
Dokumen ini membantu Anda memigrasikan workload Apache Kafka ke Google Cloud Managed Service for Apache Kafka, yang merupakan layanan terkelola dalam Google Cloud.
Managed Service for Apache Kafka membantu Anda menjalankan Apache Kafka di Google Cloud. Dalam solusi yang didokumentasikan ini, Anda memindahkan data dari cluster Apache Kafka eksternal ke cluster Managed Service for Apache Kafka.
Untuk mengetahui informasi selengkapnya tentang Managed Service for Apache Kafka, lihat Ringkasan Managed Service for Apache Kafka.
Sebaiknya gunakan MirrorMaker 2.0 Apache Kafka untuk migrasi ini.
MirrorMaker 2.0 adalah alat untuk mereplikasi data antara cluster Apache Kafka secara real time. Layanan ini dapat digunakan untuk migrasi data, pemulihan dari bencana, isolasi data, dan agregasi data.
Untuk mengetahui informasi selengkapnya tentang MirrorMaker 2.0, lihat bagian berikutnya.
Apa itu MirrorMaker 2.0
MirrorMaker 2.0 menggunakan framework Kafka Connect untuk mereplikasi data antar-cluster Kafka. Kafka Connect adalah framework untuk men-streaming data antara cluster Kafka dan sistem lainnya. Pipeline ini berfungsi sebagai pipeline yang skalabel dan andal. Framework ini menyederhanakan integrasi Kafka dengan berbagai sistem eksternal, seperti database, antrean pesan, dan penyimpanan online, melalui penggunaan konektor yang tersedia. Berikut adalah daftar kemungkinan skenario saat Anda dapat menggunakan MirrorMaker 2.0:
Migrasi data: Pindahkan workload Kafka Anda ke cluster baru, seperti yang ditunjukkan dalam panduan ini.
Pemulihan dari bencana: Buat cluster cadangan untuk memastikan kelangsungan bisnis jika terjadi kegagalan.
Isolasi data: Mereplikasi topik secara selektif ke cluster publik sambil menjaga keamanan data sensitif di cluster pribadi.
Agregasi data: Gabungkan data dari beberapa cluster Kafka ke dalam cluster pusat untuk tujuan analisis.
MirrorMaker 2.0 mendukung Kafka versi 2.4.0 dan yang lebih tinggi, yang menawarkan fitur utama berikut:
Replikasi komprehensif: Mereplikasi semua komponen yang diperlukan, termasuk topik, data, dan konfigurasi, grup konsumen dengan offset, dan ACL.
Mempertahankan partisi: Mempertahankan skema partisi yang sama di cluster target, sehingga menyederhanakan transisi untuk aplikasi.
Pembuatan topik dan partisi otomatis: Secara otomatis mendeteksi dan mereplikasi topik dan partisi baru, sehingga meminimalkan konfigurasi manual.
Kemampuan pemantauan: Menyediakan metrik penting seperti latensi replikasi end-to-end, sehingga Anda dapat melacak kondisi dan performa proses replikasi.
Fault tolerance dan skalabilitas: Memastikan operasi yang andal meskipun dengan volume data yang tinggi dan dapat diskalakan secara horizontal untuk menangani peningkatan workload.
Topik internal untuk keandalan: Menggunakan topik internal untuk sinkronisasi offset, titik pemeriksaan, dan sinyal detak jantung. Topik ini memiliki faktor replikasi yang dapat dikonfigurasi seperti
offset.syncs.topic.replication.factoruntuk memastikan ketersediaan tinggi dan fault tolerance.
MirrorMaker 2.0 menawarkan dua mode deployment:
Mode cluster khusus: MirrorMaker 2.0 berjalan sebagai cluster mandiri, mengelola pekerja sendiri. Dokumen ini berfokus pada mode ini, dengan memberikan contoh praktis deployment dan konfigurasinya.
Mode cluster Kafka Connect: MirrorMaker 2.0 berjalan sebagai konektor dalam cluster Kafka Connect yang ada.
Alur kerja tingkat tinggi
Diagram berikut menggambarkan arsitektur untuk memigrasikan data dari cluster Apache Kafka sumber ke cluster Managed Service untuk Apache Kafka menggunakan MirrorMaker 2.0.
