
K-anonymity 是指資料集的一個屬性,表示資料集記錄的重新識別性。如果資料集中每個人的準識別項與資料集中至少其他 k- 1 個人相同,則這個資料集就符合 k-anonymous。
您可以根據資料集的一或多個資料欄或欄位,計算 k-anonymity 值。本主題將示範如何使用 Sensitive Data Protection,計算資料集的 k-anonymity 值。如要進一步瞭解 k-anonymity 或一般風險分析,請先參閱風險分析概念主題,然後再繼續閱讀本文。
事前準備
繼續操作前,請務必先完成下列事項:
- 登入您的 Google 帳戶。
- 在 Google Cloud 控制台的專案選擇器頁面中,選取或建立 Google Cloud 專案。 前往專案選取器
- 請確認您已為 Google Cloud 專案啟用計費功能。瞭解如何確認專案已啟用計費功能。
- 啟用 Sensitive Data Protection。 啟用 Sensitive Data Protection
- 選取要分析的 BigQuery 資料集。Sensitive Data Protection 會掃描 BigQuery 資料表,計算 k 匿名性指標。
- 判斷資料集中的識別項 (如適用) 和至少一個準識別項。詳情請參閱「風險分析術語與技術」。
計算 k-anonymity
每當執行風險分析工作時,Sensitive Data Protection 都會執行風險分析。您必須先建立工作,方法是使用Google Cloud 控制台、傳送 DLP API 要求,或使用 Sensitive Data Protection 用戶端程式庫。
控制台
前往 Google Cloud 控制台的「建立風險分析」頁面。
在「選擇輸入資料」部分,輸入含有資料表的專案 ID、資料表的資料集 ID 和資料表名稱,指定要掃描的 BigQuery 資料表。
在「要計算的隱私權指標」下方,選取「k-匿名」。
在「Job ID」(工作 ID) 區段中,您可以選擇為工作提供自訂 ID,並選取 資源位置,讓 Sensitive Data Protection 處理資料。完成後,按一下「繼續」。
在「定義欄位」部分,為 k 匿名風險工作指定識別碼和準識別碼。Sensitive Data Protection 會存取您在上一個步驟中指定的 BigQuery 資料表的中繼資料,並嘗試填入欄位清單。
- 選取適當的核取方塊,將欄位指定為識別項 (ID) 或準識別項 (QI)。您必須選取 0 或 1 個識別項,以及至少 1 個準識別項。
- 如果「機密資料防護」無法填入欄位,請按一下「輸入欄位名稱」,手動輸入一或多個欄位,並將每個欄位設為識別項或準識別項。完成後,按一下「繼續」。
在「新增動作」部分,您可以新增選用的動作,在風險工作完成時執行。可用的選項如下:
