
클라이언트는 Google Cloud프로젝트의 모든 가상 프라이빗 클라우드 (VPC) 네트워크에서 Managed Service for Apache Kafka 클러스터에 연결할 수 있습니다.
이 페이지에서는 Managed Service for Apache Kafka에서 네트워킹이 구성되는 방식, Kafka 클라이언트와 클러스터 간 연결을 사용 설정하는 방법, 교차 프로젝트 연결을 사용 설정하는 방법을 설명합니다.
개요
클러스터를 만들면 서비스가 Google Cloud에서 관리하는 VPC 네트워크에 클러스터를 배치합니다. 이 네트워크를 테넌트 네트워크라고 합니다. 각 Managed Service for Apache Kafka 클러스터에는 자체 격리된 테넌트 네트워크가 있습니다. 클라이언트 애플리케이션이 클러스터와 통신할 수 있도록 하려면 VPC 네트워크 내의 서브넷을 테넌트 네트워크에 연결합니다.
다음 다이어그램은 두 개의 Google Cloud 프로젝트, project-1 및 project-2를 보여줍니다. Managed Service for Apache Kafka 클러스터는 project-1에 있습니다.
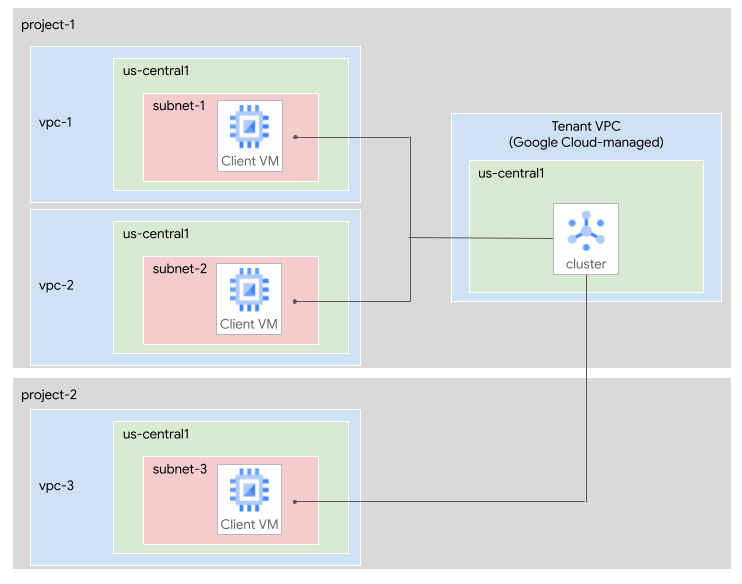
다음 서브넷이 클러스터에 연결되어 있습니다.
project-1의 VPC 네트워크vpc-1에 있는subnet-1project-1의 VPC 네트워크vpc-2에 있는subnet-2project-2의 VPC 네트워크vpc-3에 있는subnet-3
서브넷을 클러스터에 연결
Managed Service for Apache Kafka 클러스터를 처음 만들 때 하나 이상의 서브넷을 지정해야 합니다. 나중에 클러스터를 업데이트하여 서브넷을 추가하거나 삭제할 수 있습니다.
연결된 서브넷은 클러스터와 동일한 Google Cloud 프로젝트에 속하거나 다른 프로젝트에 속할 수 있습니다. 연결된 서브넷은 클러스터와 동일한 리전에 있어야 하지만 동일한 VPC 내의 모든 리전에 있는 클라이언트는 해당 서브넷의 IP 주소에 연결할 수 있습니다. VPC 네트워크당 최대 하나의 서브넷을 클러스터에 연결할 수 있습니다.
클러스터에 연결된 서브넷을 보려면 클러스터의 서브넷 보기를 참고하세요.
클러스터 DNS 항목
서브넷을 클러스터에 연결하면 서비스는 클러스터의 부트스트랩 주소와 브로커에 대해 해당 서브넷 네트워크 내에 DNS 항목을 만듭니다. Kafka 클라이언트는 부트스트랩 주소를 사용하여 브로커를 찾고 연결을 설정합니다.
DNS 이름은 연결된 모든 서브넷에서 동일하지만 각 서브넷의 IP 주소는 서로 다릅니다. DNS 이름이 일관되므로 모든 Kafka 클라이언트 애플리케이션에서 동일한 부트스트랩 주소를 사용할 수 있습니다. 클러스터의 부트스트랩 주소를 가져오려면 클러스터의 부트스트랩 주소 보기를 참고하세요.