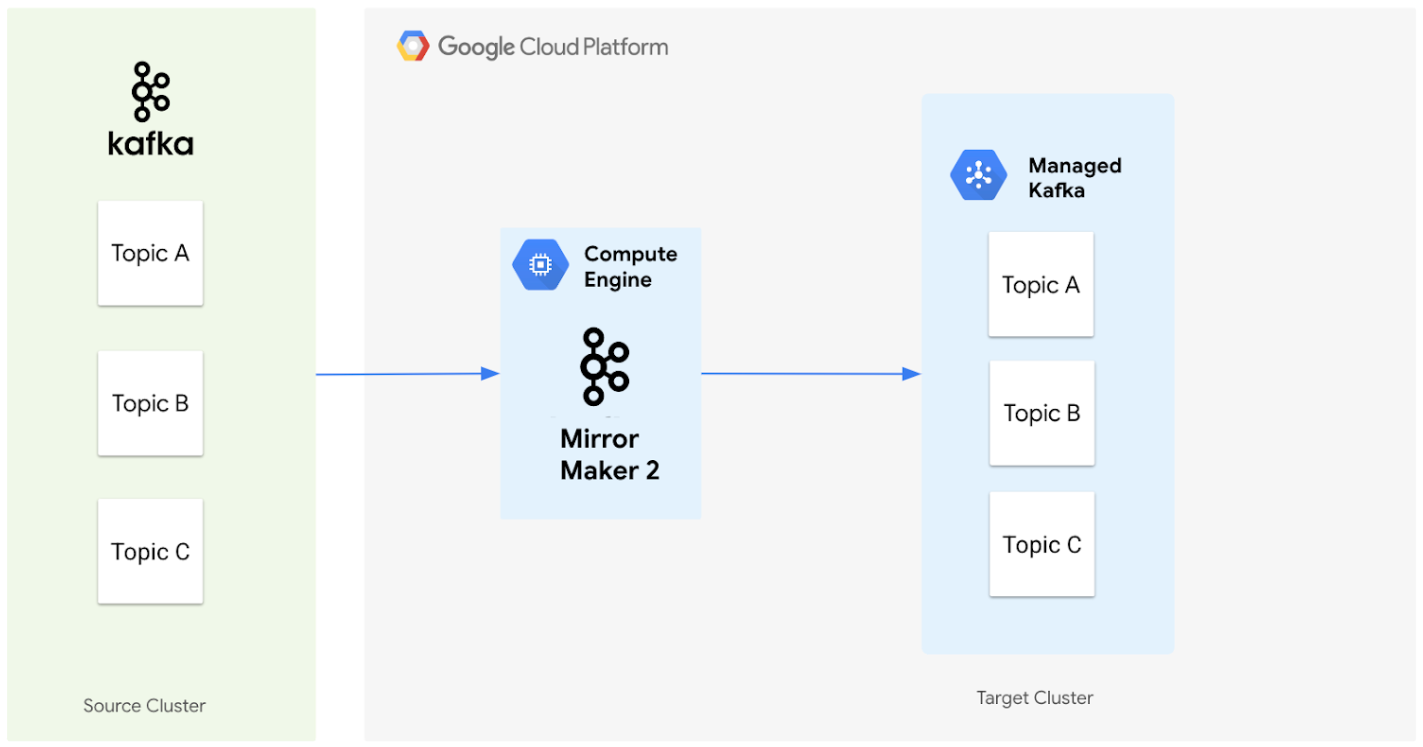
Berikut cara kerja komponen-komponen tersebut:
Cluster sumber: Ini mewakili cluster Apache Kafka yang sudah ada, yang dapat berada di lokal atau di lingkungan cloud lain. Berisi topik yang ingin Anda migrasikan. Dalam diagram ini, cluster Apache Kafka sumber berisi tiga topik, yaitu Topic A, B, dan C.
