
目標
本教學課程將逐步引導您使用 REST 的 Cloud Spanner API 進行下列步驟:
- 建立 Spanner 執行個體和資料庫。
- 對資料庫中的資料進行寫入和讀取,以及執行 SQL 查詢。
- 更新資料庫結構定義。
- 將次要索引新增至資料庫。
- 使用索引對資料執行讀取作業和 SQL 查詢。
- 使用唯讀交易擷取資料。
如要使用 Spanner 用戶端程式庫,而非 REST API,請參閱教學課程。
費用
本教學課程使用 Spanner,這是Google Cloud的計費元件。如要瞭解 Spanner 的使用費用,請參閱定價。
事前準備
- 登入 Google Cloud 帳戶。如果您是 Google Cloud新手,歡迎 建立帳戶,親自評估產品在實際工作環境中的成效。新客戶還能獲得價值 $300 美元的免費抵免額,可用於執行、測試及部署工作負載。
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
發出 REST 呼叫的方式
您可以使用下列項目發出 Spanner REST 呼叫:
- Spanner API 參考文件中的「試試看!」功能。
- Google APIs Explorer,其中包含 Cloud Spanner API 和其他 Google API。
- 支援 HTTP REST 呼叫的其他工具或架構。
本頁面使用的慣例
範例使用
<var>PROJECT_ID</var>做為專案 ID。 Google Cloud 請將<var>PROJECT_ID</var>替換為您的專案 ID。 Google Cloud這些範例會建立及使用
test-instance的執行個體 ID。如未使用test-instance,請代入執行個體 ID。範例會建立及使用
example-db的資料庫 ID。如未使用example-db,請替換成資料庫 ID。範例會使用
<var>SESSION</var>做為工作階段名稱的一部分。請代入您在建立工作階段時收到的<var>SESSION</var>值。範例使用交易 ID
<var>TRANSACTION_ID</var>。建立<var>TRANSACTION_ID</var>的交易時,請代入您收到的值。「Try-It!」功能支援以互動方式新增個別 HTTP 要求欄位。本文中的大多數範例都會提供完整要求,而非說明如何以互動方式將個別欄位新增至要求。
執行個體
首次使用 Spanner 時,請建立執行個體。執行個體會分配 Spanner 資料庫使用的資源。建立執行個體時,請選擇資料儲存位置,以及執行個體的運算容量。
清單執行個體設定
建立執行個體時,請指定「執行個體設定」,定義該執行個體中資料庫的地理位置與複製功能。選擇區域設定,將資料儲存在一個區域;或選擇多區域設定,將資料分佈在多個區域。詳情請參閱「執行個體」。
使用 projects.instanceConfigs.list 判斷專案可用的設定。 Google Cloud
- 按一下 [
projects.instanceConfigs.list]。 在「parent」中輸入:
projects/PROJECT_ID
按一下 [Execute] (執行)。回應會顯示可用的執行個體設定。 以下是回應範例 (您的專案可能會有不同的執行個體設定):
{ "instanceConfigs": [ { "name": "projects/<var>PROJECT_ID</var>/instanceConfigs/regional-asia-south1", "displayName": "asia-south1" }, { "name": "projects/<var>PROJECT_ID</var>/instanceConfigs/regional-asia-east1", "displayName": "asia-east1" }, { "name": "projects/<var>PROJECT_ID</var>/instanceConfigs/regional-asia-northeast1", "displayName": "asia-northeast1" }, { "name": "projects/<var>PROJECT_ID</var>/instanceConfigs/regional-europe-west1", "displayName": "europe-west1" }, { "name": "projects/<var>PROJECT_ID</var>/instanceConfigs/regional-us-east4", "displayName": "us-east4" }, { "name": "projects/<var>PROJECT_ID</var>/instanceConfigs/regional-us-central1", "displayName": "us-central1" } ] }
建立執行個體時,您會使用其中一個執行個體設定的 name 值。
建立執行個體
- 按一下 [
projects.instances.create]。 在「parent」中輸入:
projects/<var>PROJECT_ID</var>點按「Add request body parameters」,然後選取
instance。按一下「執行個體」的提示泡泡,即可查看可能的欄位。為下列欄位新增值:
nodeCount:輸入1。config:輸入列出例項設定時傳回的其中一個區域例項設定的name值。displayName:輸入Test Instance。
按一下 instance 結尾方括號後方的提示泡泡,然後選取 instanceId。
如果是
