
In diesem Dokument wird beschrieben, wie Sie die Kontextsets erstellen und optimieren, mit denen Sie eine hohe Abfragegenauigkeit für QueryData in Ihren Datenagentenanwendungen erzielen können. Der Kontext-Engineering-Agent hilft Ihnen beim Erstellen, Bewerten und Verbessern von Kontextsets, indem er die Erstellung und Optimierung automatisiert.
Weitere Informationen zu Kontextsets und QueryData finden Sie unter Übersicht über Kontextsets und Übersicht über QueryData.Für die Entwicklung von Datenanwendungen auf Unternehmensebene muss die Genauigkeit des Text-zu-SQL-Modells in der Regel nahezu 100% erreichen. Falsche Abfrageergebnisse beeinträchtigen die allgemeine Benutzerfreundlichkeit der Anwendung und die Nutzererfahrung. Um erklärbare, geschäftsrelevante Antworten mit hoher Genauigkeit zu erhalten, ist Kontext-Engineering erforderlich. Dabei wird der Kontext erstellt und iterativ optimiert, um eine optimale Genauigkeit zu erzielen.
Wenn Sie QueryData den auf Ihre Geschäftsanwendung zugeschnittenen Kontext zur Verfügung stellen, geben Sie die genauen Geschäftsregeln an, die das System benötigt, um die nuancierte Nutzerabsicht zu erkennen.
Kontext-Engineering-Agent
Der Kontext-Engineering-Agent automatisiert diesen Optimierungsworkflow. Sie können mit dem Agenten interagieren, um Ad-hoc-Aufgaben zur Optimierung Ihres Kontexts zu erledigen. In der folgenden Liste finden Sie Beispiele für Prompts in natürlicher Sprache, mit denen Sie den Agenten anweisen können, sowie eine Beschreibung der Reaktion des Agenten. Verwenden Sie diese Beispiele, um Ihren Kontext zu erstellen und zu optimieren:
- Beispielprompt für die Fehleranalyse: "Aktualisiere den Kontext, damit wir den Flughafen für Abfragen wie „Flüge nach Disneyland“ korrekt identifizieren können." Der Agent analysiert den Fehler, begründet die Lücke und empfiehlt, ein geeignetes Kontextelement hinzuzufügen, z. B. eine Wertsuchabfrage.
- Beispielprompt für Kontextvorschläge: "Lies meinen App-Code und schlage einige Kontextelemente vor, die ich hinzufügen kann." Der Agent analysiert den Code, begründet die Domain Ihrer Anwendung und schlägt vor, welche Kontextelemente relevant wären.
- Beispielprompt für die Batchverarbeitung: "Hier sind 10 Beispiele für Fragen und SQL-Abfragen. Erstelle daraus Vorlagen." Der Agent verarbeitet Ihre Eingaben im Batch und aktualisiert Ihr Kontextset.
Bedeutung des Golden-Datasets
Um Ihren Kontext zu optimieren, müssen Sie zuerst ein Dataset erstellen, das den Eingaben in natürlicher Sprache Ihrer Anwendung entspricht. Der Agent kann Ihnen helfen, dieses Golden-Dataset zu erstellen, das aus Nutzerfragen und den erwarteten Datenbankabfragen besteht. Mit einem Golden-Dataset können Sie:
- Eine Baseline für die Abfrageleistung festlegen.
- Updates anhand von Datenbankabfragen mit Ground-Truth-Antworten validieren.
- Genauigkeitsverbesserungen über mehrere Iterationen hinweg messen.
