
本文档概述了如何将图查询语言与 Spanner Graph 搭配使用,包括其图模式匹配语法,并介绍了如何针对图运行查询。借助 Spanner Graph,您可以运行查询来查找模式、遍历关系,并从属性图数据中获取数据分析洞见。
本文档中的示例使用您在设置和查询 Spanner Graph 中创建的图表架构。下图对此进行了说明。
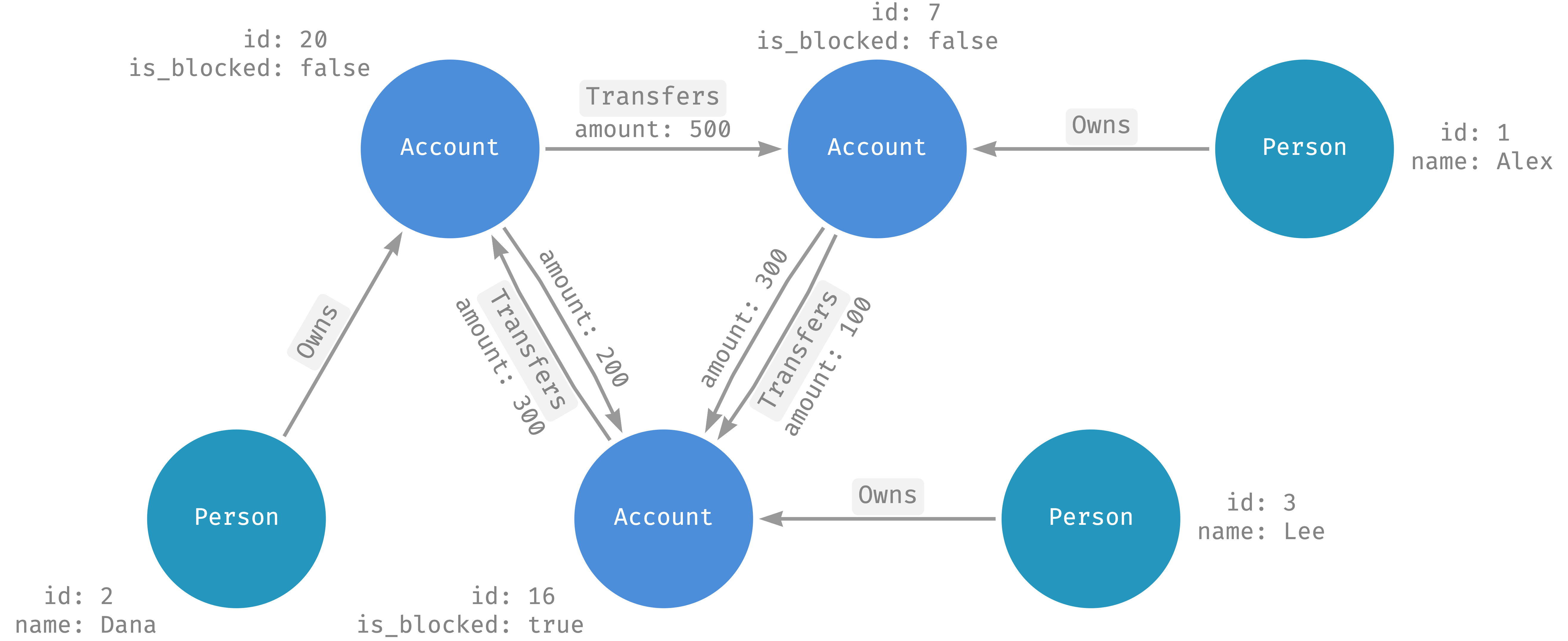
运行 Spanner Graph 查询
您可以使用 Google Cloud 控制台、Google Cloud CLI、客户端库、REST API 或 RPC API 运行 Spanner 图查询。
Google Cloud 控制台
以下步骤介绍了如何在Google Cloud 控制台中运行查询。这些步骤假设您有一个名为 test-instance 的实例,其中包含一个名为 example-db 的数据库。如需了解如何创建包含数据库的实例,请参阅设置和查询 Spanner Graph。
在 Google Cloud 控制台中,前往 Spanner 实例页面。
点击名为
test-instance的实例。在数据库下,点击名为
example-db的数据库。打开 Spanner Studio,然后点击 新标签页或使用编辑器标签页。
在查询编辑器中输入查询。
点击运行。
gcloud CLI
如需使用 gcloud CLI 命令行工具提交查询,请执行以下操作:
安装 gcloud CLI(如果尚未安装)。
在 gcloud CLI 中,运行以下命令:
如需了解详情,请参阅 Spanner CLI 快速入门。
REST API
如需使用 REST API 提交查询,请使用以下命令之一:
如需了解详情,请参阅使用 REST API 查询数据和使用 REST 开始使用 Spanner。
RPC API
如需使用 RPC API 提交查询,请使用以下命令之一:
客户端库
如需详细了解如何使用 Spanner 客户端库运行查询,请参阅以下内容:
- 使用 Spanner C++ 客户端库进行查询
- 使用 Spanner C# 客户端库进行查询
- 使用 Spanner Go 客户端库进行查询
- 使用 Spanner Java 客户端库进行查询
- 使用 Spanner Node.js 客户端库进行查询
- 使用 Spanner PHP 客户端库进行查询
- 使用 Spanner Python 客户端库进行查询
- 使用 Spanner Ruby 客户端库进行查询
如需详细了解 Spanner 客户端库,请参阅 Spanner 客户端库概览。
直观呈现 Spanner Graph 查询结果
您可以在 Google Cloud 控制台的 Spanner Studio 中查看 Spanner Graph 查询结果的可视化表示形式。通过查询可视化图表,您可以了解返回的元素(节点和边)之间的连接方式。这可以揭示在表格中查看结果时难以发现的模式、依赖关系和异常情况。如需查看查询的可视化图表,查询必须以 JSON 格式返回完整节点。否则,您只能以表格格式查看查询结果。如需了解详情,请参阅使用 Spanner Graph 查询可视化图表。
Spanner Graph 查询结构
Spanner Graph 查询由多个组件组成,例如属性图名称、节点和边模式以及量词。您可以使用这些组件创建查询,以在图表中查找特定模式。本文档的图模式匹配部分介绍了每个组件。
图 2 中的查询展示了 Spanner Graph 查询的基本结构。查询首先使用 GRAPH 子句指定目标图表 FinGraph。然后,MATCH 子句定义要搜索的模式。在本例中,它是通过 Owns 边连接到 Account 节点的 Person 节点。RETURN 子句用于指定要返回的匹配节点的哪些属性。

图表模式匹配
图表模式匹配可在图表中查找特定模式。最基本的模式是元素模式,例如匹配节点的节点模式和匹配边的边模式。
节点模式
节点模式用于匹配图表中的节点。此模式包含一对匹配的圆括号,其中可选择包含图形模式变量、标签表达式和属性过滤器。
查找所有节点
以下查询会返回图表中的所有节点。变量 n(称为图表模式变量)会绑定到匹配节点。在这种情况下,节点模式会匹配图表中的所有节点。
