
k-匿名性是数据集的一个属性,指示其记录的可重标识性。如果数据集中每个人的准标识符与该数据集中至少 k - 1 个其他人相同,则该数据集具有 k-匿名性。
您可以根据数据集的一个或多个列或字段计算 k-匿名性值。本主题演示了如何使用 Sensitive Data Protection 计算数据集的 k-匿名性值。如需从总体上详细了解 k-匿名性或风险分析,请参阅风险分析概念主题,然后再继续。
准备工作
在继续操作之前,请确保您已完成以下步骤:
- 登录您的 Google 账号。
- 在 Google Cloud 控制台的项目选择器页面上,选择或创建 Google Cloud 项目。 转到项目选择器
- 确保您的 Google Cloud 项目已启用结算功能。 了解如何确认您的项目已启用结算功能。
- 启用 Sensitive Data Protection。 启用 Sensitive Data Protection
- 选择要分析的 BigQuery 数据集。Sensitive Data Protection 通过扫描 BigQuery 表来计算 k-匿名性指标k。
- 在数据集中确定一个标识符(如果适用)和至少一个准标识符。如需了解详情,请参阅风险分析术语和技术。
计算 k-匿名性
每当运行风险分析作业时,Sensitive Data Protection 都会执行风险分析。您必须先创建作业,方法是使用Google Cloud 控制台、发送 DLP API 请求或使用 Sensitive Data Protection 客户端库。
控制台
在 Google Cloud 控制台中,前往创建风险分析页面。
在选择输入数据部分中,通过输入包含表的项目的 ID、表的数据集 ID 以及表的名称来指定要扫描的 BigQuery 表。
在要计算的隐私权指标下,选择 k-匿名性。
在任务 ID 部分中,您可以视需要为作业提供自定义标识符,然后选择 Sensitive Data Protection 将在其中处理您的数据的资源位置。完成操作后,请点击继续。
在定义字段部分中,您可为 k-匿名性风险作业指定标识符和准标识符。Sensitive Data Protection 会访问您在上一步中指定的 BigQuery 表的元数据,并尝试填充字段列表。
- 选择相应的复选框,将字段指定为标识符 (ID) 或准标识符 (QI)。您必须选择 0 个或 1 个标识符以及至少 1 个准标识符。
- 如果 Sensitive Data Protection 无法填充字段,请点击输入字段名称以手动输入一个或多个字段,并将每个字段设置为标识符或准标识符。完成操作后,请点击继续。
在添加操作部分中,您可以添加可选操作,以便在风险作业完成时执行。可用的选项包括:
- 保存到 BigQuery:将风险分析扫描的结果保存到 BigQuery 表中。
发布到 Pub/Sub:将通知发布到 Pub/Sub 主题。
通过电子邮件发送通知:向您发送电子邮件,其中包含结果。完成操作后,请点击创建。
k-匿名性风险分析作业会立即启动。
C#
如需了解如何安装和使用 Sensitive Data Protection 客户端库,请参阅 Sensitive Data Protection 客户端库。
如需向 Sensitive Data Protection 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为本地开发环境设置身份验证。
Go
