
En esta página, se describe cómo estimar el costo de generar perfiles de datos de BigQuery en una organización o carpeta. Si deseas crear una estimación para un proyecto, consulta Calcular el costo de generar perfiles de datos para un solo proyecto.
Para obtener más información sobre la generación de perfiles de datos de BigQuery, consulta Perfiles de datos para datos de BigQuery.
Descripción general
Antes de comenzar a generar perfiles de datos, puedes ejecutar una estimación para comprender la cantidad de datos de BigQuery que tienes y cuánto podría costar generar perfiles de esos datos. Para ejecutar una estimación, debes crear una estimación.
Cuando creas una estimación, especificas el recurso (organización, carpeta o proyecto) que contiene los datos de los que deseas generar perfiles. Puedes establecer filtros para ajustar la selección de datos. También puedes establecer las condiciones que se deban cumplir antes de que Sensitive Data Protection genere el perfil de una tabla. La protección de datos sensibles basa la estimación en la forma, el tamaño y el tipo de los datos en el momento en que creas la estimación.
Cada estimación incluye detalles como la cantidad de tablas coincidentes que se encuentran en el recurso, el tamaño total de todas esas tablas y el costo estimado de generar perfiles del recurso una vez y de forma mensual.
Para obtener más información sobre cómo se calculan los precios, consulta Precios de la generación de perfiles de datos.
Precios de estimación
Crear una estimación es sin costo.
Retención
Cada estimación se borra automáticamente después de 28 días.
Limitaciones
Si tu organización o carpeta tiene un proyecto protegido por un perímetro de servicio de los Controles del servicio de VPC, es posible que Sensitive Data Protection subestime la cantidad de datos de BigQuery en tu recurso. Si tienes perímetros de servicio, crea una estimación para cada uno de ellos de forma independiente.
Antes de comenzar
Para obtener los permisos que
necesitas para crear y administrar estimaciones de costos de generación de perfiles de datos,
pídele a tu administrador que te otorgue el
rol de IAM de Administrador de DLP (roles/dlp.admin) en la organización o carpeta.
Para obtener más información sobre cómo otorgar roles, consulta Administra el acceso a proyectos, carpetas y organizaciones.
También puedes obtener los permisos necesarios a través de roles personalizados o cualquier otro rol predefinido.
Crea una estimación
Ve a la página Crear estimación de perfil de datos.
Selecciona tu organización.
En las siguientes secciones, se proporciona más información sobre los pasos de la página Crear estimación de perfil de datos. Al final de cada sección, haz clic en Continuar.
Selecciona un recurso para analizarlo
Realiza una de las siguientes acciones:- Para crear una estimación para una organización, selecciona Analizar toda la organización.
- Para crear una estimación para una carpeta, selecciona Analizar la carpeta seleccionada. Luego, haz clic en Examinar y selecciona la carpeta.
Filtros y condiciones de entrada
Puedes omitir esta sección si deseas incluir todas las tablas de BigQuery en la organización o carpeta en tu estimación.En esta sección, creas filtros para especificar ciertos subconjuntos de tus datos que deseas incluir o excluir de la estimación. Para los subconjuntos que incluyes en la estimación, también especificas las condiciones que debe cumplir una tabla en el subconjunto para incluirse en la estimación.
Para establecer filtros y condiciones, sigue estos pasos:
- Haz clic en Agregar filtros y condiciones.
En la sección Filtros, define uno o más filtros que especifiquen qué tablas están dentro del alcance de la estimación.
Reemplaza al menos uno de los siguientes elementos:
- Un ID del proyecto o una expresión regular que especifique uno o más proyectos
- Un ID del conjunto de datos o una expresión regular que especifique uno o más conjuntos de datos
- Un ID de la tabla o una expresión regular que especifique una o más tablas
Las expresiones regulares deben seguir la sintaxis RE2.
