
Clients können von jedem VPC-Netzwerk (Virtual Private Cloud) in Ihren Google Cloud Projekten aus eine Verbindung zu einem Managed Service for Apache Kafka-Cluster herstellen.
Auf dieser Seite wird erläutert, wie die Netzwerkkonfiguration in Managed Service for Apache Kafka erfolgt, wie Sie Verbindungen zwischen Kafka-Clients und Ihrem Cluster aktivieren und wie Sie projektübergreifende Verbindungen aktivieren.
Übersicht
Wenn Sie einen Cluster erstellen, platziert der Dienst ihn in einem VPC-Netzwerk , das von Google Cloudverwaltet wird. Dieses Netzwerk wird als Mandantennetzwerk bezeichnet. Jeder Managed Service for Apache Kafka-Cluster hat ein eigenes isoliertes Mandantennetzwerk. Damit Clientanwendungen mit dem Cluster kommunizieren können, verbinden Sie Subnetze in Ihren VPC-Netzwerken mit dem Mandantennetzwerk.
Das folgende Diagramm zeigt zwei Google Cloud Projekte: project-1 und
project-2. Ein Managed Service for Apache Kafka-Cluster befindet sich in project-1.
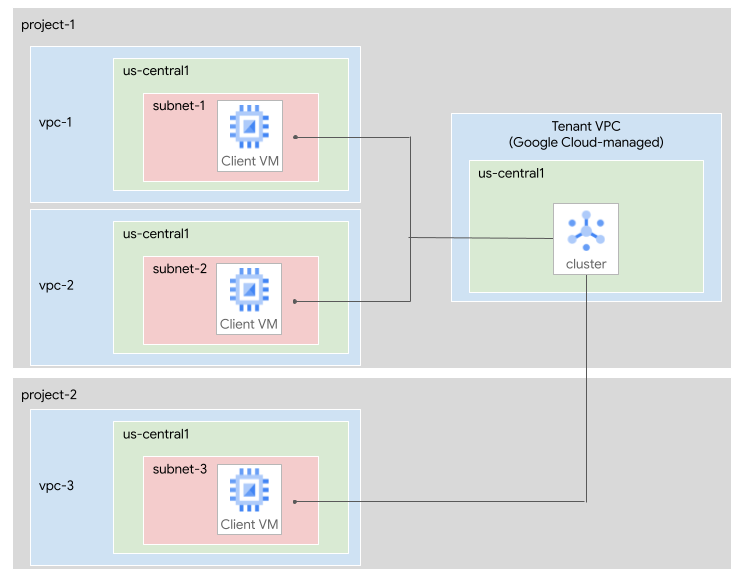
Die folgenden Subnetze sind mit dem Cluster verbunden:
subnet-1im VPC-Netzwerkvpc-1inproject-1.subnet-2im VPC-Netzwerkvpc-2inproject-1.subnet-3im VPC-Netzwerkvpc-3inproject-2.
Subnetze mit einem Cluster verbinden
Wenn Sie zum ersten Mal einen Managed Service for Apache Kafka-Cluster erstellen, müssen Sie mindestens ein Subnetz angeben. Später können Sie den Cluster aktualisieren, um Subnetze hinzuzufügen oder zu entfernen.
Verbundene Subnetze können sich im selben Google Cloud Projekt wie der Cluster oder in einem anderen Projekt befinden. Verbundene Subnetze müssen sich in derselben Region wie der Cluster befinden. Clients in jeder Region innerhalb derselben VPC können jedoch eine Verbindung zu den IP-Adressen in diesem Subnetz herstellen. Es kann höchstens ein Subnetz pro VPC-Netzwerk mit dem Cluster verbunden werden.
Informationen zum Aufrufen der Subnetze, die mit einem Cluster verbunden sind, finden Sie unter Subnetze eines Clusters ansehen.
Cluster-DNS-Einträge
Wenn Sie ein Subnetz mit einem Cluster verbinden, erstellt der Dienst DNS-Einträge in diesem Subnetznetzwerk für die Bootstrap-Adresse und die Broker des Clusters. Kafka-Clients verwenden die Bootstrap-Adresse, um die Broker zu finden und eine Verbindung herzustellen.
Die DNS-Namen sind in allen verbundenen Subnetzen gleich, obwohl sie in jedem Subnetz unterschiedlichen IP-Adressen entsprechen. Da die DNS-Namen einheitlich sind, können alle Ihre Kafka-Clientanwendungen dieselbe Bootstrap-Adresse verwenden. Informationen zum Abrufen der Bootstrap-Adresse des Clusters finden Sie unter Bootstrap-Adresse eines Clusters ansehen.