GRAPH FinGraph
MATCH (n)
RETURN LABELS(n) AS label, n.id;
此查询会返回 label 和 id:
| 标签 | id |
|---|---|
| 账号 | 7 |
| 账号 | 16 |
| 账号 | 20 |
| 用户 | 1 |
| 用户 | 2 |
| 用户 | 3 |
查找具有特定标签的所有节点
以下查询会匹配图中具有 Person
标签的所有节点。该查询会返回匹配节点的 label 以及 id、name 属性。
GRAPH FinGraph
MATCH (p:Person)
RETURN LABELS(p) AS label, p.id, p.name;
此查询会返回匹配节点的以下属性:
| 标签 | id | name |
|---|---|---|
| 用户 | 1 | Alex |
| 用户 | 2 | Dana |
| 用户 | 3 | Lee |
查找与标签表达式匹配的所有节点
您可以创建包含一个或多个逻辑运算符的标签表达式。 例如,以下查询会匹配图表中具有 Person 或 Account 标签的所有节点。图表模式变量 n 公开具有 Person 或 Account 标签的节点的所有属性。
GRAPH FinGraph
MATCH (n:Person|Account)
RETURN LABELS(n) AS label, n.id, n.birthday, n.create_time;
在此查询的以下结果中:
- 所有节点都具有
id属性。 - 与
Account标签匹配的节点具有create_time属性,但不具有birthday属性。对于这些节点,birthday属性为NULL。 - 与
Person标签匹配的节点具有birthday属性,但不具有create_time属性。对于这些节点,create_time属性为NULL。
| 标签 | id | 生日 | create_time |
|---|---|---|---|
| 账号 | 7 | NULL | 2020-01-10T14:22:20.222Z |
| 账号 | 16 | NULL | 2020-01-28T01:55:09.206Z |
| 账号 | 20 | NULL | 2020-02-18T13:44:20.655Z |
| 用户 | 1 | 1991-12-21T08:00:00Z | NULL |
| 用户 | 2 | 1980-10-31T08:00:00Z | NULL |
| 用户 | 3 | 1986-12-07T08:00:00Z | NULL |
查找与标签表达式和属性过滤条件匹配的所有节点
以下查询会匹配图表中具有 Person 标签且属性 id 等于 1 的所有节点。
GRAPH FinGraph
MATCH (p:Person {id: 1})
RETURN LABELS(p) AS label, p.id, p.name, p.birthday;
查询结果如下:
| 标签 | id | name | 生日 |
|---|---|---|---|
| 用户 | 1 | Alex | 1991-12-21T08:00:00Z |
您可以使用 WHERE 子句对标签和属性构造更复杂的过滤条件。
以下查询使用 WHERE 子句对属性构造更复杂的过滤条件。它会匹配图表中具有 Person 标签且属性 birthday 在 1990-01-10 之前的所有节点。
GRAPH FinGraph
MATCH (p:Person WHERE p.birthday < '1990-01-10')
RETURN LABELS(p) AS label, p.name, p.birthday;
查询结果如下:
| 标签 | name | 生日 |
|---|---|---|
| 用户 | Dana | 1980-10-31T08:00:00Z |
| 用户 | Lee | 1986-12-07T08:00:00Z |
边缘模式
边缘模式用于匹配节点之间的边缘或关系。边缘模式用英文方括号 ([]) 括起来,并使用符号(例如 -、-> 或 <-)表示方向。边模式可以选择性地包含图表模式变量,以绑定到匹配的边。
