
本頁面是指 測量中的
type參數。
type也可做為維度或篩選器的一部分,詳情請參閱「維度、篩選器和參數類型」說明文件頁面。
type也可做為維度群組的一部分,詳情請參閱dimension_group參數說明文件頁面。
用量
view: view_name {
measure: field_name {
type: measure_field_type
}
}
|
階層
type |
可能的欄位類型
評估
接受
測量指標類型
|
本頁面詳細說明可指派給指標的各種型別。測量指標只能有一種類型,如果未指定類型,系統會預設為 string。
部分指標類型有支援參數,詳情請參閱相關章節。
度量類型類別
每種指標類型都屬於下列其中一個類別。這些類別會決定指標類型是否執行匯總、指標類型可參照的欄位類型,以及您是否可以使用 filters 參數篩選指標類型:
- 匯總測量指標:匯總測量指標類型會執行匯總作業,例如
sum和average。匯總測量指標只能參照維度,不能參照其他測量指標。這是唯一可搭配filters參數使用的指標類型。 - 非匯總指標:顧名思義,非匯總指標是不會執行匯總作業的指標類型,例如
number和yesno。這類測量指標類型會執行基本轉換,且由於不會執行匯總,因此只能參照匯總測量指標或先前匯總的維度。您無法將filters參數與這些評估類型搭配使用。 - 後 SQL 測量指標:後 SQL 測量指標是特殊的測量指標類型,會在 Looker 產生查詢 SQL 後執行特定計算。只能參照數值指標或數值維度。您無法將
filters參數與這些評估類型搭配使用。
類型定義清單
| 類型 | 類別 | 說明 |
|---|---|---|
average |
匯總 | 產生資料欄中值的平均值 (均值) |
average_distinct |
匯總 | 使用去正規化資料時,可正確產生值的平均值 (平均數)。如需完整說明,請參閱 average_distinct 一節。 |
count |
匯總 | 產生資料列數量 |
count_distinct |
匯總 | 產生資料欄中不重複值的計數 |
date |
非匯總 | 含有日期的指標 |
list |
匯總 | 產生資料欄中的不重複值清單 |
max |
匯總 | 產生資料欄中的最大值 |
median |
匯總 | 產生資料欄中值的中間值 (中點值) |
median_distinct |
匯總 | 如果聯結導致擴散傳遞,系統會正確產生值的中間值 (中點值)。如需完整說明,請參閱 median_distinct 一節。 |
min |
匯總 | 產生資料欄中的最小值 |
number |
非匯總 | 包含數字的指標 |
percent_of_previous |
Post-SQL | 產生顯示列之間的百分比差異 |
percent_of_total |
Post-SQL | 產生每個顯示資料列的總計百分比 |
percentile |
匯總 | 在資料欄中產生指定百分位數的值 |
percentile_distinct |
匯總 | 如果聯結導致擴散傳遞,系統會正確產生指定百分位數的值。如需完整說明,請參閱 percentile_distinct 一節。 |
running_total |
Post-SQL | 為每個顯示的資料列產生累計總計 |
period_over_period |
匯總 | 參照較早時間範圍的匯總 |
string |
非匯總 | 如果指標包含字母或特殊字元 (如 MySQL 的 GROUP_CONCAT 函式) |
sum |
匯總 | 產生資料欄中的值總和 |
sum_distinct |
匯總 | 使用非正規化資料時,可正確產生值總和。如需完整說明,請參閱 sum_distinct 一節。 |
yesno |
非匯總 | 顯示某個項目是否為 True 或 False 的欄位 |
int |
非匯總 |
已移除 5.4
已替換為 type: number |
average
type: average 會計算指定欄位中的值平均值。這與 SQL 的 AVG 函式類似。不過,與原始 SQL 不同的是,即使查詢的聯結包含扇出,Looker 仍會正確計算平均值。
type: average 測量指標的 sql 參數可採用任何有效的 SQL 運算式,產生數字資料表欄、LookML 維度或 LookML 維度組合。
您可以使用 value_format 或 value_format_name 參數,設定 type: average 欄位的格式。
舉例來說,下列 LookML 會建立名為 avg_order 的欄位,方法是計算 sales_price 維度的平均值,然後以貨幣格式 ($1,234.56) 顯示:
measure: avg_order {
type: average
sql: ${sales_price} ;;
value_format_name: usd
}
average_distinct
type: average_distinct 適用於去正規化資料集。系統會根據 sql_distinct_key 參數定義的不重複值,計算指定欄位中不重複值的平均值。
這是進階概念,透過範例說明會更清楚。請參考下列非正規化資料表:
| 訂單項目 ID | 訂單 ID | 訂單運送 |
|---|---|---|
| 1 | 1 | 10.00 |
| 2 | 1 | 10.00 |
| 3 | 2 | 20.00 |
| 4 | 2 | 20.00 |
| 5 | 2 | 20.00 |