- 儲存至 BigQuery:將風險分析掃描的結果儲存至 BigQuery 表格。
發布至 Pub/Sub:將通知發布至 Pub/Sub 主題。
透過電子郵件通知:透過電子郵件傳送結果。 完成後,按一下「建立」。
k-anonymity 風險分析作業會立即啟動。
C#
如要瞭解如何安裝及使用 Sensitive Data Protection 的用戶端程式庫,請參閱「Sensitive Data Protection 用戶端程式庫」。
如要向 Sensitive Data Protection 進行驗證,請設定應用程式預設憑證。詳情請參閱「為本機開發環境設定驗證機制」。
Go
如要瞭解如何安裝及使用 Sensitive Data Protection 的用戶端程式庫,請參閱「Sensitive Data Protection 用戶端程式庫」。
如要向 Sensitive Data Protection 進行驗證,請設定應用程式預設憑證。詳情請參閱「為本機開發環境設定驗證機制」。
Java
如要瞭解如何安裝及使用 Sensitive Data Protection 的用戶端程式庫,請參閱「Sensitive Data Protection 用戶端程式庫」。
如要向 Sensitive Data Protection 進行驗證,請設定應用程式預設憑證。詳情請參閱「為本機開發環境設定驗證機制」。
Node.js
如要瞭解如何安裝及使用 Sensitive Data Protection 的用戶端程式庫,請參閱「Sensitive Data Protection 用戶端程式庫」。
如要向 Sensitive Data Protection 進行驗證,請設定應用程式預設憑證。詳情請參閱「為本機開發環境設定驗證機制」。
PHP
如要瞭解如何安裝及使用 Sensitive Data Protection 的用戶端程式庫,請參閱「Sensitive Data Protection 用戶端程式庫」。
如要向 Sensitive Data Protection 進行驗證,請設定應用程式預設憑證。詳情請參閱「為本機開發環境設定驗證機制」。
Python
如要瞭解如何安裝及使用 Sensitive Data Protection 的用戶端程式庫,請參閱「Sensitive Data Protection 用戶端程式庫」。
如要向 Sensitive Data Protection 進行驗證,請設定應用程式預設憑證。詳情請參閱「為本機開發環境設定驗證機制」。
REST
如要執行新的風險分析工作來計算 k-anonymity,請將要求傳送至 projects.dlpJobs 資源,其中 PROJECT_ID 表示您的專案 ID:
https://dlp.googleapis.com/v2/projects/PROJECT_ID/dlpJobs