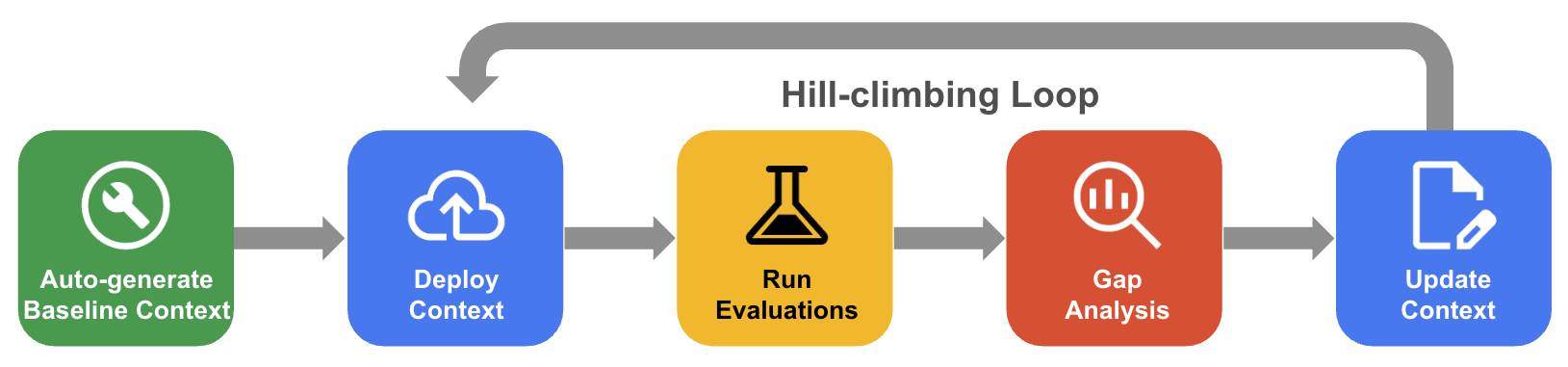
Der systematische Hill-Climbing-Prozess
Beim systematischen Hill-Climbing-Prozess verbessert der Agent ein Kontextset iterativ durch die Bewertung des Golden-Datasets, die Lückenanalyse und Updates, um die Genauigkeit auf nahezu 100 % zu steigern.
- Baseline-Kontext automatisch generieren: Erstellen Sie ein Kontextset, das aus Ihrem Datenbankschema und Ihren Anwendungsartefakten abgeleitet wird.
- Hill-Climbing-Optimierungsworkflow: Lassen Sie den Agenten die Genauigkeit von QueryData bewerten, eine Lückenanalyse für Fehler durchführen und automatisch Verbesserungen vorschlagen, um die Genauigkeit zu erhöhen.
Das folgende Diagramm zeigt den systematischen Hill-Climbing-Workflow:
Hinweis
Führen Sie die folgenden Schritte aus, bevor Sie den Kontext-Engineering-Agent verwenden.
Erforderliche Dienste aktivieren
Aktivieren Sie die folgenden Dienste für Ihr Projekt:Spanner-Instanz vorbereiten
- Achten Sie darauf, dass eine Spanner-Instanz verfügbar ist. Weitere Informationen finden Sie unter Instanz erstellen.
- Erstellen Sie in Ihrer Instanz eine Datenbank, in der Sie die Tabellen erstellen. Weitere Informationen finden Sie unter Datenbank in der Spanner-Instanz erstellen
Für diese Anleitung ist eine Datenbank in Ihrer Spanner-Instanz erforderlich. Weitere Informationen finden Sie unter Datenbank erstellen.
Erforderliche Rollen und Berechtigungen
- Fügen Sie dem Cluster einen IAM-Nutzer oder ein Dienstkonto hinzu. Weitere Informationen finden Sie unter IAM-Rollen anwenden.
- Weisen Sie dem IAM-Nutzer auf Projektebene die Rollen
spanner.databaseReaderundgeminidataanalytics.queryDataUserzu. Weitere Informationen finden Sie unter IAM-Richtlinienbindung für ein Projekt hinzufügen. - Weisen Sie dem IAM-Nutzer auf Projektebene Rollen und Berechtigungen für die erforderlichen Datenbanken zu.
Umgebung vorbereiten
Sie können Kontextset-Dateien in jeder lokalen Entwicklungsumgebung oder IDE erstellen. Führen Sie die folgenden Schritte aus, um die Umgebung vorzubereiten:
- Kontext-Engineering-Agent installieren
- Datenbankverbindung einrichten
Kontext-Engineering-Agent installieren
Der Kontext-Engineering-Agent führt einen Model Context Protocol (MCP)-Server aus, für den uv zur Verwaltung der zugrunde liegenden Python-Pakete erforderlich ist.