查找具有匹配标签的所有边缘
此查询会返回图中具有 Transfers 标签的所有边。相应查询会将图表模式变量 e 绑定到匹配的边。
GRAPH FinGraph
MATCH -[e:Transfers]->
RETURN e.Id as src_account, e.order_number
查询结果如下:
| src_account | order_number |
|---|---|
| 7 | 304330008004315 |
| 7 | 304120005529714 |
| 16 | 103650009791820 |
| 20 | 304120005529714 |
| 20 | 302290001255747 |
查找与标签表达式和属性过滤条件匹配的所有边缘
此查询的边模式使用标签表达式和属性过滤条件来查找所有标记为 Transfers 且与指定 order_number 匹配的边。
GRAPH FinGraph
MATCH -[e:Transfers {order_number: "304120005529714"}]->
RETURN e.Id AS src_account, e.order_number
查询结果如下:
| src_account | order_number |
|---|---|
| 7 | 304120005529714 |
| 20 | 304120005529714 |
使用任意方向边缘模式查找所有边
您可以在查询中使用 any direction 边缘模式 (-[]-) 来匹配任意方向的边缘。以下查询会查找涉及被屏蔽账号的所有资金转移。
GRAPH FinGraph
MATCH (account:Account)-[transfer:Transfers]-(:Account {is_blocked:true})
RETURN transfer.order_number, transfer.amount;
查询结果如下:
| order_number | 金额 |
|---|---|
| 304330008004315 | 300 |
| 304120005529714 | 100 |
| 103650009791820 | 300 |
| 302290001255747 | 200 |
路径模式
路径模式由交替的节点模式和边缘模式构建而成。
使用路径模式查找特定节点的所有路径
以下查询会查找从 Person 所拥有且 id 等于 2 的账号发起的所有针对账号的资金转移。
每个匹配的结果都表示一条路径,该路径从 Person {id: 2} 开始,通过使用 Owns 边缘连接的 Account,使用 Transfers 边缘进入另一个 Account。
GRAPH FinGraph
MATCH
(p:Person {id: 2})-[:Owns]->(account:Account)-[t:Transfers]->
(to_account:Account)
RETURN
p.id AS sender_id, account.id AS from_id, to_account.id AS to_id;
查询结果如下:
| sender_id | from_id | to_id |
|---|---|---|
| 2 | 20 | 7 |
| 2 | 20 | 16 |
量化路径模式
量化模式会在指定范围内重复某个模式。
匹配量化边缘模式
如需查找长度可变的路径,您可以将量词应用于边模式。以下查询通过查找与来源 Account(其中 id 为 7)相距一到三次资金转移的目标账号来演示这一点。
该查询将限定符 {1, 3} 应用于边缘模式 -[e:Transfers]->。这会指示查询匹配重复 Transfers 边模式一次、两次或三次的路径。WHERE 子句用于从结果中排除源账号。ARRAY_LENGTH 函数用于访问 group variable e。如需了解详情,请参阅访问权限群组变量。
GRAPH FinGraph
MATCH (src:Account {id: 7})-[e:Transfers]->{1, 3}(dst:Account)
