
En este documento, se te ayuda a migrar tus cargas de trabajo de Apache Kafka a Google Cloud Managed Service for Apache Kafka, que es un servicio administrado dentro de Google Cloud.
Managed Service for Apache Kafka te ayuda a ejecutar Apache Kafka en Google Cloud. En esta solución documentada, transfieres datos de un clúster externo de Apache Kafka a un clúster de Managed Service para Apache Kafka.
Para obtener más información sobre Managed Service para Apache Kafka, consulta la descripción general de Managed Service para Apache Kafka.
Te recomendamos que uses MirrorMaker 2.0 de Apache Kafka para esta migración.
MirrorMaker 2.0 es una herramienta para replicar datos entre clústeres de Apache Kafka en tiempo real. Se puede usar para migraciones de datos, recuperación ante desastres, aislamiento de datos y agregación de datos.
Para obtener más información sobre MirrorMaker 2.0, consulta la siguiente sección.
¿Qué es MirrorMaker 2.0?
MirrorMaker 2.0 usa el framework de Kafka Connect para replicar datos entre clústeres de Kafka. Kafka Connect es un framework para transmitir datos entre clústeres de Kafka y otros sistemas. Actúa como una canalización escalable y confiable. Este framework simplifica la integración de Kafka con varios sistemas externos, como bases de datos, colas de mensajes y almacenamiento en línea, a través del uso de conectores disponibles. A continuación, se incluye una lista de posibles situaciones en las que puedes usar MirrorMaker 2.0:
Migraciones de datos: Mueve tu carga de trabajo de Kafka a un clúster nuevo, como se muestra en esta guía.
Recuperación ante desastres: Crea un clúster de copia de seguridad para garantizar la continuidad empresarial en caso de fallas.
Aislamiento de datos: Replica temas de forma selectiva en un clúster público y, al mismo tiempo, mantén seguros los datos sensibles en un clúster privado.
Agregación de datos: Consolida datos de varios clústeres de Kafka en un clúster central para fines analíticos.
MirrorMaker 2.0 admite la versión 2.4.0 de Kafka y versiones posteriores, y ofrece estas funciones clave:
Replicación integral: Replicar todos los componentes necesarios, incluidos los temas, los datos y las configuraciones, los grupos de consumidores con desfases y las ACLs
Conservación de particiones: Mantiene el mismo esquema de partición en el clúster de destino, lo que simplifica la transición para las aplicaciones.
Creación automática de temas y particiones: Detecta y replica automáticamente temas y particiones nuevos, lo que minimiza la configuración manual.
Capacidades de supervisión: Proporciona métricas esenciales, como la latencia de replicación de extremo a extremo, lo que te permite hacer un seguimiento del estado y el rendimiento del proceso de replicación.
Tolerancia a errores y escalabilidad: Garantiza un funcionamiento confiable incluso con grandes volúmenes de datos y se puede escalar horizontalmente para controlar cargas de trabajo cada vez mayores.
Temas internos para la solidez: Utiliza temas internos para la sincronización de compensación, los puntos de control y los latidos. Estos temas tienen factores de replicación configurables, como
offset.syncs.topic.replication.factor, para garantizar la alta disponibilidad y la tolerancia a errores.
MirrorMaker 2.0 ofrece dos modos de implementación:
Modo de clúster dedicado: MirrorMaker 2.0 se ejecuta como un clúster independiente y administra sus propios trabajadores. En este documento, se explica este modo y se proporciona un ejemplo práctico de su implementación y configuración.
Modo de clúster de Kafka Connect: MirrorMaker 2.0 se ejecuta como conectores dentro de un clúster de Kafka Connect existente.
Flujo de trabajo de alto nivel
En el siguiente diagrama, se ilustra la arquitectura para migrar datos de un clúster de Apache Kafka de origen a un clúster de Managed Service para Apache Kafka con MirrorMaker 2.0.