MirrorMaker 2.0: Komponen inti ini, yang di-deploy di VM Compute Engine sebagai cluster MirrorMaker 2.0 khusus, secara aktif mereplikasi data dari cluster Apache Kafka sumber ke cluster Managed Service untuk Apache Kafka target. Yang penting, fitur ini juga otomatis membuat topik dan partisi yang sesuai di cluster target jika belum ada, sehingga mencerminkan penyiapan cluster sumber.
Target cluster: Ini adalah cluster Managed Service for Apache Kafka Anda. Cluster ini menjadi lokasi baru untuk data Kafka Anda, dengan MirrorMaker 2.0 yang memastikan topik dan partisi dibuat agar sesuai dengan lingkungan sumber Anda.
Berikut adalah alur kerja tingkat tinggi untuk proses migrasi.
Penilaian awal
Dokumentasikan penyiapan Kafka yang ada, termasuk ukuran cluster, topik, throughput, dan grup konsumen.
Rencanakan sasaran dan strategi migrasi Anda, termasuk toleransi periode nonaktif dan pendekatan peralihan.
Perkirakan resource yang diperlukan untuk cluster Managed Service for Apache Kafka Anda.
Persiapan
Buat cluster Managed Service for Apache Kafka.
Konfigurasi konektivitas jaringan antara cluster Kafka yang sudah ada dan cluster Managed Service for Apache Kafka yang baru saja Anda buat.
Deploy MirrorMaker 2.0 di VM Google Cloud .
Eksekusi migrasi
Konfigurasi MirrorMaker 2.0 untuk mereplikasi data dari cluster Kafka yang ada ke cluster Managed Service for Apache Kafka.
Pantau proses replikasi menggunakan metrik MirrorMaker 2.0.
Migrasikan konsumen dan produsen secara bertahap ke cluster Managed Service for Apache Kafka yang baru.
Validasi dan pengalihan
Validasi integritas data dan fitur aplikasi di cluster Managed Service untuk Apache Kafka.
Lakukan pengalihan akhir, dengan mengalihkan traffic ke cluster Managed Service for Apache Kafka.
Nonaktifkan cluster Kafka lama Anda.
Setelah migrasi
Pantau terus performa cluster Managed Service for Apache Kafka Anda.
Tinjau dan perbarui dokumentasi untuk mencerminkan perubahan.
Meminimalkan waktu non-operasional migrasi
Bagian ini menguraikan beberapa pertimbangan untuk memigrasikan data Kafka open source ke Managed Service for Apache Kafka menggunakan MirrorMaker 2.0. MirrorMaker 2.0 memfasilitasi replikasi data dan offset yang memungkinkan konsumen melanjutkan dari titik yang benar di cluster baru. Namun, perencanaan yang matang sangat penting untuk meminimalkan periode nonaktif selama proses migrasi. Pertimbangkan strategi berikut:
Deployment paralel: Untuk meminimalkan waktu henti saat beralih ke cluster Managed Service for Apache Kafka yang baru, Anda dapat menjalankan instance paralel aplikasi di cluster lama dan baru. Selama transisi ini, nonaktifkan sementara tindakan apa pun di aplikasi Anda yang hanya boleh terjadi satu kali per pesan, seperti mengirim notifikasi. Nonaktifkan efek samping ini untuk mencegah konsekuensi yang tidak diinginkan akibat memproses pesan yang sama dua kali. Setelah instance baru sepenuhnya siap, alihkan semua traffic ke cluster baru dan aktifkan kembali semua fitur.
Peluncuran bertahap: Lakukan migrasi dalam fase yang lebih kecil dan mudah dikelola, dimulai dengan aplikasi yang kurang penting. Pendekatan ini membantu mengisolasi potensi masalah dan meminimalkan dampak gangguan.
Deployment biru dan hijau: Buat replika lengkap lingkungan produksi (hijau) bersama dengan lingkungan yang ada (biru). Alihkan traffic secara bertahap dari biru ke hijau, sehingga memungkinkan pengujian dan validasi sebelum pengalihan akhir. Pendekatan ini meminimalkan periode nonaktif, tetapi memerlukan peningkatan penggunaan resource.