Managed Service for Apache Kafka에 연결하는 클라이언트 애플리케이션의 예는 다음 튜토리얼을 참고하세요.
서브넷 크기 조정
클러스터에 서브넷을 추가할 때는 서브넷에 사용 가능한 IP 주소가 충분해야 합니다. 각 서브넷에는 Kafka 브로커당 하나의 IP 주소와 부트스트랩 주소용 하나의 IP 주소가 필요합니다. Managed Service for Apache Kafka의 최소 클러스터 크기는 브로커 3개이므로 각 서브넷에는 부트스트랩 주소를 포함하여 사용 가능한 IP 주소가 4개 이상 필요합니다.
클러스터에 vCPU가 45개를 초과하면 클러스터에는 vCPU 15개당 브로커가 하나씩 있습니다. 이 경우 각 서브넷의 최소 IP 주소 수를 다음과 같이 계산합니다.
- vCPU 수를 15로 나눕니다.
- 가장 가까운 정수로 올림합니다.
- 부트스트랩 주소를 고려하여 1을 추가합니다.
예를 들어 vCPU가 60개인 클러스터에는 사용 가능한 IP 주소가 최소 (60/15 + 1) = 5개 필요합니다.
향후 Google에서 브로커와 vCPU의 비율을 변경할 수 있습니다. 향후 변경사항을 수용하려면 이전 단계에서 계산한 IP 주소 수의 3배를 할당하는 것이 좋습니다.
서브넷 크기를 계획할 때는 향후 클러스터를 확장할 것으로 예상되는 최대 크기를 기준으로 계산하세요.
Kafka Connect를 사용하려는 경우 Connect 클러스터의 서브넷 요구사항도 고려하세요. 자세한 내용은 작업자 서브넷을 참고하세요.
비공개로 사용되는 공개 IP 범위
RFC 1918 이외의 주소 공간을 사용하는 서브넷에 클러스터를 연결할 수 있습니다. 이러한 IP 주소 범위를 비공개로 사용되는 공개 IP (PUPI) 범위라고 합니다.
PUPI 서브넷에 연결하기 위해 추가 구성이 필요하지 않습니다. PUPI 서브넷은 금지된 IPv4 서브넷 범위가 아닌 유효한 IPv4 범위를 사용해야 합니다.
프로젝트 간 클라이언트 및 클러스터 연결
서로 다른 Google Cloud 프로젝트에 Kafka 클라이언트가 있는 경우 다음과 같은 방법으로 클러스터에 연결할 수 있습니다.
다음 섹션에서는 이러한 옵션을 설명합니다.
프로젝트 간 클러스터 연결
다른 프로젝트의 서브넷을 클러스터에 연결할 수 있습니다. 프로젝트 간 액세스를 사용 설정하려면 클러스터와 연결된 Google 관리 서비스 계정에 권한을 부여해야 합니다. Kafka 클라이언트가 클러스터에 액세스할 프로젝트마다 서비스 계정에 해당 프로젝트의 관리형 Kafka 서비스 에이전트 IAM 역할이 있어야 합니다. 이 역할을 사용하면 클러스터가Google Cloud 리소스에 액세스하여 네트워크 리소스와 DNS 항목을 만들 수 있습니다.
예: project-1에 클러스터가 포함되어 있고 project-2의 클라이언트가 클러스터에 액세스하도록 하려면 project-1의 관리형 Kafka 서비스 계정에 project-2에 대한 관리형 Kafka 서비스 에이전트 역할을 부여합니다. 그런 다음 project-2의 서브넷을 클러스터에 연결합니다(클러스터에 서브넷 연결 참고).
필요한 역할을 부여하려면 다음 단계를 따르세요.
콘솔
Kafka 클라이언트가 Managed Service for Apache Kafka 클러스터에 액세스할 Google Cloud 프로젝트를 결정합니다.
각 프로젝트의 경우 Google Cloud 콘솔에서 해당 프로젝트의 IAM 페이지로 이동합니다.
액세스 권한 부여를 클릭합니다.
