
Questo documento ti aiuta a eseguire la migrazione dei tuoi carichi di lavoro Apache Kafka a Google Cloud Managed Service per Apache Kafka, un servizio gestito all'interno di Google Cloud.
Managed Service per Apache Kafka ti aiuta a eseguire Apache Kafka su Google Cloud. In questa soluzione documentata, sposti i dati da un cluster Apache Kafka esterno a un cluster Managed Service per Apache Kafka.
Per saperne di più su Managed Service per Apache Kafka, consulta la panoramica di Managed Service per Apache Kafka.
Ti consigliamo di utilizzare MirrorMaker 2.0 per questa migrazione.
MirrorMaker 2.0 è uno strumento per replicare i dati tra cluster Apache Kafka in tempo reale. Può essere utilizzato per migrazioni dei dati, ripristino di emergenza, isolamento e aggregazione dei dati.
Per saperne di più su MirrorMaker 2.0, consulta la sezione successiva.
Che cos'è MirrorMaker 2.0
MirrorMaker 2.0 utilizza il framework Kafka Connect per replicare i dati tra i cluster Kafka. Kafka Connect è un framework per lo streaming di dati tra cluster Kafka e altri sistemi. Funge da pipeline scalabile e affidabile. Questo framework semplifica l'integrazione di Kafka con vari sistemi esterni, come database, code di messaggi e spazio di archiviazione online, tramite l'utilizzo di connettori facilmente disponibili. Di seguito è riportato un elenco di possibili scenari in cui puoi utilizzare MirrorMaker 2.0:
Migrazioni dei dati: sposta il tuo workload Kafka in un nuovo cluster, come illustrato in questa guida.
Ripristino di emergenza: crea un cluster di backup per garantire la continuità aziendale in caso di errori.
Isolamento dei dati: replica selettivamente gli argomenti in un cluster pubblico mantenendo al sicuro i dati sensibili in un cluster privato.
Aggregazione dei dati: consolida i dati di più cluster Kafka in un cluster centrale a scopo di analisi.
MirrorMaker 2.0 supporta Kafka versione 2.4.0 e successive e offre le seguenti funzionalità chiave:
Replica completa: replica tutti i componenti necessari, inclusi argomenti, dati e configurazioni, gruppi di consumatori con offset e ACL.
Conservazione delle partizioni: mantiene lo stesso schema di partizionamento nel cluster di destinazione, semplificando la transizione per le applicazioni.
Creazione automatica di argomenti e partizioni: rileva e replica automaticamente nuovi argomenti e partizioni, riducendo al minimo la configurazione manuale.
Funzionalità di monitoraggio: fornisce metriche essenziali come la latenza di replica end-to-end, consentendoti di monitorare l'integrità e le prestazioni del processo di replica.
Tolleranza agli errori e scalabilità: garantisce un funzionamento affidabile anche con volumi di dati elevati e può essere scalato orizzontalmente per gestire carichi di lavoro crescenti.
Argomenti interni per la robustezza: utilizza argomenti interni per la sincronizzazione dell'offset, i checkpoint e i battiti. Questi argomenti hanno fattori di replica configurabili, ad esempio
offset.syncs.topic.replication.factor, per garantire un'elevata disponibilità e tolleranza agli errori.
MirrorMaker 2.0 offre due modalità di deployment:
Modalità cluster dedicato: MirrorMaker 2.0 viene eseguito come cluster autonomo, gestendo i propri worker. Questo documento si concentra su questa modalità, fornendo un esempio pratico del suo deployment e della sua configurazione.
Modalità cluster Kafka Connect: MirrorMaker 2.0 viene eseguito come connettore all'interno di un cluster Kafka Connect esistente.
Workflow di alto livello
Il seguente diagramma illustra l'architettura per la migrazione dei dati da un cluster Apache Kafka di origine a un cluster Managed Service per Apache Kafka utilizzando MirrorMaker 2.0.
