
Auf dieser Seite wird beschrieben, wie Sie mithilfe von Messwerten und Diagrammen zur CPU-Auslastung zusammen mit anderen Tools zur Selbstbeobachtung die hohe CPU-Auslastung in Ihrer Datenbank untersuchen können.
Ermitteln, ob ein System oder eine Nutzeraufgabe eine hohe CPU-Auslastung verursacht
Die Google Cloud -Konsole bietet verschiedene Monitoring-Tools für Spanner, mit denen Sie den Status der wichtigsten Messwerte für Ihre Instanz abrufen können. Eines davon ist das Diagramm CPU-Auslastung – gesamt. Dieses Diagramm zeigt die gesamte CPU-Auslastung als Prozentsatz der CPU-Ressourcen der Instanz, aufgeschlüsselt nach Aufgabenpriorität und Vorgangstyp. Es gibt zwei Arten von Aufgaben: Nutzeraufgaben wie Lese- und Schreibvorgänge und Systemaufgaben, zu denen automatisierte Hintergrundaufgaben wie die Verdichtung und das Backfill von Indexen gehören.
Abbildung 1 zeigt ein Beispiel für das Diagramm CPU-Auslastung – gesamt.
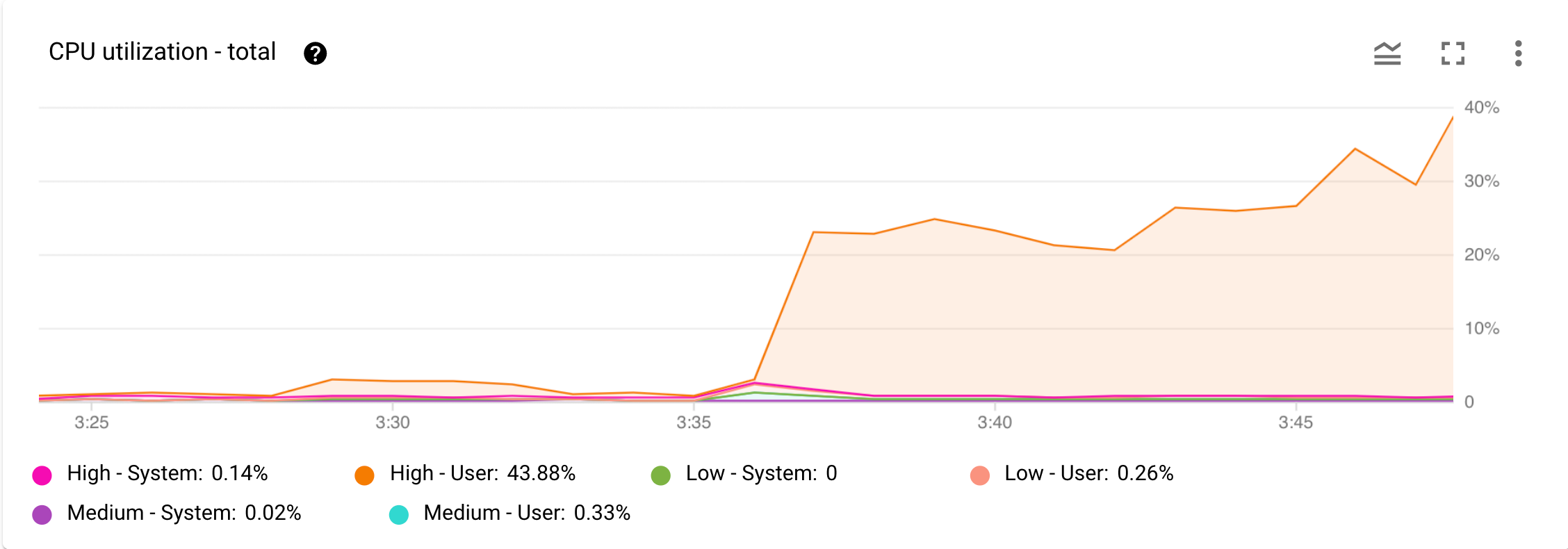
Abbildung 1. Diagramm zur CPU-Auslastung – gesamt im Monitoring-Dashboard in derGoogle Cloud -Konsole
Angenommen, Sie erhalten von Cloud Monitoring eine Benachrichtigung, dass die CPU-Auslastung deutlich gestiegen ist. Sie öffnen das Dashboard Monitoring für Ihre Instanz in der Google Cloud Console und prüfen das Diagramm CPU-Auslastung – Gesamt in der Google Cloud Console. Wie in Abbildung 1 gezeigt, sehen Sie die erhöhte CPU-Auslastung durch Nutzeraufgaben mit hoher Priorität. Der nächste Schritt besteht darin, herauszufinden, welcher Nutzervorgang mit hoher Priorität die Erhöhung der CPU-Auslastung verursacht.
