
Il registro degli schemi fornisce repository di schemi condivisi da più applicazioni. In precedenza, senza un registro degli schemi, i team potevano dipendere da accordi informali, come intese verbali, documenti condivisi non applicati a livello di programmazione o pagine wiki, per definire il formato dei messaggi e come serializzare e deserializzare i messaggi. Il registro di schemi garantisce la codifica e la decodifica coerenti dei messaggi.
Questo documento fornisce una panoramica della funzionalità del registro di schema per Managed Service per Apache Kafka, dei suoi componenti e del flusso di lavoro di base.
Informazioni sugli schemi
Immagina di creare un'applicazione che monitora gli ordini dei clienti. Potresti
utilizzare un argomento Kafka chiamato customer_orders per trasmettere messaggi contenenti
informazioni su ogni ordine. Un tipico messaggio di ordine potrebbe includere i seguenti campi di informazioni:
ID ordine
Nome cliente
Nome del prodotto
Quantità
Prezzo
Per garantire che questi messaggi siano strutturati in modo coerente, puoi definire uno schema. Ecco un esempio in formato Apache Avro:
{
"type": "record",
"name": "Order",
"namespace": "com.example",
"fields": [
{"name": "orderId", "type": "string"},
{"name": "customerName", "type": "string"},
{"name": "productName", "type": "string"},
{"name": "quantity", "type": "int"},
{"name": "price", "type": "double"}
]
}
Ecco lo stesso esempio in formato Protocol Buffer.
syntax = "proto3";
package com.example;
option java_multiple_files = true; // Optional: Recommended for Java users
option java_package = "com.example"; // Optional: Explicit Java package
message Order {
string orderId = 1;
string customerName = 2;
string productName = 3;
int32 quantity = 4; // Avro int maps to Protobuf int32
double price = 5;
}
Questo schema è un progetto per un messaggio. Indica che un messaggio
order ha cinque campi: un ID ordine, un nome cliente, un nome prodotto, una
quantità e un prezzo. Specifica anche il tipo di dati di ogni campo.
Se un client consumer riceve un messaggio binario codificato con questo schema, deve sapere esattamente come interpretarlo. Per renderlo possibile, il producer
memorizza lo schema order in un registro di schemi e trasmette un identificatore dello
schema insieme al messaggio. Se un consumer del messaggio sa quale
registro è stato utilizzato, può recuperare lo stesso schema e decodificare il messaggio.
Supponiamo che tu voglia aggiungere un campo, orderDate, ai tuoi messaggi order. Creeresti una nuova versione dello schema order e la registreresti con lo stesso soggetto. In questo modo puoi monitorare l'evoluzione dello schema nel tempo.
L'aggiunta di un campo è una modifica compatibile con le versioni successive. Ciò significa che i consumatori che utilizzano
versioni precedenti dello schema (senza orderDate) possono comunque leggere ed elaborare i messaggi
prodotti con il nuovo schema. Il nuovo campo viene ignorato.
La compatibilità con le versioni precedenti del registro degli schemi indica che un'applicazione consumer configurata con una nuova versione dello schema può leggere i dati prodotti con uno schema precedente.
In questo esempio, lo schema order iniziale sarebbe la versione 1. Quando aggiungi
il campo orderDate, crei la versione 2 dello schema order. Entrambe le versioni
sono archiviate nello stesso argomento, il che ti consente di gestire gli aggiornamenti dello schema senza
interrompere le applicazioni esistenti che potrebbero ancora basarsi sulla versione 1.
Di seguito è riportata una visualizzazione dall'alto verso il basso di un registro di schema di esempio chiamato
schema_registry_test organizzato per contesto, oggetto e
versione dello schema:
customer_supportcontextorderoggettoVersione
V1(include orderId, customerName, productName, quantity, price)Versione
V2(aggiunge orderDate alla versione 1)
Che cos'è uno schema
I messaggi Apache Kafka sono costituiti da stringhe di byte. Senza una struttura definita, le applicazioni consumer devono coordinarsi direttamente con le applicazioni produttrici per capire come interpretare questi byte.
Uno schema fornisce una descrizione formale dei dati all'interno di un messaggio. Definisce i campi e i relativi tipi di dati, ad esempio stringa, numero intero o booleano, e qualsiasi struttura nidificata.
Managed Service per Apache Kafka supporta gli schemi nei seguenti formati:
Buffer di protocollo (Protobuf)
L'API del registro degli schemi non supporta JSON.
La funzionalità del registro di schema integrata in Managed Service per Apache Kafka consente di creare, gestire e utilizzare questi schemi con i client Kafka. Il registro di schema implementa l'API REST Confluent Schema Registry, compatibile con le applicazioni Apache Kafka esistenti e le librerie client comuni.
Organizzazione del registro di schema
Il registro degli schemi utilizza una struttura gerarchica per organizzare gli schemi.