Persyaratan pemrosesan pesan: Pahami toleransi aplikasi Anda terhadap pesan duplikat atau yang hilang dan konfigurasi konsumen yang sesuai. MirrorMaker 2.0 menawarkan konfigurasi untuk menangani semantik pengiriman pesan. Misalnya,
sync.group.offsets.enabledmendukung sinkronisasi offset konsumen. Konsumen dapat menggunakan offset yang disinkronkan untuk melanjutkan membaca dari tempat mereka berhenti di cluster sumber. Tindakan ini dapat mencegah hilangnya pesan atau mencegah penerimaan terlalu banyak duplikat.Komunikasi dan koordinasi: Komunikasi yang efektif dengan tim aplikasi sangat penting untuk kelancaran migrasi. Bangun saluran komunikasi yang jelas dan koordinasikan waktu peralihan.
Menghubungkan Apache Kafka lokal ke Google Cloud
Jika cluster Apache Kafka sumber Anda berada di lokal, Anda harus membuat koneksi yang aman antara jaringan lokal dan Virtual Private Cloud (VPC) tempat cluster Managed Service for Apache Kafka berada. Gunakan salah satu opsi berikut dari Google Cloud.
Cloud VPN: Solusi hemat biaya yang cocok untuk kebutuhan bandwidth yang lebih rendah atau eksperimen migrasi awal. Fitur ini membuat tunnel terenkripsi melalui internet publik. Untuk mengetahui informasi selengkapnya tentang Cloud VPN, lihat Ringkasan Cloud VPN.
Cloud Interconnect: Menyediakan koneksi bandwidth tinggi khusus antara jaringan lokal Anda dan Google Cloud. Hal ini ideal untuk deployment tingkat perusahaan yang memerlukan throughput lebih tinggi dan latensi lebih rendah. Anda dapat memilih antara Dedicated Interconnect (untuk koneksi fisik langsung) atau Partner Interconnect (koneksi melalui penyedia layanan yang didukung). Untuk mengetahui informasi selengkapnya tentang dokumentasi Interconnect, lihat Ringkasan Cloud Interconnect. Google Cloud
Saat membuat cluster Managed Service for Apache Kafka, Anda harus memilih setidaknya satu subnet di VPC Anda. Subnet ini menyediakan alamat IP yang digunakan cluster Anda untuk berkomunikasi dengan resource lain di VPC Anda, sehingga membuat cluster dapat diakses dalam jaringan VPC Anda.
Untuk terhubung dengan aman ke cluster Managed Service for Apache Kafka dari jaringan lokal atau jaringan VPC lainnya, Anda dapat menggunakan Private Service Connect (PSC) melalui Cloud VPN atau Cloud Interconnect. Anda tidak perlu menyiapkan endpoint PSC secara eksplisit. Saat Anda memilih subnet selama pembuatan cluster, layanan Managed Service for Apache Kafka akan otomatis membuat endpoint PSC yang diperlukan. Hal ini menyederhanakan konfigurasi jaringan dengan memungkinkan Anda mengakses cluster menggunakan alamat IP internal dalam VPC, tanpa perlu mengelola aturan firewall yang rumit atau alamat IP publik.
Untuk mengetahui informasi selengkapnya tentang penyiapan jaringan untuk Managed Service for Apache Kafka, lihat Jaringan untuk Managed Service for Apache Kafka.
Sebelum memulai
Sebelum memulai pembuatan konfigurasi migrasi, Anda harus mendokumentasikan konfigurasi Apache Kafka saat ini. Anda memerlukan hal ini agar dapat menghitung resource, seperti vCPU, memori, dan penyimpanan, yang diperlukan untuk cluster Managed Service for Apache Kafka yang baru. Kumpulkan informasi berikut tentang lingkungan Apache Kafka sumber Anda:
Pastikan versi Apache Kafka adalah 2.4.0 atau yang lebih tinggi.
Untuk memeriksa versi cluster Apache Kafka Anda, buka direktori penginstalan Kafka Anda dan jalankan perintah
bin/kafka-topics.sh --versionIdentifikasi cluster dan topik yang perlu dimigrasikan.
Identifikasi produsen dan konsumen yang terkait dengan setiap topik.
Identifikasi semua grup konsumen.
Tentukan throughput pesan di tingkat cluster dan topik.
Tentukan faktor replikasi untuk cluster dan topik Anda.