Sie können diese und andere Messwerte in einer Zeitreihe mithilfe von Query Insights-Dashboards visualisieren. Mit diesen vorgefertigten Dashboards können Sie Spitzen bei der CPU-Auslastung sehen und ineffiziente Abfragen identifizieren.
Ermitteln, welcher Nutzervorgang die Spitze der CPU-Auslastung verursacht
Das Diagramm CPU-Auslastung – Gesamt in Abbildung 1 zeigt, dass Nutzeraufgaben mit hoher Priorität die CPU-Auslastung erhöhen.
Als Nächstes untersuchen Sie das Diagramm zur CPU-Auslastung nach Vorgangstyp in derGoogle Cloud console. Dieses Diagramm zeigt die CPU-Auslastung, aufgeschlüsselt nach vom Nutzer initiierten Vorgängen mit hoher, mittlerer und niedriger Priorität.
Was ist ein vom Nutzer initiierter Vorgang?
Ein vom Nutzer initiierter Vorgang ist ein Vorgang, der über eine API-Anfrage initiiert wird. Spanner gruppiert diese Anfragen in Vorgangstypen oder Kategorien. Jeder Vorgangstyp kann als Linie im Diagramm CPU-Auslastung nach Vorgangstyp angezeigt werden. In der folgenden Tabelle werden die API-Methoden beschrieben, die in den einzelnen Vorgangstypen enthalten sind.
| Aktion | API-Methoden | Beschreibung |
|---|---|---|
| read_readonly | Read StreamingRead |
Enthält Lesevorgänge, die Zeilen mit Schlüsselsuchen und -scans aus der Datenbank abrufen. |
| read_readwrite | Read StreamingRead |
Enthält Lesevorgänge in Lese-Schreib-Transaktionen. |
| read_withpartitiontoken | Read StreamingRead |
Umfasst Lesevorgänge, die mit einer Reihe von Partitionstokens ausgeführt werden. |
| executesql_select_readonly | ExecuteSql ExecuteStreamingSql |
Enthält eine Anweisung zum Ausführen von Select-SQL und Change Stream-Abfragen. |
| executesql_select_readwrite | ExecuteSql ExecuteStreamingSql |
Enthält eine Anweisung zum Ausführen von Select innerhalb von Lese-Schreib-Transaktionen. |
| executesql_select_withpartitiontoken | ExecuteSql ExecuteStreamingSql |
Enthält eine Anweisung zum Ausführen von Select, die mit einer Reihe von Partitionstokens ausgeführt wird. |
| executesql_dml_readwrite | ExecuteSql ExecuteStreamingSql ExecuteBatchDml |
Enthält eine Anweisung zum Ausführen der DML-SQL-Anweisung. |
| executesql_dml_partitioned | ExecuteSql ExecuteStreamingSql ExecuteBatchDml |
Enthält eine partitionierte DML-SQL-Anweisung. |
| beginorcommit | BeginTransaction Commit Rollback |
Enthält Anfangs-, Commit- und Rollback-Transaktionen. |
| misc | PartitionQuery PartitionRead GetSession CreateSession |
Enthält PartitionQuery, PartitionRead, Create Database, Create Instance, sitzungsbezogene Vorgänge, interne zeitkritische Bereitstellungsvorgänge usw. |
Hier ein Beispieldiagramm des Messwerts CPU-Auslastung nach Vorgangstyp.