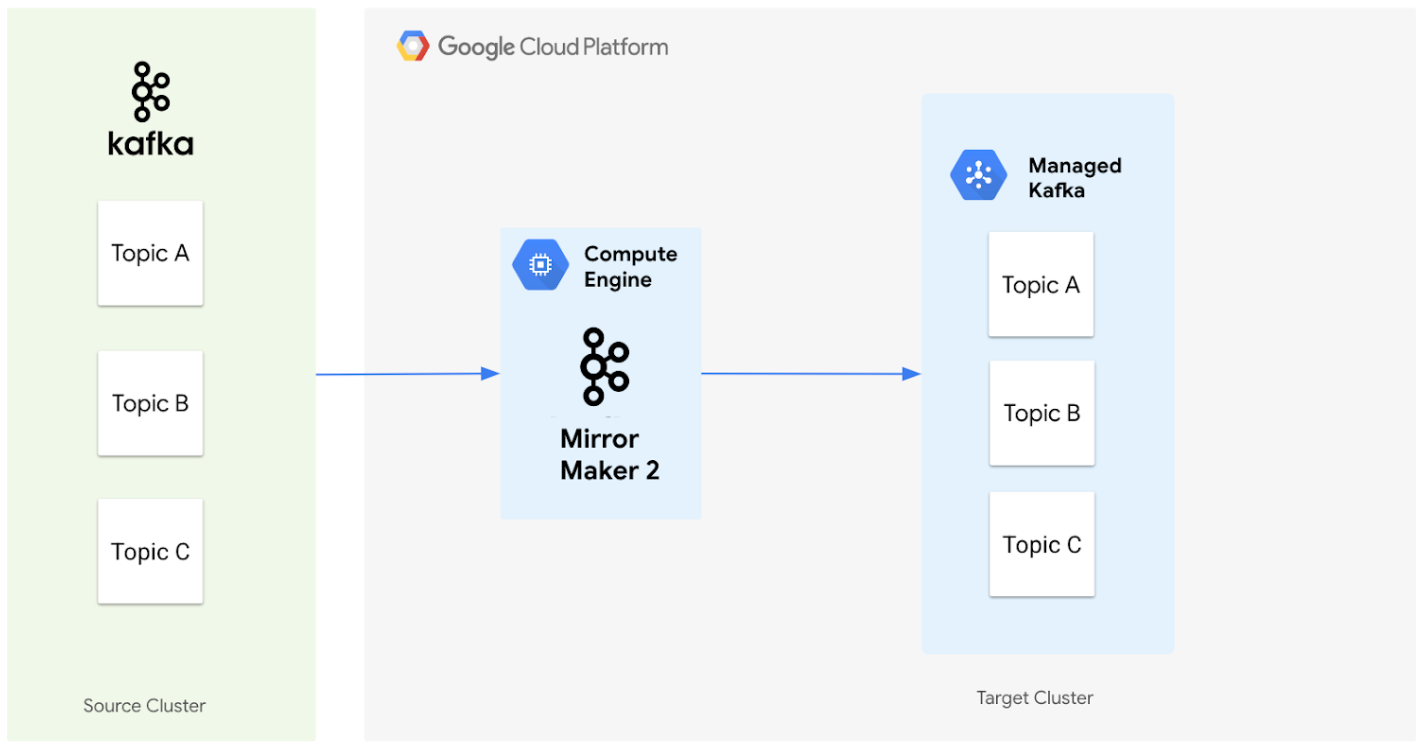
Así es como funcionan juntos los componentes:
Clúster de origen: Representa tu clúster de Apache Kafka existente, que puede estar ubicado de forma local o en otro entorno de nube. Contiene los temas que deseas migrar. En este diagrama, el clúster de Apache Kafka de origen contiene tres temas: A, B y C.