Beispiele für Clientanwendungen, die eine Verbindung zu Managed Service for Apache Kafka herstellen, finden Sie in den folgenden Anleitungen:
Subnetzgröße
Wenn Sie einem Cluster ein Subnetz hinzufügen, muss das Subnetz genügend IP-Adressen haben. Jedes Subnetz benötigt eine IP-Adresse für jeden Kafka-Broker sowie eine IP-Adresse für die Bootstrap-Adresse. Die Mindestgröße des Clusters für Managed Service for Apache Kafka beträgt drei Broker. Daher benötigt jedes Subnetz mindestens vier nutzbare IP-Adressen, einschließlich der Bootstrap-Adresse.
Wenn Ihr Cluster mehr als 45 vCPUs hat, hat der Cluster einen Broker für jeweils 15 vCPUs. In diesem Fall berechnen Sie die Mindestanzahl der IP-Adressen für jedes Subnetz so:
- Teilen Sie die Anzahl der vCPUs durch 15.
- Runden Sie auf die nächste ganze Zahl auf.
- Fügen Sie 1 für die Bootstrap-Adresse hinzu.
Ein Cluster mit 60 vCPUs benötigt beispielsweise mindestens (60/15 + 1) = 5 nutzbare IP-Adressen.
Google ändert das Verhältnis von Brokern zu vCPUs möglicherweise in Zukunft. Um zukünftigen Änderungen Rechnung zu tragen, empfehlen wir, die im vorherigen Schritt berechnete Anzahl von IP-Adressen zu verdreifachen.
Wenn Sie die Subnetzgröße planen, basieren Sie Ihre Berechnungen auf der maximalen Größe, auf die Sie Ihren Cluster in Zukunft skalieren möchten.
Wenn Sie Kafka Connect verwenden möchten, berücksichtigen Sie auch die Subnetzanforderungen für den Connect-Cluster. Weitere Informationen finden Sie unter Worker-Subnetz.
Privat verwendete öffentliche IP-Bereiche
Sie können Ihren Cluster mit Subnetzen verbinden, die den Adressraum außerhalb von RFC 1918 verwenden. Solche IP-Adressbereiche werden als privat verwendete öffentliche IP-Bereiche (Privately Used Public IP, PUPI) bezeichnet.
Für die Verbindung mit PUPI-Subnetzen ist keine zusätzliche Konfiguration erforderlich. Die PUPI Subnetze müssen einen gültigen IPv4-Bereich verwenden, der kein verbotener IPv4-Subnetzbereich ist.
Clients und Cluster projektübergreifend verbinden
Wenn Sie Kafka-Clients in verschiedenen Google Cloud Projekten haben, können Sie sie auf folgende Weise mit Ihrem Cluster verbinden:
- Verbinden Sie den Cluster mit VPC-Netzwerken in mehreren Projekten.
- Verwenden Sie gemeinsam genutzte VPC, um Projekte zu verbinden.
In den nächsten Abschnitten werden diese Optionen beschrieben.
Cluster projektübergreifend verbinden
Sie können Subnetze aus anderen Projekten mit Ihrem Cluster verbinden. Um projektübergreifenden Zugriff zu ermöglichen, müssen Sie dem von Google verwalteten Dienstkonto, das mit dem Cluster verknüpft ist, Berechtigungen gewähren. Für jedes Projekt, in dem Kafka-Clients auf den Cluster zugreifen sollen, muss das Dienstkonto die IAM-Rolle „Managed Kafka Service Agent“ für dieses Projekt haben. Diese Rolle ermöglicht dem Cluster den Zugriff auf Google Cloud Ressourcen, sodass er Netzwerkressourcen und DNS Einträge erstellen kann.
Beispiel: Wenn project-1 den Cluster enthält und Clients in project-2 auf den Cluster zugreifen sollen, gewähren Sie dem Managed Kafka-Dienstkonto für project-1 die Rolle „Managed Kafka Service Agent“ für project-2. Verbinden Sie dann
ein Subnetz aus project-2 mit dem Cluster, wie unter
Subnetze mit dem Cluster verbinden beschrieben.
Führen Sie die folgenden Schritte aus, um die erforderlichen Rollen zu gewähren:
Console
Bestimmen Sie die Google Cloud Projekte, in denen Ihre Kafka-Clients auf den Managed Service for Apache Kafka-Cluster zugreifen sollen.
Rufen Sie in der Google Cloud Console für jedes Projekt die IAM Seite auf:
Klicken Sie auf Zugriffsrechte erteilen.