如需了解如何安装和使用 Sensitive Data Protection 客户端库,请参阅 Sensitive Data Protection 客户端库。
如需向 Sensitive Data Protection 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为本地开发环境设置身份验证。
Java
如需了解如何安装和使用 Sensitive Data Protection 客户端库,请参阅 Sensitive Data Protection 客户端库。
如需向 Sensitive Data Protection 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为本地开发环境设置身份验证。
Node.js
如需了解如何安装和使用 Sensitive Data Protection 客户端库,请参阅 Sensitive Data Protection 客户端库。
如需向 Sensitive Data Protection 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为本地开发环境设置身份验证。
PHP
如需了解如何安装和使用 Sensitive Data Protection 客户端库,请参阅 Sensitive Data Protection 客户端库。
如需向 Sensitive Data Protection 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为本地开发环境设置身份验证。
Python
如需了解如何安装和使用 Sensitive Data Protection 客户端库,请参阅 Sensitive Data Protection 客户端库。
如需向 Sensitive Data Protection 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为本地开发环境设置身份验证。
REST
如需运行新的风险分析作业以计算 k-匿名性,请向 projects.dlpJobs 资源发送一个请求,其中 PROJECT_ID 表示项目标识符:
https://dlp.googleapis.com/v2/projects/PROJECT_ID/dlpJobs
该请求包含一个由以下项组成的 RiskAnalysisJobConfig 对象:
PrivacyMetric对象。您可以在此处添加KAnonymityConfig对象来表明您正在计算 k-匿名性。BigQueryTable对象。通过包括以下所有项指定要扫描的 BigQuery 表格:projectId:包含该表的项目 ID。datasetId:表格的数据集 ID。tableId:表格的名称。
由一个或多个
Action对象组成的对象集,这些对象表示在作业完成时要按给定顺序运行的操作。每个Action对象都可以包含以下操作之一:SaveFindings对象:将风险分析扫描的结果保存到 BigQuery 表格中。JobNotificationEmails对象:向您发送电子邮件,其中包含结果。
在