在這種情況下,您會看到每個訂單有多個資料列。因此,如果您為 order_shipping 欄新增基本type: average測量值,即使實際平均值為 15.00,您也會得到 16.00 的值。
# Will NOT calculate the correct average
measure: avg_shipping {
type: average
sql: ${order_shipping} ;;
}
如要取得準確結果,您可以使用 sql_distinct_key 參數,向 Looker 定義如何識別每個不重複的實體 (在本例中為每個不重複的訂單)。這會計算出正確的 15.00 金額:
# Will calculate the correct average
measure: avg_shipping {
type: average_distinct
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
sql_distinct_key 的每個不重複值在 sql 中都只能有一個對應值。換句話說,前例之所以有效,是因為 每個 order_id 為 1 的資料列都有相同的 order_shipping (10.00),且每個 order_id 為 2 的資料列都有相同的 order_shipping (20.00)。
您可以使用 value_format 或 value_format_name 參數,設定 type: average_distinct 欄位的格式。
count
type: count 會執行資料表計數,類似於 SQL 的 COUNT 函式。不過,與原始 SQL 不同的是,即使查詢的聯結包含擴散傳遞,Looker 仍會正確計算計數。
type: count 措施會根據資料表的主鍵執行資料表計數,因此 type: count 措施不支援 sql 參數。
如要對資料表主鍵以外的欄位執行資料表計數,請使用 type: count_distinct 測量值。或者,如果您不想使用 count_distinct,可以改用 type: number 測量 (詳情請參閱「如何計算非主要鍵」這篇社群貼文)。
舉例來說,下列 LookML 會建立 number_of_products 欄位:
view: products {
measure: number_of_products {
type: count
drill_fields: [product_details*] # optional
}
}
定義 type: count 測量值時,提供 drill_fields (適用於欄位) 參數非常常見,這樣使用者點選計數時,就能看到組成計數的個別記錄。
在「探索」中使用
type: count的指標時,視覺化會以檢視區塊名稱標示結果值,而非「計數」。為避免混淆,建議您將檢視區塊名稱設為複數,在視覺化設定中選取「系列」下方的「顯示完整欄位名稱」,或使用view_label,並將檢視區塊名稱設為複數。
您可以使用 filters 參數,為 type: count 的指標新增篩選器。
count_distinct
type: count_distinct 會計算指定欄位中不重複值的數量,並使用 SQL 的 COUNT DISTINCT 函式。
type: count_distinct 測量指標的 sql 參數可採用任何有效的 SQL 運算式,產生資料表欄、LookML 維度或 LookML 維度組合。
舉例來說,下列 LookML 會建立 number_of_unique_customers 欄位,計算不重複的客戶 ID 數量:
measure: number_of_unique_customers {
type: count_distinct
sql: ${customer_id} ;;
}
您可以使用 filters 參數,為 type: count_distinct 的指標新增篩選器。
date
type: date 用於含有日期的欄位。
type: date 評估指標的 sql 參數可採用任何有效的 SQL 運算式,並產生日期。在實務上,這種型別很少使用,因為大多數 SQL 匯總函式不會傳回日期。常見的例外狀況是日期維度的 MIN 或 MAX。
使用 type: date 建立最大或最小日期測量指標
如要建立最晚或最早日期的度量,您一開始可能會認為使用 type: max 或 type: min 的度量即可。不過,這些測量類型僅適用於數值欄位。您可以改為定義 type: date 的度量,並將 sql 參數中參照的日期欄位包裝在 MIN() 或 MAX() 函式中,藉此擷取最晚或最早日期。
假設您有一個名為 updated 的 type: time維度群組:
dimension_group: updated {
type: time
timeframes: [time, date, week, month, raw]
sql: ${TABLE}.updated_at ;;
}
您可以建立 type: date 的指標,擷取這個維度群組的最大日期,方法如下:
measure: last_updated_date {
type: date
sql: MAX(${updated_raw}) ;;
convert_tz: no
}
在本範例中,系統不會使用 type: max 的測量值建立 last_updated_date 測量值,而是將 MAX() 函式套用至 sql 參數。last_updated_date 評估指標的 convert_tz 參數也設為 no,避免評估指標中發生時區重複轉換,因為維度群組 updated 的定義中已發生時區轉換。詳情請參閱 convert_tz 參數的說明文件。
