
In diesem Dokument wird beschrieben, wie Sie Ihre Apache Kafka-Arbeitslasten zu Google Cloud Managed Service for Apache Kafka migrieren. Dieser Dienst ist ein verwalteter Dienst in Google Cloud.
Mit Managed Service for Apache Kafka können Sie Apache Kafka auf Google Cloudausführen. In dieser dokumentierten Lösung werden Daten aus einem externen Apache Kafka-Cluster in einen Managed Service for Apache Kafka-Cluster verschoben.
Weitere Informationen zu Managed Service for Apache Kafka finden Sie in der Übersicht zu Managed Service for Apache Kafka.
Wir empfehlen, für diese Migration MirrorMaker 2.0 von Apache Kafka zu verwenden.
MirrorMaker 2.0 ist ein Tool zum Replizieren von Daten in Echtzeit zwischen Apache Kafka-Clustern. Es kann für Datenmigrationen, Notfallwiederherstellung, Datenisolation und Datenaggregation verwendet werden.
Weitere Informationen zu MirrorMaker 2.0 finden Sie im nächsten Abschnitt.
Was ist MirrorMaker 2.0?
MirrorMaker 2.0 verwendet das Kafka Connect-Framework, um Daten zwischen Kafka-Clustern zu replizieren. Kafka Connect ist ein Framework zum Streamen von Daten zwischen Kafka-Clustern und anderen Systemen. Es fungiert als skalierbare und zuverlässige Pipeline. Dieses Framework vereinfacht die Integration von Kafka in verschiedene externe Systeme wie Datenbanken, Message Queues und Onlinespeicher durch die Verwendung von sofort verfügbaren Connectors. Im Folgenden finden Sie eine Liste möglicher Szenarien, in denen Sie MirrorMaker 2.0 verwenden können:
Datenmigrationen: Verschieben Sie Ihre Kafka-Arbeitslast in einen neuen Cluster, wie in diesem Leitfaden beschrieben.
Notfallwiederherstellung: Erstellen Sie einen Sicherungscluster, um die Geschäftskontinuität im Falle von Fehlern sicherzustellen.
Datenisolation: Themen selektiv in einen öffentlichen Cluster replizieren und gleichzeitig sensible Daten in einem privaten Cluster schützen.
Datenaggregation: Daten aus mehreren Kafka-Clustern in einem zentralen Cluster für Analysezwecke zusammenführen.
MirrorMaker 2.0 unterstützt Kafka-Version 2.4.0 und höher und bietet die folgenden wichtigen Funktionen:
Umfassende Replikation: Alle erforderlichen Komponenten werden repliziert, einschließlich Themen, Daten und Konfigurationen, Verbrauchergruppen mit Offsets und Zugriffskontrolllisten.
Partitionierung beibehalten: Im Zielcluster wird dasselbe Partitionierungsschema beibehalten, was den Übergang für Anwendungen vereinfacht.
Automatische Erstellung von Themen und Partitionen: Neue Themen und Partitionen werden automatisch erkannt und repliziert, wodurch die manuelle Konfiguration minimiert wird.
Monitoring-Funktionen: Bietet wichtige Messwerte wie die End-to-End-Replikationslatenz, mit denen Sie den Zustand und die Leistung des Replikationsprozesses im Blick behalten können.
Fehlertoleranz und Skalierbarkeit: Gewährleistet einen zuverlässigen Betrieb auch bei großen Datenmengen und kann horizontal skaliert werden, um steigende Arbeitslasten zu bewältigen.
Interne Themen für Robustheit: Verwendet interne Themen für die Offset-Synchronisierung, Checkpoints und Heartbeats. Für diese Themen sind konfigurierbare Replikationsfaktoren wie
offset.syncs.topic.replication.factorverfügbar, um Hochverfügbarkeit und Fehlertoleranz zu gewährleisten.
MirrorMaker 2.0 bietet zwei Bereitstellungsmodi:
Modus „Dedizierter Cluster“: MirrorMaker 2.0 wird als eigenständiger Cluster ausgeführt und verwaltet seine eigenen Worker. In diesem Dokument wird dieser Modus behandelt und ein praktisches Beispiel für die Bereitstellung und Konfiguration gegeben.