要求會包含由以下項目組成的 RiskAnalysisJobConfig 物件:
A
PrivacyMetric物件。您可以在這裡包含KAnonymityConfig物件,指定要計算 k-anonymity。BigQueryTable物件。包含以下所有項目以指定要掃描的 BigQuery 表格:projectId:包含表格的專案 ID。datasetId:表格的資料集 ID。tableId:資料表名稱。
一或多個
Action物件的組合,代表完成工作時要按照指定順序執行的動作。每個Action物件都可包含以下其中一個動作:SaveFindings物件:將風險分析掃描的結果儲存至 BigQuery 表格。PublishToPubSubobject: 將通知發布至 Pub/Sub 主題。JobNotificationEmails物件:傳送內含結果的電子郵件給你。
您可在
KAnonymityConfig物件中指定以下項目:quasiIds[]:一或多個準 ID (FieldId物件),用於掃描及計算 k-anonymity。當您指定多個準識別項時,系統會將這些準識別項視為單一複合式金鑰。不支援結構和重複資料類型,但可支援巢狀欄位 (只要它們本身並非結構或某個重複欄位內含的巢狀結構)。entityId:選用 ID 值,設定這個項目時,即表示應針對 k-anonymity 計算,將對應到每個獨立entityId的所有資料列分在一組。entityId通常會是表示不重複使用者的資料欄,例如客戶 ID 或使用者 ID。當entityId出現在多個具有不同準識別項值的資料列時,這些資料列會加以彙整形成一個多重集合,用來當做這個實體的準識別項。如要進一步瞭解實體 ID,請參閱風險分析概念主題中的「實體 ID 及計算 k-anonymity」。
只要您將要求傳送至 DLP API,系統就會啟動風險分析工作。
列出已完成的風險分析工作
您可以查看目前專案中已執行的風險分析工作清單。
控制台
如要在Google Cloud 控制台中列出正在執行和先前執行的風險分析工作,請按照下列步驟操作:
在 Google Cloud 控制台中,開啟 Sensitive Data Protection。
按一下頁面頂端的「工作和工作觸發條件」分頁標籤。
按一下「風險工作」分頁標籤。
系統會顯示有風險的工作清單。
通訊協定
如要列出正在執行和先前執行的風險分析工作,請將 GET 要求傳送至 projects.dlpJobs 資源。新增工作類型篩選器 (?type=RISK_ANALYSIS_JOB) 可將回應範圍縮小至僅限風險分析工作。
https://dlp.googleapis.com/v2/projects/PROJECT_ID/dlpJobs?type=RISK_ANALYSIS_JOB
您收到的回應包含所有目前和先前風險分析工作的 JSON 表示法。
