
במסמך הזה מפורטת סקירה כללית של מינוי ל-BigQuery, של תהליך העבודה שלו ושל הנכסים שמשויכים אליו.
מינוי BigQuery הוא סוג של מינוי לייצוא שכותב הודעות לטבלת BigQuery קיימת כשהן מתקבלות. אין צורך להגדיר לקוח נפרד למנויים. כדי ליצור, לעדכן, להציג, לנתק או למחוק מינוי ל-BigQuery, אפשר להשתמש במסוף, ב-Google Cloud CLI, בספריות הלקוח או ב-Pub/Sub API. Google Cloud
אם אין לכם מינוי מסוג BigQuery, אתם צריכים מינוי מסוג pull או push ומנוי (למשל Dataflow) שקורא הודעות וכותב אותן לטבלה ב-BigQuery. לא צריך להפעיל משימת Dataflow אם ההודעות לא דורשות עיבוד נוסף לפני שמאחסנים אותן בטבלה ב-BigQuery. במקום זאת, אפשר להשתמש במינוי ל-BigQuery.
כדי לבצע שינויים קלים בהודעות, אפשר לצרף Single Message Transform למינוי BigQuery. עם זאת, מומלץ להשתמש בצינור (pipeline) של Dataflow במערכות Pub/Sub שבהן נדרשת טרנספורמציה מורכבת יותר של נתונים לפני שהנתונים מאוחסנים בטבלה ב-BigQuery, במיוחד אם רוצים להשתמש בחלונות או בצבירה של הודעות.
כדי ללמוד איך להזרים נתונים מ-Pub/Sub ל-BigQuery עם טרנספורמציה באמצעות Dataflow, אפשר לעיין במאמר בנושא הזרמה מ-Pub/Sub ל-BigQuery.
תבנית המינוי ל-Pub/Sub ל-BigQuery מ-Dataflow אוכפת כברירת מחדל מסירה של כל הודעה בדיוק פעם אחת. בדרך כלל עושים את זה באמצעות מנגנוני ביטול כפילויות בפייפליין של Dataflow. עם זאת, המינוי ל-BigQuery תומך רק בשליחה של הודעה אחת לפחות. אם ביטול כפילויות מדויק הוא קריטי לתרחיש השימוש שלכם, כדאי לשקול תהליכים במורד הזרם ב-BigQuery כדי לטפל בכפילויות פוטנציאליות.
לפני שמתחילים
לפני שקוראים את המסמך הזה, חשוב לוודא שמכירים את הנושאים הבאים:
איך Pub/Sub פועל ומהם המונחים השונים של Pub/Sub.
סוגי המינויים השונים שנתמכים ב-Pub/Sub והסיבות לשימוש במינוי ל-BigQuery.
איך BigQuery פועל ואיך מגדירים ומנהלים טבלאות BigQuery.
תהליך העבודה של מינוי ל-BigQuery
בתמונה הבאה מוצג תהליך העבודה בין מינוי ל-BigQuery לבין BigQuery.
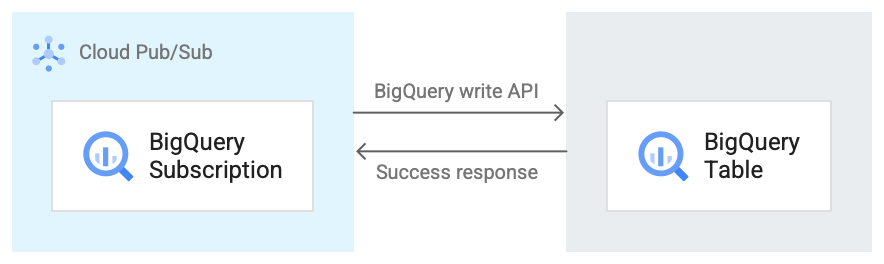
הנה תיאור קצר של תהליך העבודה שמופיע באיור 1:
- Pub/Sub משתמש ב-BigQuery Storage Write API כדי לשלוח נתונים לטבלה ב-BigQuery.
