
Cette page décrit et compare deux services Sensitive Data Protection qui vous aident à comprendre vos données et à activer les workflows de gouvernance des données : le service de découverte et le service d'inspection.
Découverte des données sensibles
Le service de découverte surveille les données dans toute votre organisation. Il s'exécute en continu et découvre, classe et profile automatiquement les données. La découverte peut vous aider à comprendre l'emplacement et la nature des données que vous stockez, y compris les ressources de données dont vous n'avez peut-être pas conscience. Les données inconnues (parfois appelées données fantômes) ne sont généralement pas soumises au même niveau de gouvernance des données et de gestion des risques que les données connues.
Vous configurez la découverte à différents niveaux. Vous pouvez définir différents programmes de profilage pour différents sous-ensembles de vos données. Vous pouvez également exclure des sous-ensembles de données que vous n'avez pas besoin de profiler.
Résultat de l'analyse de découverte : profils de données
Le résultat d'une analyse de découverte est un ensemble de profils de données pour chaque ressource de données concernée. Par exemple, une analyse de découverte des données BigQuery ou Cloud SQL génère des profils de données au niveau du projet, de la table et de la colonne.
Un profil de données contient des métriques et des insights sur la ressource profilée. Il inclut les classifications de données (ou infoTypes), les niveaux de sensibilité, les niveaux de risque des données, la taille des données, la forme des données et d'autres éléments qui décrivent la nature des données et leur niveau de sécurité (le niveau de sécurité des données). Vous pouvez utiliser des profils de données pour prendre des décisions éclairées sur la manière de protéger vos données, par exemple en définissant des règles d'accès à la table.
Prenons l'exemple d'une colonne BigQuery appelée ccn, où chaque ligne contient un numéro de carte de crédit unique et où il n'y a pas de valeurs nulles. Le profil de données généré au niveau de la colonne contiendra les informations suivantes :
| Nom à afficher | Valeur |
|---|---|
Field ID |
ccn |
Data risk |
High |
Sensitivity |
High |
Data type |
TYPE_STRING |
Policy tags |
No |
Free text score |
0 |
Estimated uniqueness |
High |
Estimated null proportion |
Very low |
Last profile generated |
DATE_TIME |
Predicted infoType |
CREDIT_CARD_NUMBER |
De plus, ce profil au niveau de la colonne fait partie d'un profil au niveau de la table, qui fournit des insights tels que l'emplacement des données, l'état de chiffrement et si la table est partagée publiquement. Dans la Google Cloud console, vous pouvez également afficher les entrées Cloud Logging pour la table, ainsi que les principaux IAM avec des rôles pour la table.
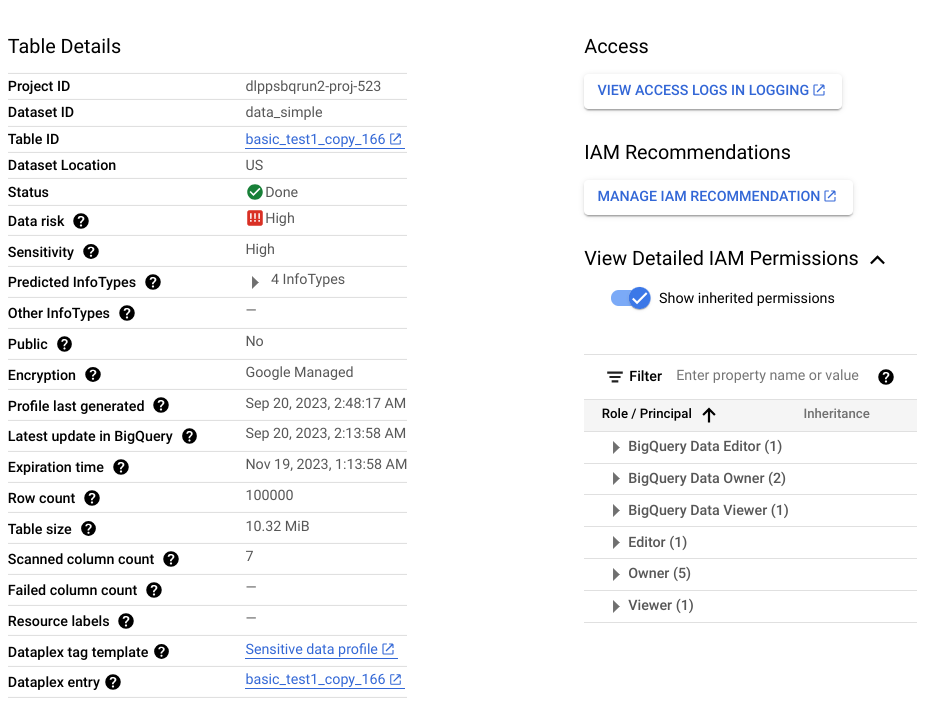
Pour obtenir la liste complète des métriques et des insights disponibles dans les profils de données, consultez la documentation de référence sur les métriques.
Quand utiliser la découverte
Lorsque vous planifiez votre approche de gestion des risques liés aux données, nous vous recommandons de commencer par la découverte. Le service de découverte vous aide à obtenir une vue d'ensemble de vos données et à activer les alertes, rapports, et la correction des problèmes.
De plus, le service de découverte peut vous aider à identifier les ressources dans lesquelles des données non structurées peuvent résider. Ces ressources peuvent justifier une inspection exhaustive. Les données non structurées sont spécifiées par un score de texte libre élevé sur une échelle de 0 à 1.