MirrorMaker 2.0: Este componente principal, implementado en una VM de Compute Engine como un clúster dedicado de MirrorMaker 2.0, replica de forma activa los datos del clúster de Apache Kafka de origen al clúster de destino de Managed Service for Apache Kafka. Es importante destacar que también crea automáticamente los temas y las particiones correspondientes en el clúster de destino si no existen, lo que refleja la configuración del clúster de origen.
Clúster de destino: Es tu clúster de Managed Service para Apache Kafka. Se convierte en el nuevo hogar de tus datos de Kafka, y MirrorMaker 2.0 garantiza que los temas y las particiones se creen para que coincidan con tu entorno de origen.
A continuación, se muestra un flujo de trabajo general para el proceso de migración.
Evaluación inicial
Documenta tu configuración existente de Kafka, incluidos el tamaño del clúster, los temas, la capacidad de procesamiento y los grupos de consumidores.
Planifica tus objetivos y estrategia de migración, incluida la tolerancia al tiempo de inactividad y el enfoque de corte.
Estima los recursos necesarios para tu clúster de Managed Service para Apache Kafka.
Preparación
Crea un clúster de Managed Service para Apache Kafka.
Configura la conectividad de red entre tu clúster de Kafka existente y el clúster de Managed Service para Apache Kafka que acabas de crear.
Implementa MirrorMaker 2.0 en una VM de Google Cloud .
Ejecución de la migración
Configura MirrorMaker 2.0 para replicar datos de tu clúster de Kafka existente al clúster de Managed Service para Apache Kafka.
Supervisa el proceso de replicación con las métricas de MirrorMaker 2.0.
Migra gradualmente los consumidores y productores al nuevo clúster de Managed Service for Apache Kafka.
Validación y migración
Valida la integridad de los datos y las funciones de la aplicación en el clúster de Managed Service para Apache Kafka.
Realiza el corte final y redirecciona el tráfico al clúster de Managed Service para Apache Kafka.
Retira tu clúster de Kafka anterior.
Después de la migración
Supervisa de forma continua el rendimiento de tu clúster de Managed Service para Apache Kafka.
Revisar y actualizar la documentación para reflejar los cambios
Minimiza el tiempo de inactividad de la migración
En esta sección, se describen algunas consideraciones para migrar tus datos de Kafka de código abierto a Managed Service para Apache Kafka con MirrorMaker 2.0. MirrorMaker 2.0 facilita la replicación de datos y de desplazamiento, lo que permite a los consumidores reanudar la actividad desde el punto correcto en el nuevo clúster. Sin embargo, es fundamental planificar cuidadosamente para minimizar el tiempo de inactividad durante el proceso de migración. Considera las siguientes estrategias:
Implementaciones paralelas: Para minimizar el tiempo de inactividad cuando cambies al nuevo clúster de Managed Service para Apache Kafka, puedes ejecutar instancias paralelas de tus aplicaciones en los clústeres antiguos y nuevos. Durante esta transición, inhabilita temporalmente las acciones de tu aplicación que deben ocurrir solo una vez por mensaje, como el envío de una notificación. Inhabilita estos efectos secundarios para evitar consecuencias no deseadas por procesar el mismo mensaje dos veces. Una vez que las instancias nuevas se hayan actualizado por completo, redirecciona todo el tráfico al clúster nuevo y vuelve a habilitar todas las funciones.
Lanzamientos por fases: Migra en fases más pequeñas y manejables, comenzando con las aplicaciones menos críticas. Este enfoque ayuda a aislar los posibles problemas y minimiza el impacto de las interrupciones.
Implementaciones azul y verde: Crea una réplica completa de tu entorno de producción (verde) junto con el existente (azul). Cambia el tráfico de azul a verde de forma gradual, lo que permite realizar pruebas y validaciones antes del corte final. Este enfoque minimiza el tiempo de inactividad, pero requiere un mayor uso de recursos.