Por ejemplo, si deseas que todas las tablas de un proyecto se incluyan en el filtro, especifica el ID de ese proyecto y deja los otros dos campos en blanco.
Si deseas agregar más filtros, haz clic en Agregar filtro y repite este paso.
Si los subconjuntos de datos definidos por tus filtros deben excluirse de la estimación, desactiva la opción Incluir las tablas que coinciden en mi estimación. Si desactivas esta opción, se ocultan las condiciones descritas en el resto de esta sección.
Opcional: En la sección Condiciones, especifica las condiciones que deben cumplir las tablas coincidentes para incluirse en la estimación. Si omites este paso, la protección de datos sensibles incluye todas las tablas compatibles que coinciden con tus filtros, independientemente de sus tamaños y antigüedad.
Configura las siguientes opciones:
Condiciones mínimas: Para excluir tablas pequeñas o nuevas de la estimación, establece un recuento mínimo de filas o una antigüedad mínima de la tabla.
Condición de tiempo: Para excluir tablas antiguas, activa la condición de tiempo. Luego, elige una fecha y hora. Cualquier tabla creada hasta esa fecha se excluye de la estimación.
Por ejemplo, si estableces la condición de tiempo en 4/5/22, 11:59 p.m., Sensitive Data Protection excluye de la estimación cualquier tabla creada hasta el 4 de mayo de 2022 a las 11:59 p.m.
Tablas para generar perfiles: Para especificar los tipos de tablas que se incluirán en la estimación, selecciona Solo incluir las tablas de uno o más tipos especificados. Luego, selecciona los tipos de tablas que deseas incluir.
Si no activas esta condición o no seleccionas ningún tipo de tabla, Sensitive Data Protection incluye todas las tablas compatibles en la estimación.
Supongamos que tienes la siguiente configuración:
Condiciones mínimas
- Recuento mínimo de filas: 10 filas
- Duración mínima: 24 horas
Condición de tiempo
- Timestamp: 4/5/22, 11:59 p.m.
Tablas para generar perfiles
Se selecciona la opción Solo incluir las tablas de uno o más tipos especificados. En la lista de tipos de tablas, solo se selecciona Generar perfiles de tablas de BigLake.
En este caso, Sensitive Data Protection excluye cualquier tabla creada hasta el 4 de mayo de 2022 a las 11:59 p.m. Entre las tablas creadas después de esta fecha y hora, Sensitive Data Protection solo genera perfiles de las tablas de BigLake que tienen 10 filas o que tienen al menos 24 horas de antigüedad.
Haz clic en Listo.
Si deseas agregar más filtros y condiciones, haz clic en Agregar filtros y condiciones y repite los pasos anteriores.
El último elemento de la lista de filtros y condiciones es siempre el que tiene la etiqueta Filtros y condiciones predeterminados. Esta configuración predeterminada se aplica a las tablas del recurso seleccionado (organización o carpeta) que no coinciden con ninguno de los filtros y condiciones que creaste.

Si deseas ajustar los filtros y las condiciones predeterminados, haz clic en Editar filtros y condiciones y ajusta la configuración según sea necesario.
Administra la facturación y el contenedor del agente de servicio
En esta sección, especificas el proyecto que se usará como contenedor de agente de servicio. Puedes hacer que Sensitive Data Protection cree automáticamente un proyecto nuevo o elegir un proyecto existente.
Independientemente de si usas un agente de servicio recién creado o reutilizas uno existente, asegúrate de que tenga acceso de lectura a los datos de los que se generarán perfiles.
Crea un proyecto automáticamente
Si no tienes los permisos necesarios para crear un proyecto en la organización, debes seleccionar un proyecto existente o bien obtener los permisos necesarios. Para obtener información sobre los permisos necesarios, consulta Roles necesarios para trabajar con perfiles de datos a nivel de la organización o la carpeta.