Mendokumentasikan konfigurasi konsumen, terutama protokol keamanan dan integrasi apa pun dengan layanan Google Cloud lainnya.
Untuk menghindari gangguan selama migrasi, petakan semua dependensi aplikasi yang terkait dengan cluster Kafka sumber Anda. Sebelum memigrasikan lingkungan produksi, lakukan migrasi pengujian menggunakan cluster non-kritis di lingkungan pengembangan. Validasi proses dan identifikasi potensi masalah. Terakhir, buat rencana rollback yang komprehensif untuk kembali ke cluster asli jika diperlukan.
Menghitung ukuran cluster tujuan
Untuk memperkirakan jumlah vCPU dan ukuran memori yang diperlukan untuk cluster Managed Service for Apache Kafka, lihat Merencanakan ukuran cluster Kafka. Konfigurasi disk dan broker bersifat otomatis dan tidak dapat disesuaikan.
Kafka open source menyediakan metrik JMX. Untuk menghitung secara akurat ukuran cluster yang diperlukan untuk Managed Service for Apache Kafka, Anda dapat menggunakan metrik JMX berikut. Metrik ini dilaporkan di tingkat broker. Anda harus menggabungkan data di semua broker untuk menghitung throughput cluster.
kafka.server:type=BrokerTopicMetrics,name=BytesInPerSec: Metrik ini melaporkan kecepatan byte masuk dari klien di semua topik. Hilangkan parametertopic={...}untuk mendapatkan tarif gabungan untuk semua topik.kafka.server:type=BrokerTopicMetrics,name=BytesOutPerSec: Metrik ini melaporkan kecepatan byte keluar ke klien di semua topik. Hilangkan parametertopic={...}untuk mendapatkan keseluruhan rasio.
Dengan memantau metrik JMX ini selama jangka waktu tertentu, Anda dapat mengumpulkan titik data untuk menghitung hal berikut:
Data Masuk Rata-Rata, MB/s: Metrik ini menunjukkan kecepatan rata-rata data yang dimasukkan ke dalam cluster Kafka.
Data Masuk Puncak, MB/s: Metrik ini menunjukkan kecepatan tertinggi saat data dimasukkan ke dalam cluster Kafka.
Rata-Rata Data Keluar, MB/s: Metrik ini menunjukkan rata-rata kecepatan data yang digunakan dari cluster Kafka.
Data Keluar Puncak, MB/s: Metrik ini menunjukkan kecepatan tertinggi saat data digunakan dari cluster Kafka.
Beberapa perhitungan metrik mungkin diperlukan untuk menggabungkan data dan mengonversi byte ke MB. Dengan menggunakan nilai yang dihitung ini, Anda dapat memperkirakan rasio setara penulisan sebagai berikut:
Write-equivalent rate (Avg/Peak) = (total write bandwidth) + (total read bandwidth / 4)
Tingkat setara penulisan ini membantu menentukan beban penulisan keseluruhan pada cluster, yang diperlukan untuk menentukan ukuran cluster Managed Service for Apache Kafka dengan tepat.
Membuat cluster Managed Service for Apache Kafka
Cluster Managed Service untuk Apache Kafka berada di Google Cloud project dan region tertentu. Endpoint ini dapat diakses menggunakan serangkaian alamat IP dalam satu atau beberapa subnet di Virtual Private Cloud (VPC) mana pun.
Ukuran cluster ditentukan oleh jumlah CPU dan total RAM yang Anda alokasikan untuk cluster tersebut. Dalam hal ini, ukuran cluster harus sama dengan ukuran cluster Apache Kafka sumber. Untuk mengetahui informasi selengkapnya tentang cara melakukan perhitungan ini, lihat Menghitung ukuran cluster tujuan.
Untuk mendapatkan izin yang diperlukan untuk membuat cluster, minta administrator Anda untuk memberi Anda atau akun layanan yang membuat cluster, peran IAM Managed Kafka Admin (roles/managedkafka.admin) di project Anda. Untuk mengetahui informasi selengkapnya tentang cara memberikan peran, lihat Mengelola akses ke project, folder, dan organisasi.