WHERE src != dst
RETURN src.id AS src_account_id, ARRAY_LENGTH(e) AS path_length, dst.id AS dst_account_id;
查询结果如下:
| src_account_id | path_length | dst_account_id |
|---|---|---|
| 7 | 1 | 16 |
| 7 | 1 | 16 |
| 7 | 1 | 16 |
| 7 | 3 | 16 |
| 7 | 3 | 16 |
| 7 | 2 | 20 |
| 7 | 2 | 20 |
结果中的某些行会重复。这是因为同一来源节点和目标节点之间可能存在多条符合相应模式的路径,而查询会返回所有这些路径。
匹配量化路径模式
以下查询会查找 Account 节点之间经过被屏蔽的中间账号且包含 1 到 2 条 Transfers 边缘的路径。
带英文圆括号的路径模式会进行量化,并且其 WHERE 子句会指定重复模式的条件。
GRAPH FinGraph
MATCH
(src:Account)
((a:Account)-[:Transfers]->(b:Account {is_blocked:true}) WHERE a != b){1,2}
-[:Transfers]->(dst:Account)
RETURN src.id AS src_account_id, dst.id AS dst_account_id;
查询结果如下:
| src_account_id | dst_account_id |
|---|---|
| 7 | 20 |
| 7 | 20 |
| 20 | 20 |
群组变量
在量化模式之外访问时,在量化模式中声明的图形模式变量会成为群组变量。然后,它会绑定到匹配的图元素数组。
您可以将群组变量作为数组进行访问。其图形元素以沿着匹配路径显示的顺序保留。您可以使用水平汇总来汇总群组变量。
访问权限群组变量
在以下示例中,变量 e 的访问方式如下所示:
- 一个图形模式变量,当它位于量化模式中时,会绑定到
WHERE子句e.amount > 100中的单个边缘。 - 一个群组变量,该变量绑定到
RETURN语句的ARRAY_LENGTH(e)中的边缘元素数组(量化模式之外)。 - 一个已绑定到边缘元素数组的群组变量,该数组按量化模式之外的
SUM(e.amount)进行汇总。这是水平汇总示例。
GRAPH FinGraph
MATCH
(src:Account {id: 7})-[e:Transfers WHERE e.amount > 100]->{0,2}
(dst:Account)
WHERE src.id != dst.id
LET total_amount = SUM(e.amount)
RETURN
src.id AS src_account_id, ARRAY_LENGTH(e) AS path_length,
total_amount, dst.id AS dst_account_id;
查询结果如下:
| src_account_id | path_length | total_amount | dst_account_id |
|---|---|---|---|
| 7 | 1 | 300 | 16 |
| 7 | 2 | 600 | 20 |
路径搜索前缀
如需限制组中共享来源节点和目标节点的匹配路径,您可以使用 ANY、ANY SHORTEST 或 ANY CHEAPEST 路径搜索前缀。您只能在整个路径模式之前应用这些前缀,而不能在英文圆括号内应用它们。
使用 ANY 进行匹配
以下查询会查找与给定 Account 节点相距 1 个或 2 个 Transfers 的所有可到达的唯一账号。
ANY 路径搜索前缀可确保查询在一对唯一的 src 和 dst Account 节点之间仅返回一条路径。在以下示例中,虽然您可以从来源节点 Account 通过两条不同路径到达具有 {id: 16} 的 Account 节点,但结果仅包含一条路径。
GRAPH FinGraph