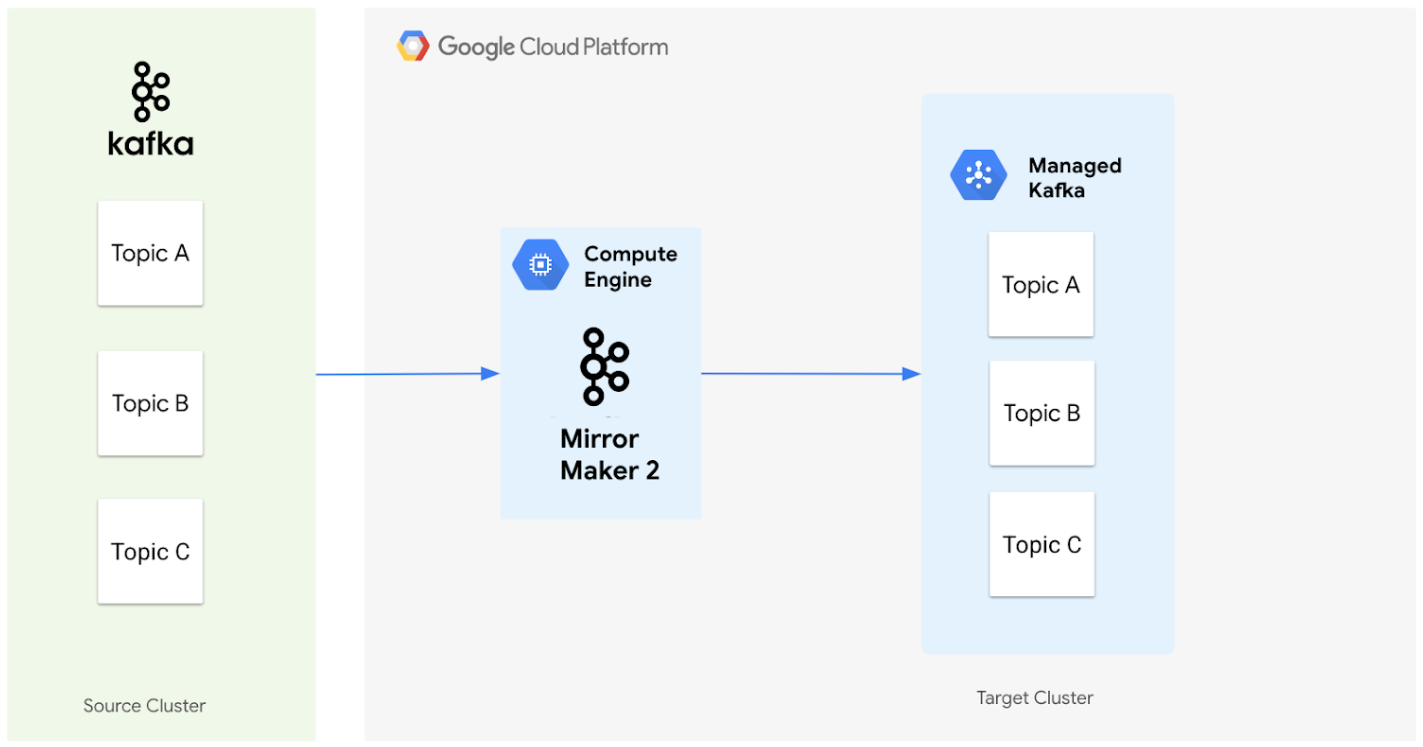
Ecco come funzionano insieme i componenti:
Cluster di origine: rappresenta il tuo cluster Apache Kafka esistente, che può trovarsi on-premise o in un altro ambiente cloud. Contiene gli argomenti di cui vuoi eseguire la migrazione. In questo diagramma, il cluster Apache Kafka di origine contiene tre argomenti: A, B e C.
