
כברירת מחדל, סוכן התפעול וסוכן Monitoring מדור קודם מוגדרים לאיסוף מדדים שכוללים מידע על התהליכים שפועלים במכונות וירטואליות (VM) של Compute Engine. אפשר גם לאסוף את המדדים האלה במכונות וירטואליות של Amazon Elastic Compute Cloud (EC2) באמצעות סוכן Monitoring.
קבוצת המדדים הזו, שנקראת מדדי תהליך, מזוהה על ידי התחילית agent.googleapis.com/processes. המדדים האלה לא נאספים ב-Google Kubernetes Engine (GKE).
החל מ-6 באוגוסט 2021, יחולו חיובים על המדדים האלה, כפי שמתואר בקטע 'מדדים שחלים עליהם חיובים' בדף תמחור של Google Cloud Observability. קבוצת מדדי התהליך מסווגת כקבוצה שניתן לחייב עליה, אבל אף פעם לא בוצעו חיובים.
במאמר הזה מתוארים כלים להצגת מדדים של תהליכים, מוסבר איך לקבוע את כמות הנתונים שאתם מכניסים למערכת מהמדדים האלה ואיך לצמצם את העלויות שקשורות לכך.
עבודה עם מדדי תהליך
אתם יכולים להמחיש את נתוני המדדים של התהליך באמצעות תרשימים שנוצרו באמצעות Metrics Explorer או לוחות בקרה בהתאמה אישית. מידע נוסף זמין במאמר שימוש במרכזי בקרה ובתרשימים. בנוסף, Cloud Monitoring כולל נתונים ממדדי תהליכים בשתי לוחות בקרה מוגדרים מראש:
- לוח הבקרה VM Instances ב-Monitoring
- לוח הבקרה Details של מכונה וירטואלית ב-Compute Engine
