
Sensitive Data Protection ti aiuta a trovare, comprendere e gestire i dati sensibili presenti nella tua infrastruttura. Dopo aver eseguito la scansione dei contenuti per individuare dati sensibili utilizzando Sensitive Data Protection, hai diverse opzioni per l'utilizzo di queste informazioni sui dati. Questo argomento mostra come sfruttare la potenza di altre Google Cloud funzionalità come BigQuery, Cloud SQL e Data Studio per:
- Archiviare i risultati delle scansioni di Sensitive Data Protection direttamente in BigQuery.
- Generare report sulla posizione dei dati sensibili nella tua infrastruttura.
- Eseguire analisi SQL avanzate per capire dove sono archiviati i dati sensibili e di che tipo sono.
- Automatizzare gli avvisi o le azioni da attivare in base a un singolo insieme o a una combinazione di risultati.
Questo argomento contiene anche un esempio completo di come utilizzare Sensitive Data Protection insieme ad altre Google Cloud funzionalità per eseguire tutte queste operazioni.
Scansiona un bucket di archiviazione
Innanzitutto, esegui una scansione dei dati. Di seguito sono riportate le informazioni di base su come eseguire la scansione dei repository di archiviazione utilizzando Sensitive Data Protection. Per istruzioni complete sulla scansione dei repository di archiviazione, incluso l'utilizzo delle librerie client, consulta Ispezione dello spazio di archiviazione e dei database per l'individuazione di dati sensibili Data.
Per eseguire un'operazione di scansione su un Google Cloud repository di archiviazione, assembla un oggetto JSON che includa i seguenti oggetti di configurazione:
InspectJobConfig: configura il job di scansione di Sensitive Data Protection ed è composto da:StorageConfig: il repository di archiviazione da scansionare.InspectConfig: come e cosa scansionare. Puoi anche utilizzare un modello di ispezione per definire la configurazione dell'ispezione.Action: attività da eseguire al completamento del job. Può includere il salvataggio dei risultati in una tabella BigQuery o la pubblicazione di una notifica in Pub/Sub.
In questo esempio, esegui la scansione di un bucket Cloud Storage per individuare nomi di persone, numeri di telefono, codici fiscali statunitensi e indirizzi email. Poi invii i risultati a una tabella BigQuery dedicata all'archiviazione dell'output di Sensitive Data Protection. Il seguente JSON può essere salvato in un file o
inviato direttamente al
create
metodo della
DlpJob
risorsa Sensitive Data Protection.
Input JSON:
POST https://dlp.googleapis.com/v2/projects/[PROJECT_ID]/dlpJobs
{
"inspectJob":{
"inspectConfig":{
"infoTypes":[
{
"name":"PERSON_NAME"
},
{
"name":"PHONE_NUMBER"
},
{
"name":"US_SOCIAL_SECURITY_NUMBER"
},
{
"name":"EMAIL_ADDRESS"
}
],
"includeQuote":true
},
"storageConfig":{
"cloudStorageOptions":{
"fileSet":{
"url":"gs://[BUCKET_NAME]/**"
}
}
},
"actions":[
{
"saveFindings":{
"outputConfig":{
"table":{
"projectId":"[PROJECT_ID]",
"datasetId":"[DATASET_ID]",
"tableId":"[TABLE_ID]"
}
}
}
}
]
}
}
Se specifichi due asterischi (**) dopo l'indirizzo del bucket Cloud Storage (gs://[BUCKET_NAME]/**), indichi al job di scansione di eseguire la scansione in modo ricorsivo. Se inserisci un singolo asterisco (*), il job eseguirà la scansione solo del livello di directory specificato e non più in profondità.
L'output verrà salvato nella tabella specificata all'interno del progetto e del set di dati indicati. I job successivi che specificano l'ID tabella indicato aggiungono i risultati alla stessa tabella. Puoi anche omettere una
"tableId"
chiave se vuoi indicare a Sensitive Data Protection di creare una nuova
tabella ogni volta che viene eseguita la scansione.