Inspection des données sensibles
Le service d'inspection effectue une analyse exhaustive d'une seule ressource pour localiser chaque instance individuelle de données sensibles. Une inspection produit un résultat pour chaque instance détectée.
Les tâches d'inspection offrent un large éventail d' options de configuration pour vous aider à identifier les données que vous souhaitez inspecter. Par exemple, vous pouvez activer l'échantillonnage pour limiter les données à inspecter à un certain nombre de lignes (pour les données BigQuery) ou à certains types de fichiers (pour les données Cloud Storage). Vous pouvez également cibler une période spécifique pendant laquelle les données ont été créées ou modifiées.
Contrairement à la découverte, qui surveille en continu vos données, une inspection est une opération à la demande. Toutefois, vous pouvez planifier des tâches d'inspection récurrentes appelées déclencheurs de tâche.
Résultat de l'analyse d'inspection : résultats
Chaque résultat inclut des détails tels que l'emplacement de l'instance détectée, son infoType potentiel et la certitude (également appelée probabilité) que le résultat correspond à l' infoType. Selon vos paramètres, vous pouvez également obtenir la chaîne réelle à laquelle le résultat se rapporte. Cette chaîne est appelée citation dans Sensitive Data Protection.
Pour obtenir la liste complète des détails inclus dans un résultat d'inspection, consultez
Finding.
Quand utiliser l'inspection
Une inspection est utile lorsque vous devez examiner des données non structurées (comme des commentaires ou des avis créés par l'utilisateur) et identifier chaque instance d'informations personnelles. Si une analyse de découverte identifie des ressources contenant des données non structurées, nous vous recommandons d'exécuter une analyse d'inspection sur ces ressources pour obtenir des détails sur chaque résultat individuel.
Quand ne pas utiliser l'inspection
L'inspection d'une ressource n'est pas utile si les deux conditions suivantes s'appliquent. Une analyse de découverte peut vous aider à déterminer si une analyse d'inspection est nécessaire.
- Vous n'avez que des données structurées dans la ressource. Autrement dit, il n'y a pas de colonnes de données de forme libre, comme des commentaires ou des avis d'utilisateurs.
- Vous connaissez déjà les infoTypes stockés dans cette ressource.
Supposons, par exemple, que les profils de données d'une analyse de découverte indiquent qu'une certaine table BigQuery ne comporte pas de colonnes avec des données non structurées, mais qu'elle comporte une colonne de numéros de carte de crédit uniques. Dans ce cas, il n'est pas utile d'inspecter la table pour rechercher des numéros de carte de crédit. Une inspection générera un résultat pour chaque élément de la colonne. Si vous avez 1 million de lignes et que chaque ligne contient un numéro de carte de crédit, une tâche d'inspection générera 1 million de résultats pour l'infoType CREDIT_CARD_NUMBER. Dans cet exemple, l'inspection n'est pas nécessaire, car l'analyse de découverte indique déjà que la colonne contient des numéros de carte de crédit uniques.
Résidence, traitement et stockage des données
La découverte et l'inspection sont compatibles avec les exigences de résidence des données :
- Le service de découverte traite vos données là où elles résident et stocke les profils de données générés dans la même région ou zone multirégionale que les données profilées. Pour en savoir plus, consultez la section Considérations relatives à la résidence des données.
- Lors de l'inspection des données dans un système de Google Cloud stockage, le
service d'inspection traite vos données dans la même région que celle où les
données résident et stocke la tâche d'inspection dans cette région. Lors de l'inspection
des données via une tâche hybride ou via une méthode
content, le service d'inspection vous permet de spécifier où il doit traiter vos données. Pour en savoir plus, consultez la section Stockage des données.
Résumé comparatif : services de découverte et d'inspection
| Découverte | Inspection | |
|---|---|---|
| Avantages |
|
|
| Coût |
10 To coûtent environ 300$par mois en mode Consommation. |
10 To coûtent environ 10 000$par analyse. |
| Sources de données prises en charge | BigLake BigQuery Variables d'environnement des fonctions Cloud Run Variables d'environnement de la révision du service Cloud Run Cloud SQL Cloud Storage Vertex AI Amazon S3 Azure Blob Storage |
BigQuery Cloud Storage Datastore Hybride (n'importe quelle source)1 |
| Niveaux d'accès pris en charge |
|
Une seule table BigQuery, un seul bucket Cloud Storage ou un seul genre Datastore. |
| Modèles d'inspection intégrés | Oui | Oui |
| Intégrés et personnalisés infoTypes | Oui | Oui |
| Résultat de l'analyse | Vue d'ensemble (profils de données) de toutes les données compatibles. | Résultats concrets de données sensibles dans la ressource inspectée. |
| Enregistrer les résultats dans BigQuery | Oui | Oui |
| Envoyer au catalogue de connaissances sous forme de tags (obsolète) | Oui | Oui |
| Envoyer au catalogue de connaissances sous forme d'aspects | Oui | Non |
| Publier les résultats dans Security Command Center | Oui | Oui |
| Publier les résultats dans Google Security Operations | Oui pour la découverte au niveau de l'organisation et du dossier | Non |
| Publier dans Pub/Sub | Oui | Oui |
| Compatibilité avec la résidence des données | Oui | Oui |
1 L'inspection hybride a un modèle de tarification différent. Pour en savoir plus, consultez la section Inspection des données provenant de n'importe quelle source .
Étape suivante
- Découvrez les stratégies recommandées pour réduire les risques liés aux données (document suivant de cette série).