查看 k-anonymity 工作結果
在 Google Cloud 控制台中,Sensitive Data Protection 內建已完成 k 匿名工作視覺化功能。按照上一節的指示操作後,從風險分析工作清單中,選取要查看結果的工作。假設工作已順利執行,則「風險分析詳細資料」頁面頂端會顯示如下內容:
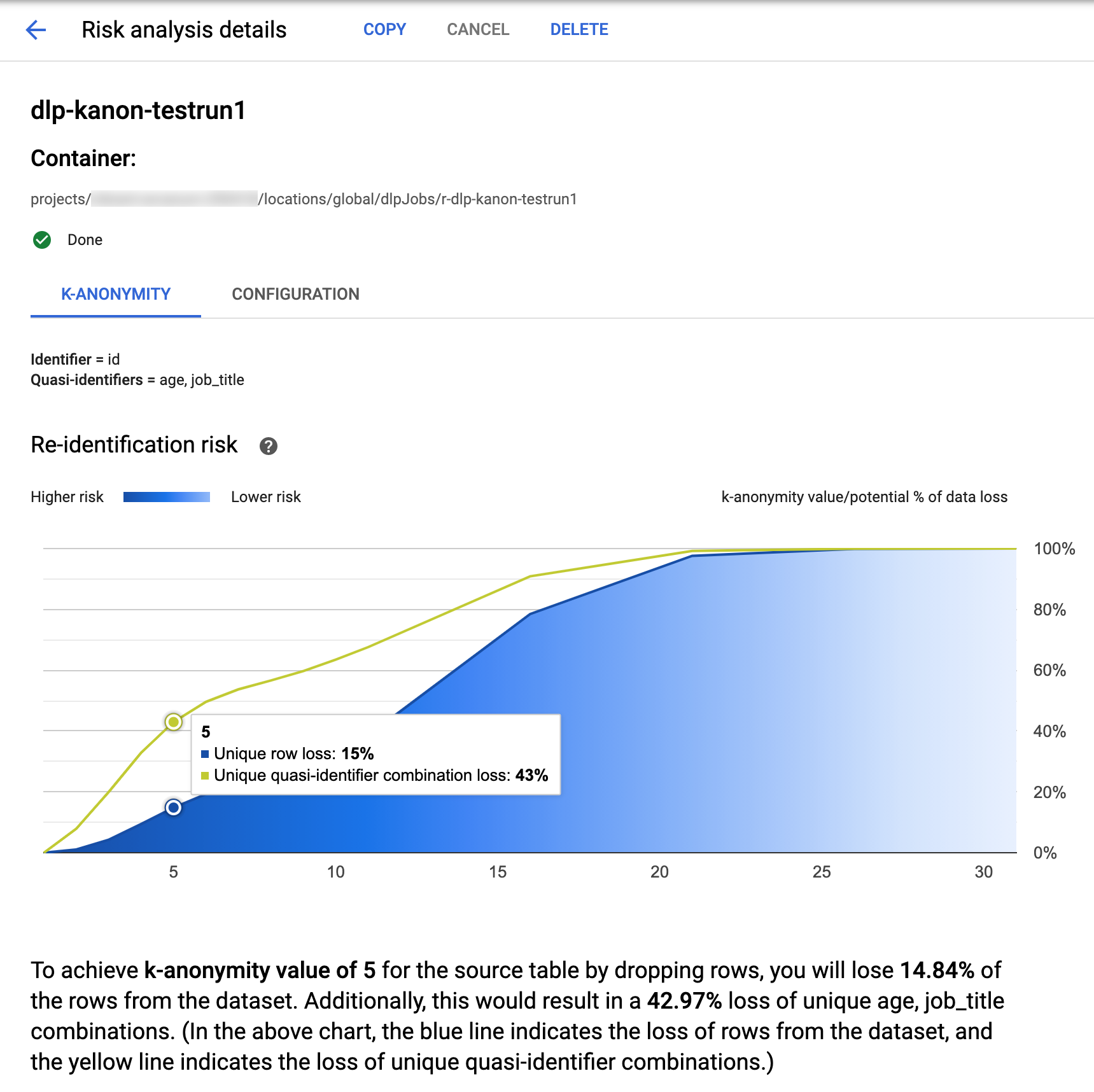
頁面頂端會顯示 k 匿名風險作業的相關資訊,包括作業 ID,以及「容器」下方的資源位置。
如要查看 k-anonymity 計算結果,請按一下「K-anonymity」分頁標籤。如要查看風險分析工作的設定,請按一下「設定」分頁標籤。
「K-anonymity」分頁會先列出實體 ID (如有) 和用於計算 k-anonymity 的準識別碼。
風險圖表
「重新識別風險」圖表會在 y 軸上,繪製出為達成 x 軸上的 k-anonymity 值,獨特資料列和獨特準識別項組合可能損失的資料百分比。圖表的顏色也會指出潛在風險。藍色越深代表風險越高,藍色越淺代表風險越低。
k-anonymity 值越高,表示重新識別的風險越低。不過,如要達到更高的 k-anonymity 值,您需要移除更高百分比的總列數和更高比例的準 ID 組合,這可能會降低資料的實用性。如要查看特定 k-anonymity 值可能的資料遺失百分比,請將游標懸停在圖表上。如螢幕截圖所示,圖表上會顯示工具提示。
如要查看特定 k-anonymity 值的詳細資料,請按一下對應的資料點。圖表下方會顯示詳細說明,頁面下方則會顯示範例資料表。
風險樣本資料表
風險分析工作結果頁面的第二個元件是資料表樣本。並顯示特定目標 k-anonymity 值的準識別項組合。
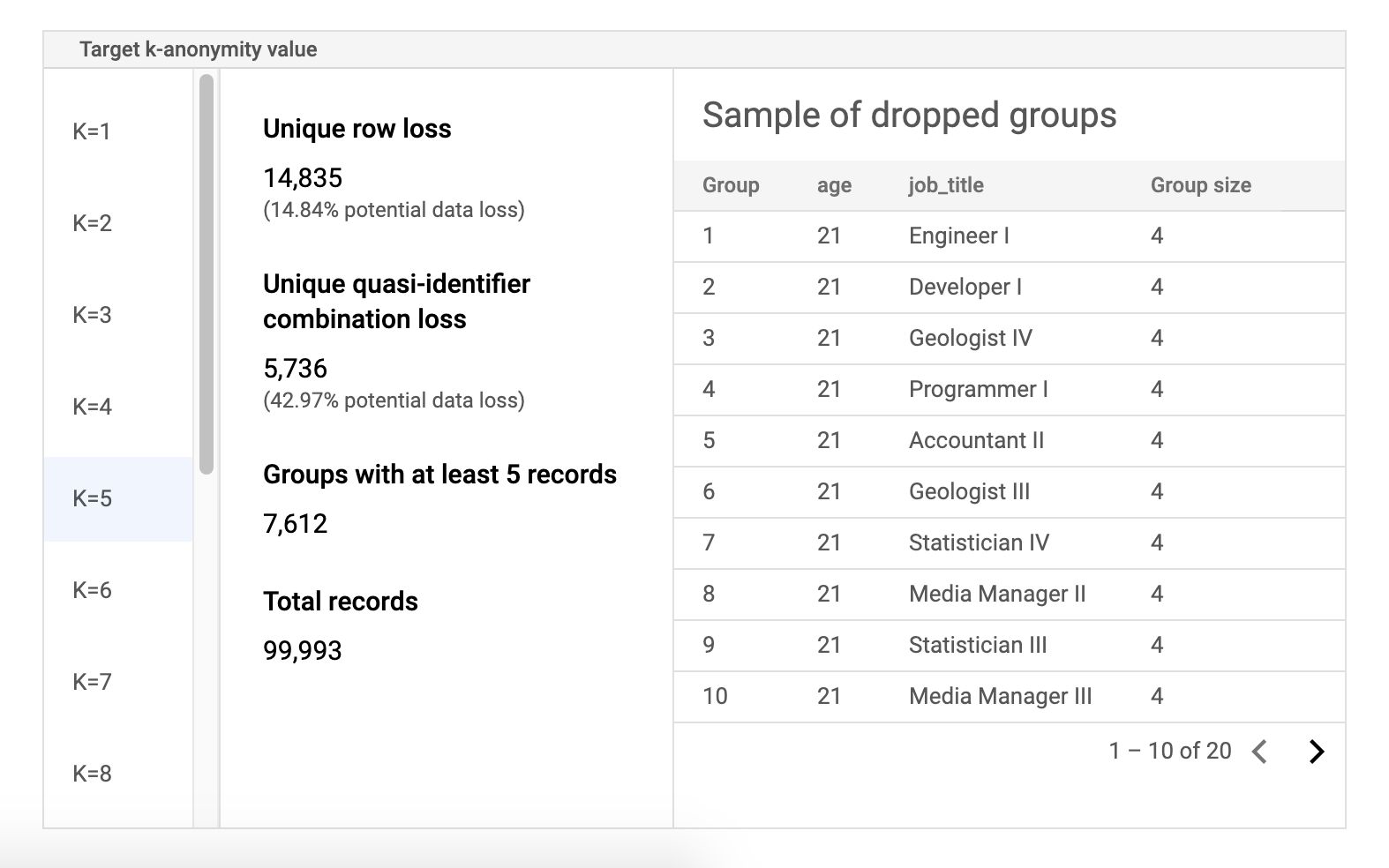
表格的第一欄會列出 k-匿名值。按一下 k-anonymity 值,即可查看為達到該值而需要捨棄的對應樣本資料。
第二欄會顯示不重複資料列和準 ID 組合的潛在資料遺失情形,以及至少有 k 筆記錄的群組數量和記錄總數。
最後一欄會顯示共用準 ID 組合的群組樣本,以及該組合的記錄數。
使用 REST 擷取工作詳細資料
如要使用 REST API 擷取 k-anonymity 風險分析工作的結果,請將下列 GET 要求傳送至 projects.dlpJobs 資源。將 PROJECT_ID 替換為專案 ID,並將 JOB_ID 替換為要取得結果的工作 ID。工作 ID 會在您啟動工作時傳回,您也可以列出所有工作來擷取 ID。
GET https://dlp.googleapis.com/v2/projects/PROJECT_ID/dlpJobs/JOB_ID