Para crear automáticamente un proyecto que se usará como contenedor de agente de servicio, sigue estos pasos:
- En el campo Contenedor de agente de servicio, revisa el ID del proyecto sugerido y edítalo según sea necesario.
- Haz clic en Crear.
- Opcional: Actualiza el nombre predeterminado del proyecto.
Selecciona la cuenta a la que se facturarán todas las operaciones facturables relacionadas con este proyecto nuevo, incluidas las operaciones que no están relacionadas con el descubrimiento.
Haz clic en Crear.
La protección de datos sensibles crea el proyecto nuevo. El agente de servicio dentro de este proyecto se usará para autenticarse en Sensitive Data Protection y otras APIs.
Selecciona un proyecto existente
Para seleccionar un proyecto existente como contenedor de agente de servicio, haz clic en el campo Contenedor de agente de servicio y selecciona el proyecto.
Establece la ubicación para almacenar la estimación
En la lista Ubicación del recurso, selecciona la región en la que deseas almacenar esta estimación.
La ubicación en la que elijas almacenar tu estimación no afecta los datos que se analizarán. Además, no afecta dónde se almacenan los perfiles de datos más adelante. Tus datos se analizan en la misma región en la que se almacenan (según se establece en BigQuery). Para obtener más información, consulta Consideraciones sobre la residencia de los datos.
Revisa tu configuración y haz clic en Crear.
La protección de datos sensibles crea la estimación y la agrega a la lista de estimaciones. Luego, ejecuta la estimación.
Según la cantidad de datos que haya en el recurso, una estimación puede tardar hasta 24 horas en completarse. Mientras tanto, puedes cerrar la página de la protección de datos sensibles y volver más tarde. Aparecerá una notificación en la Google Cloud console cuando la estimación esté lista.
Cómo ver una estimación
Ve a la lista de estimaciones.
Haz clic en la estimación que deseas ver. La estimación contiene lo siguiente:
- La cantidad de tablas en el recurso, menos las tablas que excluyes a través de filtros y condiciones
- La cantidad total de datos a la que equivalen las tablas
- La cantidad de unidades de suscripción necesarias para generar perfiles de esta cantidad de datos cada mes
- El costo del descubrimiento inicial, que es el costo aproximado de generar perfiles de las tablas que se encontraron. Esta estimación se basa solo en una instantánea de los datos actuales y no tiene en cuenta cuánto crecen tus datos dentro de un período determinado.
- Estimaciones de costos adicionales para generar perfiles solo de las tablas que tienen menos de 6, 12 o 24 meses de antigüedad Estas estimaciones adicionales se proporcionan para mostrarte cómo limitar aún más la cobertura de tus datos puede ayudarte a controlar el costo de la generación de perfiles de datos.
- El costo mensual estimado de generar perfiles de tus datos, suponiendo que tu uso de BigQuery cada mes sea el mismo que el de este mes
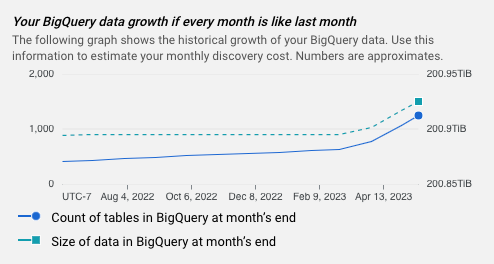
- Un gráfico que muestra el crecimiento de BigQuery a lo largo del tiempo
- Los detalles de configuración que estableciste
Gráfico de estimación
Cada estimación incluye un gráfico que muestra el crecimiento histórico de tus datos de BigQuery. Puedes usar esta información para estimar el costo mensual de la generación de perfiles de datos.
¿Qué sigue?
- Obtén información sobre los precios de la generación de perfiles de datos.
- Obtén más información sobre los perfiles de datos para datos de BigQuery datos.
- Obtén información para generar perfiles de datos en una organización o carpeta.
- Obtén información para generar perfiles de datos en un solo proyecto.