Requisitos de procesamiento de mensajes: Comprende la tolerancia de tu aplicación a los mensajes duplicados o faltantes, y configura los consumidores según corresponda. MirrorMaker 2.0 ofrece configuraciones para controlar la semántica de entrega de mensajes. Por ejemplo,
sync.group.offsets.enabledadmite la sincronización de la compensación del consumidor. Los consumidores pueden usar los desplazamientos sincronizados para reanudar la lectura desde donde la habían dejado en el clúster de origen. De esta manera, se puede evitar la pérdida de mensajes o la recepción de demasiados duplicados.Comunicación y coordinación: La comunicación eficaz con los equipos de aplicaciones es fundamental para una migración sin problemas. Establece canales de comunicación claros y coordina los tiempos de cambio.
Conecta Apache Kafka local a Google Cloud
Si tu clúster de Apache Kafka de origen se encuentra en las instalaciones, deberás establecer una conexión segura entre tu red local y tu nube privada virtual (VPC) en la que reside tu clúster de Managed Service para Apache Kafka. Usa una de las siguientes opciones de Google Cloud.
Cloud VPN: Es una solución rentable adecuada para necesidades de menor ancho de banda o experimentos de migración iniciales. Crea un túnel encriptado a través de Internet pública. Para obtener más información sobre Cloud VPN, consulta la descripción general de Cloud VPN.
Cloud Interconnect: Proporciona una conexión dedicada de gran ancho de banda entre tu red local y Google Cloud. Esto es ideal para implementaciones de nivel empresarial que requieren mayor capacidad de procesamiento y menor latencia. Puedes elegir entre la interconexión dedicada (para una conexión física directa) o la interconexión de socio (conexión a través de un proveedor de servicios compatible). Para obtener más información sobre la documentación de Google CloudInterconnect, consulta la descripción general de Cloud Interconnect.
Cuando creas un clúster de Managed Service para Apache Kafka, debes seleccionar al menos una subred en tu VPC. Esta subred proporciona las direcciones IP que usa tu clúster para comunicarse con otros recursos de tu VPC, lo que hace que el clúster sea accesible dentro de tu red de VPC.
Para conectarte de forma segura a tu clúster de Managed Service for Apache Kafka desde redes locales o desde otras redes de VPC, puedes usar Private Service Connect (PSC) a través de Cloud VPN o Cloud Interconnect. No es necesario que configures explícitamente los extremos de PSC. Cuando seleccionas una subred durante la creación del clúster, el servicio de Managed Service para Apache Kafka crea automáticamente los extremos de PSC necesarios. Esto simplifica la configuración de la red, ya que te permite acceder a tu clúster con direcciones IP internas dentro de tu VPC, sin necesidad de administrar reglas de firewall complejas ni direcciones IP públicas.
Para obtener más información sobre la configuración de redes de Managed Service para Apache Kafka, consulta Redes para Managed Service para Apache Kafka.
Antes de comenzar
Antes de comenzar a crear la configuración de migración, debes documentar tu configuración actual de Apache Kafka. Necesitas esta información para calcular los recursos, como las CPU virtuales, la memoria y el almacenamiento, que requiere tu nuevo clúster de Managed Service para Apache Kafka. Recopila la siguiente información sobre tu entorno de Apache Kafka de origen:
Asegúrate de que la versión de Apache Kafka sea 2.4.0 o posterior.
Para verificar la versión de tu clúster de Apache Kafka, navega al directorio de instalación de Kafka y ejecuta el comando
bin/kafka-topics.sh --version.Identifica los clústeres y los temas que se deben migrar.
Identifica los productores y consumidores asociados con cada tema.
Identifica todos los grupos de consumidores.
Determina la capacidad de procesamiento de mensajes a nivel del clúster y del tema.
Determina el factor de replicación para tus clústeres y temas.
Documenta las configuraciones del consumidor, en especial los protocolos de seguridad y cualquier integración con otros servicios de Google Cloud .