בקטעים הבאים מתוארים מרכזי הבקרה האלה.
מעקב: הצגת מדדים מצטברים של תהליכים
כדי לראות מדדים מצטברים של תהליכים בהיקף של מדדים, עוברים לכרטיסייה Processes בלוח הבקרה VM Instances:
-
במסוף Google Cloud , עוברים לדף Dashboards:
אם משתמשים בסרגל החיפוש כדי למצוא את הדף הזה, בוחרים בתוצאה שבה הכותרת המשנית היא Monitoring.
בוחרים את לוח הבקרה VM Instances (מכונות וירטואליות) מהרשימה.
לוחצים על תהליכים.
בצילום המסך הבא אפשר לראות דוגמה לדף Processes (תהליכים) בקטע Monitoring (מעקב):
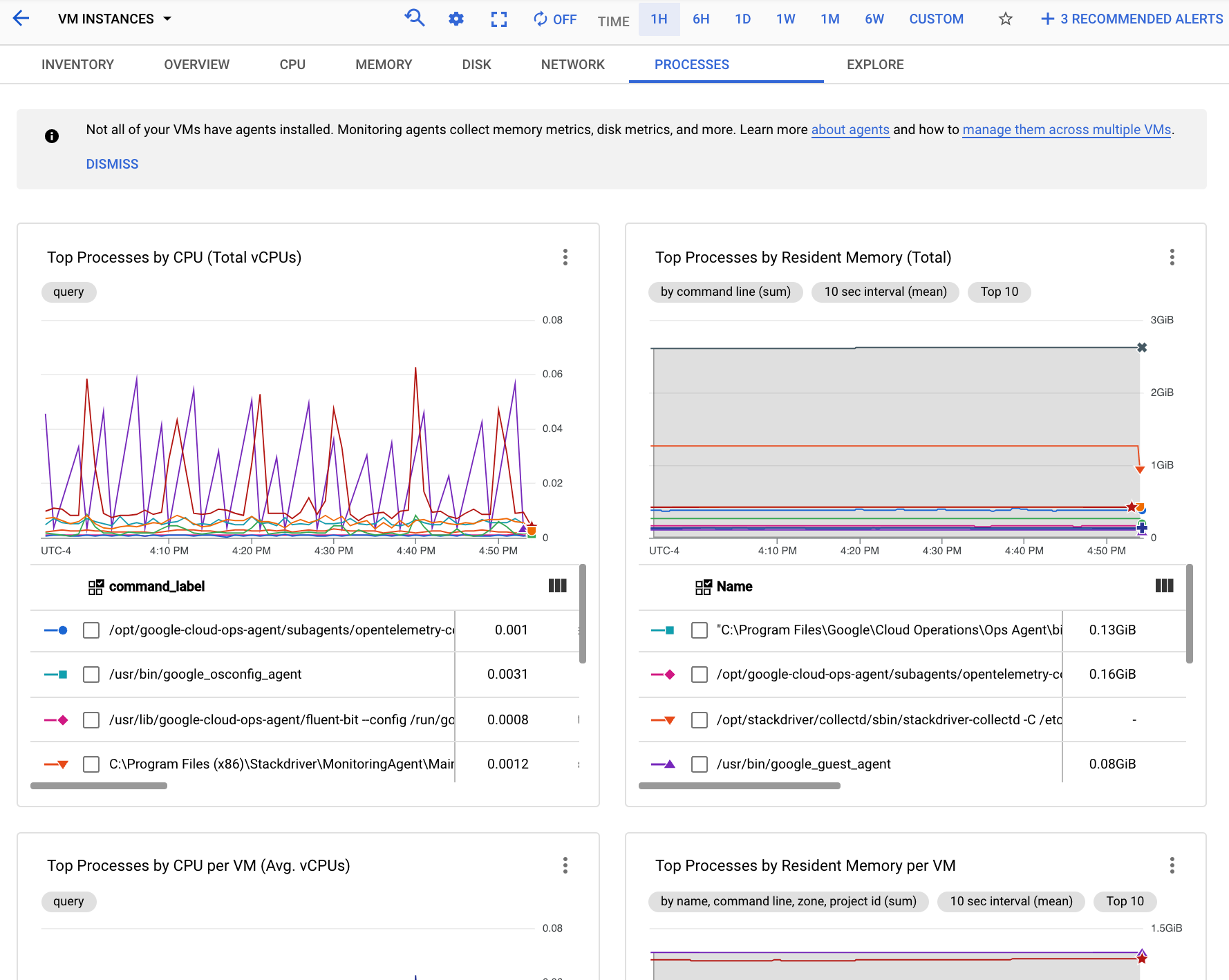
אתם יכולים להשתמש בתרשימים שבכרטיסייה Processes כדי לזהות את התהליכים בהיקף המדדים שצורכים הכי הרבה CPU וזיכרון, ושמנצלים הכי הרבה מקום בדיסק.
Compute Engine: הצגת מדדי ביצועים של מכונות וירטואליות שצורכות הכי הרבה משאבים
כדי לראות את תרשימי הביצועים שמציגים את 5 המכונות הווירטואליות שצורכות הכי הרבה משאבים בפרויקט Google Cloud , עוברים לכרטיסייה Observability של מופעי המכונות הווירטואליות:
-
נכנסים לדף VM instances במסוף Google Cloud :
אם משתמשים בסרגל החיפוש כדי למצוא את הדף הזה, בוחרים את התוצאה שבה כותרת המשנה היא Compute Engine.
- לוחצים על יכולת צפייה.
בצילום המסך הבא מוצגת דוגמה לדף Observability ב-Compute Engine.