instanceId,請輸入test-instance。
「Try It!」(試試看!) 執行個體建立頁面現在應如下所示: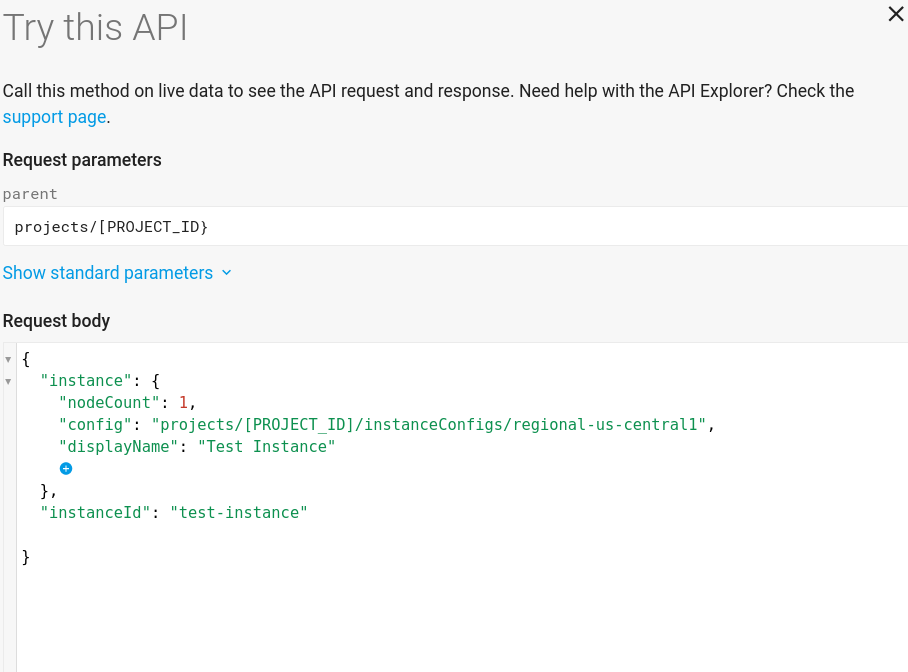
按一下 [Execute] (執行)。回應會傳回長時間執行的作業。查詢這項作業,即可查看狀態。
使用 projects.instances.list 列出執行個體。
建立資料庫
建立名為 example-db 的資料庫。
- 按一下 [
projects.instances.databases.create]。 在「parent」中輸入:
projects/<var>PROJECT_ID</var>/instances/test-instance點按「Add request body parameters」,然後選取
createStatement。在
createStatement中輸入:CREATE DATABASE `example-db`
資料庫名稱 example-db 含有連字號,因此請以倒引號 (`) 括住。
- 按一下「執行」。回應會傳回長時間執行的作業。查詢這項作業,即可查看狀態。
使用 projects.instances.databases.list 列出資料庫。
建立結構定義
使用 Spanner 的資料定義語言 (DDL) 建立、變更或刪除資料表,以及建立或刪除索引。
- 按一下 [
projects.instances.databases.updateDdl]。 在「database」中輸入:
projects/<var>PROJECT_ID</var>/instances/test-instance/databases/example-db在「Request body」部分,使用下列程式碼:
{ "statements": [ "CREATE TABLE Singers ( SingerId INT64 NOT NULL, FirstName STRING(1024), LastName STRING(1024), SingerInfo BYTES(MAX) ) PRIMARY KEY (SingerId)", "CREATE TABLE Albums ( SingerId INT64 NOT NULL, AlbumId INT64 NOT NULL, AlbumTitle STRING(MAX)) PRIMARY KEY (SingerId, AlbumId), INTERLEAVE IN PARENT Singers ON DELETE CASCADE" ] }statements陣列包含定義結構定義的 DDL 陳述式。按一下「執行」。回應會傳回長時間執行的作業。查詢這項作業,即可查看其狀態。
這個結構定義為基本音樂應用程式定義了兩個資料表:Singers 和 Albums。本文會使用這些表格。查看結構定義範例。
使用 projects.instances.databases.getDdl 擷取結構定義。
建立課程
新增、更新、刪除或查詢資料前,請先建立工作階段。工作階段代表與 Spanner 資料庫服務的通訊管道。(如果您使用 Spanner 用戶端程式庫,就不會直接使用工作階段,因為用戶端程式庫會代您管理工作階段)。
- 按一下 [
projects.instances.databases.sessions.create]。 在「database」中輸入:
projects/<var>PROJECT_ID</var>/instances/test-instance/databases/example-db點選「Execute」。
回應會顯示您建立的會期,格式如下:
projects/<var>PROJECT_ID</var>/instances/test-instance/databases/example-db/sessions/<var>SESSION</var>讀取或寫入資料庫時,請使用這個工作階段。
工作階段是為長期使用做準備。當工作階段閒置超過一小時,Spanner 資料庫服務會刪除工作階段。嘗試使用已刪除的工作階段會導致 NOT_FOUND。如果遇到這個錯誤,請建立並使用新的工作階段。使用 projects.instances.databases.sessions.get 查看工作階段是否仍有效。
如需相關資訊,請參閱「保持閒置工作階段的運作」。
工作階段是進階概念。如需更多詳細資料和最佳做法,請參閱「工作階段」。
接著,將資料寫入資料庫。
寫入資料
您可以使用 Mutation 型別寫入資料。Mutation 是變異作業的容器。Mutation 代表一系列的插入、更新、刪除和其他作業,這些作業會以不可分割的形式套用到 Spanner 資料庫中不同的資料列和資料表。
- 按一下 [
projects.instances.databases.sessions.commit]。 在「session」中輸入:
projects/<var>PROJECT_ID</var>/instances/test-instance/databases/example-db/sessions/<var>SESSION</var>在「Request body」部分,使用下列程式碼:
{ "singleUseTransaction": { "readWrite": {} }, "mutations": [ { "insertOrUpdate": { "table": "Singers", "columns": [ "SingerId", "FirstName", "LastName" ], "values": [ [ "1", "Marc", "Richards" ], [ "2", "Catalina", "Smith" ], [ "3", "Alice", "Trentor" ], [ "4", "Lea", "Martin" ], [ "5", "David", "Lomond" ] ] } }, { "insertOrUpdate": { "table": "Albums", "columns": [ "SingerId", "AlbumId", "AlbumTitle" ], "values": [ [ "1", "1", "Total Junk" ], [ "1", "2", "Go, Go, Go" ], [ "2", "1", "Green" ], [ "2", "2", "Forever Hold Your Peace" ], [ "2", "3", "Terrified" ] ] } } ] }按一下 [Execute] (執行)。回應會顯示提交時間戳記。
本範例使用 insertOrUpdate。Mutations 的其他作業包括 insert、update、replace 和 delete。
如要瞭解如何編碼資料型別,請參閱「TypeCode」。
使用 SQL 查詢資料
- 按一下 [
projects.instances.databases.sessions.executeSql]。 在「session」中輸入:
projects/<var>PROJECT_ID</var>/instances/test-instance/databases/example-db/sessions/<var>SESSION</var>在「Request body」部分,使用下列程式碼:
{ "sql": "SELECT SingerId, AlbumId, AlbumTitle FROM Albums" }按一下 [Execute] (執行)。回應會顯示查詢結果。
使用讀取 API 讀取資料
- 按一下 [
projects.instances.databases.sessions.read]。 在「session」中輸入:
projects/<var>PROJECT_ID</var>/instances/test-instance/databases/example-db/sessions/<var>SESSION</var>在「Request body」部分,使用下列程式碼:
{ "table": "Albums", "columns": [ "SingerId", "AlbumId", "AlbumTitle" ], "keySet": { "all": true } }按一下 [Execute] (執行)。回應會顯示讀取結果。
更新資料庫結構定義
在 Albums 表格中新增名為 MarketingBudget 的資料欄。不過,您須更新資料庫結構定義,Spanner 可支援更新資料庫結構定義,同時讓資料庫持續處理流量。結構定義更新作業不需要讓資料庫離線,也不會鎖定整個資料表或資料欄;您可以在結構定義更新期間,持續將資料寫入資料庫。
新增資料欄
- 按一下 [
projects.instances.databases.updateDdl]。 在「database」中輸入:
projects/<var>PROJECT_ID</var>/instances/test-instance/databases/example-db在「Request body」部分,使用下列程式碼:
{ "statements": [ "ALTER TABLE Albums ADD COLUMN MarketingBudget INT64" ] } ``` The `statements` array contains the DDL statements that define the schema.按一下 [Execute] (執行)。即使 REST 呼叫傳回回應,這項作業也可能需要幾分鐘才能完成。回應會傳回長時間執行的作業。查詢這項作業,即可查看狀態。
將資料寫入新資料欄
這段程式碼會將資料寫入新資料欄,並在 Albums(1, 1) 和 Albums(2, 2) 這兩個索引鍵表示的資料列中將 MarketingBudget 一欄分別設為 100000 和 500000。
- 按一下 [
projects.instances.databases.sessions.commit]。 在「session」中輸入:
projects/<var>PROJECT_ID</var>/instances/test-instance/databases/example-db/sessions/<var>SESSION</var>(您會在建立工作階段時收到這個值)。
在「Request body」部分,使用下列程式碼:
{ "singleUseTransaction": { "readWrite": {} }, "mutations": [ { "update": { "table": "Albums", "columns": [ "SingerId", "AlbumId", "MarketingBudget" ], "values": [ [ "1", "1", "100000" ], [ "2", "2", "500000" ] ] } } ] }按一下 [Execute] (執行)。回應會顯示提交時間戳記。
執行 SQL 查詢或讀取呼叫,以擷取剛寫入的值。
- 按一下 [
projects.instances.databases.sessions.executeSql]。 在「session」中輸入:
projects/<var>PROJECT_ID</var>/instances/test-instance/databases/example-db/sessions/<var>SESSION</var>在「Request body」部分,使用下列程式碼:
{ "sql": "SELECT SingerId, AlbumId, MarketingBudget FROM Albums" }按一下 [Execute] (執行)。回應會顯示兩列,其中包含更新後的
MarketingBudget值:"rows": [ [ "1", "1", "100000" ], [ "1", "2", null ], [ "2", "1", null ], [ "2", "2", "500000" ], [ "2", "3", null ] ]
使用次要索引
如要擷取 Albums 中 AlbumTitle 值位於特定範圍內的所有資料列,請使用 SQL 陳述式或讀取呼叫,從 AlbumTitle 資料欄讀取所有值,然後捨棄不符合條件的資料列。不過,執行完整資料表掃描的費用高昂,對於內含大量資料列的資料表而言更是如此。如要加快以非主鍵資料欄做為搜尋條件時的資料列擷取速度,請在資料表建立次要索引。
您必須先更新結構定義,才能在現有資料表新增次要索引。如同其他結構定義更新,Spanner 支援在資料庫持續處理流量時新增索引。Spanner 會自動使用現有資料回填索引。補充作業可能需要幾分鐘才能完成,在這個過程中,您不需將資料庫設為離線,可照常執行特定資料表或資料欄的寫入作業。詳情請參閱索引補充作業。
新增次要索引後,Spanner 會自動將該索引用於可加快執行速度的 SQL 查詢。如果您使用讀取介面,請指定要使用的索引。
新增次要索引
使用 updateDdl 新增索引。
- 按一下 [
projects.instances.databases.updateDdl]。 在「database」中輸入:
projects/<var>PROJECT_ID</var>/instances/test-instance/databases/example-db在「Request body」部分,使用下列程式碼:
{ "statements": [ "CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle)" ] }按一下 [Execute] (執行)。即使 REST 呼叫傳回回應,這項作業也可能需要幾分鐘才能完成。回應會傳回長時間執行的作業。查詢這項作業,即可查看狀態。
使用索引查詢
- 按一下 [
projects.instances.databases.sessions.executeSql]。 在「session」中輸入:
projects/<var>PROJECT_ID</var>/instances/test-instance/databases/example-db/sessions/<var>SESSION</var>在「Request body」部分,使用下列程式碼:
{ "sql": "SELECT AlbumId, AlbumTitle, MarketingBudget FROM Albums WHERE AlbumTitle >= 'Aardvark' AND AlbumTitle < 'Goo'" }按一下 [Execute] (執行)。回應會顯示下列資料列:
"rows": [ [ "2", "Go, Go, Go", null ], [ "2", "Forever Hold Your Peace", "500000" ] ]
使用索引進行讀取
- 按一下 [
projects.instances.databases.sessions.read]。 在「session」中輸入:
projects/<var>PROJECT_ID</var>/instances/test-instance/databases/example-db/sessions/<var>SESSION</var>在「Request body」部分,使用下列程式碼:
{ "table": "Albums", "columns": [ "AlbumId", "AlbumTitle" ], "keySet": { "all": true }, "index": "AlbumsByAlbumTitle" }按一下 [Execute] (執行)。回應會顯示下列資料列:
"rows": [ [ "2", "Forever Hold Your Peace" ], [ "2", "Go, Go, Go" ], [ "1", "Green" ], [ "3", "Terrified" ], [ "1", "Total Junk" ] ]
使用 STORING 子句新增索引
先前的讀取範例並未包含 MarketingBudget 資料欄。這是因為 Spanner 讀取介面不支援將索引與資料表彙整,再查詢未保存於索引中的值。
請為 AlbumsByAlbumTitle 建立替代定義,將 MarketingBudget 的副本保存在索引中。
使用 updateDdl 新增 STORING 索引。
- 按一下 [
projects.instances.databases.updateDdl]。 在「database」中輸入:
projects/<var>PROJECT_ID</var>/instances/test-instance/databases/example-db在「Request body」部分,使用下列程式碼:
{ "statements": [ "CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget)" ] }按一下 [Execute] (執行)。即使 REST 呼叫傳回回應,這項作業也可能需要幾分鐘才能完成。回應會傳回長時間執行的作業。查詢這項作業,即可查看狀態。