MirrorMaker 2.0: questo componente principale, di cui è stato eseguito il deployment su una VM Compute Engine come cluster MirrorMaker 2.0 dedicato, replica attivamente i dati dal cluster Apache Kafka di origine al cluster Managed Service per Apache Kafka di destinazione. aspetto importante, crea automaticamente anche gli argomenti e le partizioni corrispondenti nel cluster di destinazione se non esistono, rispecchiando la configurazione del cluster di origine.
Cluster di destinazione: questo è il tuo cluster Managed Service per Apache Kafka. Diventa la nuova sede dei tuoi dati Kafka, con MirrorMaker 2.0 che garantisce che gli argomenti e le partizioni vengano creati in modo che corrispondano all'ambiente di origine.
Di seguito è riportato un workflow generale per il processo di migrazione.
Valutazione iniziale
Documenta la configurazione Kafka esistente, includendo dimensioni del cluster, argomenti, throughput e gruppi di consumer.
Pianifica gli obiettivi e la strategia di migrazione, inclusi la tolleranza ai tempi di inattività e l'approccio al cutover.
Stima le risorse richieste per il tuo cluster Managed Service per Apache Kafka.
Preparazione
Crea un cluster Managed Service per Apache Kafka.
Configura la connettività di rete tra il cluster Kafka esistente e il cluster Managed Service per Apache Kafka che hai appena creato.
Esegui il deployment di MirrorMaker 2.0 su una VM Google Cloud .
Esecuzione della migrazione
Configura MirrorMaker 2.0 per replicare i dati dal cluster Kafka esistente al cluster Managed Service per Apache Kafka.
Monitora il processo di replica utilizzando le metriche di MirrorMaker 2.0.
Esegui la migrazione graduale di consumer e producer al nuovo cluster Managed Service per Apache Kafka.
Convalida e transizione
Convalida l'integrità dei dati e le funzionalità dell'applicazione nel cluster Managed Service per Apache Kafka.
Esegui il cutover finale, reindirizzando il traffico al cluster Managed Service per Apache Kafka.
Ritira il vecchio cluster Kafka.
Dopo la migrazione
Monitora continuamente le prestazioni del tuo cluster Managed Service per Apache Kafka.
Rivedi e aggiorna la documentazione per riflettere le modifiche.
Ridurre al minimo i tempi di inattività della migrazione
Questa sezione descrive alcune considerazioni per la migrazione dei dati Kafka open source a Managed Service per Apache Kafka utilizzando MirrorMaker 2.0. MirrorMaker 2.0 facilita la replica dei dati e dell'offset, consentendo ai consumatori di riprendere dal punto corretto nel nuovo cluster. Tuttavia, una pianificazione attenta è fondamentale per ridurre al minimo i tempi di inattività durante il processo di migrazione. Prendi in considerazione queste strategie:
Deployment paralleli: per ridurre al minimo i tempi di inattività quando passi al nuovo cluster Managed Service per Apache Kafka, puoi eseguire istanze parallele delle tue applicazioni sia sul cluster precedente che su quello nuovo. Durante questa transizione, disattiva temporaneamente qualsiasi azione nella tua applicazione che deve essere eseguita una sola volta per messaggio, ad esempio l'invio di una notifica. Disattiva questi effetti collaterali per evitare conseguenze indesiderate dall'elaborazione dello stesso messaggio due volte. Una volta che le nuove istanze sono completamente aggiornate, reindirizza tutto il traffico al nuovo cluster e riattiva tutte le funzionalità.
Implementazioni in più fasi: esegui la migrazione in fasi più piccole e gestibili, a partire dalle applicazioni meno critiche. Questo approccio aiuta a isolare i potenziali problemi e riduce al minimo l'impatto di eventuali interruzioni.
Deployment blu e verde: crea una replica completa dell'ambiente di produzione (verde) accanto a quello esistente (blu). Sposta gradualmente il traffico dal blu al verde, consentendo test e convalida prima del passaggio definitivo. Questo approccio riduce al minimo i tempi di inattività, ma richiede un maggiore utilizzo delle risorse.