Kafka Connect-Clustermodus: MirrorMaker 2.0 wird als Connector in einem vorhandenen Kafka Connect-Cluster ausgeführt.
Allgemeiner Workflow
Das folgende Diagramm zeigt die Architektur für die Migration von Daten aus einem Apache Kafka-Quellcluster zu einem Managed Service for Apache Kafka-Cluster mit MirrorMaker 2.0.
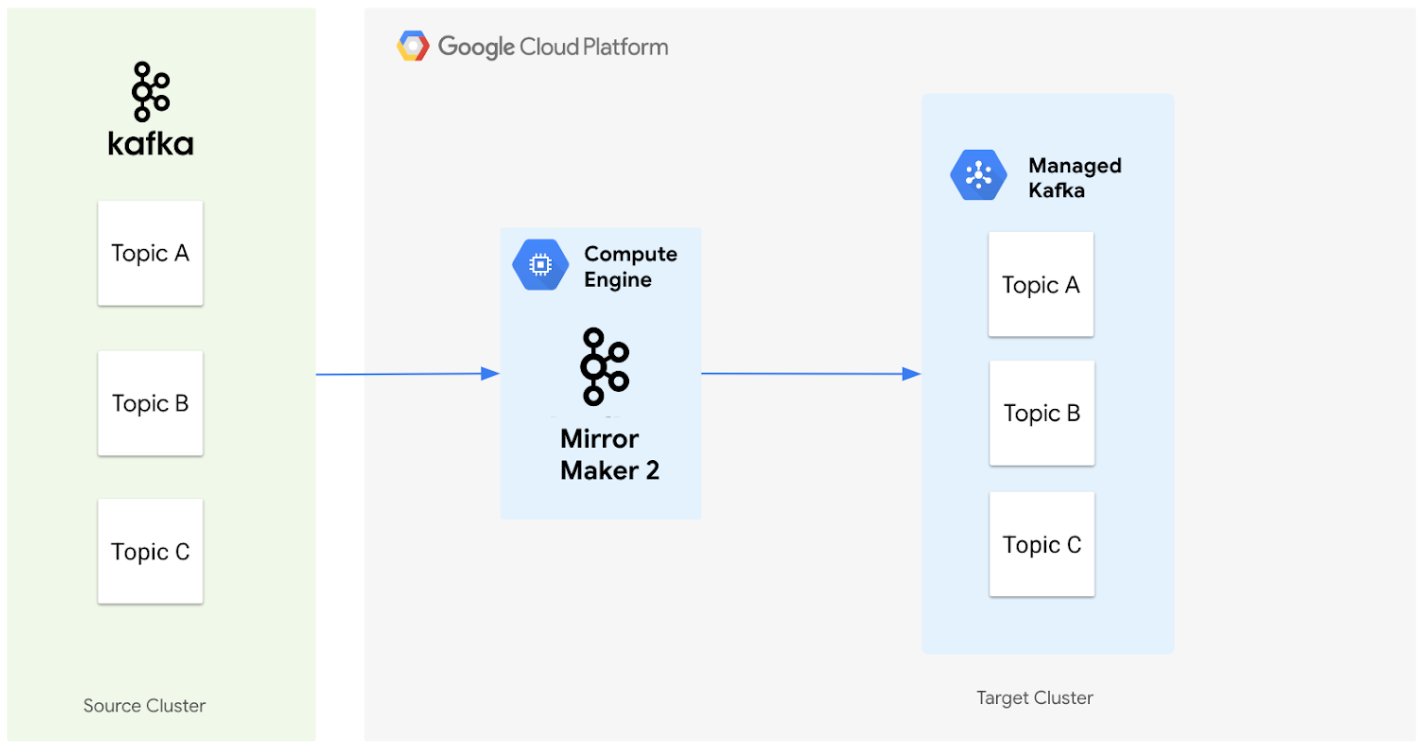
So arbeiten die Komponenten zusammen:
Quellcluster: Dies ist Ihr vorhandener Apache Kafka-Cluster, der sich lokal oder in einer anderen Cloud-Umgebung befinden kann. Sie enthält die Themen, die Sie migrieren möchten. In diesem Diagramm enthält der Apache Kafka-Quellcluster drei Themen: Thema A, B und C.