Geben Sie im Feld Neue Hauptkonten Folgendes ein:
service-CLUSTER_PROJECT_NUMBER@gcp-sa-managedkafka.iam.gserviceaccount.comErsetzen Sie CLUSTER_PROJECT_NUMBER durch die Projektnummer des Projekts, das den Managed Service for Apache Kafka Cluster enthält.
Klicken Sie auf Rollen hinzufügen.
Geben Sie im Feld Nach Rollen suchen
Managed Kafka Service Agentein. Der Name des Dienst-Agents wird in den Suchergebnissen angezeigt.Wählen Sie in den Suchergebnissen Managed Kafka Service Agent aus.
Klicken Sie auf Übernehmen.
Klicken Sie auf Speichern.
gcloud
Bestimmen Sie die Google Cloud Projekte, in denen Ihre Kafka-Clients auf den Managed Service for Apache Kafka-Cluster zugreifen sollen.
Führen Sie für jedes Projekt den
gcloud projects add-iam-policy-bindingBefehl aus:gcloud projects add-iam-policy-binding CLIENT_PROJECT_ID \ --member=serviceAccount:service-CLUSTER_PROJECT_NUMBER@gcp-sa-managedkafka.iam.gserviceaccount.com \ --role=roles/managedkafka.serviceAgentErsetzen Sie Folgendes:
- CLIENT_PROJECT_ID: der Name des Projekts, das das zu verbindende VPC-Netzwerk enthält
- CLUSTER_PROJECT_NUMBER: die Projektnummer des Projekts, das den Managed Service for Apache Kafka Cluster enthält
Gemeinsam genutzte VPC verwenden, um Projekte zu verbinden
Mit einer gemeinsam genutzten VPC können Unternehmen Ressourcen aus mehreren Projekten in einem gemeinsamen VPC-Netzwerk zusammenführen. So verwenden Sie freigegebene VPC mit Managed Service for Apache Kafka:
Erstellen Sie einen Managed Service for Apache Kafka-Cluster.
Gewähren Sie dem Managed Kafka-Dienstkonto die erforderlichen Rollen im Hostprojekt der freigegebene VPC, wie im vorherigen Abschnitt beschrieben.
Verbinden Sie den Managed Service for Apache Kafka-Cluster mit einem Subnetz im freigegebene VPC-Netzwerk.
Clients im Hostprojekt der freigegebene VPC oder in den Dienstprojekten können eine Verbindung zum Cluster herstellen.
Informationen dazu, wann Sie freigegebene VPC in Ihren Netzwerkarchitekturen verwenden sollten, finden Sie unter Best Practices und Referenzarchitekturen für das VPC-Design.
Netzwerkarchitektur eines Clusters
In diesem Abschnitt werden die Details der Netzwerkarchitektur beschrieben, die in Managed Service for Apache Kafka verwendet wird.
Ein Kafka-Cluster umfasst ein Mandantennetzwerk und ein oder mehrere Verbrauchernetzwerke.
Im Mandantennetzwerk hat der Cluster eine einzelne Bootstrap-IP-Adresse und -URL. Diese Bootstrap-Adresse entspricht einem Load Balancer, der mit allen Brokern im Cluster verbunden ist. Jeder Broker kann auch einzeln als Bootstrap-Server fungieren. Wir empfehlen jedoch, aus Zuverlässigkeitsgründen die Bootstrap-Adresse zu verwenden.
In jedem Verbrauchernetzwerk erstellt der Dienst einen Private Service Connect Endpunkt für die Bootstrap-Adresse und einen Endpunkt für jeden Broker.
Die URL für die Bootstrap-Adresse ist in allen VPC-Netzwerken gleich, mit denen ein Cluster verbunden ist. Die IP-Adresse ist lokal für das Verbrauchernetzwerk.
Clients stellen über DNS-Namen eine Verbindung zu Kafka-Brokern her. Diese Namen werden automatisch in jedem VPC-Netzwerk registriert, mit dem ein Kafka-Cluster verbunden ist. Die Bootstrap-Adresse und die zugehörige Portnummer sind als Attribut des Clusters verfügbar.
Clients verwenden die Bootstrap-Adresse, um Broker-URLs abzurufen. Diese URLs werden in IP-Adressen aufgelöst, die für jedes VPC-Netzwerk lokal sind. Die tatsächlichen Broker-IP-Adressen und -URLs finden Sie in Cloud DNS.
Das folgende Diagramm zeigt eine Beispielarchitektur eines Managed Service for Apache Kafka-Clusternetzwerks.