Requisiti di elaborazione dei messaggi: comprendi la tolleranza della tua applicazione per i messaggi duplicati o mancanti e configura i consumer di conseguenza. MirrorMaker 2.0 offre configurazioni per gestire la semantica di distribuzione dei messaggi. Ad esempio,
sync.group.offsets.enabledsupporta la sincronizzazione dell'offset del consumer. I consumatori possono utilizzare gli offset sincronizzati per riprendere la lettura da dove l'avevano interrotta nel cluster di origine. In questo modo, puoi evitare la perdita di messaggi o la ricezione di troppi duplicati.Comunicazione e coordinamento: una comunicazione efficace con i team delle applicazioni è essenziale per una migrazione senza problemi. Stabilisci canali di comunicazione chiari e coordina i tempi di trasferimento.
Connetti Apache Kafka on-premise a Google Cloud
Se il cluster Apache Kafka di origine si trova on-premise, devi stabilire una connessione sicura tra la tua rete on-premise e il tuo Virtual Private Cloud (VPC) in cui si trova il cluster Managed Service per Apache Kafka. Utilizza una delle seguenti opzioni da Google Cloud.
Cloud VPN: una soluzione conveniente adatta a esigenze di larghezza di banda inferiori o a esperimenti di migrazione iniziali. Crea un tunnel criptato sulla rete internet pubblica. Per ulteriori informazioni su Cloud VPN, consulta la panoramica di Cloud VPN.
Cloud Interconnect: fornisce una connessione dedicata a larghezza di banda elevata tra la tua rete on-premise e Google Cloud. È ideale per implementazioni di livello aziendale che richiedono un throughput più elevato e una latenza inferiore. Puoi scegliere tra Dedicated Interconnect (per la connessione fisica diretta) o Partner Interconnect (connessione tramite un provider di servizi supportato). Per ulteriori informazioni sulla Google Cloud documentazione di Interconnect, consulta la panoramica di Cloud Interconnect.
Quando crei un cluster Managed Service per Apache Kafka, devi selezionare almeno una subnet nel VPC. Questa subnet fornisce gli indirizzi IP che il cluster utilizza per comunicare con altre risorse nel VPC, rendendo il cluster accessibile all'interno della rete VPC.
Per connetterti in modo sicuro al tuo cluster Managed Service for Apache Kafka da reti on-premise o altre reti VPC, puoi utilizzare Private Service Connect (PSC) su Cloud VPN o Cloud Interconnect. Non è necessario configurare esplicitamente gli endpoint PSC. Quando selezioni una subnet durante la creazione del cluster, il servizio Managed Service per Apache Kafka crea automaticamente gli endpoint PSC necessari. Ciò semplifica la configurazione di rete consentendoti di accedere al cluster utilizzando indirizzi IP interni all'interno del VPC, senza dover gestire regole firewall complesse o indirizzi IP pubblici.
Per maggiori informazioni sulla configurazione di rete per Managed Service per Apache Kafka, consulta Networking per Managed Service per Apache Kafka.
Prima di iniziare
Prima di iniziare a creare la configurazione della migrazione, devi documentare la configurazione attuale di Apache Kafka. Ti serve per calcolare le risorse, come vCPU, memoria e spazio di archiviazione, necessarie per il nuovo cluster Managed Service per Apache Kafka. Raccogli le seguenti informazioni sull'ambiente Apache Kafka di origine:
Assicurati che la versione di Apache Kafka sia 2.4.0 o successiva.
Per controllare la versione del cluster Apache Kafka, vai alla directory di installazione di Kafka ed esegui il comando
bin/kafka-topics.sh --versionIdentifica i cluster e gli argomenti di cui eseguire la migrazione.
Identifica i producer e i consumer associati a ogni argomento.
Identifica tutti i gruppi di consumatori.
Determina la velocità effettiva dei messaggi a livello di cluster e di argomento.
Determina il fattore di replica per i cluster e gli argomenti.
Documenta le configurazioni dei consumer, in particolare i protocolli di sicurezza e qualsiasi integrazione con altri Google Cloud servizi.
