
Esta página oferece uma vista geral dos componentes de alto nível envolvidos num pedido do Spanner e como cada componente pode afetar a latência.
Pedidos da API Spanner
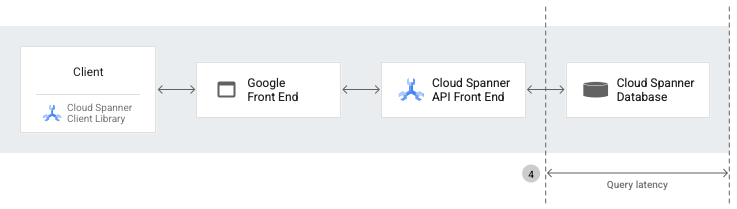
Os componentes de nível elevado usados para fazer um pedido à API Spanner incluem:
Bibliotecas do cliente do Spanner, que fornecem uma camada de abstração sobre o gRPC e processam detalhes de comunicação do servidor, como gestão de sessões, transações e novas tentativas.
O Google Front End (GFE), que é um serviço de infraestrutura comum a todos os serviços, incluindo o Spanner. Google Cloud O GFE verifica se todas as ligações Transport Layer Security (TLS) estão paradas e aplica proteções contra ataques de negação de serviço. Para saber mais acerca do GFE, consulte o serviço Google Front End.
O front-end da API Spanner (AFE), que realiza várias verificações no pedido da API (incluindo verificações de autenticação, autorização e quota) e mantém as sessões e os estados das transações.
A base de dados do Spanner, que executa leituras e escritas na base de dados.
Quando faz uma chamada de procedimento remoto para o Spanner, as bibliotecas cliente do Spanner preparam o pedido da API. Em seguida, o pedido da API passa pelo GFE e pelo AFE do Spanner antes de chegar à base de dados do Spanner.
Ao medir e comparar as latências de pedidos entre diferentes componentes e a base de dados, pode determinar que componente está a causar o problema. Estas latências incluem a latência ponto a ponto do cliente, do GFE, do pedido da API Spanner e da consulta.
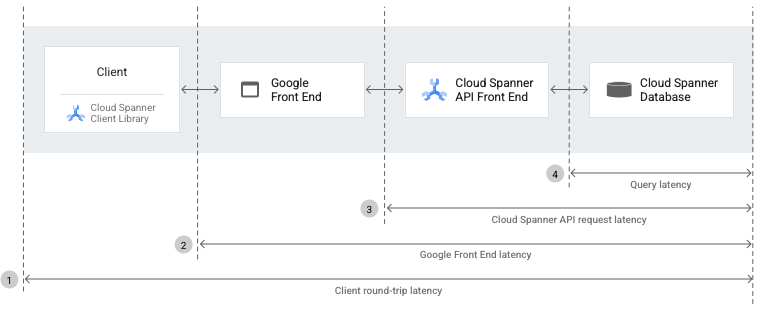
As secções seguintes explicam cada tipo de latência que vê no diagrama anterior.
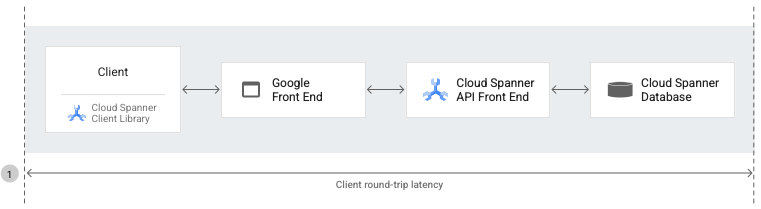
Latência ponto a ponto
A latência ponto a ponto é o período (em milissegundos) entre o primeiro byte do pedido da API Spanner que o cliente envia para a base de dados (através do GFE e do front-end da API Spanner) e o último byte da resposta que o cliente recebe da base de dados.
A métrica
spanner.googleapis.com/client/operation_latencies
indica o tempo decorrido entre o primeiro byte do pedido da API
enviado e o último byte da resposta recebida. Isto inclui as novas tentativas realizadas pela biblioteca de cliente.
Para mais informações, consulte o artigo Veja e faça a gestão das métricas do lado do cliente.
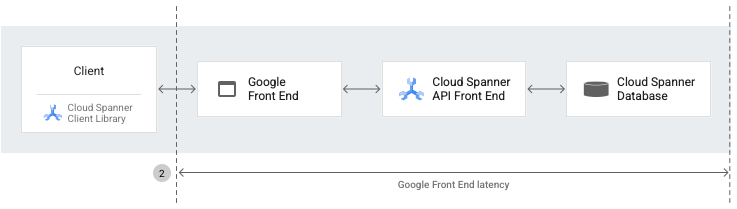
Latência do GFE
A latência do front-end da Google (GFE) é o período (em milissegundos) entre o momento em que a rede Google recebe uma chamada de procedimento remoto do cliente e o momento em que o GFE recebe o primeiro byte da resposta. Esta latência não inclui nenhum handshake TCP/SSL.
Todas as respostas do Spanner (REST ou gRPC) incluem um cabeçalho que contém o tempo total entre o GFE e o back-end (o serviço Spanner) para o pedido e a resposta. Isto ajuda a diferenciar melhor a origem da latência entre o cliente e o GFE.
A métrica spanner.googleapis.com/client/gfe_latencies
captura e expõe a latência do GFE para pedidos do Spanner.
Para mais informações, consulte o artigo Veja e faça a gestão das métricas do lado do cliente.
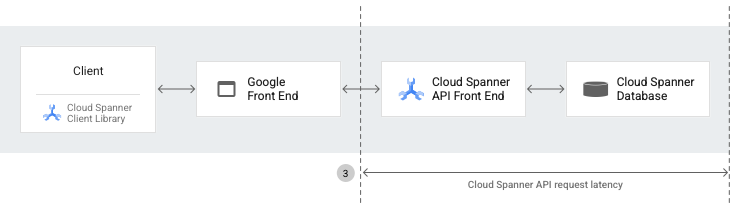
Latência do pedido da API Spanner
A latência do pedido da API Spanner é o período (em segundos) desde o momento em que o AFE do Spanner recebe o primeiro byte de um pedido até ao momento em que o front-end da API Spanner envia o último byte de uma resposta. A latência inclui o tempo necessário para processar pedidos da API no back-end do Spanner e na camada da API. No entanto, esta latência não inclui a sobrecarga de rede ou de proxy inverso entre os clientes e os servidores do Spanner.
A métrica spanner.googleapis.com/api/request_latencies capta e expõe a latência do AFE do Spanner para pedidos do Spanner. Para mais informações, consulte o artigo
Métricas do Spanner.
Latência da consulta
A latência de consulta é o período (em milissegundos) necessário para executar consultas SQL na base de dados do Spanner.
A latência de consulta está disponível para a API executeSql.
Se o parâmetro
QueryMode
estiver definido como WITH_STATS ou WITH_PLAN_AND_STATS,
as propriedades
ResultSetStats
do Spanner estão disponíveis nas respostas. ResultSetStats inclui o tempo decorrido para executar consultas na base de dados do Spanner.
Para capturar e visualizar a latência das consultas, consulte o artigo Capture a latência das consultas com o OpenTelemetry.
O que se segue?
- Saiba como identificar pontos de latência nos componentes do Spanner.