現在,請執行讀取作業,從 AlbumsByAlbumTitle2 索引中擷取所有 AlbumId、AlbumTitle 和 MarketingBudget 資料欄:
- 按一下 [
projects.instances.databases.sessions.read]。 在「session」中輸入:
projects/<var>PROJECT_ID</var>/instances/test-instance/databases/example-db/sessions/<var>SESSION</var>在「Request body」部分,使用下列程式碼:
{ "table": "Albums", "columns": [ "AlbumId", "AlbumTitle", "MarketingBudget" ], "keySet": { "all": true }, "index": "AlbumsByAlbumTitle2" }按一下 [Execute] (執行)。回應會顯示下列資料列:
"rows": [ [ "2", "Forever Hold Your Peace", "500000" ], [ "2", "Go, Go, Go", null ], [ "1", "Green", null ], [ "3", "Terrified", null ], [ "1", "Total Junk", "100000" ] ]
使用唯讀交易擷取資料
如要在同一個時間戳記執行多個讀取作業,請使用唯讀交易。這些交易會觀察交易修訂記錄中一致的前置字串,讓應用程式永遠取得一致的資料。
建立唯讀交易
- 按一下 [
projects.instances.databases.sessions.beginTransaction]。 在「session」中輸入:
projects/<var>PROJECT_ID</var>/instances/test-instance/databases/example-db/sessions/<var>SESSION</var>在「Request Body」部分,使用下列程式碼:
{ "options": { "readOnly": {} } }點選「Execute」。
回應會顯示您建立的交易 ID。
即使資料在您建立唯讀交易後發生變更,您仍可使用唯讀交易,在一致的時間戳記擷取資料。
使用唯讀交易執行查詢
- 按一下 [
projects.instances.databases.sessions.executeSql]。 在「session」中輸入:
projects/<var>PROJECT_ID</var>/instances/test-instance/databases/example-db/sessions/<var>SESSION</var>在「Request body」部分,使用下列程式碼:
{ "sql": "SELECT SingerId, AlbumId, AlbumTitle FROM Albums", "transaction": { "id": "<var>TRANSACTION_ID</var>" } }按一下 [Execute] (執行)。回應會顯示類似下列的資料列:
"rows": [ [ "2", "2", "Forever Hold Your Peace" ], [ "1", "2", "Go, Go, Go" ], [ "2", "1", "Green" ], [ "2", "3", "Terrified" ], [ "1", "1", "Total Junk" ] ]
使用唯讀交易讀取資料
- 按一下 [
projects.instances.databases.sessions.read]。 在「session」中輸入:
projects/<var>PROJECT_ID</var>/instances/test-instance/databases/example-db/sessions/<var>SESSION</var>在「Request body」部分,使用下列程式碼:
{ "table": "Albums", "columns": [ "SingerId", "AlbumId", "AlbumTitle" ], "keySet": { "all": true }, "transaction": { "id": "<var>TRANSACTION_ID</var>" } }按一下 [Execute] (執行)。回應會顯示類似下列的資料列:
"rows": [ [ "1", "1", "Total Junk" ], [ "1", "2", "Go, Go, Go" ], [ "2", "1", "Green" ], [ "2", "2", "Forever Hold Your Peace" ], [ "2", "3", "Terrified" ] ]
Spanner 也支援讀寫交易,這類交易會以不可分割的形式,在單一邏輯時點執行一組讀寫作業。詳情請參閱「讀寫交易」。(「試試看!」功能不適合用來示範讀寫交易。)
清除所用資源
如要避免系統向您的 Google Cloud 帳戶收取您在本教學課程中所用資源的相關費用,請捨棄資料庫並刪除您建立的執行個體。
捨棄資料庫
- 按一下 [
projects.instances.databases.dropDatabase]。 在「name」中輸入:
projects/<var>PROJECT_ID</var>/instances/test-instance/databases/example-db點選「Execute」。
刪除執行個體
後續步驟
- 在虛擬機器執行個體中存取 Spanner:建立具備 Spanner 資料庫存取權的虛擬機器執行個體。
- 進一步瞭解 Spanner 概念。