Installieren Sie
uvgemäß der Anleitung unter Installieren Sieuv.Prüfen Sie, ob
uvinstalliert ist und über die Befehlszeile zugänglich ist:uv --version
Installieren Sie den Kontext-Engineering-Agent in der ausgewählten Agentenplattform, z. B. in der Antigravity CLI, in Claude Code oder in der Gemini CLI.
Führen Sie je nach ausgewählter Agentenplattform die entsprechenden Installationsschritte aus:
Antigravity CLI
So installieren Sie den Kontext-Engineering-Agent in der Antigravity CLI:
- Installieren Sie die Antigravity CLI. Weitere Informationen finden Sie unter Erste Schritte mit der Antigravity CLI.
- Installieren Sie das Plug‑in für den Kontext-Engineering-Agent, das Workflows für die Kontextgenerierung enthält. Ersetzen Sie VERSION durch die erforderliche veröffentlichte Version:
agy plugin install https://github.com/GoogleCloudPlatform/db-context-enrichment/tree/VERSION
- Starten Sie die Antigravity CLI:
agy
- Optional. Aktualisieren Sie das Plug‑in:
agy plugin uninstall google-cloud-db-context-engineering agy plugin install https://github.com/GoogleCloudPlatform/db-context-enrichment/tree/NEW_VERSION
Claude Code
So installieren Sie den Kontext-Engineering-Agent in Claude Code:
- Fügen Sie den Plug‑in-Marketplace hinzu:
/plugin marketplace add https://github.com/GoogleCloudPlatform/db-context-enrichment.git
- Installieren Sie das Plug‑in:
/plugin install db-context-engineering@db-context-enrichment-marketplace
- Laden Sie die Plug‑ins neu, um die Änderungen zu aktivieren:
/reload-plugins
- Optional. Aktualisieren Sie das Plug‑in:
/plugin update db-context-engineering@db-context-enrichment-marketplace
Gemini CLI (eingestellt)
So installieren Sie den Kontext-Engineering-Agent in der Gemini CLI:
- Installieren Sie die Gemini CLI. Weitere Informationen finden Sie unter Erste Schritte mit der Gemini CLI.
- Installieren Sie die Erweiterung:
gemini extensions install https://github.com/GoogleCloudPlatform/db-context-enrichment
- Optional. Aktualisieren Sie die Erweiterung:
gemini extensions update mcp-db-context-enrichment
Datenbankverbindung einrichten
Der Agent benötigt eine Datenbankverbindung, um Schemas abzurufen und die Syntax des generierten SQL-Kontexts zu validieren. Damit der Agent mit Ihrer Datenbank interagieren kann, konfigurieren Sie Anmeldedaten und definieren Sie die Konfiguration Ihrer Datenbankverbindung.
Standardanmeldedaten für Anwendungen konfigurieren
Konfigurieren Sie Standardanmeldedaten für Anwendungen (Application Default Credentials, ADC) , um Anmeldedaten für den Zugriff auf Ressourcen über den Kontext-Engineering-Agent bereitzustellen: Google Cloud
- Toolbox-MCP-Server: Verwendet Anmeldedaten, um eine Verbindung zu Ihrer Datenbank herzustellen, Schemas abzurufen und SQL zur Validierung auszuführen.
- Evalbench: Verwendet Anmeldedaten, um QueryData zur Bewertung aufzurufen.
Führen Sie die folgenden Befehle im Terminal aus, um sich zu authentifizieren:
gcloud auth application-default loginDatenbankverbindungsdatei konfigurieren
Der Agent benötigt eine Datenbankverbindung für die Kontextgenerierung, die von der MCP Toolbox unterstützt und in einer Konfigurationsdatei definiert wird.
In der Konfigurationsdatei werden die Datenbankquelle und die Tools angegeben, die zum Abrufen von Schemas oder zum Ausführen von SQL erforderlich sind. Der Kontext-Engineering-Agent wird mit vorinstallierten Agent Skills geliefert, die Ihnen bei der Generierung der Konfiguration helfen.
Starten Sie Ihre Agentenumgebung.
