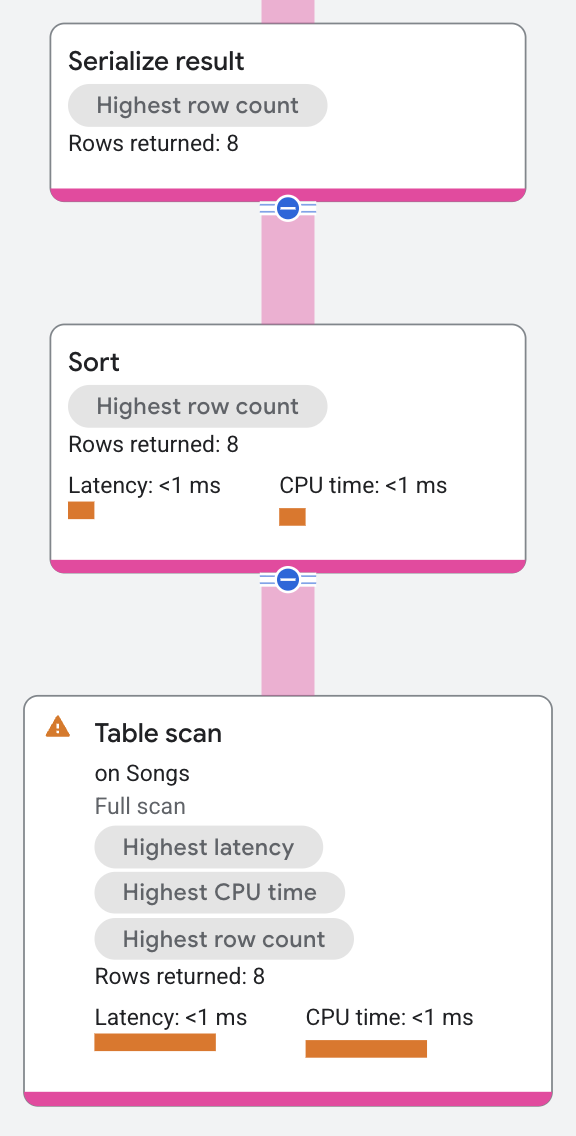
この実行プランでは、並べ替え演算子は分散ユニオン演算子から入力行を受け取り、入力行を並べ替えてから結果のシリアル化演算子に返します。
返す行数を制限するには、並べ替え演算子に LIMIT パラメータと OFFSET パラメータを指定します。これらのパラメータは省略可能です。分散環境では、LIMIT または OFFSET 演算子を使用した並べ替え演算子はローカルとグローバルに分かれます。それぞれのリモート サーバーが入力行に並べ替え順とローカルの制限 / オフセットを適用し、結果をルートサーバーに返します。ルートサーバーは、リモート サーバーから受信した行を集計して並べ替え、全体の制限 / オフセットを適用します。
次のクエリは、この演算子を示しています。
SELECT s.songgenre
FROM songs AS s
ORDER BY songgenre
LIMIT 3;
/*--------------------------+
| SongGenre |
+--------------------------+
| BLUES |
| BLUES |
| BLUES |
+--------------------------*/
実行プランは次のように表示されます。
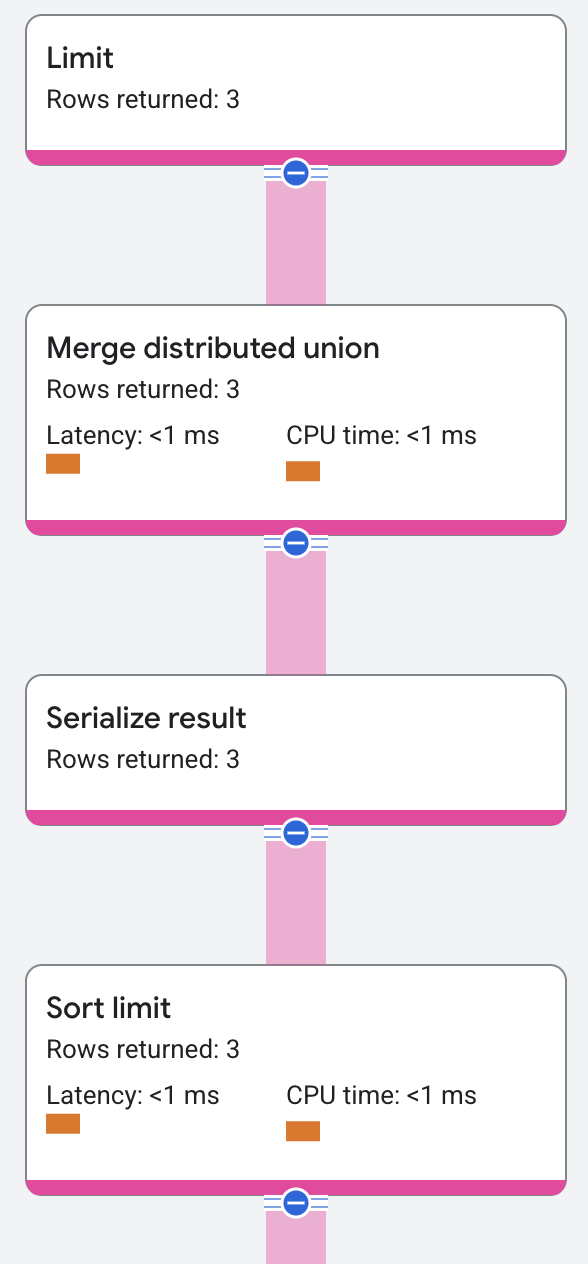
この実行プランは、リモート サーバーのローカル制限とルートサーバーの全体制限を表しています。
プロパティと実行統計情報
演算子のプロパティは、演算子の実行時に使用される特性を表します。実行統計情報は、クエリ実行中に収集される値で、オペレーターのパフォーマンスを評価するのに役立ちます。
Filter 演算子には、追加の個別のプロパティがあります。プロパティ
| 名前 | 説明 |
|---|---|
| 条件 | 各入力行に適用される述語。true の場合、行は次の演算子に渡されます。false の場合、行は破棄されます。 |
| 実行メソッド | 行実行では、演算子は一度に 1 行を処理します。バッチ実行では、演算子は一度に複数の行を処理します。 |
実行統計情報
| 名前 | 説明 |
|---|---|
| レイテンシ | 演算子で実行されたすべての実行の経過時間。 |
| 累積レイテンシ | 現在の演算子とその子孫の合計時間。 |
| CPU 時間 | 演算子の実行に費やされた CPU 時間の合計。 |
| 累積 CPU 時間 | オペレーターとその子孫の実行に費やされた合計 CPU 時間。 |
| 実行時間 | クエリの実行と結果の処理にかかった合計時間。 |
| 返された行数 | この演算子によって出力された行数 |
| 実行数 | 演算子が実行された回数。一部の実行は並行して実行できます。 |
TVF
テーブル値関数演算子は、入力行を読み取り、指定された関数を適用することで出力を生成します。この関数はマッピングを実装し、入力と同じ数の行を返す場合があります。行数を増やすジェネレータや、行数を減らすフィルタにすることもできます。
次のクエリは、この演算子を示しています。
SELECT genre,
songname
FROM ml.predict(model genreclassifier, TABLE songs)
/*-----------------------+--------------------------+
| Genre | SongName |