MirrorMaker 2.0: Diese Kernkomponente wird auf einer Compute Engine-VM als dedizierter MirrorMaker 2.0-Cluster bereitgestellt und repliziert Daten aktiv vom Apache Kafka-Quellcluster in den Managed Service for Apache Kafka-Zielcluster. Wichtig: Die entsprechenden Themen und Partitionen werden auch automatisch im Zielcluster erstellt, falls sie nicht vorhanden sind. So wird die Einrichtung des Quellclusters gespiegelt.
Zielcluster: Dies ist Ihr Managed Service for Apache Kafka-Cluster. Es wird zum neuen Speicherort für Ihre Kafka-Daten. MirrorMaker 2.0 sorgt dafür, dass die Themen und Partitionen entsprechend Ihrer Quellumgebung erstellt werden.
Hier ist ein allgemeiner Workflow für den Migrationsprozess.
Erste Bewertung
Dokumentieren Sie Ihre vorhandene Kafka-Einrichtung, einschließlich Clustergröße, Themen, Durchsatz und Nutzergruppen.
Planen Sie Ihre Migrationsziele und -strategie, einschließlich der Toleranz für Ausfallzeiten und des Umstellungsansatzes.
Schätzen Sie die Ressourcen, die für Ihren Managed Service for Apache Kafka-Cluster erforderlich sind.
Vorbereitung
Erstellen Sie ein Managed Service for Apache Kafka-Cluster.
Konfigurieren Sie die Netzwerkverbindung zwischen Ihrem vorhandenen Kafka-Cluster und dem Managed Service for Apache Kafka-Cluster, das Sie gerade erstellt haben.
Stellen Sie MirrorMaker 2.0 auf einer Google Cloud -VM bereit.
Migration ausführen
Konfigurieren Sie MirrorMaker 2.0, um Daten aus Ihrem vorhandenen Kafka-Cluster in den Managed Service for Apache Kafka-Cluster zu replizieren.
Überwachen Sie den Replikationsprozess mit MirrorMaker 2.0-Messwerten.
Migrieren Sie die Consumer und Producer nach und nach zum neuen Managed Service for Apache Kafka-Cluster.
Validierung und Umstellung
Datenintegrität und Anwendungsfunktionen im Managed Service for Apache Kafka-Cluster validieren.
Führen Sie die endgültige Umstellung durch und leiten Sie den Traffic zum Managed Service for Apache Kafka-Cluster um.
Deaktivieren Sie Ihr altes Kafka-Cluster.
Nach der Migration
Überwachen Sie die Leistung Ihres Managed Service for Apache Kafka-Clusters kontinuierlich.
Überprüfen und aktualisieren Sie die Dokumentation, um die Änderungen zu berücksichtigen.
Ausfallzeiten bei der Migration minimieren
In diesem Abschnitt werden einige Überlegungen zur Migration Ihrer Open-Source-Kafka-Daten zu Managed Service for Apache Kafka mit MirrorMaker 2.0 beschrieben. MirrorMaker 2.0 ermöglicht die Replikation von Daten und Offsets, sodass Consumer im neuen Cluster an der richtigen Stelle fortfahren können. Eine sorgfältige Planung ist jedoch entscheidend, um die Ausfallzeit während der Migration zu minimieren. Hier einige Strategien:
Parallele Bereitstellungen: Um Ausfallzeiten beim Wechsel zum neuen Managed Service for Apache Kafka-Cluster zu minimieren, können Sie parallele Instanzen Ihrer Anwendungen sowohl im alten als auch im neuen Cluster ausführen. Deaktivieren Sie während dieser Umstellung vorübergehend alle Aktionen in Ihrer Anwendung, die nur einmal pro Nachricht ausgeführt werden dürfen, z. B. das Senden einer Benachrichtigung. Deaktivieren Sie diese Nebeneffekte, um unbeabsichtigte Folgen durch die zweimalige Verarbeitung derselben Nachricht zu vermeiden. Sobald die neuen Instanzen vollständig synchronisiert sind, leiten Sie den gesamten Traffic zum neuen Cluster um und aktivieren Sie alle Funktionen wieder.