MATCH ANY (src:Account {id: 7})-[e:Transfers]->{1,2}(dst:Account)
LET ids_in_path = ARRAY_CONCAT(ARRAY_AGG(e.Id), [dst.Id])
RETURN src.id AS src_account_id, dst.id AS dst_account_id, ids_in_path;
查询结果如下:
| src_account_id | dst_account_id | ids_in_path |
|---|---|---|
| 7 | 16 | 7,16 |
| 7 | 20 | 7,16,20 |
使用 ANY SHORTEST 进行匹配
ANY SHORTEST 路径搜索前缀会为每对源节点和目标节点返回一条路径,该路径是从边数最少的路径中选择的。
例如,以下查询会查找 id 为 7 的 Account 节点与 id 为 20 的 Account 节点之间最短的一条路径。该查询会考虑包含 1 到 3 条 Transfers 边的路径。
GRAPH FinGraph
MATCH ANY SHORTEST (src:Account {id: 7})-[e:Transfers]->{1, 3}(dst:Account {id: 20})
RETURN src.id AS src_account_id, dst.id AS dst_account_id, ARRAY_LENGTH(e) AS path_length;
查询结果如下:
| src_account_id | dst_account_id | path_length |
|---|---|---|
| 7 | 20 | 2 |
使用 ANY CHEAPEST 进行匹配
ANY CHEAPEST 路径搜索前缀可确保对于每对来源账号和目标账号,查询仅返回一条总计算成本最低的路径。
以下查询会查找 Account 节点之间总计算成本最低的路径。此成本基于 Transfers 边的 amount 属性之和。该搜索会考虑包含 1 到 3 条 Transfers 边的路径。
GRAPH FinGraph
MATCH ANY CHEAPEST (src:Account)-[e:Transfers COST e.amount]->{1,3}(dst:Account)
LET total_cost = sum(e.amount)
RETURN src.id AS src_account_id, dst.id AS dst_account_id, total_cost
查询结果如下:
| src_account_id | dst_account_id | total_cost |
|---|---|---|
| 7 | 7 | 900 |
| 7 | 16 | 100 |
| 7 | 20 | 400 |
| 16 | 7 | 800 |
| 16 | 16 | 500 |
| 16 | 20 | 300 |
| 20 | 7 | 500 |
| 20 | 16 | 200 |
| 20 | 20 | 500 |
图表模式
图表模式由一个或多个以英文逗号 (,) 分隔的路径模式组成。图表模式可以包含 WHERE 子句,该子句可让您访问路径模式中的所有图表模式变量,以构成过滤条件。每个路径模式都会生成一个路径集合。
使用图表模式进行匹配
以下查询可识别超过 200 的交易金额中涉及的中间账号及其所有者,资金通过这些账号从来源账号转移到被屏蔽账号。
以下路径模式构成了该图形模式:
- 第一种模式会查找使用中间账号将资金从一个账号转移到被屏蔽账号的路径。
- 第二种模式会查找从账号到其所有者的路径。
变量 interm 充当两个路径模式之间的通用链接,这需要 interm 在两个路径模式中引用相同的元素节点。这会根据 interm 变量创建等值联接操作。
GRAPH FinGraph
MATCH
(src:Account)-[t1:Transfers]->(interm:Account)-[t2:Transfers]->(dst:Account),
(interm)<-[:Owns]-(p:Person)