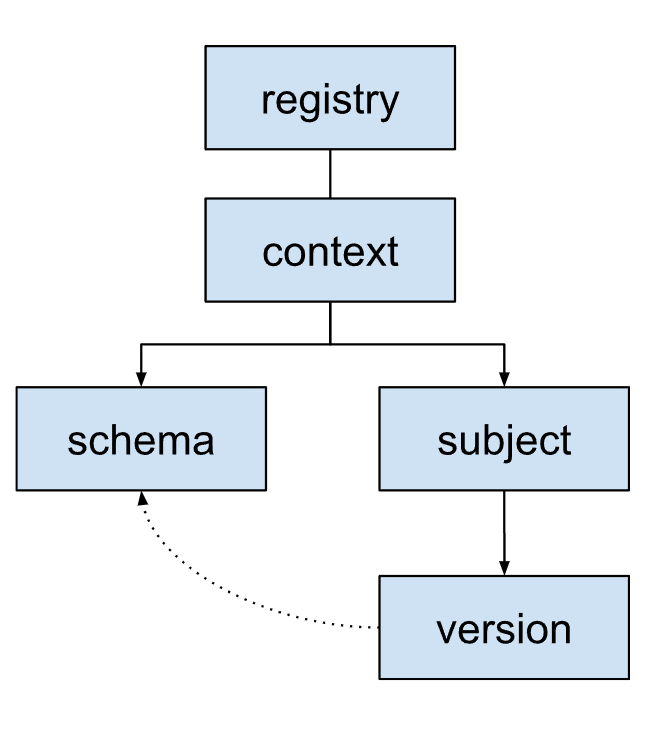
Schema:la struttura e i tipi di dati di un messaggio. Ogni schema è identificato da un ID schema. Questo ID viene utilizzato dalle applicazioni per recuperare lo schema.
Oggetto:un contenitore logico per le diverse versioni di uno schema. I soggetti gestiscono l'evoluzione degli schemi nel tempo utilizzando regole di compatibilità. Ogni soggetto corrisponde in genere a un argomento Kafka o a un oggetto record.
Versione:quando la logica di business richiede modifiche a una struttura del messaggio, crea e registra una nuova versione dello schema nell'oggetto pertinente.
Ogni versione fa riferimento a uno schema specifico. Le versioni di soggetti diversi possono fare riferimento allo stesso schema se lo schema sottostante è lo stesso.
Contesto:un raggruppamento o uno spazio dei nomi di alto livello per gli argomenti. I contesti consentono a team o applicazioni diversi di utilizzare lo stesso nome del soggetto senza conflitti all'interno dello stesso registro dello schema.
Un registro degli schemi può avere più contesti. Contiene sempre un contesto predefinito identificato come
., in cui vengono inseriti schemi e soggetti quando non viene specificato un altro identificatore di contesto.Un contesto può contenere più soggetti.
Registro:il contenitore di primo livello per l'intero ecosistema di schemi. Archivia e gestisce tutti gli schemi, i soggetti, le versioni e i contesti.
Workflow del registro di schema
Per seguire il flusso di lavoro descritto in questa sezione, puoi provare la guida rapida in Produci messaggi Avro con il registro di schemi.
I serializzatori e i deserializzatori nei client Kafka interagiscono con il registro di schema per garantire che i messaggi siano conformi a uno schema definito. Ecco un flusso di lavoro tipico per un registro di schema in Managed Service per Apache Kafka:
Inizializza l'applicazione producer con uno schema specifico specificato come classe generata da Avro e configurala per utilizzare una particolare libreria di serializzazione e un particolare registro dello schema.
Configura un client consumer in modo che utilizzi una libreria di deserializzazione corrispondente e lo stesso registro di schema.
In fase di runtime, il client passa l'oggetto messaggio nel metodo
producer.sende la libreria client Kafka utilizza il serializzatore configurato per convertire questo record nei byte codificati in Avro.Il serializzatore determina un nome soggetto per lo schema in base a una strategia di denominazione dei soggetti configurata all'interno della libreria client. Utilizza poi questo nome del soggetto in una richiesta al registro degli schemi per recuperare l'ID dello schema. Per saperne di più, consulta Strategie di denominazione dei soggetti.
Se lo schema non esiste nel registro con quel nome del soggetto, il client può essere configurato per registrare lo schema, nel qual caso riceve l'ID appena assegnato.
Evita questa configurazione negli ambienti di produzione.
Il produttore invia il messaggio serializzato con l'ID schema all'argomento appropriato di un broker Kafka.
Il broker Kafka memorizza la rappresentazione dell'array di byte del messaggio in un argomento.
L'applicazione consumer riceve il messaggio.
Il deserializzatore recupera lo schema con questo ID dal registro dello schema.
Il deserializzatore analizza il messaggio per l'applicazione consumer.
Limitazioni
Le seguenti funzionalità non sono supportate dal registro degli schemi:
Formati dello schema:
- Formato dello schema JSON.
Modalità dello schema:
- Modalità schema
READONLY_OVERRIDE.
- Modalità schema
Valori di configurazione dello schema:
- Valori di configurazione di
NormalizeeAlias.
- Valori di configurazione di
Metodi API:
- Il metodo
ModifySchemaTags(/subjects/{subject}/versions/{version}/tags). - Il metodo
GetLatestWithMetadata(/subjects/{subject}/metadata). - Il metodo
ListSchemas(/schemas). - Il metodo
DeleteSchemaMode. - Per il metodo
GetVersion: i parametriformat,deletedefindTags. - Per il metodo
CreateVersion: i parametrimetadata,ruleSet,schemaTagsToAddeschemaTagsToRemove. - Per il metodo
UpdateSchemaMode: il parametroforce. - Per il metodo
GetSchemaMode: il parametrodefaultToGlobal. - Per il metodo
GetSchema: i parametriWorkspaceMaxIdefindTags. - Per il metodo
ListVersions: il parametrodeletedOnly. - Per il metodo
ListSubjects: il parametrodeletedOnly.
- Il metodo