KAnonymityConfig对象中,指定以下内容:quasiIds[]:要扫描的一个或多个准标识符(FieldId对象),用于计算 k-匿名性。当您指定多个准标识符时,它们会被视为单个复合键。结构体和重复数据类型不受支持,但只要嵌套字段本身不是结构体或嵌套在重复字段中,嵌套字段就受支持。entityId:可选的标识符值;如果设置此项,则指示在计算 k-匿名性时应将与每个不同entityId对应的所有行组合在一起。通常,entityId将是表示唯一用户身份的列,例如客户 ID 或用户 ID。如果entityId出现在多个具有不同准标识符值的行中,这些行将连接形成一个多集,以用作该实体的准标识符。如需详细了解实体 ID,请参阅风险分析概念主题中的实体 ID 与 k-匿名性计算。
向 DLP API 发送请求后,它将立即启动风险分析作业。
列出已完成的风险分析作业
您可以查看当前项目中已运行的风险分析作业的列表。
控制台
如需在Google Cloud 控制台中列出正在运行和先前运行的风险分析作业,请执行以下操作:
在 Google Cloud 控制台中,打开 Sensitive Data Protection。
点击页面顶部的作业和作业触发器标签页。
点击风险作业标签页。
系统会显示风险列表。
协议
如需列出正在运行和先前运行的风险分析作业,请向 projects.dlpJobs 资源发送 GET 请求。添加作业类型过滤条件 (?type=RISK_ANALYSIS_JOB) 可将响应范围缩小至风险分析作业。
https://dlp.googleapis.com/v2/projects/PROJECT_ID/dlpJobs?type=RISK_ANALYSIS_JOB
您收到的响应将以 JSON 表示法包含所有当前和以前的风险分析作业。
查看 k-匿名性作业结果
Google Cloud 控制台中的 Sensitive Data Protection 包含已完成的 k-匿名性作业的内置可视化功能。按照上一部分中的说明进行操作后,请在风险分析作业列表中,选择您要查看其结果的作业。假设作业已成功运行,风险分析详情页面顶部将如下所示:
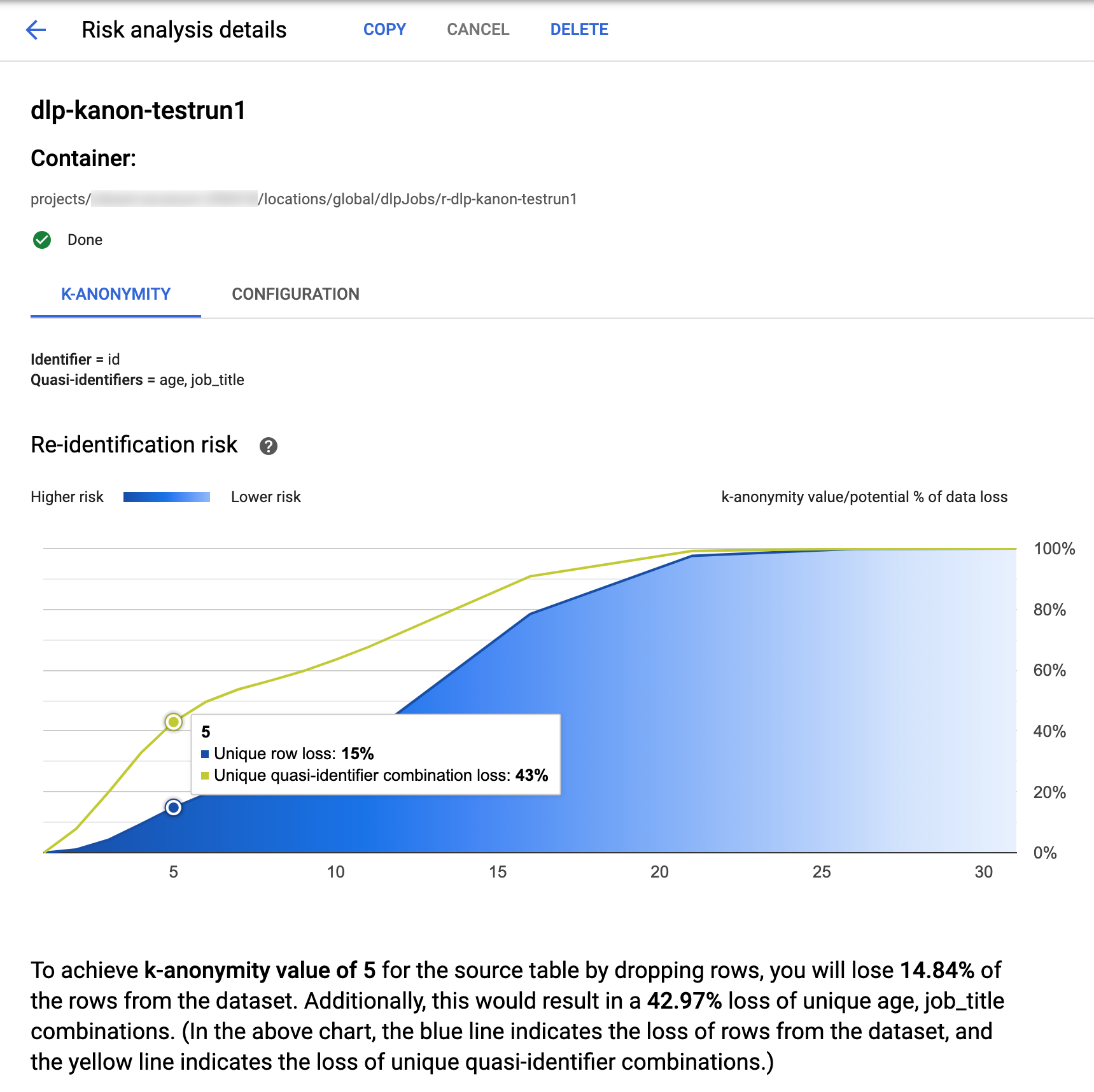
该页面顶部列出了有关 k-匿名性风险作业的信息,包括其作业 ID 以及其资源位置(在容器下)。
如需查看 k-匿名性计算的结果,请点击 K-匿名性标签页。如需查看风险分析作业的配置,请点击配置标签页。
K-匿名性标签页首先列出实体 ID(如果有)以及用于计算 k-匿名性的准标识符。
风险图表
重标识风险图表在 y 轴上绘制唯一行和唯一准标识符组合的潜在数据泄露百分比,以在 x 轴上实现 k-匿名性值。。图表的颜色还表示潜在风险程度。较深的蓝色表示风险较高,而较浅的蓝色表示风险较低。
k-匿名性值越大,表示重标识的风险越小。但是,要实现较大的 k-匿名性值,您需要移除总行数的较大百分比以及较大的唯一准标识符组合,这可能会降低数据的效用。如需查看某个 k-匿名性值的特定潜在泄露百分比值,请将光标悬停在图表上。如屏幕截图所示,图表上会显示一个提示。
如需查看特定 k-匿名性值的更多详情,请点击相应的数据点。图表下方会显示详细的说明,并且页面下方显示了示例数据表。
风险示例数据表
风险作业结果页面的第二个组成部分是示例数据表。它会显示给定目标 k-匿名性值的准标识符组合。
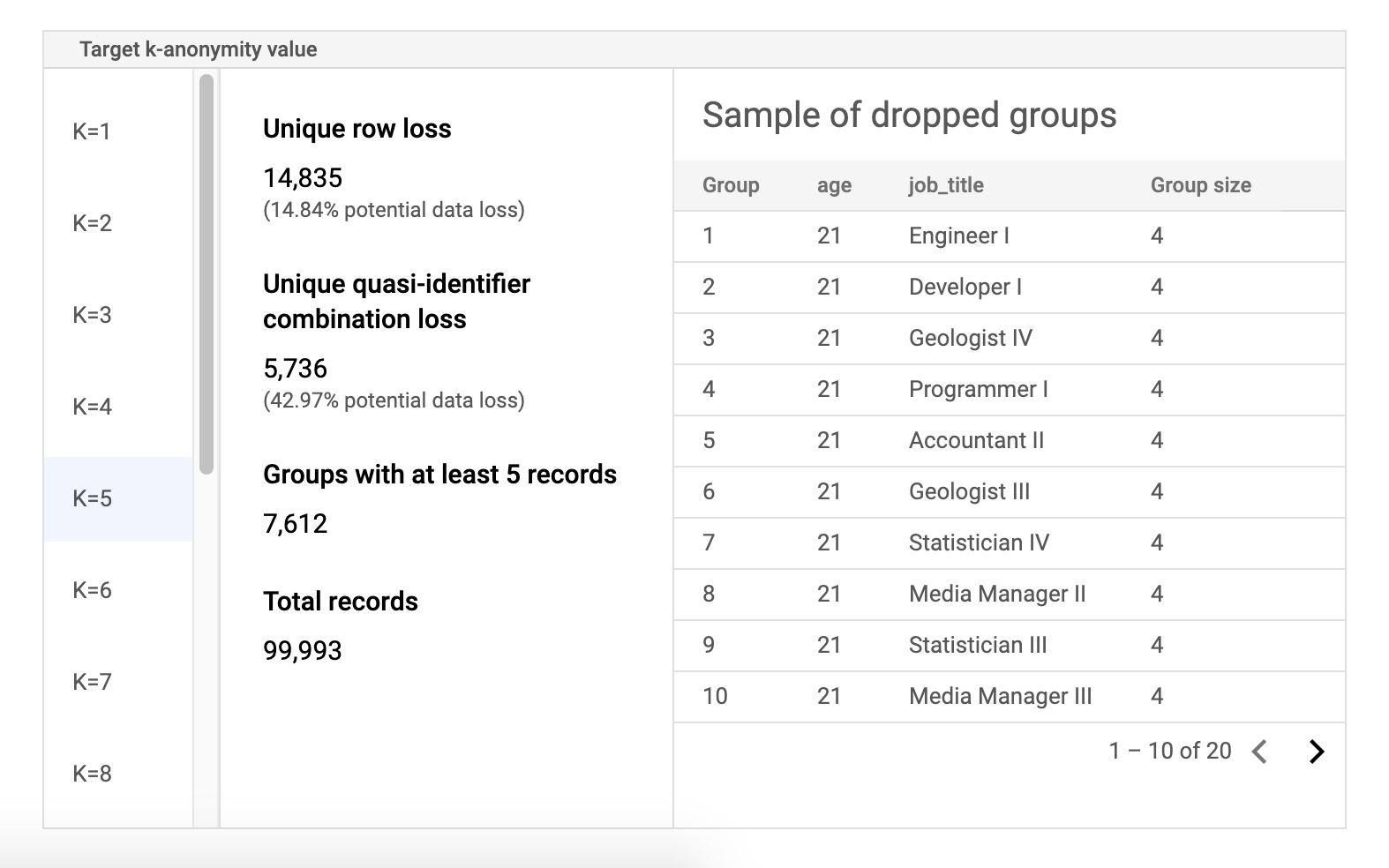
表的第一列列出了 k-匿名性值。点击 k-匿名性值以查看为达到该值而需要丢弃的相应样本数据。
第二列会显示不重复的行和准标识符组合的各自潜在的数据泄露,以及具有至少 k 条记录的群组数和记录总数。
最后一列会显示共用一个准标识符组合的群组的一个示例,以及该组合存在的记录数量。
使用 REST 检索作业详情