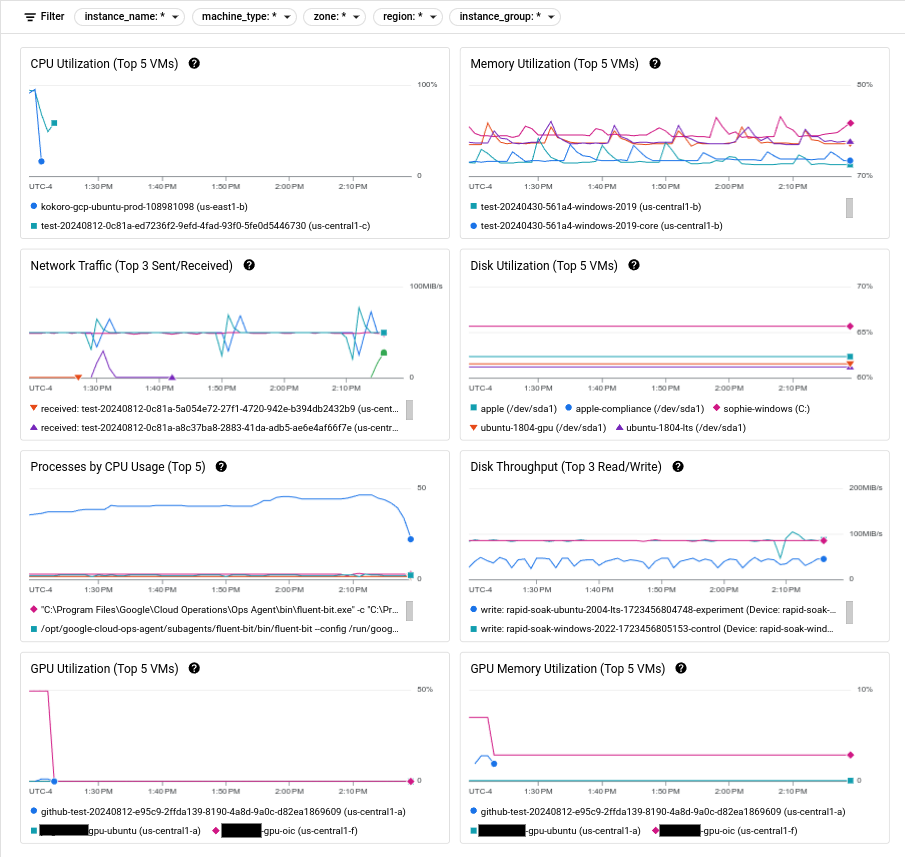
מידע על שימוש במדדים האלה כדי לאבחן בעיות במכונות הווירטואליות זמין במאמר פתרון בעיות בביצועים של מכונות וירטואליות.
Compute Engine: הצגת מדדי תהליכים לכל מכונה וירטואלית
כדי לראות רשימה של התהליכים שפועלים במכונה וירטואלית (VM) אחת של Compute Engine וטבלאות של התהליכים עם צריכת המשאבים הכי גבוהה, עוברים לכרטיסייה Observability של המכונה הווירטואלית:
-
נכנסים לדף VM instances במסוף Google Cloud :
אם משתמשים בסרגל החיפוש כדי למצוא את הדף הזה, בוחרים את התוצאה שבה כותרת המשנה היא Compute Engine.
בכרטיסייה Instances (מכונות), לוחצים על שם המכונה הווירטואלית שרוצים לבדוק.
לוחצים על Observability כדי לראות את המדדים של המכונה הווירטואלית הזו.
בחלונית הניווט בכרטיסייה Observability, בוחרים באפשרות Processes.
בצילום המסך הבא מוצגת דוגמה לדף Processes ב-Compute Engine:
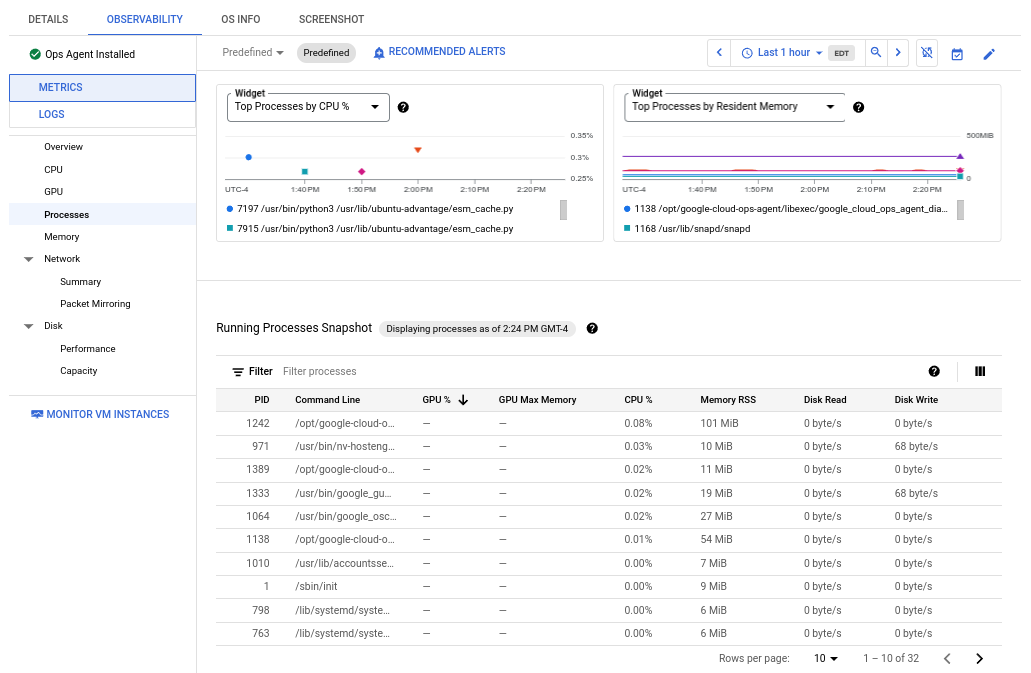
מדדי התהליך נשמרים עד 24 חודשים, כך שאפשר להשתמש בהם כדי לבדוק נתונים היסטוריים ולשייך אנומליות בצריכת המשאבים לתהליכים ספציפיים, או כדי לזהות את התהליכים שצורכים הכי הרבה משאבים. לדוגמה, בתרשים הבא מוצגים התהליכים שצורכים את האחוזים הכי גבוהים של משאבי המעבד. אפשר להשתמש בבורר טווח הזמן כדי לשנות את טווח הזמן של התרשים. בורר טווח התאריכים מציע ערכים מוגדרים מראש, כמו השעה האחרונה, ומאפשר גם להזין טווח תאריכים מותאם אישית.