在 last_updated_date 測量的 LookML 範例中,type: date 可以省略,值會視為字串,因為 string 是 type 的預設值。不過,如果您使用 type: date,使用者就能享有更完善的篩選功能。
您可能也會發現 last_updated_date 評估指標定義參照的是 ${updated_raw} 時間範圍,而非 ${updated_date} 時間範圍。由於 ${updated_date} 傳回的值是字串,因此必須使用 ${updated_raw} 參照實際日期值。
您也可以搭配 type: date 使用 datatype 參數,指定資料庫表格使用的日期資料類型,進而提升查詢效能。
為日期時間欄建立最大值或最小值指標
計算 type: datetime 欄的最大值時,做法略有不同。在這種情況下,您要建立測量指標,但不宣告類型,如下所示:
measure: last_updated_datetime {
sql: MAX(${TABLE}.datetime_string_field) ;;
}
list
type: list 會建立指定欄位中不重複值的清單。這與 MySQL 的 GROUP_CONCAT 函式類似。
type: list 評估指標不需要加入 sql 參數。您可以改用 list_field 參數,指定要用來建立名單的維度。
使用方式如下:
view: view_name {
measure: field_name {
type: list
list_field: my_field_name
}
}
舉例來說,下列 LookML 會根據 name 維度建立 name_list 測量指標:
measure: name_list {
type: list
list_field: name
}
請注意以下事項:list
list測量指標類型不支援篩選。您無法在type: list測量指標上使用filters參數。list測量指標類型無法使用替換運算子 ($) 參照。您無法使用${}語法參照type: list測量指標。
list 支援的資料庫方言
如要讓 Looker 支援 Looker 專案中的 type: list,資料庫方言也必須支援這項功能。下表列出最新版 Looker 支援 type: list 的方言:
| 方言 | 是否支援? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
max
type: max 會找出指定欄位中的最大值。並使用 SQL 的 MAX 函式。
type: max 測量指標的 sql 參數可採用任何有效的 SQL 運算式,產生數字資料表欄、LookML 維度或 LookML 維度組合。
由於 type: max 評估只能與數值欄位相容,因此您無法使用 type: max 評估來找出最晚日期。不過,您可以在 type: date 測量的 sql 參數中使用 MAX() 函式,擷取最晚日期,如先前 date 部分的範例所示。
您可以使用 value_format 或 value_format_name 參數,設定 type: max 欄位的格式。
舉例來說,下列 LookML 會查看 sales_price 維度,然後建立名為 largest_order 的欄位,並以貨幣格式 ($1,234.56) 顯示:
measure: largest_order {
type: max
sql: ${sales_price} ;;
value_format_name: usd
}
您無法對字串或日期使用 type: max 測量指標,但可以手動新增 MAX 函式來建立這類欄位,如下所示:
measure: latest_name_in_alphabet {
type: string
sql: MAX(${name}) ;;
}
median
type: median 會傳回指定欄位中值的中間值。如果資料有幾個極大或極小的離群值,會導致資料的基本平均值 (平均數) 偏斜,這時中位數就特別實用。
請參考下表:
| 訂單項目 ID | 費用 | 播到一半? |
|---|---|---|
| 2 | 10.00 | |
| 4 | 10.00 | |
| 3 | 20.00 | 中點值 |
| 1 | 80.00 | |
| 5 | 90.00 |
表格是依費用排序,但這不會影響結果。average 型別會傳回 42 (將所有值加總並除以 5),而 median 型別則會傳回中點值:20.00。
如果值有偶數個,則中位數是取最接近中點的兩個值的平均數。假設有以下資料表,且資料列數量為偶數:
| 訂單項目 ID | 費用 | 播到一半? |
|---|---|---|
| 2 | 10 | |
| 3 | 20 | 最接近中間點的點 |
| 1 | 80 | 最接近中間點的後方 |
| 4 | 90 |
中位數 (中間值) 為 (20 + 80)/2 = 50。
中位數也等於第 50 個百分位數的值。
type: median 測量指標的 sql 參數可採用任何有效的 SQL 運算式,產生數字資料表欄、LookML 維度或 LookML 維度組合。
您可以使用 value_format 或 value_format_name 參數,設定 type: median 欄位的格式。
範例