Untuk membuat cluster Managed Service for Apache Kafka, ikuti petunjuk memulai cepat di Produce and consume messages with the CLI. Pembuatan cluster biasanya memerlukan waktu 20-30 menit.
Menyiapkan MirrorMaker 2.0 dalam mode cluster mandiri
Untuk mengetahui dokumen bukti konsep dan kode contoh yang menunjukkan cara menggunakan MirrorMaker 2.0 dan Terraform untuk mentransfer data Kafka ke Google Cloud, lihat repositori GitHub ini.
Bagian ini memandu Anda menginstal dan mengonfigurasi MirrorMaker 2.0 dalam mode cluster mandiri di Google Cloud VM. Penyiapan ini memungkinkan Anda mereplikasi data dari cluster Apache Kafka yang ada ke cluster Managed Service for Apache Kafka.
Buat VM di jaringan yang sama yang diberi akses ke cluster Managed Service for Apache Kafka. Gunakan perintah gcloud compute instances create.
gcloud compute instances create VM_NAME\ --zone=ZONE\ [--image=IMAGE | --image-family=IMAGE_FAMILY]\ --image-project=IMAGE_PROJECT\ --machine-type=MACHINE_TYPE
Ganti kode berikut:
VM_NAME: nama VM yang ingin Anda buat.ZONE: zona tempat Anda ingin membuat VM.IMAGEatauIMAGE_FAMILY: image atau kelompok image yang ingin Anda gunakan untuk VM.IMAGE_PROJECT: project tempat image berada.MACHINE_TYPE: jenis mesin yang ingin Anda gunakan untuk VM.
Untuk mengakses VM yang baru dibuat, Anda dapat menggunakan SSH.
Untuk mengetahui informasi selengkapnya tentang koneksi SSH, lihat Tentang koneksi SSH.
Untuk mendownload Kafka, lalu mengekstraknya, di jendela terminal VM baru, jalankan perintah berikut:
wget https://downloads.apache.org/kafka/3.7.1/kafka_2.13-3.7.1.tgz tar -xzvf kafka_2.13-3.7.1.tgzDownload Java, ekstrak paket, lalu tetapkan jalur Java.
# Download Java wget https://download.java.net/java/GA/jdk11/9/GPL/openjdk-11.0.2_linux-x64_bin.tar.gz # Extract Java tar -xzvf openjdk-11.0.2_linux-x64_bin.tar.gz # Set Java path export PATH=$PATH:/java/jdk-11.0.2/bin/Edit file
path/to/kafka/config/mm2.propertiesdan perbarui properti berikut:clusters = source, target source.bootstrap.servers = <source_kafka_bootstrap_servers> target.bootstrap.servers = <target_kafka_bootstrap_servers> source.security.protocol = SASL_SSL source.sasl.mechanism = PLAIN source.sasl.jaas.config = org.apache.kafka.common.security.plain.PlainLoginModule required username="<source_kafka_username>" password="<source_kafka_password>"; target.security.protocol = SASL_SSL target.sasl.mechanism = PLAIN target.sasl.jaas.config = org.apache.kafka.common.security.plain.PlainLoginModule required username="<target_kafka_username>" password="<target_kafka_password>"; mirrors = source->target source->target.enabled=true topics = .* groups = .* offset.syncs.topic.replication.factor = 3 checkpoints.topic.replication.factor = 3 heartbeats.topic.replication.factor = 3 emit.checkpoints.interval.seconds = 10Ganti
source_kafka_bootstrap_serversdantarget_kafka_bootstrap_serversdengan alamat server bootstrap cluster Kafka sumber dan target Anda. Anda bisa mendapatkan alamat server bootstrap untuk Managed Service for Apache Kafka menggunakan perintahmanaged-kafka clusters describeGoogle Cloud CLI.Ganti
source_kafka_usernamedansource_kafka_passworddengan kredensial untuk cluster Kafka sumber Anda.Ganti
target_kafka_usernamedantarget_kafka_passworddengan kredensial untuk cluster Managed Service for Apache Kafka target Anda. Untuk mengonfigurasi nama pengguna dan sandi, lihat Autentikasi SASL/PLAIN.Setelan