Bitten Sie den Agenten, Ihnen bei der Einrichtung der Datenbankverbindung zu helfen, z. B. mit dem Prompt „Hilf mir, die Datenbankverbindung einzurichten“. Folgen Sie der Anleitung des Agenten, um die Konfigurationsdatei in Ihrem aktuellen Arbeitsverzeichnis als
autoctx/tools.yamlzu erstellen.Laden Sie die Verbindung neu, um die neue
tools.yaml-Konfiguration anzuwenden:- Führen Sie in der Antigravity CLI
/mcpaus und wählen Sietoolboxaus, um neu zu starten. - Führen Sie in der Gemini CLI
/mcp reloadaus. - Führen Sie in Claude Code
/mcpaus, wählen Sietoolboxund dannReconnectaus.
- Führen Sie in der Antigravity CLI
Weitere Informationen zum manuellen Konfigurieren der Datenbankkonfigurationsdatei, siehe MCP Toolbox-Konfiguration.
Kontext generieren und optimieren
Der Kontext-Engineering-Agent bietet eine Reihe von Agent Skills und MCP-Tools, um die Kontext-Engineering-Funktionen Ihres Coding-Agenten zu verbessern. Sie können diese Tools zusammen verwenden, um eine Baseline zu erstellen, die Effektivität zu messen und iterativ Verbesserungen anzuwenden. Sie können jedoch in jeder Phase des Workflows beginnen:
- Wenn Sie bereits ein Kontextset haben, können Sie direkt mit der Bewertung fortfahren.
- Wenn Sie fehlerhafte Abfragen haben, die Sie beheben möchten, können Sie direkt mit der Lückenanalyse fortfahren.
Jede Funktion beschreibt die Aktionen, Anwendungsfälle und Aufrufbefehle des Agenten.
Die Beispielprompts zeigen, wie Sie den Agenten in natürlicher Sprache abfragen können. Wenn der Agent zusätzliche Details benötigt, um eine Anfrage zu bearbeiten, fordert er Sie auf, die Anfrage zu präzisieren.
Bewertungs-Datasets erstellen und erweitern
Um die Leistung zu verbessern, müssen Sie sie zuerst messen. Beim Kontext-Engineering ohne Golden-Dataset, das aus Nutzerfragen und den erwarteten SQL-Abfragen besteht, fehlt eine systematische Überprüfung. Mit einem Golden-Dataset ist jede Änderung eine messbare Verbesserung, die Sie anhand der Ground-Truth-Antworten validieren können.
Das manuelle Erstellen eines repräsentativen Golden-Datasets ist zeitaufwendig und bei kleinen Datasets werden möglicherweise Variationen in der Formulierung der Nutzer nicht berücksichtigt. Der Agent löst dieses Problem so:
- Er generiert Kandidatenpaare aus Frage und SQL-Abfrage basierend auf Ihrem Datenbankschema.
- Er erweitert ein kleines Ausgangs-Dataset mit Filtervariationen, Synonymen und Umformulierungen.
Optional können Sie den Agenten das generierte SQL für Ihre Datenbank ausführen lassen. Mit dieser Überprüfung wird bestätigt, dass die Abfragen erfolgreich ausgeführt werden, bevor Sie sie dem Dataset hinzufügen.
Das Dataset ist eine JSON-Datei mit Paaren aus Frage und SQL-Abfrage:
[
{
"id": "example_001",
"nlq": "What is the total revenue for the top 5 products?",
"golden_sql": "SELECT product_id, sum(net_revenue) FROM sales GROUP BY product_id ORDER BY sum(net_revenue) DESC LIMIT 5;"
}
]
Genehmigte Paare werden in die Datei autoctx/golden.json in Ihrem Arbeitsbereich eingefügt, wo sie für die Bewertung bereit sind. Sie können eine vorhandene Datei angeben oder einige Bewertungsbeispiele inline schreiben, die der Agent erweitern soll.
Mit den folgenden Beispielprompts können Sie den Agenten anweisen:
- "Generiere ein Bewertungs-Dataset aus meinem Schema."
- "Hier ist eine Ausgangsfrage und eine SQL-Abfrage. Erweitere sie zu einem größeren Dataset und prüfe, ob die Abfragen ausgeführt werden."
Baseline-Kontextset generieren
Um den Kontext nicht von Grund auf neu erstellen zu müssen, können Sie den Agenten ein anfängliches Kontextset aus Ihrem Datenbankschema und Ihren Anwendungsartefakten ableiten lassen, z. B. aus Geschäftsregeln, Beispielabfragen oder README-Dateien. Dieser Baseline-Kontext ist zwar nicht endgültig, bietet aber einen validierten Ausgangspunkt, der auf Ihrem Datenbankmodell basiert.