舉例來說,下列 LookML 會建立名為 median_order 的欄位,方法是計算 sales_price 維度的平均值,然後以貨幣格式 ($1,234.56) 顯示:
measure: median_order {
type: median
sql: ${sales_price} ;;
value_format_name: usd
}
median注意事項
如果您在參與 fanout 的欄位中使用 median,Looker 會嘗試改用 median_distinct。不過,medium_distinct 僅支援特定方言。如果方言不支援 median_distinct,Looker 會傳回錯誤。由於 median 可視為第 50 個百分位數,因此錯誤訊息指出方言不支援不同的百分位數。
median 支援的資料庫方言
如要讓 Looker 支援 Looker 專案中的 median 型別,資料庫方言也必須支援該型別。下表列出最新版 Looker 中支援 median 類型的方言:
| 方言 | 是否支援? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
如果查詢涉及扇出,Looker 會嘗試將 median 轉換為 median_distinct。這項功能僅適用於支援 median_distinct 的方言。
median_distinct
如果加入作業涉及扇出,請使用 type: median_distinct。系統會根據 sql_distinct_key 參數定義的不重複值,計算指定欄位中不重複值的平均值。如果該指標沒有 sql_distinct_key 參數,Looker 會嘗試使用 primary_key 欄位。
請參考彙整 Order Item 和 Order 資料表的查詢結果:
| 訂單項目 ID | 訂單 ID | 訂單運送 |
|---|---|---|
| 1 | 1 | 10 |
| 2 | 1 | 10 |
| 3 | 2 | 20 |
| 4 | 3 | 50 |
| 5 | 3 | 50 |
| 6 | 3 | 50 |
在這種情況下,您會看到每筆訂單有多個資料列。這項查詢涉及擴散傳遞,因為每筆訂單都會對應到多個訂單項目。median_distinct 會將此納入考量,並找出 10、20 和 50 這幾個不同值的中位數,因此您會得到 20 這個值。
如要取得準確結果,您可以使用 sql_distinct_key 參數,向 Looker 定義如何識別每個不重複的實體 (在本例中為每個不重複的訂單)。系統會計算正確金額:
measure: median_shipping {
type: median_distinct
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
sql_distinct_key 的每個不重複值,在指標的 sql 參數中都只能有一個對應值。換句話說,上述範例之所以能運作,是因為 每個 order_id 為 1 的資料列都有相同的 order_shipping (10),且每個 order_id 為 2 的資料列都有相同的 order_shipping (20)。
您可以使用 value_format 或 value_format_name 參數,設定 type: median_distinct 欄位的格式。
median_distinct注意事項
medium_distinct 測量類型僅支援特定方言。如果方言不支援 median_distinct,Looker 會傳回錯誤。由於 median 可視為第 50 個百分位數,因此錯誤訊息指出方言不支援不同的百分位數。
median_distinct 支援的資料庫方言
如要讓 Looker 支援 Looker 專案中的 median_distinct 型別,資料庫方言也必須支援該型別。下表列出最新版 Looker 中支援 median_distinct 類型的方言:
| 方言 | 是否支援? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
min
type: min 會找出指定欄位中的最小值。並使用 SQL 的 MIN 函式。
type: min 測量指標的 sql 參數可採用任何有效的 SQL 運算式,產生數字資料表欄、LookML 維度或 LookML 維度組合。
由於 type: min 評估只能與數值欄位相容,因此您無法使用 type: min 評估來找出最早日期。不過,您可以在 type: date 評估指標的 sql 參數中使用 MIN() 函式擷取最小值,就像您可以在 type: date 評估指標中使用 MAX() 函式擷取最大日期一樣。本頁面稍早的「date」一節中已說明這點,包括在 sql 參數中使用 MAX() 函式尋找最晚日期的範例。
您可以使用 value_format 或 value_format_name 參數,設定 type: min 欄位的格式。
舉例來說,下列 LookML 會查看 sales_price 維度,然後建立名為 smallest_order 的欄位,並以貨幣格式 ($1,234.56) 顯示:
measure: smallest_order {
type: min
sql: ${sales_price} ;;
value_format_name: usd
}
您無法對字串或日期使用 type: min 測量指標,但可以手動新增 MIN 函式來建立這類欄位,如下所示:
measure: earliest_name_in_alphabet {
type: string