- ההודעות נשלחות בקבוצות לטבלה ב-BigQuery.
- אחרי השלמה מוצלחת של פעולת כתיבה, ה-API מחזיר תגובה מסוג OK.
- אם יש כשלים בפעולת הכתיבה, מתקבל אישור שלילי להודעת Pub/Sub עצמה. ההודעה נשלחת מחדש. אם שליחת ההודעה נכשלת מספיק פעמים ומוגדר נושא של הודעות שלא נמסרו במינוי, ההודעה מועברת לנושא של הודעות שלא נמסרו.
מאפיינים של מינוי ל-BigQuery
המאפיינים שאתם מגדירים למינוי BigQuery קובעים את הטבלה ב-BigQuery שאליה Pub/Sub כותב הודעות ואת סוג הסכימה של הטבלה הזו.
מידע נוסף זמין במאמר מאפיינים של BigQuery.
תאימות סכימה
הקטע הזה רלוונטי רק אם בוחרים באפשרות שימוש בסכימת נושא כשיוצרים מינוי ל-BigQuery.
ב-Pub/Sub וב-BigQuery משתמשים בשיטות שונות להגדרת הסכימות. סכימות של Pub/Sub מוגדרות בפורמט Apache Avro או Protocol Buffer, בעוד שסכימות של BigQuery מוגדרות באמצעות מגוון פורמטים.
בהמשך מופיעה רשימה של פרטים חשובים לגבי תאימות הסכימה בין נושא ב-Pub/Sub לבין טבלה ב-BigQuery.
הודעות שמכילות שדה בפורמט לא תקין לא נכתבות ב-BigQuery.
בסכימת BigQuery,
INT, SMALLINT, INTEGER,BIGINT, TINYINTו-BYTEINTהם כינויים ל-INTEGER, DECIMALהוא כינוי ל-NUMERICו-BIGDECIMALהוא כינוי ל-BIGNUMERIC.אם הסוג בסכימת הנושא הוא
stringוהסוג בטבלת BigQuery הואJSON,TIMESTAMP,DATETIME,DATE,TIME,NUMERICאוBIGNUMERIC, כל ערך בשדה הזה בהודעת Pub/Sub צריך להיות בפורמט שצוין עבור סוג הנתונים ב-BigQuery.יש תמיכה בחלק מהסוגים הלוגיים של Avro, כמו שמפורט בטבלה הבאה. סוגים לוגיים שלא מופיעים ברשימה תואמים רק לסוג Avro המקביל שהם מציינים, כפי שמפורט במפרט Avro.
בטבלה הבאה מפורט מיפוי של פורמטים שונים של סכימות לסוגי נתונים ב-BigQuery.
סוגי Avro
| סוג Avro | סוג הנתונים ב-BigQuery |
null |
Any NULLABLE |
boolean |
BOOLEAN |
int |
INTEGER, NUMERIC או BIGNUMERIC |
long |
INTEGER, NUMERIC או BIGNUMERIC |
float |
FLOAT64, NUMERIC או BIGNUMERIC |
double |
FLOAT64, NUMERIC או BIGNUMERIC |
bytes |
BYTES, NUMERIC או BIGNUMERIC |
string |
STRING, JSON,
TIMESTAMP, DATETIME,
DATE, TIME,
NUMERIC או BIGNUMERIC |
record |
RECORD/STRUCT |
array מתוך Type |
REPEATED Type |
map with value type ValueType
|
REPEATED STRUCT <key STRING, value
ValueType> |
union עם שני סוגים, אחד שהוא null והשני Type |
NULLABLE Type |
עוד union |
לא ניתן למיפוי |
fixed |
BYTES, NUMERIC או BIGNUMERIC |
enum |
INTEGER |
סוגים לוגיים של Avro
| סוג לוגי של Avro | סוג הנתונים ב-BigQuery |
timestamp-micros |
TIMESTAMP |
timestamp-millis |