Schrittweise Einführung: Migrieren Sie in kleineren, überschaubaren Phasen und beginnen Sie mit weniger kritischen Anwendungen. So lassen sich potenzielle Probleme eingrenzen und die Auswirkungen von Störungen minimieren.
Blau/Grün-Bereitstellungen: Erstellen Sie neben der vorhandenen Produktionsumgebung (blau) eine vollständige Replik (grün). Traffic schrittweise von Blau auf Grün umstellen, um Tests und Validierungen vor der endgültigen Umstellung zu ermöglichen. Dieser Ansatz minimiert die Ausfallzeit, erfordert aber eine höhere Ressourcennutzung.
Anforderungen an die Nachrichtenverarbeitung: Machen Sie sich mit der Toleranz Ihrer Anwendung für doppelte oder fehlende Nachrichten vertraut und konfigurieren Sie die Consumer entsprechend. MirrorMaker 2.0 bietet Konfigurationen für die Semantik der Nachrichtenzustellung.
sync.group.offsets.enabledunterstützt beispielsweise die Synchronisierung von Consumer-Offsets. Nutzer können die synchronisierten Offsets verwenden, um dort weiterzulesen, wo sie im Quellcluster aufgehört haben. So können Sie verhindern, dass Nachrichten verloren gehen oder zu viele Duplikate empfangen werden.Kommunikation und Koordination: Eine effektive Kommunikation mit den Anwendungsteams ist für eine reibungslose Migration unerlässlich. Richten Sie klare Kommunikationskanäle ein und koordinieren Sie die Umstellungszeiten.
Lokales Apache Kafka mit Google Cloudverbinden
Wenn sich Ihr Apache Kafka-Quellcluster lokal befindet, müssen Sie eine sichere Verbindung zwischen Ihrem lokalen Netzwerk und Ihrer Virtual Private Cloud (VPC) herstellen, in der sich Ihr Managed Service for Apache Kafka-Cluster befindet. Verwenden Sie eine der folgenden Optionen aus Google Cloud.
Cloud VPN: Eine kostengünstige Lösung, die sich für geringere Bandbreitenanforderungen oder erste Migrationstests eignet. Es wird ein verschlüsselter Tunnel über das öffentliche Internet erstellt. Weitere Informationen zu Cloud VPN finden Sie unter Cloud VPN – Übersicht.
Cloud Interconnect: Bietet eine dedizierte Verbindung mit hoher Bandbreite zwischen Ihrem lokalen Netzwerk und Google Cloud. Dies ist ideal für Bereitstellungen auf Unternehmensniveau, die einen höheren Durchsatz und eine geringere Latenz erfordern. Sie können zwischen Dedicated Interconnect (für eine direkte physische Verbindung) oder Partner Interconnect (Verbindung über einen unterstützten Dienstanbieter) wählen. Weitere Informationen zur Dokumentation zu Google CloudInterconnect finden Sie unter Cloud Interconnect – Übersicht.
Wenn Sie einen Managed Service for Apache Kafka-Cluster erstellen, müssen Sie mindestens ein Subnetz in Ihrer VPC auswählen. Dieses Subnetz stellt die IP-Adressen bereit, die Ihr Cluster für die Kommunikation mit anderen Ressourcen in Ihrer VPC verwendet. Dadurch ist der Cluster in Ihrem VPC-Netzwerk zugänglich.