sql: MIN(${name}) ;;
}
number
type: number 可與數字或整數搭配使用。type: number 測量不會執行任何彙整作業,而是對其他測量執行基本轉換。如果您要定義以其他指標為基礎的指標,新指標必須為 type: number,才能避免巢狀匯總錯誤。
type: number 測量的 sql 參數可採用任何有效的 SQL 運算式,只要結果是數字或整數即可。
您可以使用 value_format 或 value_format_name 參數,設定 type: number 欄位的格式。
舉例來說,下列 LookML 會根據 total_sale_price 和 total_gross_margin 匯總指標建立名為 total_gross_margin_percentage 的指標,然後以百分比格式顯示,並保留兩位小數 (12.34%):
measure: total_sale_price {
type: sum
value_format_name: usd
sql: ${sale_price} ;;
}
measure: total_gross_margin {
type: sum
value_format_name: usd
sql: ${gross_margin} ;;
}
measure: total_gross_margin_percentage {
type: number
value_format_name: percent_2
sql: ${total_gross_margin}/ NULLIF(${total_sale_price},0) ;;
}
這個範例也使用 NULLIF() SQL 函式,避免發生除以零的錯誤。
type: number注意事項
使用 type: number 措施時,請留意下列幾項重要事項:
type: number只能對其他指標執行算術運算,不能對其他維度執行。- 在跨聯結計算時,Looker 對稱式匯總函式不會保護指標
type: number的 SQL 中的匯總函式。 filters參數無法與type: number評估指標搭配使用,但請參閱filters說明文件瞭解替代方案。type: number措施不會向使用者提供建議。
percent_of_previous
type: percent_of_previous 會計算儲存格與同一資料欄中前一個儲存格的百分比差異。
type: percent_of_previous 測量的 sql 參數必須參照其他數值測量。
您可以使用 value_format 或 value_format_name 參數,設定 type: percent_of_previous 欄位的格式。不過,value_format_name 參數的百分比格式不適用於 type: percent_of_previous 指標。這些百分比格式會將值乘以 100,導致先前計算的百分比結果有誤。
這個 LookML 範例會建立以 count 測量值為基礎的 count_growth 測量值:
measure: count_growth {
type: percent_of_previous
sql: ${count} ;;
}
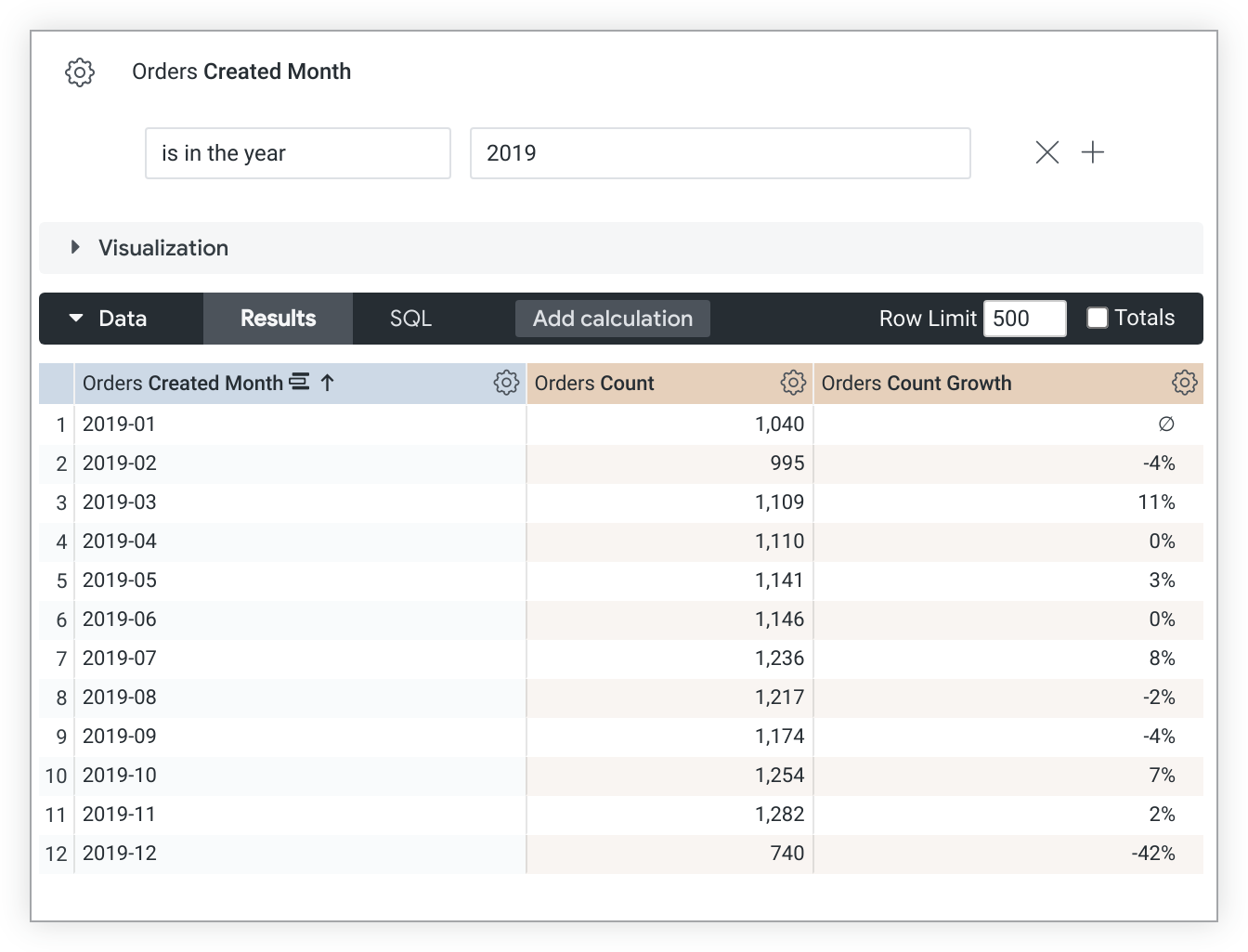
請注意,percent_of_previous 值取決於排列順序。如果變更排序方式,必須重新執行查詢,重新計算 percent_of_previous 值。如果查詢經過樞紐分析,percent_of_previous 會在資料列中執行,而不是在資料欄中執行。你無法變更這項行為。
此外,percent_of_previous 測量指標是在資料從資料庫傳回後計算,也就是說,您不應在其他指標中參照 percent_of_previous 指標,因為這類指標的計算時間可能不同,因此您可能無法取得準確結果。這也表示無法篩選 percent_of_previous 指標。
這類指標的一項應用是「與前一期比較」(PoP) 分析,這種分析模式會評估當前情況,並與過去類似期間的相同評估結果進行比較。如要進一步瞭解 PoP,請參閱 Looker 社群文章「如何進行同期比較分析」和「Looker 中的同期比較 (PoP) 分析方法」。
percent_of_total
type: percent_of_total 會計算儲存格在欄總計中所占的比例。百分比的計算依據是查詢傳回的總列數,而非所有可能的總列數。不過,如果查詢傳回的資料超過資料列限制,欄位值會顯示為空值,因為系統需要完整結果才能計算總百分比。
type: percent_of_total 測量的 sql 參數必須參照其他數值測量。
您可以使用 value_format 或 value_format_name 參數,設定 type: percent_of_total 欄位的格式。不過,value_format_name 參數的百分比格式不適用於 type: percent_of_total 指標。這些百分比格式會將值乘以 100,導致 percent_of_total 計算結果有誤。
這個 LookML 範例會建立以 total_gross_margin 測量值為基礎的 percent_of_total_gross_margin 測量值:
measure: percent_of_total_gross_margin {
type: percent_of_total
sql: ${total_gross_margin} ;;
}