Dopo aver inviato questo JSON in una richiesta al
projects.dlpJobs.create
metodo tramite l'URL specificato, riceverai la seguente risposta:
Output JSON:
{
"name":"projects/[PROJECT_ID]/dlpJobs/[JOB_ID]",
"type":"INSPECT_JOB",
"state":"PENDING",
"inspectDetails":{
"requestedOptions":{
"snapshotInspectTemplate":{
},
"jobConfig":{
"storageConfig":{
"cloudStorageOptions":{
"fileSet":{
"url":"gs://[BUCKET_NAME]/**"
}
}
},
"inspectConfig":{
"infoTypes":[
{
"name":"PERSON_NAME"
},
{
"name":"PHONE_NUMBER"
},
{
"name":"US_SOCIAL_SECURITY_NUMBER"
},
{
"name":"EMAIL_ADDRESS"
}
],
"minLikelihood":"POSSIBLE",
"limits":{
},
"includeQuote":true
},
"actions":[
{
"saveFindings":{
"outputConfig":{
"table":{
"projectId":"[PROJECT_ID]",
"datasetId":"[DATASET_ID]",
"tableId":"[TABLE_ID]"
}
}
}
}
]
}
}
},
"createTime":"2018-11-19T21:09:07.926Z"
}
Al termine del job, i risultati vengono salvati nella tabella BigQuery indicata.
Per ottenere lo stato del job, chiama il
projects.dlpJobs.get
metodo o invia una richiesta GET al seguente URL, sostituendo [PROJECT_ID]
con l'ID progetto e [JOB_ID] con l'identificatore del job fornito nella
risposta dell'API Cloud Data Loss Prevention alla richiesta di creazione del job (l'identificatore del job sarà
preceduto da "i-"):
GET https://dlp.googleapis.com/v2/projects/[PROJECT_ID]/dlpJobs/[JOB_ID]
Per il job appena creato, questa richiesta restituisce il seguente JSON. Tieni presente che dopo i dettagli dell'ispezione viene restituito un riepilogo dei risultati della scansione. Se la scansione non fosse ancora stata completata, la chiave "state" specificherebbe
"RUNNING".
Output JSON:
{
"name":"projects/[PROJECT_ID]/dlpJobs/[JOB_ID]",
"type":"INSPECT_JOB",
"state":"DONE",
"inspectDetails":{
"requestedOptions":{
"snapshotInspectTemplate":{
},
"jobConfig":{
"storageConfig":{
"cloudStorageOptions":{
"fileSet":{
"url":"gs://[BUCKET_NAME]/**"
}
}
},
"inspectConfig":{
"infoTypes":[
{
"name":"PERSON_NAME"
},
{
"name":"PHONE_NUMBER"
},
{
"name":"US_SOCIAL_SECURITY_NUMBER"
},
{
"name":"EMAIL_ADDRESS"
}
],
"minLikelihood":"POSSIBLE",
"limits":{
},
"includeQuote":true
},
"actions":[
{
"saveFindings":{
"outputConfig":{
"table":{
"projectId":"[PROJECT_ID]",
"datasetId":"[DATASET_ID]",
"tableId":"[TABLE_ID]"
}
}
}
}
]
}
},
"result":{
"processedBytes":"536734051",
"totalEstimatedBytes":"536734051",
"infoTypeStats":[
{
"infoType":{
"name":"PERSON_NAME"
},
"count":"269679"
},
{
"infoType":{
"name":"EMAIL_ADDRESS"
},
"count":"256"
},
{
"infoType":{
"name":"PHONE_NUMBER"
},
"count":"7"
}
]
}
},
"createTime":"2018-11-19T21:09:07.926Z",
"startTime":"2018-11-19T21:10:20.660Z",
"endTime":"2018-11-19T22:07:39.725Z"
}
Esegui l'analisi in BigQuery
Ora che hai creato una nuova tabella BigQuery con i risultati della scansione di Sensitive Data Protection, il passaggio successivo consiste nell'eseguire l'analisi della tabella.
Sul lato sinistro della Google Cloud console, nella sezione Big Data, fai clic su BigQuery. Apri il progetto e il set di dati, quindi individua la nuova tabella creata.