如需使用 REST API 检索 k-匿名性风险分析作业,请将以下 GET 请求发送到 projects.dlpJobs 资源。将 PROJECT_ID 替换为您的项目 ID,并将 JOB_ID 替换为您要获取其结果的作业的标识符。作业 ID 在启动作业时返回,也可通过列出所有作业来检索。
GET https://dlp.googleapis.com/v2/projects/PROJECT_ID/dlpJobs/JOB_ID
该请求会返回包含作业实例的 JSON 对象。分析的结果位于 AnalyzeDataSourceRiskDetails 对象的 "riskDetails" 键中。如需了解详情,请参阅 DlpJob 资源的 API 参考文档。
代码示例:计算具有实体 ID 的 k-匿名性
此示例创建了一个风险分析作业,用于计算具有实体 ID 的 k-匿名性。
如需详细了解实体 ID,请参阅实体 ID 与 k-匿名性计算。
C#
如需了解如何安装和使用 Sensitive Data Protection 客户端库,请参阅 Sensitive Data Protection 客户端库。
如需向 Sensitive Data Protection 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为本地开发环境设置身份验证。
Go
如需了解如何安装和使用 Sensitive Data Protection 客户端库,请参阅 Sensitive Data Protection 客户端库。
如需向 Sensitive Data Protection 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为本地开发环境设置身份验证。
Java
如需了解如何安装和使用 Sensitive Data Protection 客户端库,请参阅 Sensitive Data Protection 客户端库。
如需向 Sensitive Data Protection 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为本地开发环境设置身份验证。
Node.js
如需了解如何安装和使用 Sensitive Data Protection 客户端库,请参阅 Sensitive Data Protection 客户端库。
如需向 Sensitive Data Protection 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为本地开发环境设置身份验证。
PHP
如需了解如何安装和使用 Sensitive Data Protection 客户端库,请参阅 Sensitive Data Protection 客户端库。
如需向 Sensitive Data Protection 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为本地开发环境设置身份验证。
Python
如需了解如何安装和使用 Sensitive Data Protection 客户端库,请参阅 Sensitive Data Protection 客户端库。
如需向 Sensitive Data Protection 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为本地开发环境设置身份验证。