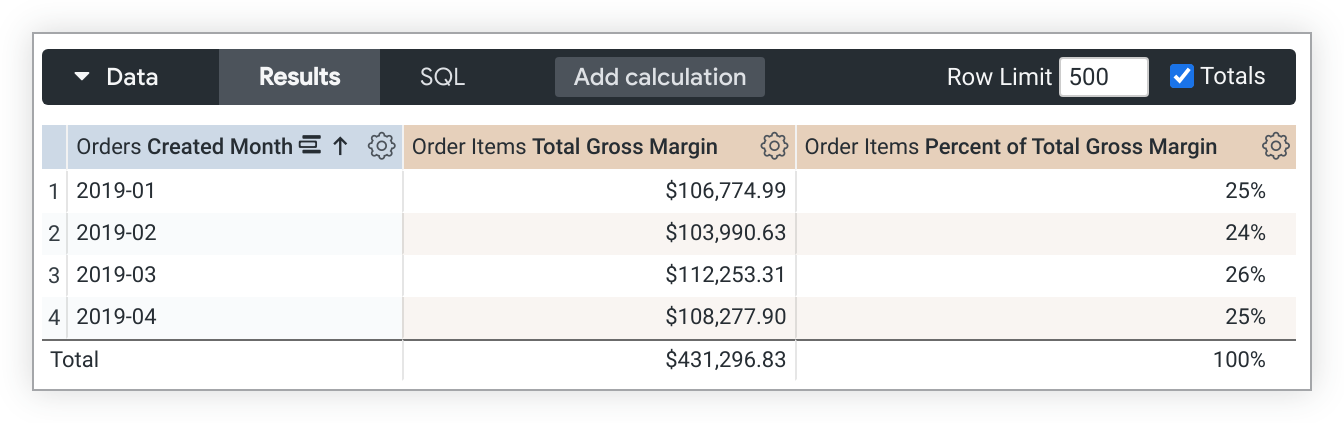
如果查詢經過樞紐分析,percent_of_total 會在資料列中執行,而不是在資料欄中執行。如果這不是您要的結果,請在指標定義中加入 direction: "column"。
此外,percent_of_total 測量指標是在資料從資料庫傳回後計算,也就是說,您不應在其他指標中參照 percent_of_total 指標,因為這類指標的計算時間可能不同,因此您可能無法取得準確結果。這也表示無法篩選 percent_of_total 指標。
percentile
type: percentile 會傳回指定欄位中位於指定百分位數的值。舉例來說,指定第 75 個百分位數會傳回的值,大於資料集中 75% 的其他值。
為找出要傳回的值,Looker 會計算資料值的總數,然後將指定百分位數乘以資料值的總數。無論資料實際排序方式為何,Looker 都會以遞增值識別資料值的相對順序。如以下兩節所述,Looker 傳回的資料值取決於計算結果是否為整數。
如果計算出的值不是整數
Looker 會將計算值無條件進位,並用來找出要傳回的資料值。在這個包含 19 個測驗分數的範例中,第 75 個百分位數為 19 * 0.75 = 14.25,也就是說,前 14 個資料值 (第 15 個位置以下) 占了 75%。因此,Looker 會傳回第 15 個資料值 (87),因為該值大於 75% 的資料值。

如果計算出的值是整數
在這個稍微複雜的案例中,Looker 會傳回該位置的資料值和後續資料值的平均值。為瞭解這點,請考慮一組 20 個測驗分數:第 75 個百分位數會以 20 * .75 = 15 識別,這表示第 15 個位置的資料值屬於第 75 個百分位數,而我們需要傳回高於 75% 資料值的值。Looker 會傳回第 15 個位置 (82) 和第 16 個位置 (87) 的平均值,確保 75% 該平均值 (84.5) 不存在於資料值集中,但會大於 75% 的資料值。

必要和選用參數
使用 percentile: 關鍵字指定分數值,也就是應低於傳回值的資料百分比。舉例來說,使用 percentile: 75 可指定資料順序中第 75 個百分位數的值,使用 percentile: 10 則可傳回第 10 個百分位數的值。如要找出第 50 個百分位數的值,可以指定 percentile: 50,或直接使用中位數類型。
type: percentile 測量指標的 sql 參數可採用任何有效的 SQL 運算式,產生數字資料表欄、LookML 維度或 LookML 維度組合。
您可以使用 value_format 或 value_format_name 參數,設定 type: percentile 欄位的格式。
範例
舉例來說,下列 LookML 會建立名為 test_scores_75th_percentile 的欄位,傳回 test_scores 維度第 75 個百分位數的值:
measure: test_scores_75th_percentile {
type: percentile
percentile: 75
sql: ${TABLE}.test_scores ;;
}
percentile注意事項
如果您在參與擴散傳遞的欄位中使用 percentile,Looker 會嘗試改用 percentile_distinct。如果方言不支援 percentile_distinct,Looker 會傳回錯誤。詳情請參閱支援的 percentile_distinct 方言。
percentile 支援的資料庫方言
如要讓 Looker 支援 Looker 專案中的 percentile 型別,資料庫方言也必須支援該型別。下表列出最新版 Looker 中支援 percentile 類型的方言:
| 方言 | 是否支援? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
percentile_distinct
type: percentile_distinct 是 百分位數的特殊形式,當聯結涉及擴散傳遞時,就應使用這項指標。系統會根據 sql_distinct_key 參數定義的唯一值,使用指定欄位中的非重複值。如果該指標沒有 sql_distinct_key 參數,Looker 會嘗試使用 primary_key 欄位。
請參考彙整 Order Item 和 Order 資料表的查詢結果:
| 訂單項目 ID | 訂單 ID | 訂單運送 |
|---|---|---|
| 1 | 1 | 10 |
| 2 | 1 | 10 |
| 3 | 2 | 20 |
| 4 | 3 | 50 |
| 5 | 3 | 50 |
| 6 | 3 | 50 |
| 7 | 4 | 70 |
| 8 | 4 | 70 |
| 9 | 5 | 110 |
| 10 | 5 | 110 |
在這種情況下,您會看到每筆訂單有多個資料列。這項查詢涉及擴散傳遞,因為每筆訂單都會對應到多個訂單項目。percentile_distinct 會將此納入考量,並使用 10、20、50、70 和 110 這幾個相異值找出百分位數值。第 25 個百分位數會傳回第二個相異值 (即 20),而第 80 個百分位數會傳回第四個和第五個相異值的平均值 (即 90)。
必要和選用參數
使用 percentile: 關鍵字指定分數值。舉例來說,使用 percentile: 75 可指定資料順序中第 75 個百分位數的值,使用 percentile: 10 則可傳回第 10 個百分位數的值。如要尋找第 50 個百分位數的值,可以改用 median_distinct 類型。