Wenn Sie von lokalen Netzwerken oder anderen VPC-Netzwerken aus eine sichere Verbindung zu Ihrem Managed Service for Apache Kafka-Cluster herstellen möchten, können Sie Private Service Connect (PSC) über Cloud VPN oder Cloud Interconnect verwenden. Sie müssen PSC-Endpunkte nicht explizit einrichten. Wenn Sie beim Erstellen eines Clusters ein Subnetz auswählen, werden die erforderlichen PSC-Endpunkte automatisch vom Managed Service for Apache Kafka-Dienst erstellt. Dies vereinfacht die Netzwerkkonfiguration, da Sie über interne IP-Adressen in Ihrer VPC auf Ihren Cluster zugreifen können, ohne komplexe Firewallregeln oder öffentliche IP-Adressen verwalten zu müssen.
Weitere Informationen zur Netzwerkeinrichtung für Managed Service for Apache Kafka finden Sie unter Netzwerk für Managed Service for Apache Kafka.
Hinweise
Bevor Sie mit der Einrichtung der Migration beginnen, müssen Sie Ihre aktuelle Apache Kafka-Einrichtung dokumentieren. Sie benötigen diese Informationen, um die Ressourcen wie vCPUs, Arbeitsspeicher und Speicherplatz zu berechnen, die für Ihren neuen Managed Service for Apache Kafka-Cluster erforderlich sind. Erfassen Sie die folgenden Informationen zu Ihrer Apache Kafka-Quellumgebung:
Achten Sie darauf, dass die Apache Kafka-Version 2.4.0 oder höher ist.
Wenn Sie die Version Ihres Apache Kafka-Clusters prüfen möchten, rufen Sie das Kafka-Installationsverzeichnis auf und führen Sie den Befehl
bin/kafka-topics.sh --versionaus.Ermitteln Sie die Cluster und Themen, die migriert werden müssen.
Identifizieren Sie die Ersteller und Nutzer, die mit den einzelnen Themen in Verbindung stehen.
Alle Verbrauchergruppen identifizieren.
Bestimmen Sie den Nachrichtendurchsatz sowohl auf Cluster- als auch auf Themenebene.
Bestimmen Sie den Replikationsfaktor für Ihre Cluster und Themen.
Dokumentieren Sie die Konfigurationen der Verbraucher, insbesondere Sicherheitsprotokolle und die Integration mit anderen Google Cloud Diensten.
Um Unterbrechungen während der Migration zu vermeiden, müssen Sie alle Anwendungsabhängigkeiten in Bezug auf Ihren Quell-Kafka-Cluster ermitteln. Bevor Sie Ihre Produktionsumgebung migrieren, sollten Sie eine Testmigration mit einem nicht kritischen Cluster in einer Entwicklungsumgebung durchführen. Validieren Sie den Prozess und ermitteln Sie potenzielle Probleme. Erstellen Sie schließlich einen umfassenden Rollback-Plan, um bei Bedarf zum ursprünglichen Cluster zurückzukehren.
Größe des Zielclusters berechnen
Informationen zum Schätzen der Anzahl der vCPUs und der Größe des Arbeitsspeichers, die für Ihren Managed Service for Apache Kafka-Cluster erforderlich sind, finden Sie unter Größe des Kafka-Clusters planen. Die Konfiguration von Laufwerk und Broker erfolgt automatisch und kann nicht angepasst werden.
Open-Source-Kafka bietet JMX-Messwerte. Mit den folgenden JMX-Messwerten können Sie die erforderliche Clustergröße für Ihren Managed Service for Apache Kafka-Cluster genau berechnen. Diese Messwerte werden auf Maklerebene erfasst. Sie müssen die Daten über alle Broker hinweg aggregieren, um den Clusterdurchsatz zu berechnen.
kafka.server:type=BrokerTopicMetrics,name=BytesInPerSec: Dieser Messwert gibt die eingehende Byte-Rate von Clients für alle Themen an. Lassen Sie den Parametertopic={...}weg, um die zusammengefasste Rate für alle Themen zu erhalten.kafka.server:type=BrokerTopicMetrics,name=BytesOutPerSec: Mit diesem Messwert wird die ausgehende Byte-Rate zu Clients für alle Themen erfasst. Lassen Sie den Parametertopic={...}weg, um die Gesamtrate zu erhalten.