WHERE dst.is_blocked = TRUE AND t1.amount > 200 AND t2.amount > 200
RETURN
src.id AS src_account_id, dst.id AS dst_account_id,
interm.id AS interm_account_id, p.id AS owner_id;
查询结果如下:
| src_account_id | dst_account_id | interm_account_id | owner_id |
|---|---|---|---|
| 20 | 16 | 7 | 1 |
线性查询语句
您可以将多个图表语句链接在一起,以组成线性查询语句。语句的执行顺序与它们在查询中的出现顺序相同。
每个语句都将前一个语句的输出作为输入。第一个语句的输入为空。
最后一个语句的输出是最终结果。
例如,您可以使用线性查询语句来查找向被屏蔽账号进行的最大资金转移。以下查询会查找向被屏蔽账号转出资金最多的账号及其所有者。
GRAPH FinGraph
MATCH (src_account:Account)-[transfer:Transfers]->(dst_account:Account {is_blocked:true})
ORDER BY transfer.amount DESC
LIMIT 1
MATCH (src_account:Account)<-[owns:Owns]-(owner:Person)
RETURN src_account.id AS account_id, owner.name AS owner_name;
下表通过显示在每个语句之间传递的中间结果来说明此过程。为简洁起见,仅显示部分属性。
| Statement | 中间结果(缩写) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
MATCH
(src_account:Account)
-[transfer:Transfers]->
(dst_account:Account {is_blocked:true})
|
|
||||||||||||
ORDER BY transfer.amount DESC |
|
||||||||||||
LIMIT 1 |
|
||||||||||||
MATCH
(src_account:Account)
<-[owns:Owns]-
(owner:Person)
|
|
||||||||||||
RETURN
src_account.id AS account_id,
owner.name AS owner_name
|
|
查询结果如下:
| account_id | owner_name |
|---|---|
7 |
Alex |
return 语句
RETURN 语句指定要从匹配的模式返回的内容。它可以访问图表模式变量,并包含表达式和其他子句,例如 ORDER BY 和 GROUP BY。
Spanner Graph 不支持以查询结果的形式返回图表元素。如需返回整个图表元素,请使用 TO_JSON 函数或 SAFE_TO_JSON 函数。在这两个函数中,我们建议您使用 SAFE_TO_JSON。
以 JSON 格式返回图表元素
GRAPH FinGraph
MATCH (n:Account {id: 7})
-- Returning a graph element in the final results is NOT allowed. Instead, use
-- the TO_JSON function or explicitly return the graph element's properties.
RETURN TO_JSON(n) AS n;
GRAPH FinGraph
MATCH (n:Account {id: 7})
-- Certain fields in the graph elements, such as TOKENLIST, can't be returned
-- in the TO_JSON function. In those cases, use the SAFE_TO_JSON function instead.