如要取得準確結果,請使用 sql_distinct_key 參數,指定 Looker 應如何識別每個不重複的實體 (在本例中,即每個不重複的訂單)。
以下範例說明如何使用 percentile_distinct 傳回第 90 個百分位數的值:
measure: order_shipping_90th_percentile {
type: percentile_distinct
percentile: 90
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
sql_distinct_key 的每個不重複值,在指標的 sql 參數中都只能有一個對應值。換句話說,上述範例之所以能運作,是因為 每個 order_id 為 1 的資料列都有相同的 order_shipping (10),且每個 order_id 為 2 的資料列都有相同的 order_shipping (20)。
您可以使用 value_format 或 value_format_name 參數,設定 type: percentile_distinct 欄位的格式。
percentile_distinct注意事項
如果方言不支援 percentile_distinct,Looker 會傳回錯誤。詳情請參閱支援的 percentile_distinct 方言。
percentile_distinct 支援的資料庫方言
如要讓 Looker 支援 Looker 專案中的 percentile_distinct 型別,資料庫方言也必須支援該型別。下表列出最新版 Looker 中支援 percentile_distinct 類型的方言:
| 方言 | 是否支援? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
period_over_period
如果方言支援按日期範圍比較的指標,您可以建立 type: period_over_period 的 LookML 指標,藉此建立按日期範圍比較 (PoP) 的指標。PoP 指標會參照較早時間範圍的匯總資料。
以下是 PoP 衡量指標範例,可提供上個月的訂單數:
measure: orders_last_month {
type: period_over_period
based_on: orders.count
based_on_time: orders.created_month
period: month
kind: previous
}
含有 type: period_over_period 的指標也必須具備下列子參數:
如需更多資訊和範例,請參閱「Looker 中的週期性指標」。
running_total
type: running_total 會計算資料欄中儲存格的累計總和。除非資料列是透視表結果,否則無法用來計算資料列的總和。
type: running_total 測量的 sql 參數必須參照其他數值測量。
您可以使用 value_format 或 value_format_name 參數,設定 type: running_total 欄位的格式。
下列 LookML 範例會建立以 total_sale_price 評估指標為基礎的 cumulative_total_revenue 評估指標:
measure: cumulative_total_revenue {
type: running_total
sql: ${total_sale_price} ;;
value_format_name: usd
}
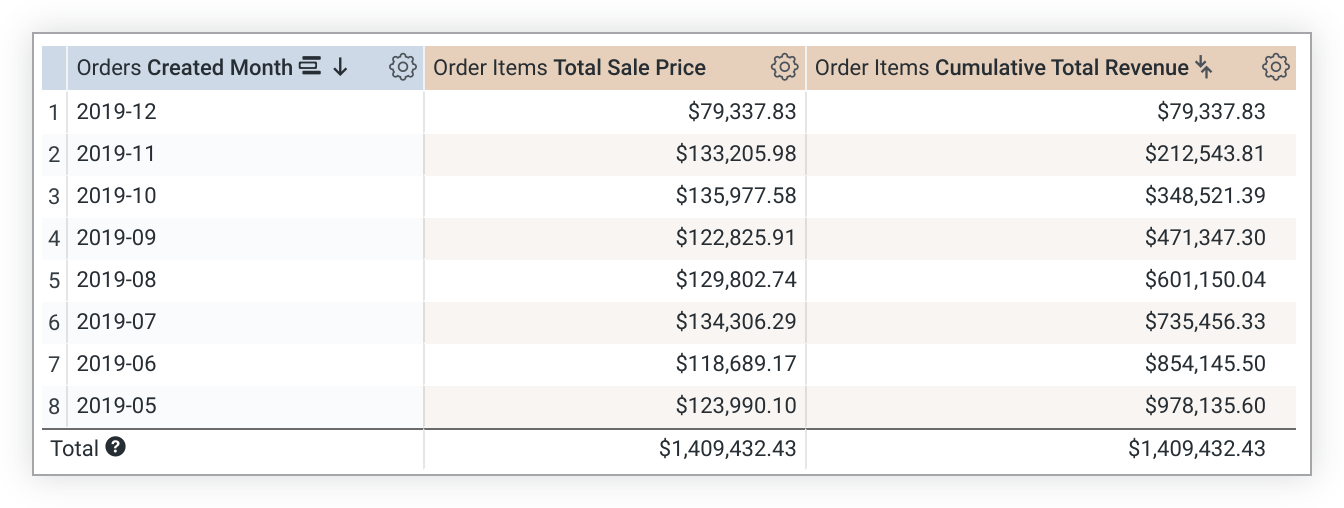
請注意,running_total 值取決於排列順序。如果變更排序方式,必須重新執行查詢,重新計算 running_total 值。如果查詢經過樞紐分析,running_total 會在資料列中執行,而不是在資料欄中執行。如果這不是您要的結果,請在指標定義中加入 direction: "column"。
此外,running_total 測量指標是在資料從資料庫傳回後計算,也就是說,您不應在其他指標中參照 running_total 指標,因為這類指標的計算時間可能不同,因此您可能無法取得準確結果。這也表示無法篩選 running_total 指標。
string
type: string 用於含有字母或特殊字元的欄位。
type: string 測量的 sql 參數可採用任何有效的 SQL 運算式,並產生字串。在實務上,這個型別很少使用,因為大多數的 SQL 匯總函式不會傳回字串。其中一個常見的例外狀況是 MySQL 的 GROUP_CONCAT 函式,但 Looker 會提供 type: list 來處理這類情況。
舉例來說,下列 LookML 會合併名為 category 的欄位不重複值,建立 category_list 欄位:
measure: category_list {
type: string
sql: GROUP_CONCAT(${category}) ;;
}
在本例中,type: string 可以省略,因為 string 是 type 的預設值。
sum
type: sum 會加總指定欄位中的值。這與 SQL 的 SUM 函式類似。不過,與原始 SQL 不同的是,即使查詢的聯結包含擴散傳遞,Looker 仍會正確計算總和。