Wenn Sie diese JMX-Messwerte über einen bestimmten Zeitraum hinweg beobachten, können Sie Datenpunkte erfassen, um Folgendes zu berechnen:
Durchschnittliche Datenmenge (Eingang), MB/s: Dieser Messwert gibt die durchschnittliche Rate an, mit der Daten in den Kafka-Cluster aufgenommen werden.
Peak Data In, MB/s (Spitzendaten-Eingabe, MB/s): Dieser Messwert gibt die höchste Rate an, mit der Daten in das Kafka-Cluster aufgenommen werden.
Durchschnittliche Datenübertragung (MB/s): Dieser Messwert gibt die durchschnittliche Rate an, mit der Daten aus dem Kafka-Cluster abgerufen werden.
Maximale Datenübertragungsrate (MB/s): Dieser Messwert gibt die höchste Rate an, mit der Daten aus dem Kafka-Cluster abgerufen werden.
Möglicherweise sind einige Berechnungen erforderlich, um die Daten zu aggregieren und Bytes in MB umzuwandeln. Anhand dieser berechneten Werte können Sie die Schreibäquivalenzrate so schätzen:
Write-equivalent rate (Avg/Peak) = (total write bandwidth) + (total read bandwidth / 4)
Anhand dieser schreibäquivalenten Rate lässt sich die gesamte Schreiblast für den Cluster ermitteln, die für die richtige Dimensionierung Ihres Managed Service for Apache Kafka-Clusters erforderlich ist.
Managed Service for Apache Kafka-Cluster erstellen
Ein Managed Service for Apache Kafka-Cluster befindet sich in einem bestimmtenGoogle Cloud Projekt und einer bestimmten Region. Sie kann über eine Reihe von IP-Adressen in einem oder mehreren Subnetzen in einer beliebigen Virtual Private Cloud (VPC) aufgerufen werden.
Die Größe des Clusters wird durch die Anzahl der CPUs und den Gesamtspeicher bestimmt, die Sie ihm zuweisen. In diesem Fall muss die Clustergröße der Größe des Apache Kafka-Quellclusters entsprechen. Weitere Informationen zur Durchführung dieser Berechnung finden Sie unter Zielclustergröße berechnen.
Bitten Sie Ihren Administrator, Ihnen oder dem Dienstkonto, mit dem der Cluster erstellt wird, die IAM-Rolle Managed Kafka Admin (roles/managedkafka.admin) für Ihr Projekt zuzuweisen, um die Berechtigungen zu erhalten, die Sie zum Erstellen eines Clusters benötigen. Weitere Informationen zum Zuweisen von Rollen finden Sie unter Zugriff auf Projekte, Ordner und Organisationen verwalten.
Wenn Sie einen Managed Service for Apache Kafka-Cluster erstellen möchten, folgen Sie der Kurzanleitung unter Nachrichten mit der CLI senden und empfangen. Das Erstellen eines Clusters dauert in der Regel 20 bis 30 Minuten.
MirrorMaker 2.0 im eigenständigen Clustermodus einrichten
Ein Konzeptnachweisdokument und Beispielcode, der zeigt, wie Sie mit MirrorMaker 2.0 und Terraform Kafka-Daten in Google Cloudübertragen, finden Sie in diesem GitHub-Repository.
In diesem Abschnitt wird beschrieben, wie Sie MirrorMaker 2.0 in einem Standalone-Clustermodus auf einer Google Cloud VM installieren und konfigurieren. Mit dieser Einrichtung können Sie Daten aus Ihrem vorhandenen Apache Kafka-Cluster in einen Managed Service for Apache Kafka-Cluster replizieren.