Para evitar interrupciones durante la migración, traza un mapa de todas las dependencias de la aplicación relacionadas con tu clúster de Kafka de origen. Antes de migrar tu entorno de producción, realiza una migración de prueba con un clúster no crítico en un entorno de desarrollo. Valida el proceso e identifica cualquier problema potencial. Por último, crea un plan de reversión integral para volver a tu clúster original si es necesario.
Cómo calcular el tamaño del clúster de destino
Para estimar la cantidad de CPU virtuales y el tamaño de la memoria que se requieren para tu clúster de Servicio administrado para Apache Kafka, consulta Planifica el tamaño de tu clúster de Kafka. La configuración del disco y del agente es automática y no se puede ajustar.
Kafka de código abierto proporciona métricas de JMX. Para calcular con precisión el tamaño del clúster requerido para tu servicio administrado para Apache Kafka, puedes usar las siguientes métricas de JMX. Estas métricas se informan a nivel del agente. Debes agregar los datos de todos los intermediarios para calcular el rendimiento del clúster.
kafka.server:type=BrokerTopicMetrics,name=BytesInPerSec: Esta métrica informa la tasa de bytes entrantes de los clientes en todos los temas. Omite el parámetrotopic={...}para obtener la tasa agregada de todos los temas.kafka.server:type=BrokerTopicMetrics,name=BytesOutPerSec: Esta métrica informa la tasa de bytes salientes a los clientes en todos los temas. Omite el parámetrotopic={...}para obtener la tasa general.
Si supervisas estas métricas de JMX durante un período, puedes recopilar puntos de datos para calcular lo siguiente:
Promedio de datos entrantes, MB/s: Esta métrica representa la tasa promedio a la que se transfieren datos al clúster de Kafka.
Peak Data In, MB/s: Esta métrica representa la tasa más alta a la que se transfieren datos al clúster de Kafka.
Promedio de datos salientes, MB/s: Esta métrica representa la tasa promedio a la que se consumen los datos del clúster de Kafka.
Peak Data Out, MB/s: Esta métrica representa la tasa más alta a la que se consumen datos del clúster de Kafka.
Es posible que se necesiten algunas operaciones matemáticas de métricas para agregar los datos y convertir los bytes en MB. Con estos valores calculados, puedes estimar la tasa equivalente de escritura de la siguiente manera:
Write-equivalent rate (Avg/Peak) = (total write bandwidth) + (total read bandwidth / 4)
Esta tasa equivalente de escritura ayuda a determinar la carga de escritura general en el clúster, lo que se requiere para dimensionar tu clúster de Managed Service para Apache Kafka de forma adecuada.
Crea un clúster de Managed Service para Apache Kafka
Un clúster de Managed Service para Apache Kafka se encuentra en unGoogle Cloud proyecto y una región específicos. Se puede acceder a ella con un conjunto de direcciones IP dentro de una o más subredes en cualquier nube privada virtual (VPC).
El tamaño del clúster se determina según la cantidad de CPU y la RAM total que le asignes. En este caso, el tamaño del clúster debe reflejar el tamaño del clúster de Apache Kafka de origen. Para obtener más información sobre cómo realizar este cálculo, consulta Cómo calcular el tamaño del clúster de destino.
Para obtener los permisos que necesitas para crear un clúster, pídele a tu administrador que te otorgue a ti o a la cuenta de servicio que crea el clúster el rol de IAM de Administrador de Kafka administrado (roles/managedkafka.admin) en tu proyecto. Para obtener más información sobre cómo otorgar roles, consulta Administra el acceso a proyectos, carpetas y organizaciones.
Para crear un clúster de Managed Service para Apache Kafka, sigue las instrucciones de la guía de inicio rápido en Produce and consume messages with the CLI. Por lo general, la creación de un clúster tarda entre 20 y 30 minutos.