+-----------------------+--------------------------+
| Country | Not About The Guitar |
| Rock | The Second Time |
| Pop | Starting Again |
| Pop | Nothing Is The Same |
| Country | Let's Get Back Together |
| Pop | I Knew You Were Magic |
| Electronic | Blue |
| Rock | 42 |
| Rock | Fight Story |
+-----------------------+--------------------------*/
プロパティと実行統計情報
演算子のプロパティは、演算子の実行時に使用される特性を表します。実行統計情報は、クエリ実行中に収集される値で、オペレーターのパフォーマンスを評価するのに役立ちます。
Filter 演算子には、追加の個別のプロパティがあります。プロパティ
| 名前 | 説明 |
|---|---|
| 条件 | 各入力行に適用される述語。true の場合、行は次の演算子に渡されます。false の場合、行は破棄されます。 |
| 実行メソッド | 行実行では、演算子は一度に 1 行を処理します。バッチ実行では、演算子は一度に複数の行を処理します。 |
実行統計情報
| 名前 | 説明 |
|---|---|
| レイテンシ | 演算子で実行されたすべての実行の経過時間。 |
| 累積レイテンシ | 現在の演算子とその子孫の合計時間。 |
| CPU 時間 | 演算子の実行に費やされた CPU 時間の合計。 |
| 累積 CPU 時間 | オペレーターとその子孫の実行に費やされた合計 CPU 時間。 |
| 実行時間 | クエリの実行と結果の処理にかかった合計時間。 |
| 返された行数 | この演算子によって出力された行数 |
| 実行数 | 演算子が実行された回数。一部の実行は並行して実行できます。 |
ユニオン入力
ユニオン入力演算子は、結果を UNION ALL 演算子に返します。実行プランでのユニオン入力演算子の例については、UNION ALL 演算子を参照してください。
プロパティと実行統計情報
演算子のプロパティは、演算子の実行時に使用される特性を表します。実行統計情報は、クエリ実行中に収集される値で、オペレーターのパフォーマンスを評価するのに役立ちます。
Filter 演算子には、追加の個別のプロパティがあります。プロパティ
| 名前 | 説明 |
|---|---|
| 条件 | 各入力行に適用される述語。true の場合、行は次の演算子に渡されます。false の場合、行は破棄されます。 |
| 実行メソッド | 行実行では、演算子は一度に 1 行を処理します。バッチ実行では、演算子は一度に複数の行を処理します。 |
実行統計情報
| 名前 | 説明 |
|---|---|
| レイテンシ | 演算子で実行されたすべての実行の経過時間。 |
| 累積レイテンシ | 現在の演算子とその子孫の合計時間。 |
| CPU 時間 | 演算子の実行に費やされた CPU 時間の合計。 |
| 累積 CPU 時間 | オペレーターとその子孫の実行に費やされた合計 CPU 時間。 |
| 実行時間 | クエリの実行と結果の処理にかかった合計時間。 |
| 返された行数 | この演算子によって出力された行数 |
| 実行数 | 演算子が実行された回数。一部の実行は並行して実行できます。 |