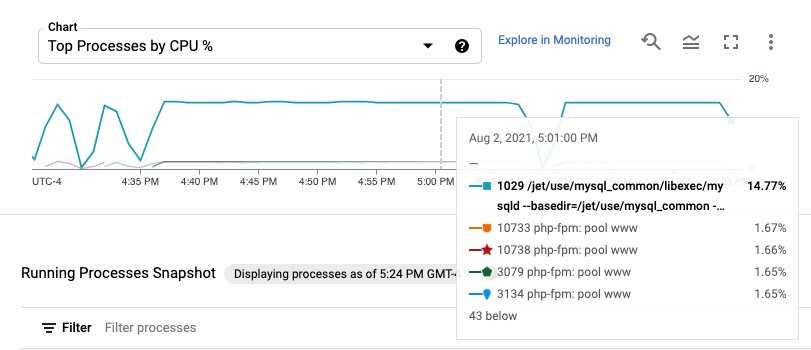
בטבלה Running Processes מופיעה רשימה של צריכת משאבים, בדומה לפלט של הפקודה top ב-Linux.
כברירת מחדל, בטבלה מוצגת תמונת מצב של הנתונים העדכניים ביותר.
עם זאת, אם בוחרים טווח זמן בתרשים שמסתיים בעבר, הטבלה מציגה את התהליכים שפעלו בסוף הטווח הזה.
מידע על שימוש במדדים האלה כדי לאבחן בעיות במכונות הווירטואליות זמין במאמר פתרון בעיות בביצועים של מכונות וירטואליות.
מדדי תהליך שנאספים על ידי הסוכן
הסוכנים של Linux אוספים את כל המדדים שמפורטים בטבלה הבאה מתהליכים שפועלים במכונות וירטואליות של Compute Engine, ובאמצעות סוכן Monitoring, במכונות וירטואליות של Amazon Elastic Compute Cloud (EC2). אפשר להשבית את האיסוף שלהם באמצעות סוכן תפעול (גרסה 2.0.0 ואילך) ובאמצעות סוכן המעקב מדור קודם.
אפשר גם להשבית את איסוף מדדי התהליך עבור סוכן תפעול (גרסה 2.0.0 ואילך) שפועל במכונות וירטואליות של Windows.
מידע נוסף זמין במאמר בנושא השבתת מדדי תהליך.
אם רוצים להשבית את איסוף המדדים האלה ב-Windows, מומלץ לשדרג לגרסה 2.0.0 של סוכן תפעול או לגרסה מתקדמת יותר. מידע נוסף מופיע במאמר בנושא התקנת סוכן תפעול.
טבלה של מדדי תהליכים
לפני המחרוזות של 'סוג המדד' בטבלה הזו צריך להוסיף את הקידומת agent.googleapis.com/processes/. הקידומת הזו הושמטה מהערכים בטבלה.