要求會傳回包含工作例項的 JSON 物件。分析結果位於 "riskDetails" 鍵中,以 AnalyzeDataSourceRiskDetails 物件的形式呈現。詳情請參閱 DlpJob 資源的 API 參考資料。
程式碼範例:使用實體 ID 計算 k-anonymity
這個範例會建立風險分析工作,計算實體 ID 的 k-匿名性。
如要進一步瞭解實體 ID,請參閱「實體 ID 及計算 k-anonymity」一節。
C#
如要瞭解如何安裝及使用 Sensitive Data Protection 的用戶端程式庫,請參閱「Sensitive Data Protection 用戶端程式庫」。
如要向 Sensitive Data Protection 進行驗證,請設定應用程式預設憑證。詳情請參閱「為本機開發環境設定驗證機制」。
Go
如要瞭解如何安裝及使用 Sensitive Data Protection 的用戶端程式庫,請參閱「Sensitive Data Protection 用戶端程式庫」。
如要向 Sensitive Data Protection 進行驗證,請設定應用程式預設憑證。詳情請參閱「為本機開發環境設定驗證機制」。
Java
如要瞭解如何安裝及使用 Sensitive Data Protection 的用戶端程式庫,請參閱「Sensitive Data Protection 用戶端程式庫」。
如要向 Sensitive Data Protection 進行驗證,請設定應用程式預設憑證。詳情請參閱「為本機開發環境設定驗證機制」。
Node.js
如要瞭解如何安裝及使用 Sensitive Data Protection 的用戶端程式庫,請參閱「Sensitive Data Protection 用戶端程式庫」。
如要向 Sensitive Data Protection 進行驗證,請設定應用程式預設憑證。詳情請參閱「為本機開發環境設定驗證機制」。
PHP
如要瞭解如何安裝及使用 Sensitive Data Protection 的用戶端程式庫,請參閱「Sensitive Data Protection 用戶端程式庫」。
如要向 Sensitive Data Protection 進行驗證,請設定應用程式預設憑證。詳情請參閱「為本機開發環境設定驗證機制」。
Python
如要瞭解如何安裝及使用 Sensitive Data Protection 的用戶端程式庫,請參閱「Sensitive Data Protection 用戶端程式庫」。
如要向 Sensitive Data Protection 進行驗證,請設定應用程式預設憑證。詳情請參閱「為本機開發環境設定驗證機制」。
後續步驟
- 瞭解如何計算資料集的 l-diversity 值。
- 瞭解如何計算資料集的 k-map 值。
- 瞭解如何計算資料集的 δ-presence 值。