새 주 구성원 필드에 다음을 입력합니다.
service-CLUSTER_PROJECT_NUMBER@gcp-sa-managedkafka.iam.gserviceaccount.comCLUSTER_PROJECT_NUMBER를 Managed Service for Apache Kafka 클러스터가 포함된 프로젝트의 프로젝트 번호로 바꿉니다.
역할 추가를 클릭합니다.
역할 검색 필드에
Managed Kafka Service Agent을 입력합니다. 서비스 에이전트 이름이 검색 결과에 표시됩니다.검색 결과에서 관리형 Kafka 서비스 에이전트를 선택합니다.
적용을 클릭합니다.
저장을 클릭합니다.
gcloud
Kafka 클라이언트가 Managed Service for Apache Kafka 클러스터에 액세스할 Google Cloud 프로젝트를 결정합니다.
각 프로젝트에 대해
gcloud projects add-iam-policy-binding명령어를 실행합니다.gcloud projects add-iam-policy-binding CLIENT_PROJECT_ID \ --member=serviceAccount:service-CLUSTER_PROJECT_NUMBER@gcp-sa-managedkafka.iam.gserviceaccount.com \ --role=roles/managedkafka.serviceAgent다음을 바꿉니다.
- CLIENT_PROJECT_ID: 연결할 VPC 네트워크가 포함된 프로젝트의 이름
- CLUSTER_PROJECT_NUMBER: Managed Service for Apache Kafka 클러스터가 포함된 프로젝트의 프로젝트 번호
공유 VPC를 사용하여 프로젝트 연결
공유 VPC를 사용하면 조직에서 여러 프로젝트의 리소스를 공통 VPC 네트워크에 연결할 수 있습니다. Managed Service for Apache Kafka와 함께 공유 VPC를 사용하려면 다음 단계를 실행하세요.
Managed Service for Apache Kafka 클러스터를 만듭니다.
이전 섹션에 설명된 대로 공유 VPC 호스트 프로젝트에서 관리형 Kafka 서비스 계정에 필요한 역할을 부여합니다.
Managed Service for Apache Kafka 클러스터를 공유 VPC 네트워크의 서브넷에 연결합니다.
공유 VPC 호스트 프로젝트 또는 서비스 프로젝트의 클라이언트는 클러스터에 연결할 수 있습니다.
네트워크 아키텍처에서 공유 VPC를 사용해야 하는 경우에 관한 자세한 내용은 VPC 설계에 관한 권장사항 및 참조 아키텍처를 참고하세요.
클러스터의 네트워크 아키텍처
이 섹션에서는 Managed Service for Apache Kafka에 사용되는 네트워킹 아키텍처의 세부정보를 설명합니다.
Kafka 클러스터는 테넌트 네트워크와 하나 이상의 소비자 네트워크에 걸쳐 있습니다.
테넌트 네트워크에서 클러스터에는 단일 부트스트랩 IP 주소와 URL이 있습니다. 이 부트스트랩 주소는 클러스터의 모든 브로커에 연결된 부하 분산기에 해당합니다. 각 브로커는 개별적으로 부트스트랩 서버 역할을 할 수도 있지만 안정성을 위해 부트스트랩 주소를 사용하는 것이 좋습니다.
각 소비자 네트워크 내에서 서비스는 부트스트랩 주소용 Private Service Connect 엔드포인트와 각 브로커용 엔드포인트 하나를 만듭니다.
부트스트랩 주소의 URL은 클러스터가 연결된 VPC 네트워크에서 동일합니다. IP 주소가 소비자 네트워크에 로컬입니다.
클라이언트는 DNS 이름을 사용하여 Kafka 브로커에 연결합니다. 이러한 이름은 Kafka 클러스터가 연결된 모든 VPC 네트워크에 자동으로 등록됩니다. 부트스트랩 주소와 포트 번호는 클러스터의 속성으로 사용할 수 있습니다.
클라이언트는 부트스트랩 주소를 사용하여 브로커 URL을 가져옵니다. 이러한 URL은 각 VPC 네트워크에 로컬인 IP 주소로 확인됩니다. 실제 브로커 IP 주소와 URL은 Cloud DNS에서 확인할 수 있습니다.
다음 다이어그램은 Managed Service for Apache Kafka 클러스터 네트워크의 샘플 아키텍처를 보여줍니다.