Per evitare interruzioni durante la migrazione, mappa tutte le dipendenze delle applicazioni correlate al cluster Kafka di origine. Prima di eseguire la migrazione dell'ambiente di produzione, esegui una migrazione di test utilizzando un cluster non critico in un ambiente di sviluppo. Convalida la procedura e identifica eventuali problemi. Infine, crea un piano di rollback completo per ripristinare il cluster originale, se necessario.
Calcolare le dimensioni del cluster di destinazione
Per stimare il numero di vCPU e le dimensioni della memoria richieste per il tuo cluster Managed Service per Apache Kafka, consulta Pianificare le dimensioni del cluster Kafka. La configurazione del disco e del broker è automatica e non può essere modificata.
Kafka open source fornisce metriche JMX. Per calcolare con precisione le dimensioni del cluster richieste per Managed Service per Apache Kafka, puoi utilizzare le seguenti metriche JMX. Queste metriche vengono riportate a livello di broker. Devi aggregare i dati in tutti i broker per calcolare la velocità effettiva del cluster.
kafka.server:type=BrokerTopicMetrics,name=BytesInPerSec: Questa metrica indica la velocità di byte in entrata dai client in tutti gli argomenti. Ometti il parametrotopic={...}per ottenere la tariffa aggregata per tutti gli argomenti.kafka.server:type=BrokerTopicMetrics,name=BytesOutPerSec: Questa metrica indica la velocità dei byte in uscita verso i client in tutti gli argomenti. Ometti il parametrotopic={...}per ottenere la tariffa complessiva.
Monitorando queste metriche JMX per un periodo di tempo, puoi raccogliere punti dati per calcolare quanto segue:
Media dati in entrata, MB/s: questa metrica rappresenta la velocità media con cui i dati vengono inseriti nel cluster Kafka.
Picco di dati in entrata, MB/s: questa metrica rappresenta la velocità più elevata con cui i dati vengono inseriti nel cluster Kafka.
Media dati in uscita, MB/s: questa metrica rappresenta la velocità media con cui i dati vengono utilizzati dal cluster Kafka.
Peak Data Out, MB/s: questa metrica rappresenta la velocità massima con cui i dati vengono utilizzati dal cluster Kafka.
Per aggregare i dati e convertire i byte in MB, potrebbe essere necessario eseguire alcuni calcoli delle metriche. Utilizzando questi valori calcolati, puoi stimare la velocità equivalente di scrittura come segue:
Write-equivalent rate (Avg/Peak) = (total write bandwidth) + (total read bandwidth / 4)
Questo tasso equivalente di scrittura aiuta a determinare il carico di scrittura complessivo sul cluster, necessario per dimensionare correttamente il cluster Managed Service per Apache Kafka.
Crea un cluster Managed Service per Apache Kafka
Un cluster Managed Service per Apache Kafka si trova in un progetto e in una regioneGoogle Cloud specifici. È possibile accedervi utilizzando un insieme di indirizzi IP all'interno di una o più subnet in qualsiasi Virtual Private Cloud (VPC).
Le dimensioni del cluster sono determinate dal numero di CPU e dalla RAM totale che gli assegni. In questo caso, le dimensioni del cluster devono corrispondere a quelle del cluster Apache Kafka di origine. Per ulteriori informazioni su come eseguire questo calcolo, vedi Calcolare le dimensioni del cluster di destinazione.
Per ottenere le autorizzazioni necessarie per creare un cluster, chiedi all'amministratore di concedere a te o al account di servizio che crea il cluster il ruolo IAM Managed Kafka Admin (roles/managedkafka.admin) sul tuo progetto. Per saperne di più sulla concessione dei ruoli, consulta Gestisci l'accesso a progetti, cartelle e organizzazioni.
Per creare un cluster Managed Service per Apache Kafka, segui le istruzioni di avvio rapido disponibili all'indirizzo Produci e consuma messaggi con la CLI. La creazione di un cluster richiede in genere 20-30 minuti.