Configura MirrorMaker 2.0 en modo de clúster independiente
Para ver un documento de prueba de concepto y un código de muestra que muestran cómo usar MirrorMaker 2.0 y Terraform para transferir datos de Kafka a Google Cloud, consulta este repositorio de GitHub.
En esta sección, se explica cómo instalar y configurar MirrorMaker 2.0 en un modo de clúster independiente en una VM de Google Cloud . Esta configuración te permite replicar datos de tu clúster de Apache Kafka existente a un clúster de Managed Service para Apache Kafka.
Crea una VM en la misma red a la que se otorgó acceso al clúster de Managed Service para Apache Kafka. Usa el comando gcloud compute instances create.
gcloud compute instances create VM_NAME\ --zone=ZONE\ [--image=IMAGE | --image-family=IMAGE_FAMILY]\ --image-project=IMAGE_PROJECT\ --machine-type=MACHINE_TYPE
Reemplaza lo siguiente:
VM_NAME: Es el nombre de la VM que deseas crear.ZONE: La zona donde deseas crear la VM.IMAGEoIMAGE_FAMILY: La imagen o la familia de imágenes que deseas usar para la VM.IMAGE_PROJECT: Es el proyecto en el que se encuentra la imagen.MACHINE_TYPE: Es el tipo de máquina que deseas usar para la VM.
Para acceder a la VM que acabas de crear, puedes usar SSH.
Para obtener más información sobre las conexiones SSH, consulta Acerca de las conexiones SSH.
Para descargar Kafka y, luego, extraerlo, ejecuta los siguientes comandos en la ventana de la terminal de la nueva VM:
wget https://downloads.apache.org/kafka/3.7.1/kafka_2.13-3.7.1.tgz tar -xzvf kafka_2.13-3.7.1.tgzDescarga Java, extrae el paquete y, luego, configura la ruta de acceso de Java.
# Download Java wget https://download.java.net/java/GA/jdk11/9/GPL/openjdk-11.0.2_linux-x64_bin.tar.gz # Extract Java tar -xzvf openjdk-11.0.2_linux-x64_bin.tar.gz # Set Java path export PATH=$PATH:/java/jdk-11.0.2/bin/Edita el archivo
path/to/kafka/config/mm2.propertiesy actualiza las siguientes propiedades:clusters = source, target source.bootstrap.servers = <source_kafka_bootstrap_servers> target.bootstrap.servers = <target_kafka_bootstrap_servers> source.security.protocol = SASL_SSL source.sasl.mechanism = PLAIN source.sasl.jaas.config = org.apache.kafka.common.security.plain.PlainLoginModule required username="<source_kafka_username>" password="<source_kafka_password>"; target.security.protocol = SASL_SSL target.sasl.mechanism = PLAIN target.sasl.jaas.config = org.apache.kafka.common.security.plain.PlainLoginModule required username="<target_kafka_username>" password="<target_kafka_password>"; mirrors = source->target source->target.enabled=true topics = .* groups = .* offset.syncs.topic.replication.factor = 3 checkpoints.topic.replication.factor = 3 heartbeats.topic.replication.factor = 3 emit.checkpoints.interval.seconds = 10Reemplaza
source_kafka_bootstrap_serversytarget_kafka_bootstrap_serverspor las direcciones del servidor de arranque de tus clústeres de Kafka de origen y destino, respectivamente. Puedes obtener la dirección del servidor de arranque para Managed Service para Apache Kafka con el comandomanaged-kafka clusters describede Google Cloud CLI.Reemplaza
source_kafka_usernameysource_kafka_passwordpor las credenciales de tu clúster de Kafka de origen.Reemplaza
target_kafka_usernameytarget_kafka_passwordpor las credenciales de tu clúster de Managed Service para Apache Kafka de destino. Para configurar el nombre de usuario y la contraseña, consulta Autenticación SASL/PLAIN.Los parámetros de configuración
topics = .\*ygroups = .\*replican todos los temas y grupos de consumidores. Si es necesario, puedes modificar estos parámetros de configuración para que sean más específicos.El parámetro de configuración