כשמבצעים שאילתה על תווית, משתמשים בקידומת metric.labels.. לדוגמה, metric.labels.LABEL="VALUE".
| סוג המדד שלב ההשקה (רמות בהיררכיית המשאבים) שם לתצוגה |
|
|---|---|
| סוג, יחידה משאבים במעקב |
תיאור תוויות |
count_by_state
GA
(project)
Processes |
|
GAUGE, DOUBLE, 1
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
מספר התהליכים במצב הנתון. ב-Linux בלבד. נדגמים כל 60 שניות.
state:
ריצה, שינה, זומבי וכו'.
|
cpu_time
GA
(project)
Process CPU |
|
CUMULATIVE, INT64, us{CPU}
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
זמן ה-CPU של התהליך הנתון. נדגמים כל 60 שניות.
process:
שם התהליך.
user_or_syst:
אם מדובר במשתמש או בתהליך מערכת.
command:
פקודת עיבוד.
command_line:
פקודה לעיבוד בשורת הפקודה, 1,024 תווים לכל היותר.
owner:
הבעלים של התהליך.
pid:
מזהה התהליך.
|
disk/read_bytes_count
GA
(project)
Process disk read I/O |
|
CUMULATIVE, INT64, By
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
עיבוד קלט/פלט של קריאת דיסק. ב-Linux בלבד. נדגמים כל 60 שניות.
process:
שם התהליך.
command:
פקודת עיבוד.
command_line:
פקודה לעיבוד בשורת הפקודה, 1,024 תווים לכל היותר.
owner:
הבעלים של התהליך.
pid:
מזהה התהליך.
|
disk/write_bytes_count
GA
(project)
Process disk write I/O |
|
CUMULATIVE, INT64, By
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
עיבוד קלט/פלט של כתיבה בדיסק. ב-Linux בלבד. נדגמים כל 60 שניות.
process:
שם התהליך.
command:
פקודת עיבוד.
command_line:
פקודה לעיבוד בשורת הפקודה, 1,024 תווים לכל היותר.
owner:
הבעלים של התהליך.
pid:
מזהה התהליך.
|
fork_count
GA
(project)
Fork count |
|
CUMULATIVE, INT64, 1
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
המספר הכולל של תהליכים שהתפצלו. ב-Linux בלבד. נדגמים כל 60 שניות. |
rss_usage
GA
(project)
Process resident memory |
|
GAUGE, DOUBLE, By
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
השימוש בזיכרון של התהליך הנתון. ב-Linux בלבד. נדגמים כל 60 שניות.
process:
שם התהליך.
command:
פקודת עיבוד.
command_line:
פקודה לעיבוד בשורת הפקודה, 1,024 תווים לכל היותר.
owner:
הבעלים של התהליך.
pid:
מזהה התהליך.
|
vm_usage
GA
(project)
Process virtual memory |
|
GAUGE, DOUBLE, By
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
השימוש במכונה הווירטואלית בתהליך הנתון. נדגמים כל 60 שניות.
process:
שם התהליך.
command:
פקודת עיבוד.
command_line:
פקודה לעיבוד בשורת הפקודה, 1,024 תווים לכל היותר.
owner:
הבעלים של התהליך.
pid:
מזהה התהליך.
|
windows/handles
אלפא
(פרויקט)
תהליך פתיחת ידיות (Windows) |
|
GAUGE, INT64, 1
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
מספר ה-handle הפתוחים של התהליך הנתון. Windows בלבד. נדגמים כל 60 שניות.
process:
שם התהליך.
command:
פקודת עיבוד.
command_line:
פקודה לעיבוד בשורת הפקודה, 1,024 תווים לכל היותר.
owner:
הבעלים של התהליך.
pid:
מזהה התהליך.
|
הטבלה נוצרה בתאריך 2026-06-24 בשעה 20:26:54 לפי שעון UTC.
קביעת ההטמעה הנוכחית
אתם יכולים להשתמש ב-Metrics Explorer כדי לראות כמה נתונים אתם מכניסים למערכת עבור מדדי תהליך. פועלים לפי השלבים הבאים:
-
נכנסים לדף leaderboard Metrics explorer במסוף Google Cloud :
אם משתמשים בסרגל החיפוש כדי למצוא את הדף הזה, בוחרים בתוצאה שבה הכותרת המשנית היא Monitoring.
בסרגל הכלים של החלונית ליצירת שאילתות, לוחצים על הלחצן ששמו code PromQL.