TIMESTAMP |
date |
DATE |
time-micros |
TIME |
time-millis |
TIME |
duration |
INTERVAL |
decimal |
NUMERIC או BIGNUMERIC |
סוגים של מאגרי אחסון לפרוטוקולים
| סוג מאגר אחסון לפרוטוקולים | סוג הנתונים ב-BigQuery |
double |
FLOAT64, NUMERIC או BIGNUMERIC |
float |
FLOAT64, NUMERIC או BIGNUMERIC |
int32 |
INTEGER, NUMERIC,
BIGNUMERIC או DATE |
int64 |
INTEGER, NUMERIC,
BIGNUMERIC, DATE,
DATETIME או TIMESTAMP |
uint32 |
INTEGER, NUMERIC,
BIGNUMERIC או DATE |
uint64 |
NUMERIC או BIGNUMERIC |
sint32 |
INTEGER, NUMERIC או BIGNUMERIC |
sint64 |
INTEGER, NUMERIC,
BIGNUMERIC, DATE,
DATETIME או TIMESTAMP |
fixed32 |
INTEGER, NUMERIC,
BIGNUMERIC או DATE |
fixed64 |
NUMERIC או BIGNUMERIC |
sfixed32 |
INTEGER, NUMERIC,
BIGNUMERIC או DATE |
sfixed64 |
INTEGER, NUMERIC,
BIGNUMERIC, DATE,
DATETIME או TIMESTAMP |
bool |
BOOLEAN |
string |
STRING, JSON,
TIMESTAMP, DATETIME,
DATE, TIME,
NUMERIC או BIGNUMERIC |
bytes |
BYTES, NUMERIC או BIGNUMERIC |
enum |
INTEGER |
message |
RECORD/STRUCT |
oneof |
לא ניתן למיפוי |
map<KeyType, ValueType> |
REPEATED RECORD<key KeyType, value
ValueType> |
enum |
INTEGER |
repeated/array of Type |
REPEATED Type |
ייצוג של תאריך ושעה כמספר שלם
כשממפים ממספר שלם לאחד מסוגי התאריך או השעה, המספר צריך לייצג את הערך הנכון. בטבלה הבאה מפורט המיפוי מסוגי נתונים ב-BigQuery למספר השלם שמייצג אותם.
| סוג הנתונים ב-BigQuery | ייצוג של מספר שלם |
DATE |
מספר הימים מאז ראשית זמן יוניקס, 1 בינואר 1970 |
DATETIME |
התאריך והשעה במיקרו-שניות, שמוצגים כזמן אזרחי באמצעות CivilTimeEncoder |
TIME |
הזמן במיקרו-שניות, שמוצג כזמן אזרחי באמצעות CivilTimeEncoder |
TIMESTAMP |
מספר המיקרו-שניות מאז ראשית זמן יוניקס, 1 בינואר 1970, 00:00:00 UTC |
הטמעה של סימון נתונים שהשתנו (CDC) ב-BigQuery
מינויים ל-BigQuery תומכים בעדכוני הטמעה של לכידת נתונים משתנים (CDC) כשuse_topic_schema או use_table_schema מוגדרים לערך true במאפייני המינוי. כדי להשתמש בתכונה עם use_topic_schema, צריך להגדיר את הסכימה של הנושא עם השדות הבאים:
_CHANGE_TYPE(חובה): שדהstringשמוגדר ל-UPSERTאו ל-DELETE.אם ההגדרה של
_CHANGE_TYPEבהודעת Pub/Sub שנכתבת לטבלה ב-BigQuery היאUPSERT, BigQuery מעדכן את השורה עם אותו מפתח אם היא קיימת, או מוסיף שורה חדשה אם היא לא קיימת.אם הודעת Pub/Sub שנכתבה לטבלה ב-BigQuery כוללת
_CHANGE_TYPEשמוגדר ל-DELETE, BigQuery מוחק את השורה בטבלה עם אותו מפתח, אם היא קיימת.