Puoi eseguire query SQL su questa tabella per scoprire di più su ciò che Sensitive Data Protection ha trovato nel bucket di dati. Ad esempio, esegui la seguente query per contare tutti i risultati della scansione per infoType, sostituendo i segnaposto con i valori reali appropriati:
SELECT
info_type.name,
COUNT(*) AS iCount
FROM
`[PROJECT_ID].[DATASET_ID].[TABLE_ID]`
GROUP BY
info_type.name
Questa query genera un riepilogo dei risultati per il bucket che potrebbe essere simile al seguente:
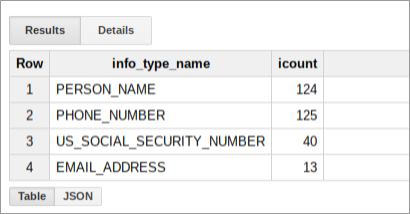
Crea un report in Data Studio
Data Studio ti consente di creare report personalizzati basati su tabelle BigQuery. In questa sezione, creerai un semplice report tabellare in Data Studio basato sui risultati di Sensitive Data Protection archiviati in BigQuery.
- Apri Data Studio e avvia un nuovo report.
- Fai clic su Crea nuova origine dati.
- Nell'elenco dei connettori, fai clic su BigQuery. Se necessario, autorizza Data Studio a connettersi ai tuoi progetti BigQuery facendo clic su Autorizza.
- Ora scegli la tabella da cercare, quindi fai clic su I miei progetti o Progetti condivisi, a seconda della posizione del progetto. Trova il tuo progetto, set di dati e tabella negli elenchi della pagina.
- Fai clic su Connetti per eseguire il report.
- Fai clic su Aggiungi al report.
Ora creerai una
tabella che mostra
la frequenza di ogni infoType. Seleziona il campo info_type.name come Dimensione. La tabella risultante sarà simile alla seguente:
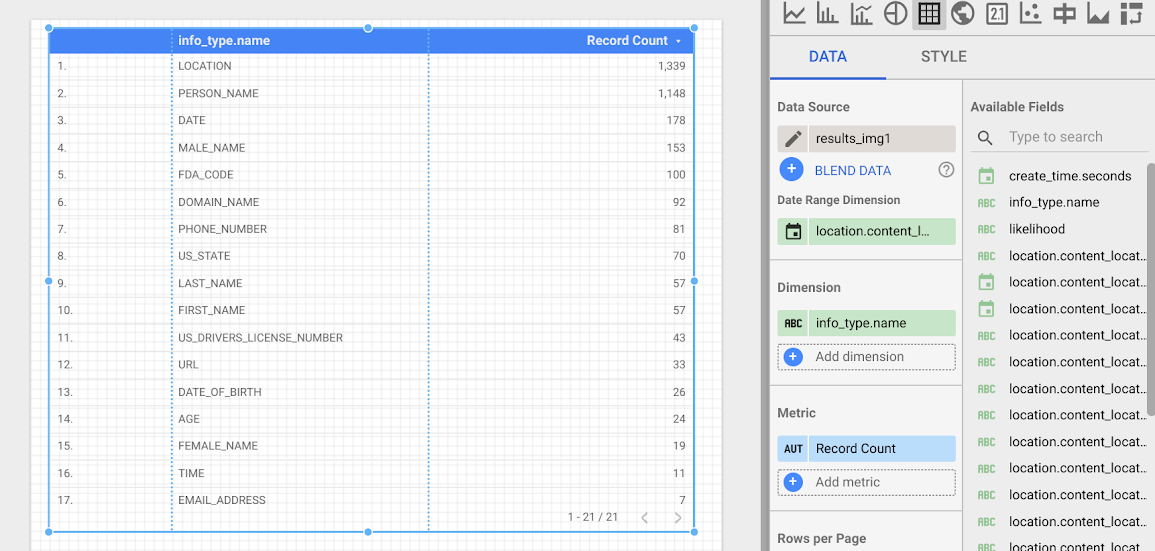
Passaggi successivi
Questo è solo l'inizio di ciò che puoi visualizzare utilizzando Data Studio e l'output di Sensitive Data Protection. Puoi aggiungere altri elementi grafici e filtri di drill-down per creare dashboard e report. Per ulteriori informazioni su ciò che è disponibile in Data Studio, consulta la panoramica del prodotto Data Studio.