Configura MirrorMaker 2.0 in modalità cluster autonomo
Per un documento di prova concettuale e codice campione che mostrano come utilizzare MirrorMaker 2.0 e Terraform per trasferire i dati Kafka a Google Cloud, consulta questo repository GitHub.
Questa sezione ti guida nell'installazione e nella configurazione di MirrorMaker 2.0 in modalità cluster autonomo su una VM Google Cloud . Questa configurazione ti consente di replicare i dati dal tuo cluster Apache Kafka esistente a un cluster Managed Service per Apache Kafka.
Crea una VM nella stessa rete a cui è stato concesso l'accesso al cluster Managed Service per Apache Kafka. Utilizza il comando gcloud compute instances create.
gcloud compute instances create VM_NAME\ --zone=ZONE\ [--image=IMAGE | --image-family=IMAGE_FAMILY]\ --image-project=IMAGE_PROJECT\ --machine-type=MACHINE_TYPE
Sostituisci quanto segue:
VM_NAME: il nome della VM che vuoi creare.ZONE: la zona in cui vuoi creare la VM.IMAGEoIMAGE_FAMILY: l'immagine o la famiglia di immagini che vuoi utilizzare per la VM.IMAGE_PROJECT: il progetto in cui si trova l'immagine.MACHINE_TYPE: il tipo di macchina che vuoi utilizzare per la VM.
Per accedere alla VM appena creata, puoi utilizzare SSH.
Per saperne di più sulle connessioni SSH, consulta Informazioni sulle connessioni SSH.
Per scaricare Kafka ed estrarlo, nella finestra del terminale della nuova VM, esegui questi comandi:
wget https://downloads.apache.org/kafka/3.7.1/kafka_2.13-3.7.1.tgz tar -xzvf kafka_2.13-3.7.1.tgzScarica Java, estrai il pacchetto e imposta il percorso Java.
# Download Java wget https://download.java.net/java/GA/jdk11/9/GPL/openjdk-11.0.2_linux-x64_bin.tar.gz # Extract Java tar -xzvf openjdk-11.0.2_linux-x64_bin.tar.gz # Set Java path export PATH=$PATH:/java/jdk-11.0.2/bin/Modifica il file
path/to/kafka/config/mm2.propertiese aggiorna le seguenti proprietà:clusters = source, target source.bootstrap.servers = <source_kafka_bootstrap_servers> target.bootstrap.servers = <target_kafka_bootstrap_servers> source.security.protocol = SASL_SSL source.sasl.mechanism = PLAIN source.sasl.jaas.config = org.apache.kafka.common.security.plain.PlainLoginModule required username="<source_kafka_username>" password="<source_kafka_password>"; target.security.protocol = SASL_SSL target.sasl.mechanism = PLAIN target.sasl.jaas.config = org.apache.kafka.common.security.plain.PlainLoginModule required username="<target_kafka_username>" password="<target_kafka_password>"; mirrors = source->target source->target.enabled=true topics = .* groups = .* offset.syncs.topic.replication.factor = 3 checkpoints.topic.replication.factor = 3 heartbeats.topic.replication.factor = 3 emit.checkpoints.interval.seconds = 10Sostituisci
source_kafka_bootstrap_serversetarget_kafka_bootstrap_serverscon gli indirizzi dei server di bootstrap dei cluster Kafka di origine e di destinazione, rispettivamente. Puoi ottenere l'indirizzo del server di bootstrap per Managed Service per Apache Kafka utilizzando il comandomanaged-kafka clusters describeGoogle Cloud CLI.Sostituisci
source_kafka_usernameesource_kafka_passwordcon le credenziali del cluster Kafka di origine.Sostituisci
target_kafka_usernameetarget_kafka_passwordcon le credenziali per il cluster Managed Service per Apache Kafka di destinazione. Per configurare il nome utente e la password, consulta Autenticazione SASL/PLAIN.Le impostazioni
topics = .\*egroups = .\*replicano tutti gli argomenti e i gruppi di consumatori. Se necessario, puoi modificare queste impostazioni per renderle più specifiche.L'impostazione