type: sum 測量指標的 sql 參數可採用任何有效的 SQL 運算式,產生數字資料表欄、LookML 維度或 LookML 維度組合。
您可以使用 value_format 或 value_format_name 參數,設定 type: sum 欄位的格式。
舉例來說,下列 LookML 會加總 sales_price 維度,然後以貨幣格式 ($1,234.56) 顯示,藉此建立名為 total_revenue 的欄位:
measure: total_revenue {
type: sum
sql: ${sales_price} ;;
value_format_name: usd
}
sum_distinct
type: sum_distinct 適用於去正規化資料集。根據 sql_distinct_key 參數定義的不重複值,加總指定欄位中的非重複值。
這是進階概念,透過範例說明會更清楚。請參考下列非正規化資料表:
| 訂單項目 ID | 訂單 ID | 訂單運送 |
|---|---|---|
| 1 | 1 | 10.00 |
| 2 | 1 | 10.00 |
| 3 | 2 | 20.00 |
| 4 | 2 | 20.00 |
| 5 | 2 | 20.00 |
在這種情況下,您會看到每個訂單有多個資料列。因此,如果您為「order_shipping」欄新增 type: sum 衡量指標,即使收取的運費總額實際上為 30.00,您也會得到 80.00 的總額。
# Will NOT calculate the correct shipping amount
measure: total_shipping {
type: sum
sql: ${order_shipping} ;;
}
如要取得準確結果,您可以使用 sql_distinct_key 參數,向 Looker 定義如何識別每個不重複的實體 (在本例中為每個不重複的訂單)。這會計算出正確的 30.00 金額:
# Will calculate the correct shipping amount
measure: total_shipping {
type: sum_distinct
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
sql_distinct_key 的每個不重複值在 sql 中都只能有一個對應值。換句話說,前例之所以有效,是因為 每個 order_id 為 1 的資料列都有相同的 order_shipping (10.00),且每個 order_id 為 2 的資料列都有相同的 order_shipping (20.00)。
您可以使用 value_format 或 value_format_name 參數,設定 type: sum_distinct 欄位的格式。
yesno
type: yesno 會建立欄位,指出某件事是 true 還是 false。在探索使用者介面中,這些值會顯示為「是」和「否」。
type: yesno 措施的 sql 參數會採用有效的 SQL 運算式,評估結果為 TRUE 或 FALSE。如果條件評估結果為 TRUE,系統會向使用者顯示「是」;否則會顯示「否」。
type: yesno 測量指標的 SQL 運算式只能包含匯總,也就是 SQL 匯總或 LookML 測量指標的參照。如要建立包含 LookML 維度參照或非匯總 SQL 運算式的 yesno 欄位,請使用 type: yesno 的 維度,而非指標。
與使用 type: number 的指標類似,使用 type: yesno 的指標不會進行任何匯總,只會參照其他匯總。
舉例來說,下列 total_sale_price 測量指標範例是訂單中訂單項目的銷售總價總和。第二項指標稱為「is_large_total」,type: yesno。is_large_total 測量指標的 sql 參數會評估 total_sale_price 值是否大於 $1,000 美元。
measure: total_sale_price {
type: sum
value_format_name: usd
sql: ${sale_price} ;;
drill_fields: [detail*]
}
measure: is_large_total {
description: "Is order total over $1000?"
type: yesno
sql: ${total_sale_price} > 1000 ;;
}
如要在其他欄位中參照 type: yesno 欄位,請將 type: yesno 欄位視為布林值 (換句話說,視為已包含 true 或 false 值)。例如:
measure: is_large_total {
description: "Is order total over $1000?"
type: yesno
sql: ${total_sale_price} > 1000 ;;
}
# This is correct:
measure: reward_points {
type: number
sql: CASE WHEN ${is_large_total} THEN 200 ELSE 100 END ;;
}
# This is NOT correct:
measure: reward_points {
type: number
sql: CASE WHEN ${is_large_total} = 'Yes' THEN 200 ELSE 100 END ;;
}