Erstellen Sie eine VM im selben Netzwerk, dem Zugriff auf den Managed Service for Apache Kafka-Cluster gewährt wurde. Verwenden Sie den Befehl gcloud compute instances create.
gcloud compute instances create VM_NAME\ --zone=ZONE\ [--image=IMAGE | --image-family=IMAGE_FAMILY]\ --image-project=IMAGE_PROJECT\ --machine-type=MACHINE_TYPE
Ersetzen Sie Folgendes:
VM_NAME: Der Name der VM, die Sie erstellen möchten.ZONE: die Zone, in der Sie die VM erstellen möchten.IMAGEoderIMAGE_FAMILY: Das Image oder die Image-Familie, die Sie für die VM verwenden möchten.IMAGE_PROJECT: Das Projekt, in dem sich das Image befindet.MACHINE_TYPE: der Maschinentyp, den Sie für die VM verwenden möchten.
Sie können über SSH auf Ihre neu erstellte VM zugreifen.
Weitere Informationen zu SSH-Verbindungen finden Sie unter Informationen zu SSH-Verbindungen.
Führen Sie in Ihrem Terminalfenster der neuen VM die folgenden Befehle aus, um Kafka herunterzuladen und zu entpacken:
wget https://downloads.apache.org/kafka/3.7.1/kafka_2.13-3.7.1.tgz tar -xzvf kafka_2.13-3.7.1.tgzLaden Sie Java herunter, extrahieren Sie das Paket und legen Sie dann den Java-Pfad fest.
# Download Java wget https://download.java.net/java/GA/jdk11/9/GPL/openjdk-11.0.2_linux-x64_bin.tar.gz # Extract Java tar -xzvf openjdk-11.0.2_linux-x64_bin.tar.gz # Set Java path export PATH=$PATH:/java/jdk-11.0.2/bin/Bearbeiten Sie die Datei
path/to/kafka/config/mm2.propertiesund aktualisieren Sie die folgenden Attribute:clusters = source, target source.bootstrap.servers = <source_kafka_bootstrap_servers> target.bootstrap.servers = <target_kafka_bootstrap_servers> source.security.protocol = SASL_SSL source.sasl.mechanism = PLAIN source.sasl.jaas.config = org.apache.kafka.common.security.plain.PlainLoginModule required username="<source_kafka_username>" password="<source_kafka_password>"; target.security.protocol = SASL_SSL target.sasl.mechanism = PLAIN target.sasl.jaas.config = org.apache.kafka.common.security.plain.PlainLoginModule required username="<target_kafka_username>" password="<target_kafka_password>"; mirrors = source->target source->target.enabled=true topics = .* groups = .* offset.syncs.topic.replication.factor = 3 checkpoints.topic.replication.factor = 3 heartbeats.topic.replication.factor = 3 emit.checkpoints.interval.seconds = 10Ersetzen Sie
source_kafka_bootstrap_serversundtarget_kafka_bootstrap_serversdurch die Bootstrap-Serveradressen Ihres Quell- bzw. Ziel-Kafka-Clusters. Sie können die Bootstrap-Serveradresse für Managed Service for Apache Kafka mit dem Google Cloud CLI-Befehlmanaged-kafka clusters describeabrufen.Ersetzen Sie
source_kafka_usernameundsource_kafka_passworddurch die Anmeldedaten für Ihren Kafka-Quellcluster.Ersetzen Sie
target_kafka_usernameundtarget_kafka_passworddurch die Anmeldedaten für Ihren Ziel-Managed Service for Apache Kafka-Cluster. Informationen zum Konfigurieren des Nutzernamens und des Passworts finden Sie unter SASL/PLAIN-Authentifizierung.Mit den Einstellungen
topics = .\*undgroups = .\*werden alle Themen und Verbrauchergruppen repliziert. Sie können diese Einstellungen bei Bedarf genauer anpassen.Mit der Einstellung
offset.syncs.topic.replication.factor = 3wird der Replikationsfaktor für das interne Thema festgelegt, das von MirrorMaker 2.0 verwendet wird, um Nutzer-Offsets zwischen dem Quell- und dem Zielcluster zu synchronisieren. Ein Replikationsfaktor von3bedeutet, dass die Offsetdaten auf drei Broker im Zielcluster repliziert werden, was für eine höhere Verfügbarkeit und Fehlertoleranz sorgt.Mit der Einstellung