כדי לראות את המספר הכולל של נקודות המדדים של התהליך עבור משאבי
gce_instanceו-aws_ec2_instance:מזינים את השאילתה הבאה:
sum_over_time( sum by (resource_type) ( label_replace( label_replace( sum(count_over_time({"agent.googleapis.com/processes/cpu_time", monitored_resource="gce_instance"}[1m])), "metric_suffix", "cpu_time", "", "" ) or label_replace( sum(count_over_time({"agent.googleapis.com/processes/disk/read_bytes_count", monitored_resource="gce_instance"}[1m])), "metric_suffix", "disk_read_bytes_count", "", "" ) or label_replace( sum(count_over_time({"agent.googleapis.com/processes/disk/write_bytes_count", monitored_resource="gce_instance"}[1m])), "metric_suffix", "disk_write_bytes_count", "", "" ) or label_replace( sum(count_over_time({"agent.googleapis.com/processes/rss_usage", monitored_resource="gce_instance"}[1m])), "metric_suffix", "rss_usage", "", "" ) or label_replace( sum(count_over_time({"agent.googleapis.com/processes/vm_usage", monitored_resource="gce_instance"}[1m])), "metric_suffix", "vm_usage", "", "" ) or label_replace( sum(count_over_time({"agent.googleapis.com/processes/count_by_state", monitored_resource="gce_instance"}[1m])), "metric_suffix", "count_by_state", "", "" ) or label_replace( sum(count_over_time({"agent.googleapis.com/processes/fork_count", monitored_resource="gce_instance"}[1m])), "metric_suffix", "fork_count", "", "" ), "resource_type", "gce_instance", "", "" ) or label_replace( label_replace( sum(count_over_time({"agent.googleapis.com/processes/cpu_time", monitored_resource="aws_ec2_instance"}[1m])), "metric_suffix", "cpu_time", "", "" ) or label_replace( sum(count_over_time({"agent.googleapis.com/processes/disk/read_bytes_count", monitored_resource="aws_ec2_instance"}[1m])), "metric_suffix", "disk_read_bytes_count", "", "" ) or label_replace( sum(count_over_time({"agent.googleapis.com/processes/disk/write_bytes_count", monitored_resource="aws_ec2_instance"}[1m])), "metric_suffix", "disk_write_bytes_count", "", "" ) or label_replace( sum(count_over_time({"agent.googleapis.com/processes/rss_usage", monitored_resource="aws_ec2_instance"}[1m])), "metric_suffix", "rss_usage", "", "" ) or label_replace( sum(count_over_time({"agent.googleapis.com/processes/vm_usage", monitored_resource="aws_ec2_instance"}[1m])), "metric_suffix", "vm_usage", "", "" ) or label_replace( sum(count_over_time({"agent.googleapis.com/processes/count_by_state", monitored_resource="aws_ec2_instance"}[1m])), "metric_suffix", "count_by_state", "", "" ) or label_replace( sum(count_over_time({"agent.googleapis.com/processes/fork_count", monitored_resource="aws_ec2_instance"}[1m])), "metric_suffix", "fork_count", "", "" ), "resource_type", "aws_ec2_instance", "", "" ) )[1d:] )לוחצים על Run Query (הפעלת שאילתה). בתרשים שמתקבל מוצגים הערכים של כל סוג משאב.
הערכת העלות של המדדים
בדוגמאות התמחור של Monitoring אפשר לראות איך אפשר להעריך את העלות של הטמעת מדדים. אפשר להשתמש בדוגמאות האלה כדי לעבד מדדים.
כל מדדי התהליך נדגמים כל 60 שניות, וכולם כותבים נקודות נתונים שנספרות כשמונה בייטים למטרות תמחור.
התמחור של מדדי התהליך מוגדר כ-5% מהעלות הסטנדרטית של נפח השימוש שמופיעה בדוגמאות לתמחור. לכן, אם מניחים שכל המדדים בתרחישים שמתוארים בדוגמאות האלה הם מדדים של תהליכים, אפשר להשתמש ב-5% מהעלות הכוללת של כל תרחיש כהערכה של העלות של מדדים של תהליכים.
השבתת האיסוף של מדדי תהליכים
יש כמה דרכים להשבית את איסוף המדדים האלה על ידי סוכן תפעול (גרסה 2.0.0 ואילך) ועל ידי סוכן המעקב מדור קודם ב-Linux.