Mit den folgenden Beispielprompts können Sie den Agenten anweisen:
- "Generiere ein Kontextset aus meinem Schema."
- "Generiere einen anfänglichen Kontext mit diesen Schemas und den Geschäftsregeln in
requirements.md."
Der Agent fordert Sie auf, das Experiment zu benennen, um die generierten Artefakte zu organisieren. Möglicherweise fordert er Sie auch auf, den Umfang einzugrenzen, wenn Ihr Datenbankschema groß ist. Wenn der Agent die JSON-Datei generiert hat, folgen Sie der Anleitung, um den Kontext mit Spanner Studio hochzuladen.
Kontexteffektivität bewerten
Nachdem Sie ein Kontextset und ein Golden-Dataset erstellt haben, können Sie den Agenten die Kontextleistung messen lassen, indem Sie die QueryData API Ihres Datenagenten mit jeder Golden-Frage abfragen. Evalbench
Eine Bewertung bietet Folgendes:
- Quantitative Messwerte wie Ergebnisse für „Bestanden“ und „Nicht bestanden“ sowie aggregierte Ergebnisse, um den Fortschritt über mehrere Kontextiterationen hinweg zu verfolgen.
- Eine Zusammenfassung der Inline-Unterhaltung und detaillierte CSV-Berichte im Verzeichnis
eval_reports/in Ihrem Experimentordner.
Geben Sie den Pfad zum Golden-Dataset und die Kontextset-ID an, um eine Bewertung zu starten. Informationen zum Suchen der Kontextset-ID finden Sie unter Kontext-ID des Agenten finden.
Mit den folgenden Beispielprompts können Sie den Agenten anweisen:
- "Bewerte meinen Kontext anhand von
golden.json." - "Führe die Bewertung mit der Konfiguration aus meinem letzten Experiment noch einmal aus."
Wenn Sie eine zuvor generierte Bewertungskonfiguration noch einmal ausführen möchten, ohne sie neu einzurichten, bitten Sie den Agenten oder rufen Sie die Befehlszeile direkt auf:
uvx google-evalbench --run_config=autoctx/experiments/my-experiment/eval_configs/run_config.json
Details zum Bewertungsschemas und zum Anpassen von Bewertungsdurchläufen finden Sie in der Evalbench-Dokumentation.
Lückenanalyse durchführen und Verbesserungen vorschlagen
Um Abfragefehler zu beheben, müssen Sie die Ursachen ermitteln, z. B. falsche Spalten, fehlende Tabellenverknüpfungen oder nicht aufgelöste Fuzzy-Begriffe. Das manuelle Ermitteln dieser Probleme erfordert eine umfassende Analyse der Bewertungsberichte.
Der Agent automatisiert diese Analyse- und Korrekturschleife:
- Lückenanalyse: Der Agent liest die Bewertungsergebnisse und Ihr Kontextset, um ähnliche Fehler zu gruppieren und gezielte Kontextergänzungen zu empfehlen, z. B. Vorlagen, Facetten oder Wertesuchen.
- Vorgeschlagene Korrekturen: Der Agent schlägt konkrete Änderungen vor und testet optional das SQL für Ihre Datenbank, um die Lösung zu überprüfen.
- Baseline-Beibehaltung: Der Agent schreibt die Verbesserungen in eine neue JSON-Datei neben Ihrem Baseline-Kontext, sodass die Originaldateien erhalten bleiben.
Mit den folgenden Beispielprompts können Sie den Agenten anweisen:
- "Führe eine Lückenanalyse für meine letzte Bewertung durch und schlage Korrekturen vor."
- "Optimiere dieses Kontextset anhand von
golden.json."
Bereiten Sie sich auf die nächste Iteration vor, indem Sie den verbesserten Kontext mit Data Agents Studio in das Ziel Kontextset hochladen. Folgen Sie dazu der Anleitung.