checkpoints.topic.replication.factor = 3wird der Replikationsfaktor für ein weiteres internes Thema festgelegt, das von MirrorMaker 2.0 zum Speichern von Prüfpunkten verwendet wird. Prüfpunkte helfen MirrorMaker 2.0, den Fortschritt zu verfolgen und die Replikation im Falle von Fehlern oder Neustarts am richtigen Punkt fortzusetzen.Mit der Einstellung
heartbeats.topic.replication.factor = 3wird der Replikationsfaktor für das interne Thema festgelegt, das von MirrorMaker 2.0 zum Senden von Heartbeats verwendet wird. Heartbeats signalisieren, dass der MirrorMaker 2.0-Prozess aktiv ist. Ein höherer Replikationsfaktor sorgt dafür, dass diese Heartbeats zuverlässig gespeichert werden und zur Überwachung des Zustands des Replikationsprozesses verwendet werden können.Mit der Einstellung
emit.checkpoints.interval.seconds = 10wird gesteuert, wie oft MirrorMaker 2.0 Prüfpunkte ausgibt. In diesem Fall werden alle 10 Sekunden Checkpoints ausgegeben. Diese Häufigkeit bietet ein Gleichgewicht zwischen der Verfolgung des Fortschritts und der Minimierung des Aufwands für das Schreiben von Prüfpunkten.
Starten Sie MirrorMaker 2.0. Verwenden Sie das
connect-mirror-maker.sh-Skript, um den Vorgang zu starten.Das Skript startet MirrorMaker 2.0 im Standalone-Modus und beginnt mit der Replikation von Daten aus Ihrem Quell-Kafka-Cluster in Ihren Managed Service for Apache Kafka-Cluster.
Zusätzliche Überlegungen:
Netzwerk: Achten Sie darauf, dass Ihre Google Cloud VM eine Netzwerkverbindung sowohl zu Ihrem Kafka-Quellcluster als auch zu Ihrem Managed Service for Apache Kafka-Zielcluster hat. Wenn sich Ihr Quellcluster lokal befindet, müssen Sie möglicherweise VPN oder Interconnect konfigurieren.
Sicherheit: Konfigurieren Sie geeignete Sicherheitsprotokolle und Firewallregeln, um Ihre MirrorMaker 2.0-Instanz und Ihre Kafka-Cluster zu schützen.
Wenn Sie diese Schritte ausführen, können Sie MirrorMaker 2.0 im Standalone-Clustermodus auf einer Google Cloud VM installieren und konfigurieren, um die Migration Ihrer Kafka-Daten zu Managed Service for Apache Kafka zu erleichtern.
Monitoring
Überwachen Sie den MirrorMaker 2.0-Prozess, um sicherzustellen, dass er korrekt ausgeführt wird und Daten wie erwartet repliziert werden. Sie können die integrierten Messwerte von MirrorMaker 2 oder andere Monitoring-Tools verwenden. Nach der Migration Ihrer Anwendungen sollten Sie Folgendes beobachten, um den Erfolg zu bestätigen:
Downstream-Durchsatzraten: Achten Sie darauf, dass es keine signifikanten Änderungen bei den Downstream-Durchsatzraten gibt. Wenn Sie beispielsweise Dataflow downstream verwenden, müssen der Durchsatz und die Messwerte im Zusammenhang mit Kafka konsistent bleiben.
CPU- und Arbeitsspeichernutzung: Überwachen Sie die CPU- und Arbeitsspeichernutzung Ihres Managed Service for Apache Kafka-Clusters mit Cloud Monitoring. Die Auslastung sollte idealerweise unter 75% bleiben, um eine optimale Leistung zu gewährleisten.
Fehlerlogs: Prüfen Sie Cloud Logging regelmäßig auf Fehlerlogs, die sich auf Ihren Managed Service for Apache Kafka-Cluster oder Ihre Anwendungen beziehen. Beheben Sie Fehler umgehend, um Unterbrechungen zu vermeiden.
Beschränkungen
- Für MirrorMaker 2.0 muss Ihr Apache Kafka-Quellcluster Version 2.4.0 oder höher haben.