offset.syncs.topic.replication.factor = 3establece el factor de replicación para el tema interno que usa MirrorMaker 2.0 para sincronizar los desplazamientos de consumidores entre los clústeres de origen y destino. Un factor de replicación de3significa que los datos de desplazamiento se replican en tres agentes del clúster de destino, lo que garantiza una mayor disponibilidad y tolerancia a errores.El parámetro de configuración
checkpoints.topic.replication.factor = 3establece el factor de replicación para otro tema interno que usa MirrorMaker 2.0 para almacenar puntos de control. Los puntos de control ayudan a MirrorMaker 2.0 a hacer un seguimiento de su progreso y reanudar la replicación desde el punto correcto en caso de fallas o reinicios.El parámetro de configuración
heartbeats.topic.replication.factor = 3establece el factor de replicación para el tema interno que usa MirrorMaker 2.0 para enviar señales de monitoreo de funcionamiento. Las señales de monitoreo de funcionamiento indican que el proceso de MirrorMaker 2.0 está activo y en ejecución. Un factor de replicación más alto garantiza que estos latidos se almacenen de forma confiable y se puedan usar para supervisar el estado del proceso de replicación.El parámetro de configuración
emit.checkpoints.interval.seconds = 10controla la frecuencia con la que MirrorMaker 2.0 emite puntos de control. En este caso, se emiten puntos de control cada 10 segundos. Esta frecuencia proporciona un equilibrio entre el seguimiento del progreso y la minimización de la sobrecarga de escritura de puntos de control.
Inicia MirrorMaker 2.0. Usa la secuencia de comandos
connect-mirror-maker.shpara iniciar el proceso.La secuencia de comandos inicia MirrorMaker 2.0 en modo independiente y comienza a replicar datos de tu clúster de Kafka de origen a tu clúster de Managed Service para Apache Kafka.
Consideraciones adicionales:
Redes: Asegúrate de que tu VM Google Cloud tenga conectividad de red tanto con tu clúster de Kafka de origen como con tu clúster de Managed Service para Apache Kafka de destino. Si tu clúster de origen es local, es posible que debas configurar una VPN o una interconexión.
Seguridad: Configura los protocolos de seguridad y las reglas de firewall adecuados para proteger tu instancia de MirrorMaker 2.0 y tus clústeres de Kafka.
Si sigues estos pasos, podrás instalar y configurar correctamente MirrorMaker 2.0 en el modo de clúster independiente en una VM de Google Cloud para facilitar la migración de tus datos de Kafka a Managed Service para Apache Kafka.
Supervisión
Supervisa el proceso de MirrorMaker 2.0 para asegurarte de que se ejecute correctamente y replique los datos según lo previsto. Puedes usar las métricas integradas de MirrorMaker 2 o cualquier otra herramienta de supervisión. Después de migrar tus aplicaciones, supervisa lo siguiente para validar el éxito de la migración:
Tasas de transferencia de datos de descarga: Asegúrate de que no haya cambios significativos en las tasas de transferencia de datos de descarga. Por ejemplo, si usas Dataflow de forma descendente, el rendimiento y las métricas relacionadas con Kafka deben seguir siendo coherentes.
Utilización de CPU y memoria: Supervisa la utilización de CPU y memoria de tu clúster de Managed Service para Apache Kafka con Cloud Monitoring. Idealmente, el uso debe permanecer por debajo del 75% para garantizar un rendimiento óptimo.
Registros de errores: Revisa periódicamente Cloud Logging para detectar cualquier registro de errores relacionado con tu clúster de Managed Service para Apache Kafka o tus aplicaciones. Soluciona los errores de inmediato para evitar interrupciones.
Limitaciones
- MirrorMaker 2.0 requiere que tu clúster de Apache Kafka de origen sea la versión 2.4.0 o una posterior.