Bestimmte Kontextelemente bei Bedarf erstellen
Wenn Sie den erforderlichen Kontext bereits kennen, z. B. eine Vorlage für eine bestimmte Frage, eine Facette für einen wiederholten Filter oder eine Wertesuche für eine bestimmte Spalte, kann das manuelle Schreiben des Kontext-JSON zu Serialisierungsfehlern in Parameternamen, Typmetadaten oder der Fragmentsyntax führen. Der Agent übernimmt die JSON-Formatierung, damit Sie sich auf Ihre Geschäftsabsicht konzentrieren können.
Sie können diese Funktion auch für Ad-hoc-Updates verwenden, z. B. wenn Sie ein neues Abfragemuster unterstützen oder ein fehlendes Schemadetail beheben müssen. Um das JSON zu erhalten, beschreiben Sie dem Agenten den erforderlichen Kontext, ohne eine Bewertung auszuführen oder ein Experiment einzurichten.
Diese Funktion ist auch die richtige Wahl, wenn Sie eine einmalige Aufgabe erhalten: Ein Stakeholder gibt Ihnen ein neues Paar aus Frage und SQL-Abfrage, das unterstützt werden soll, oder Sie entdecken bei einer Codeüberprüfung eine fehlende Facette. Sie müssen kein Experiment einrichten oder eine Bewertung ausführen, um das Problem zu beheben. Beschreiben Sie einfach, was Sie möchten, und der Agent erstellt das JSON.
Mit den folgenden Beispielprompts können Sie den Agenten anweisen:
- „Erstelle eine Vorlage für: „Welche Flughäfen gibt es in Kalifornien?“ mit SQL:
SELECT name FROM airports WHERE country = 'United States' AND state = 'CA'“ - "Erstelle eine Facette für den Filter
departure_time BETWEEN '00:00:00' AND '06:00:00'mit dem Label „Nachtflug“." - "Erstelle eine Wertesuche für
airports.iata."
Begründung für die Auswahl des Kontexttyps
Die Auswahl des richtigen Kontexttyps, unabhängig davon, ob es sich um eine Vorlage, eine Facette oder eine Wertesuche handelt, trägt dazu bei, eine übermäßige Kontextgröße und Regressionen bei Datenbankabfragen zu vermeiden. Wenn Sie beispielsweise eine Vorlage anstelle einer Facette verwenden, können doppelte Regeln entstehen. Wertesuchen, die eingeführt werden, wenn eine Vorlage ausreicht, können die Abfragelatenz erhöhen. Um das richtige Schemaformat zu finden, fordern Sie den Agenten auf, einen Typ basierend auf der Abfragestruktur oder den Datenbankspalten zu empfehlen, bevor Sie Kontextelemente erstellen. Der Agent erklärt seine Begründung, damit Sie die Kontextoptionen besser verstehen.
Mit den folgenden Beispielprompts können Sie den Agenten anweisen:
- "Ich schreibe den Filter
departure_time BETWEEN '00:00:00' AND '06:00:00'immer wieder in viele Abfragen. Wie kann ich das am besten erfassen?" - "Nutzer beschreiben den Flugstatus in Freitext und ich möchte sie mit
flights.statusabgleichen. Welche Art von Wertesuche sollte ich einrichten?" - "Was ist der Unterschied zwischen einer Vorlage und einer Facette und wann sollte ich sie verwenden?"
Batchvorgänge für ein Kontextset anwenden
Der Agent unterstützt Batchupdates, um große Kontextsets konsistent zu verwalten. Wenn Sie mehrere Kontextelemente gleichzeitig aktualisieren müssen, z. B. wenn eine Datenbankspalte umbenannt wird, sich das Format eines Codewerts ändert oder Vorlagen auf eine eingestellte Tabelle verweisen, kann der Agent die Änderung auf alle betroffenen Elemente anwenden, ohne nicht verwandte Einträge zu ändern.
Mit den folgenden Beispielprompts können Sie den Agenten anweisen:
- "Lies
golden.txtund wandle alle Paare in Vorlagen um." - „Ersetze in
context_set.jsonairline = 'UA'durchairline = 'United Airlines'für alle Elemente, die auf „United“ verweisen. Lass nicht verwandte Elemente unverändert."
Nächste Schritte
- Weitere Informationen zu Kontextsets.
- Informationen zum Erstellen oder Löschen eines Kontextsets in Spanner Studio
- Informationen zum Testen eines Kontextsets.