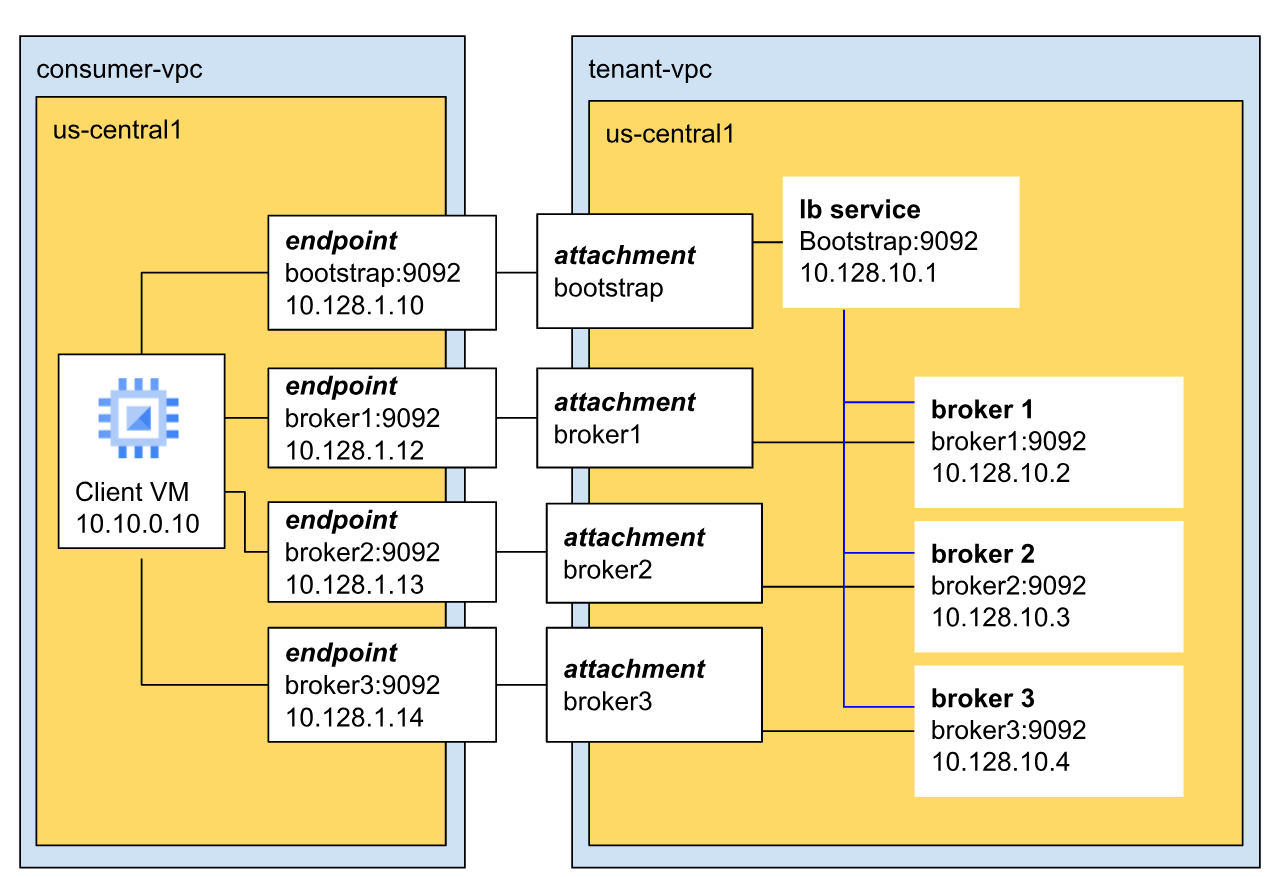
이 예시에서 클러스터에는 브로커가 3개 있으며 클러스터는 테넌트 VPC에 있습니다.
브로커는 기본 Kafka 포트 (9092)를 통해 클라이언트와 통신하며 고유한 IP 주소가 있습니다. 이 예에서 세 브로커의 IP 주소는 각각 10.128.10.2, 10.128.10.3, 10.128.10.4입니다.
세 브로커 모두 부트스트랩 부하 분산기에 연결됩니다. 이렇게 하면 부트스트랩 주소가 단일 브로커나 영역에 국한되지 않으므로 고가용성과 리전 내결함성이 보장됩니다.
문제 해결
네트워킹 문제를 해결하는 방법은 네트워킹 오류를 참고하세요.