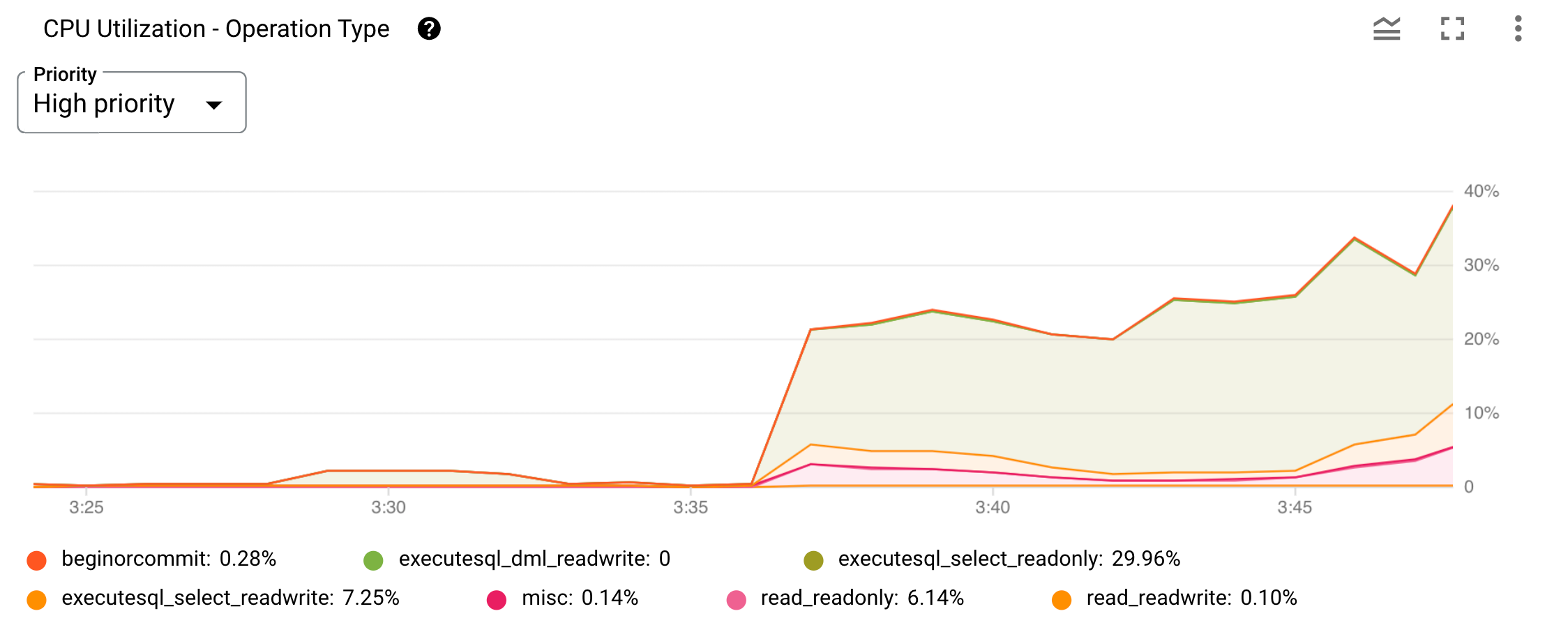
Abbildung 2. Diagramm zur CPU-Auslastung nach Vorgangstyp in derGoogle Cloud -Konsole
Sie können die Anzeige auf eine bestimmte Priorität beschränken, indem Sie das Menü Priorität oben im Diagramm verwenden. Jeder Vorgangstyp oder jede Kategorie wird in einem Liniendiagramm dargestellt. Die Kategorien unter dem Diagramm identifizieren die entsprechende Grafik. Sie können jedes Diagramm ausblenden und anzeigen lassen, indem Sie den entsprechenden Kategoriefilter auswählen oder die Auswahl aufheben.
Alternativ können Sie dieses Diagramm auch im Metrics Explorer erstellen, wie unten beschrieben:
Diagramm zur CPU-Auslastung nach Vorgangstyp im Metrics Explorer erstellen
- Wählen Sie in der Google Cloud Console Monitoring aus oder klicken Sie auf die folgende Schaltfläche:
- Wählen Sie im Navigationsbereich den Metrics Explorer aus.
-
Geben Sie im Feld Ressourcentyp und Messwert suchen den Wert
spanner.googleapis.com/instance/cpu/utilization_by_operation_typeein und klicken Sie dann auf die Zeile, die unter dem Feld angezeigt wird. -
Geben Sie im Feld Filter den Wert
instance_idein. Geben Sie dann die Instanz-ID ein, die Sie prüfen möchten, und klicken Sie auf >Übernehmen. -
Wählen Sie im Feld Gruppieren nach aus der Drop-down-Liste
categoryaus. Das Diagramm zeigt die CPU-Auslastung der Nutzeraufgaben, gruppiert nach Vorgangstyp oder Kategorie.