_CHANGE_SEQUENCE_NUMBER(אופציונלי): שדהstringשמוגדר כדי לוודא שעדכונים ומחיקות שבוצעו בטבלה ב-BigQuery יעובדו לפי הסדר. ההודעות לאותו מפתח שורה צריכות להכיל ערך_CHANGE_SEQUENCE_NUMBERשעולה באופן מונוטוני. להודעות עם מספרי רצף שקטנים ממספר הרצף הכי גבוה שעובד בשורה, אין השפעה על השורה בטבלה ב-BigQuery. מספר הרצף צריך להיות בפורמט_CHANGE_SEQUENCE_NUMBER.
כדי להשתמש בתכונה עם use_table_schema, צריך לכלול את השדות הקודמים בהודעת ה-JSON.
מידע על תמחור זמין במאמר בנושא תמחור של הטמעת CDC ב-BigQuery.
טבלאות BigLake ל-Apache Iceberg ב-BigQuery
אפשר להשתמש במינויים ל-BigQuery עם טבלאות BigLake ל-Apache Iceberg ב-BigQuery בלי לבצע שינויים נוספים.
טבלאות BigLake ל-Apache Iceberg ב-BigQuery מספקות את הבסיס לבניית אגמי נתונים בפורמט פתוח ב- Google Cloud. הטבלאות האלה מציעות את אותה חוויה מנוהלת מלאה כמו טבלאות BigQuery רגילות (מובנות), אבל הנתונים מאוחסנים בדלי אחסון בבעלות הלקוח בפורמט Parquet, כדי לאפשר פעולה הדדית עם פורמטים פתוחים של טבלאות Iceberg.
במאמר יצירת טבלת Iceberg מוסבר איך ליצור טבלאות BigLake עבור Apache Iceberg ב-BigQuery.
טיפול בכשלים בשליחת הודעות
כשאי אפשר לכתוב הודעת Pub/Sub ל-BigQuery, אי אפשר לאשר את ההודעה. כדי להעביר הודעות כאלה שלא ניתן למסור, צריך להגדיר נושא להודעות ללא מוצא במינוי ל-BigQuery. הודעת Pub/Sub שמועברת לנושא להודעות ללא מוצא מכילה מאפיין CloudPubSubDeadLetterSourceDeliveryErrorMessage עם הסיבה לכך שלא ניתן היה לכתוב את הודעת Pub/Sub ל-BigQuery.
אם מערכת Pub/Sub לא מצליחה לכתוב הודעות ל-BigQuery, היא מפסיקה את מסירת ההודעות באופן דומה להתנהגות של נסיגה בדחיפה. עם זאת, אם מחובר למינוי נושא של הודעות שלא נמסרו, מערכת Pub/Sub לא מפסיקה את המסירה כשיש שגיאות בהודעות בגלל בעיות תאימות לסכימה.
מכסות ומגבלות
יש מגבלות על המכסות של קצב העברת הנתונים של מנויי BigQuery לכל אזור. מידע נוסף זמין במאמר מכסות ומגבלות של Pub/Sub.
מינויים ל-BigQuery כותבים נתונים באמצעות BigQuery Storage Write API. מידע על המכסות והמגבלות של Storage Write API זמין במאמר בנושא בקשות של Storage Write API. מינויים ל-BigQuery צורכים רק את מכסת התפוקה של Storage Write API. במקרה הזה, אפשר להתעלם משיקולים אחרים לגבי מכסות של Storage Write API.
תמחור
בדף התמחור של Pub/Sub מפורטים המחירים של מינויים ל-BigQuery.
המאמרים הבאים
יוצרים מינוי, כמו מינוי ל-BigQuery.
פתרון בעיות במינוי ל-BigQuery
מידע נוסף על BigQuery
כדאי לעיין בתמחור של Pub/Sub, כולל מינויים ל-BigQuery.
ליצור או לשנות מינוי באמצעות פקודות של
gcloudCLI.יצירה או שינוי של מינוי באמצעות ממשקי REST API.