RETURN SAFE_TO_JSON(n) AS n;
查询结果如下:
| n |
|---|
{"identifier":"mUZpbkdyYXBoLkFjY291bnQAeJEO","kind":"node","labels":["Account"],"properties":{"create_time":"2020-01-10T14:22:20.222Z","id":7,"is_blocked":false,"nick_name":"Vacation
Fund"}} |
使用 NEXT 关键字编写更大的查询
您可以使用 NEXT 关键字将多个图表线性查询语句链接在一起。第一个语句接收空输入,而每个后续语句的输出都会成为下一个语句的输入。
以下示例通过将多个图线性语句链接在一起,查找收到转账次数最多的账号的所有者。您可以使用同一变量(例如 account)在多个线性语句中引用同一图元素。
GRAPH FinGraph
MATCH (:Account)-[:Transfers]->(account:Account)
RETURN account, COUNT(*) AS num_incoming_transfers
GROUP BY account
ORDER BY num_incoming_transfers DESC
LIMIT 1
NEXT
MATCH (account:Account)<-[:Owns]-(owner:Person)
RETURN account.id AS account_id, owner.name AS owner_name, num_incoming_transfers;
查询结果如下:
| account_id | owner_name | num_incoming_transfers |
|---|---|---|
16 |
Lee |
3 |
函数和表达式
您可以在 Spanner Graph 查询中使用所有 GoogleSQL 函数(聚合函数和标量函数)、运算符和条件表达式。Spanner Graph 还支持特定于图表的函数和运算符。
内置函数和运算符
PROPERTY_EXISTS(n, birthday):返回n是否具有birthday属性。LABELS(n):返回图表架构中定义的n的标签。PROPERTY_NAMES(n):返回n的属性名称。TO_JSON(n):返回 JSON 格式的n。如需了解详情,请参阅TO_JSON函数。
PROPERTY_EXISTS 谓词、LABELS 函数和 TO_JSON 函数,以及 ARRAY_AGG 和 CONCAT 等其他内置函数。
GRAPH FinGraph
MATCH (person:Person)-[:Owns]->(account:Account)
RETURN person, ARRAY_AGG(account.nick_name) AS accounts
GROUP BY person
NEXT
RETURN
LABELS(person) AS labels,
TO_JSON(person) AS person,
accounts,
CONCAT(person.city, ", ", person.country) AS location,
PROPERTY_EXISTS(person, is_blocked) AS is_blocked_property_exists,
PROPERTY_EXISTS(person, name) AS name_property_exists
LIMIT 1;
查询结果如下:
| is_blocked_property_exists | name_property_exists | 标签 | 账号 | 地理位置 | 人 |
|---|---|---|---|---|---|
false |
true |
Person |
["Vacation Fund"] |
Adelaide, Australia |
{"identifier":"mUZpbkdyYXBoLlBlcnNvbgB4kQI=","kind":"node","labels":["Person"],"properties":{"birthday":"1991-12-21T08:00:00Z","city":"Adelaide","country":"Australia","id":1,"name":"Alex"}} |
子查询
子查询是嵌套在另一个查询中的查询。以下列表列出了 Spanner Graph 子查询规则:
- 子查询包含在一对英文大括号
{}内。 - 子查询可以从前导
GRAPH子句开始,以指定范围内的图表。指定的图表不需要与外部查询中使用的图表相同。 - 如果子查询中省略了
GRAPH子句,则会发生以下情况:- 范围内的图表是从最接近的外部查询上下文推理出来的。
- 子查询必须从具有
MATCH的图表模式匹配语句开始
- 在子查询范围外部声明的图形模式变量无法在子查询内再次声明,但可以在子查询内的表达式或函数中引用该变量。
使用子查询查找每个账号进行的资金转移总次数
以下查询演示了如何使用 VALUE 子查询。子查询用 {} 括起来,前缀为 VALUE 关键字。查询会返回从账号发起的转账总次数。