Während der Messwert CPU-Auslastung nach Priorität im vorherigen Abschnitt dabei geholfen hat, festzustellen, ob eine Nutzer- oder Systemaufgabe eine Erhöhung der CPU-Ressourcennutzung verursacht hat, können Sie mit dem Messwert CPU-Auslastung nach Vorgangstyp genauer untersuchen, welche Art von vom Nutzer initiiertem Vorgang für diesen Anstieg der CPU-Auslastung verantwortlich ist.
Ermitteln, welche Nutzeranfrage zu einer erhöhten CPU-Auslastung beiträgt
Zur Feststellung, welche Nutzeranfrage für den Anstieg der CPU-Auslastung in der Grafik zum Ausführungstyp executesql_select_readonly konkret verantwortlich ist, die Sie in Abbildung 2 sehen, verwenden Sie die integrierten Statistiktabellen zur Selbstprüfung und erhalten so mehr Einblick.
Verwenden Sie die folgende Tabelle als Leitfaden, um anhand des Vorgangstyps, der eine hohe CPU-Auslastung verursacht, zu ermitteln, welche Statistiktabelle abgefragt werden soll.
| Vorgangstyp | Abfrage | Lesen | Transaktion |
|---|---|---|---|
| read_readonly | Nein | Ja | Nein |
| read_readwrite | Nein | Ja | Ja |
| read_withpartitiontoken | Nein | Ja | Nein |
| executesql_select_readonly | Ja | Nein | Nein |
| executesql_select_withpartitiontoken | Ja | Nein | Nein |
| executesql_select_readwrite | Ja | Nein | Ja |
| executesql_dml_readwrite | Ja | Nein | Ja |
| executesql_dml_partitioned | Nein | Nein | Ja |
| beginorcommit | Nein | Nein | Ja |
Wenn beispielsweise read_withpartitiontoken das Problem ist, beheben Sie den Fehler mithilfe von Lesestatistiken.
In diesem Szenario scheint der Vorgang executesql_select_readonly der Grund für die beobachtete Erhöhung der CPU-Auslastung zu sein. Anhand der vorhergehenden Tabelle sollten Sie sich als Nächstes Abfragestatistiken ansehen, um herauszufinden, welche Abfragen teuer sind, häufig ausgeführt werden oder große Datenmengen scannen.
Führen Sie die folgende Abfrage in der Statistiktabelle query_stats_top_hour aus, um die Abfragen mit der höchsten CPU-Auslastung der vorherigen Stunde zu ermitteln.
SELECT text,
execution_count AS count,
avg_latency_seconds AS latency,
avg_cpu_seconds AS cpu,
execution_count * avg_cpu_seconds AS total_cpu
FROM spanner_sys.query_stats_top_hour
WHERE interval_end =
(SELECT MAX(interval_end)
FROM spanner_sys.query_stats_top_hour)
ORDER BY total_cpu DESC;
Die Ausgabe zeigt Abfragen, sortiert nach CPU-Auslastung. Nachdem Sie die Abfrage mit der höchsten CPU-Auslastung ermittelt haben, können Sie sie mit den folgenden Optionen optimieren.
Prüfen Sie den Abfrageausführungsplan, um mögliche Ineffizienzen zu ermitteln, die zu einer hohen CPU-Auslastung führen können.
Prüfen Sie, ob die Abfrage den Best Practices für SQL entspricht.
Prüfen Sie das Schemadesign der Datenbank und aktualisieren Sie das Schema, um effizientere Abfragen zu ermöglichen.
Richten Sie eine Referenz für die Häufigkeit ein, mit der Spanner eine Abfrage während eines Intervalls ausführt. Mit dieser Referenz können Sie die Ursache für unerwartete Abweichungen vom normalen Verhalten erkennen und untersuchen.
Wenn Sie keine CPU-intensive Abfrage gefunden haben, fügen Sie der Instanz Rechenkapazität hinzu. Weitere Rechenkapazitäten bieten mehr CPU-Ressourcen und geben Spanner die Möglichkeit, eine größere Arbeitslast zu bewältigen. Weitere Informationen finden Sie unter Rechenkapazität erhöhen.
Nächste Schritte
Weitere Informationen zu Tools zur Selbstbeobachtung
SQL-Best-Practices für Spanner
Liste der Messwerte aus Spanner ansehen