הסוכנים פועלים רק במכונות וירטואליות של Compute Engine, והנהלים האלה חלים רק על הפלטפורמה הזו.
אי אפשר להשבית את האיסוף באמצעות Ops Agent אם אתם מריצים גרסאות שקטנות מ-2.0.0 או את סוכן המעקב מדור קודם ב-Windows. אם רוצים להשבית את איסוף המדדים האלה ב-Windows, מומלץ לשדרג לגרסה 2.0.0 של סוכן תפעול או לגרסה מתקדמת יותר. מידע נוסף מופיע במאמר בנושא התקנת סוכן תפעול.
התהליך הכללי נראה כך:
מתחברים ל-VM.
יוצרים עותק של קובץ התצורה הקיים כגיבוי. מאחסנים את עותק הגיבוי מחוץ לספריית ההגדרות של הסוכן, כדי שהסוכן לא ינסה לטעון את שני הקבצים. לדוגמה, הפקודה הבאה יוצרת עותק של קובץ התצורה של סוכן המעקב ב-Linux:
cp /etc/stackdriver/collectd.conf BACKUP_DIR/collectd.conf.bak
משנים את ההגדרה באמצעות אחת מהאפשרויות שמתוארות במאמרים הבאים:
מפעילים מחדש את הסוכן כדי להחיל את ההגדרה החדשה:
- סוכן מעקב:
sudo service stackdriver-agent restart - סוכן תפעול:
sudo service google-cloud-ops-agent restart
- סוכן מעקב:
מוודאים שהמדדים של התהליך לא נאספים יותר עבור המכונה הווירטואלית הזו:
-
נכנסים לדף leaderboard Metrics explorer במסוף Google Cloud :
אם משתמשים בסרגל החיפוש כדי למצוא את הדף הזה, בוחרים בתוצאה שבה הכותרת המשנית היא Monitoring.
בסרגל הכלים של החלונית ליצירת שאילתות, לוחצים על הלחצן ששמו code PromQL.
כדי להריץ שאילתה על משאב
gce_instance, מזינים את השאילתה הבאה ומחליפים את VM_NAME בשם של המכונה הווירטואלית:rate({"agent.googleapis.com/processes/cpu_time", monitored_resource="gce_instance", metadata_system_name="VM_NAME"}[1m])לוחצים על Run Query (הפעלת שאילתה).
-
סוכן תפעול ב-Linux או ב-Windows
המיקום של קובץ התצורה של סוכן תפעול תלוי במערכת ההפעלה:
- ב-Linux:
/etc/google-cloud-ops-agent/config.yaml - ב-Windows:
C:\Program Files\Google\Cloud Operations\Ops Agent\config\config.yaml
כדי להשבית את איסוף כל מדדי התהליך על ידי סוכן תפעול, מוסיפים את השורות הבאות לקובץ config.yaml:
metrics:
processors:
metrics_filter:
type: exclude_metrics
metrics_pattern:
- agent.googleapis.com/processes/*
המדדים האלה לא נכללים באוסף המדדים של התהליך בmetrics_filter
מעבד שחל על צינור ברירת המחדל בשירות metrics.
מידע נוסף על אפשרויות ההגדרה של סוכן תפעול זמין במאמר הגדרת סוכן תפעול.
סוכן מעקב ב-Linux
יש לכם את האפשרויות הבאות להשבתת האיסוף של מדדי תהליכים באמצעות סוכן המעקב מדור קודם:
בקטעים הבאים מתוארת כל אפשרות ומפורטים היתרונות והסיכונים שקשורים אליה.
שינוי קובץ ההגדרות של הסוכן
באפשרות הזו, אתם עורכים ישירות את קובץ ההגדרות הראשי של הסוכן, /etc/stackdriver/collectd.conf, כדי להסיר את הקטעים שמאפשרים את איסוף מדדי התהליך.