GRAPH FinGraph
MATCH (p:Person)-[:Owns]->(account:Account)
RETURN p.name, account.id AS account_id, VALUE {
MATCH (a:Account)-[transfer:Transfers]->(:Account)
WHERE a = account
RETURN COUNT(transfer) AS num_transfers
} AS num_transfers;
查询结果如下:
| name | account_id | num_transfers |
|---|---|---|
Alex |
7 |
2 |
Dana |
20 |
2 |
Lee |
16 |
1 |
如需查看支持的子查询表达式列表,请参阅 Spanner Graph 子查询。
使用子查询查找每个人拥有的账号
以下查询将 CALL 语句与内嵌子查询搭配使用。MATCH
(p:Person) 语句会创建一个包含一列(名为 p)的表。此表中的每一行都包含一个 Person 节点。CALL (p) 语句针对此工作表中的每一行执行封闭的子查询。子查询会查找每位匹配人员 p 所拥有的账号。同一人的多个账号按账号 ID 排序。
该示例通过 MATCH
(p:Person) 子句声明了外部范围的节点变量 p。CALL (p) 语句引用了此变量。此声明允许您在子查询的路径模式中重新声明或多次声明节点变量。这样可确保内部和外部 p 节点变量绑定到图中的同一 Person 节点。如果 CALL 语句未声明节点变量 p,则子查询会将重新声明的变量 p 视为新变量。此新变量独立于外部范围变量,并且子查询不会多次声明它,因为子查询会返回不同的结果。如需了解详情,请参阅 CALL 语句。
GRAPH FinGraph
MATCH (p:Person)
CALL (p) {
MATCH (p)-[:Owns]->(a:Account)
RETURN a.Id AS account_Id
ORDER BY account_Id
}
RETURN p.name AS person_name, account_Id
ORDER BY person_name, account_Id;
结果
| person_name | account_Id |
|---|---|
| Alex | 7 |
| Dana | 20 |
| Lee | 16 |
查询参数
您可以使用参数查询 Spanner Graph。如需了解详情,请参阅 Spanner 客户端库中的语法,并了解如何使用参数查询数据。
以下查询演示了如何使用查询参数。
GRAPH FinGraph
MATCH (person:Person {id: @id})
RETURN person.name;
同时查询图表和表
您可以将图表查询与 SQL 结合使用,以便在单个语句中同时访问图表和表中的信息。
GRAPH_TABLE 运算符接受线性图表查询,并以表格形式返回其结果,该结果可以无缝集成到 SQL 查询中。这种互操作性可让您使用非图表内容丰富图表查询结果,反之亦然。
例如,您可以创建一个 CreditReports 表并插入一些信用报告,如以下示例所示:
CREATE TABLE CreditReports (
person_id INT64 NOT NULL,
create_time TIMESTAMP NOT NULL,
score INT64 NOT NULL,
) PRIMARY KEY (person_id, create_time);
INSERT INTO CreditReports (person_id, create_time, score)
VALUES
(1,"2020-01-10 06:22:20.222", 700),
(2,"2020-02-10 06:22:20.222", 800),
(3,"2020-03-10 06:22:20.222", 750);
接下来,您可以通过 GRAPH_TABLE 中的图模式匹配来识别特定人员,并将图查询结果与 CreditReports 表联接,以检索信用评分。
SELECT
gt.person.id,
credit.score AS latest_credit_score
FROM GRAPH_TABLE(
FinGraph
MATCH (person:Person)-[:Owns]->(:Account)-[:Transfers]->(account:Account {is_blocked:true})
RETURN DISTINCT person
) AS gt
JOIN CreditReports AS credit
ON gt.person.id = credit.person_id
ORDER BY credit.create_time;
查询结果如下:
| person_id | latest_credit_score |
|---|---|
1 |
700 |
2 |
800 |
后续步骤
了解对查询进行调优的最佳实践。