topics = .\*dangroups = .\*mereplikasi semua topik dan grup konsumen. Anda dapat mengubah setelan ini agar lebih spesifik, jika diperlukan.Setelan
offset.syncs.topic.replication.factor = 3menetapkan faktor replikasi untuk topik internal yang digunakan oleh MirrorMaker 2.0 untuk menyelaraskan offset konsumen antara cluster sumber dan target. Faktor replikasi3berarti data offset direplikasi ke tiga broker di cluster target, sehingga memastikan ketersediaan dan toleransi kesalahan yang lebih tinggi.Setelan
checkpoints.topic.replication.factor = 3menetapkan faktor replikasi untuk topik internal lain yang digunakan oleh MirrorMaker 2.0 untuk menyimpan titik pemeriksaan. Checkpoint membantu MirrorMaker 2.0 melacak progresnya dan melanjutkan replikasi dari titik yang benar jika terjadi kegagalan atau dimulai ulang.Setelan
heartbeats.topic.replication.factor = 3menetapkan faktor replikasi untuk topik internal yang digunakan oleh MirrorMaker 2.0 untuk mengirim sinyal detak jantung. Detak jantung menandakan bahwa proses MirrorMaker 2.0 aktif dan berjalan. Faktor replikasi yang lebih tinggi memastikan bahwa detak jantung ini disimpan dengan andal dan dapat digunakan untuk memantau kondisi proses replikasi.Setelan
emit.checkpoints.interval.seconds = 10mengontrol frekuensi MirrorMaker 2.0 memancarkan titik pemeriksaan. Dalam hal ini, titik pemeriksaan dipancarkan setiap 10 detik. Frekuensi ini memberikan keseimbangan antara melacak progres dan meminimalkan overhead penulisan titik pemeriksaan.
Mulai MirrorMaker 2.0. Gunakan skrip
connect-mirror-maker.shuntuk memulai proses.Skrip memulai MirrorMaker 2.0 dalam mode mandiri, dan mulai mereplikasi data dari cluster Kafka sumber ke cluster Managed Service untuk Apache Kafka.
Pertimbangan tambahan:
Jaringan: Pastikan VM Google Cloud Anda memiliki konektivitas jaringan ke cluster Kafka sumber dan cluster Managed Service for Apache Kafka target. Jika cluster sumber Anda berada di lokal, Anda mungkin perlu mengonfigurasi VPN atau Interconnect.
Keamanan: Konfigurasi protokol keamanan dan aturan firewall yang sesuai untuk mengamankan instance MirrorMaker 2.0 dan cluster Kafka Anda.
Dengan mengikuti langkah-langkah ini, Anda dapat berhasil menginstal dan mengonfigurasi MirrorMaker 2.0 dalam mode cluster mandiri di VM Google Cloud untuk memfasilitasi migrasi data Kafka Anda ke Managed Service for Apache Kafka.
Pemantauan
Pantau proses MirrorMaker 2.0 untuk memastikan proses berjalan dengan benar dan mereplikasi data seperti yang diharapkan. Anda dapat menggunakan metrik bawaan MirrorMaker 2 atau alat pemantauan lainnya. Setelah memigrasikan aplikasi, pantau hal berikut untuk memvalidasi keberhasilan:
Kecepatan throughput downstream: Pastikan tidak ada perubahan signifikan pada kecepatan throughput downstream. Misalnya, jika Anda menggunakan Dataflow di hilir, throughput dan metrik yang terkait dengan Kafka harus tetap konsisten.
Penggunaan CPU dan memori: Pantau penggunaan CPU dan memori cluster Managed Service for Apache Kafka Anda menggunakan Cloud Monitoring. Idealnya, pemanfaatan harus tetap di bawah 75% untuk memastikan performa yang optimal.
Log error: Periksa Cloud Logging secara rutin untuk melihat log error yang terkait dengan cluster Managed Service for Apache Kafka atau aplikasi Anda. Segera atasi error apa pun untuk mencegah gangguan.
Batasan
- MirrorMaker 2.0 mengharuskan cluster Apache Kafka sumber Anda menggunakan versi 2.4.0 atau yang lebih tinggi.