התהליך
יש שלושה סוגי מחיקות שצריך לבצע בקובץ collectd.conf:
צריך למחוק את ההנחיה
LoadPluginואת הגדרות הפלאגין הבאות:LoadPlugin processes <Plugin "processes"> ProcessMatch "all" ".*" Detail "ps_cputime" Detail "ps_disk_octets" Detail "ps_rss" Detail "ps_vm" </Plugin>צריך למחוק את ההנחיה
PostCacheChainואת ההגדרה של שרשרתPostCache:PostCacheChain "PostCache" <Chain "PostCache"> <Rule "processes"> <Match "regex"> Plugin "^processes$" Type "^(ps_cputime|disk_octets|ps_rss|ps_vm)$" </Match> <Target "jump"> Chain "MaybeThrottleProcesses" </Target> Target "stop" </Rule> <Rule "otherwise"> <Match "throttle_metadata_keys"> OKToThrottle false HighWaterMark 5700000000 # 950M * 6 LowWaterMark 4800000000 # 800M * 6 </Match> <Target "write"> Plugin "write_gcm" </Target> </Rule> </Chain>מוחקים את שרשרת
MaybeThrottleProcessesשמשמשת את שרשרתPostCache:<Chain "MaybeThrottleProcesses"> <Rule "default"> <Match "throttle_metadata_keys"> OKToThrottle true TrackedMetadata "processes:pid" TrackedMetadata "processes:command" TrackedMetadata "processes:command_line" TrackedMetadata "processes:owner" </Match> <Target "write"> Plugin "write_gcm" </Target> </Rule> </Chain>
יתרונות וסיכונים
- הטבות
- המשאבים שהסוכן צורך יצטמצמו, כי המדדים לא נאספים אף פעם.
- אם ביצעתם שינויים אחרים בקובץ
collectd.conf, יכול להיות שתוכלו לשמור אותם בקלות.
- סיכונים
- כדי לערוך את קובץ ההגדרות הזה, צריך להשתמש בחשבון
root. - יש סיכון להוספת שגיאות הקלדה לקובץ.
- כדי לערוך את קובץ ההגדרות הזה, צריך להשתמש בחשבון
החלפת קובץ ההגדרות של הסוכן
באמצעות האפשרות הזו, קובץ ההגדרות הראשי של הסוכן מוחלף בגרסה שעברה עריכה מראש, שבה הוסרו הקטעים הרלוונטיים.
התהליך
מורידים את הקובץ
collectd-no-process-metrics.confשכבר נערך מראש ממאגר GitHub לספרייה/tmp, ואז מבצעים את הפעולות הבאות:cd /tmp && curl -sSO https://raw.githubusercontent.com/Stackdriver/agent-packaging/master/collectd-no-process-metrics.confמחליפים את הקובץ הקיים
collectd.confבקובץ שעבר עריכה מראש:cp /tmp/collectd-no-process-metrics.conf /etc/stackdriver/collectd.conf
יתרונות וסיכונים
- הטבות
- הסוכן צורך פחות משאבים כי המדדים אף פעם לא נאספים.
- לא צריך לערוך את הקובץ באופן ידני כמו
root. - אפשר להשתמש בקלות בכלים לניהול תצורה כדי להחליף קובץ.
- סיכונים
- אם ביצעתם שינויים אחרים בקובץ
collectd.conf, תצטרכו למזג את השינויים האלה עם הקובץ החדש.
- אם ביצעתם שינויים אחרים בקובץ
פתרון בעיות
הפעולות שמתוארות במאמר הזה הן שינויים בהגדרות של הסוכן, ולכן הבעיות הבאות הן הסבירות ביותר:
- אין הרשאה מספקת לערוך את קובצי ההגדרות. צריך לערוך את קובצי ההגדרה מחשבון
root. - הוספה של שגיאות הקלדה לקובץ ההגדרות, אם עורכים אותו ישירות.
מידע על פתרון בעיות אחרות זמין במאמר פתרון בעיות בסוכן המעקב.
סוכן מעקב ב-Windows
אי אפשר להשבית את איסוף מדדי התהליך על ידי סוכן Monitoring מדור קודם שפועל במכונות וירטואליות של Windows. אי אפשר להגדיר את הסוכן הזה. אם רוצים להשבית את איסוף המדדים האלה ב-Windows, מומלץ לשדרג לגרסה 2.0.0 של סוכן תפעול או לגרסה מתקדמת יותר. מידע נוסף מופיע במאמר בנושא התקנת סוכן תפעול.
אם אתם מריצים את Ops Agent, כדאי לעיין במאמר בנושא Ops Agent ב-Linux או ב-Windows.