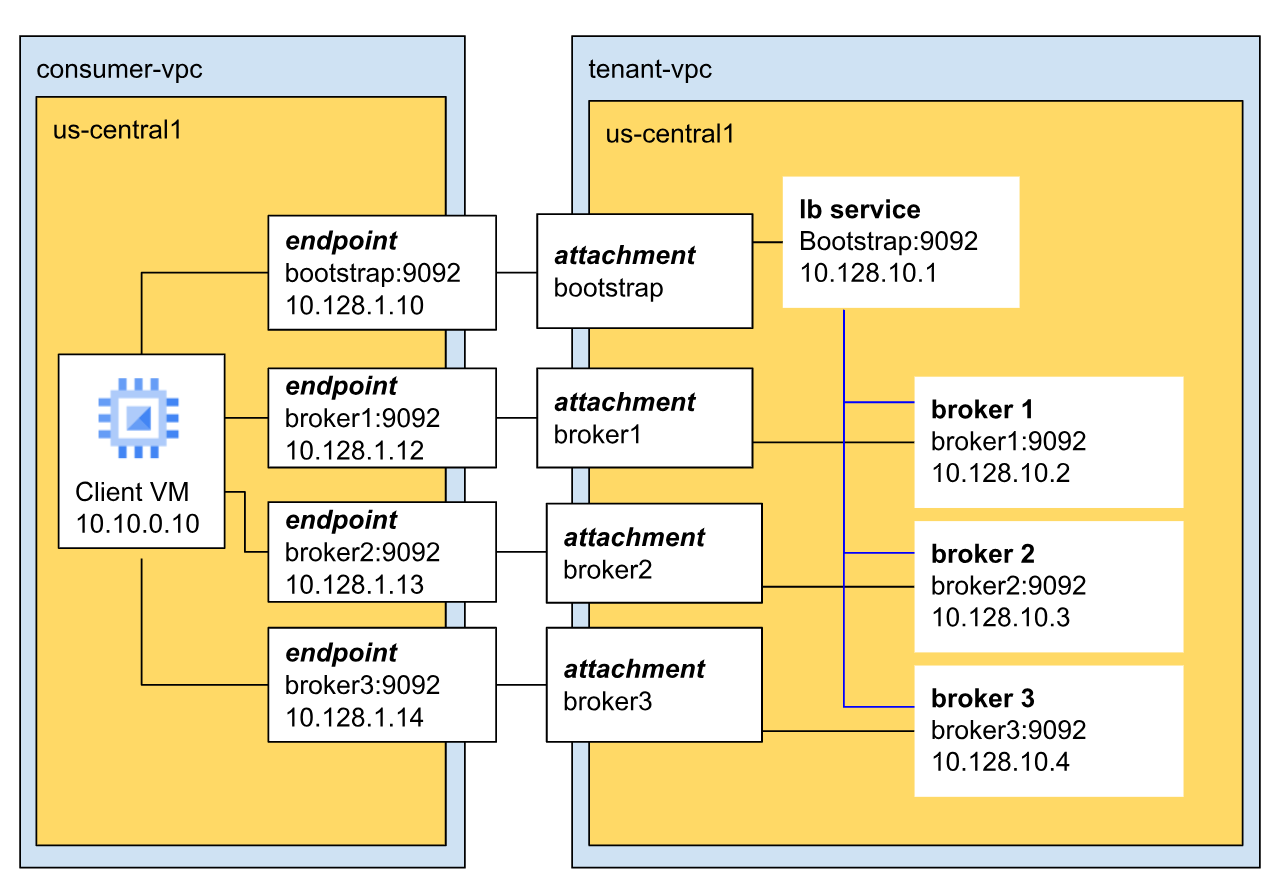
In diesem Beispiel hat der Cluster drei Broker und befindet sich in der Mandanten-VPC.
Broker kommunizieren über den Standard-Kafka-Port (9092) mit Clients und haben eindeutige IP-Adressen. In diesem Beispiel haben die drei Broker die IP-Adressen 10.128.10.2, 10.128.10.3 und 10.128.10.4.
Alle drei Broker stellen eine Verbindung zum Bootstrap-Load-Balancer her. Dies sorgt für Hochverfügbarkeit und regionale Fehlertoleranz, da die Bootstrap-Adresse nicht auf einen einzelnen Broker oder eine einzelne Zone beschränkt ist.
Fehlerbehebung
Informationen zur Fehlerbehebung bei Netzwerkproblemen finden Sie unter Netzwerkfehler.