offset.syncs.topic.replication.factor = 3imposta il fattore di replica per l'argomento interno utilizzato da MirrorMaker 2.0 per sincronizzare gli offset dei consumer tra i cluster di origine e di destinazione. Un fattore di replica di3significa che i dati di offset vengono replicati in tre broker nel cluster di destinazione, garantendo una maggiore disponibilità e tolleranza agli errori.L'impostazione
checkpoints.topic.replication.factor = 3imposta il fattore di replica per un altro argomento interno utilizzato da MirrorMaker 2.0 per archiviare i checkpoint. I checkpoint aiutano MirrorMaker 2.0 a monitorare i progressi e a riprendere la replica dal punto corretto in caso di errori o riavvii.L'impostazione
heartbeats.topic.replication.factor = 3imposta il fattore di replica per l'argomento interno utilizzato da MirrorMaker 2.0 per inviare heartbeat. Gli heartbeat indicano che il processo MirrorMaker 2.0 è attivo. Un fattore di replica più elevato garantisce che questi heartbeat vengano archiviati in modo affidabile e possano essere utilizzati per monitorare l'integrità del processo di replica.L'impostazione
emit.checkpoints.interval.seconds = 10controlla la frequenza con cui MirrorMaker 2.0 emette i checkpoint. In questo caso, i checkpoint vengono emessi ogni 10 secondi. Questa frequenza offre un equilibrio tra il monitoraggio dei progressi e la riduzione al minimo dell'overhead della scrittura dei checkpoint.
Avvia MirrorMaker 2.0. Utilizza lo script
connect-mirror-maker.shper avviare la procedura.Lo script avvia MirrorMaker 2.0 in modalità standalone e inizia a replicare i dati dal cluster Kafka di origine al cluster Managed Service per Apache Kafka.
Considerazioni aggiuntive:
Networking: assicurati che la tua Google Cloud VM abbia connettività di rete sia al cluster Kafka di origine sia al cluster Managed Service per Apache Kafka di destinazione. Se il cluster di origine è on-premise, potrebbe essere necessario configurare la VPN o Interconnect.
Sicurezza: configura protocolli di sicurezza e regole firewall appropriati per proteggere l'istanza di MirrorMaker 2.0 e i cluster Kafka.
Se segui questi passaggi, puoi installare e configurare correttamente MirrorMaker 2.0 in modalità cluster standalone su una VM Google Cloud per facilitare la migrazione dei dati Kafka a Managed Service per Apache Kafka.
Monitoraggio
Monitora il processo MirrorMaker 2.0 per assicurarti che venga eseguito correttamente e che i dati vengano replicati come previsto. Puoi utilizzare le metriche integrate di MirrorMaker 2 o altri strumenti di monitoraggio. Dopo aver eseguito la migrazione delle applicazioni, monitora quanto segue per convalidare la riuscita dell'operazione:
Tassi di velocità effettiva downstream: assicurati che non vi siano variazioni significative nei tassi di velocità effettiva downstream. Ad esempio, se utilizzi Dataflow a valle, il throughput e le metriche correlate a Kafka devono rimanere coerenti.
Utilizzo di CPU e memoria: monitora l'utilizzo di CPU e memoria del tuo cluster Managed Service per Apache Kafka utilizzando Cloud Monitoring. Idealmente, l'utilizzo deve rimanere inferiore al 75% per garantire un rendimento ottimale.
Log degli errori: controlla regolarmente Cloud Logging per eventuali log degli errori relativi al tuo cluster Managed Service per Apache Kafka o alle tue applicazioni. Correggi tempestivamente gli errori per evitare interruzioni.
Limitazioni
- MirrorMaker 2.0 richiede che il cluster Apache Kafka di origine sia la versione 2.4.0 o successive.