
用量
explore: explore_name {
aggregate_table: table_name {
query: {
dimensions: [dimension1, dimension2, ... ]
measures: [measure1, measure2, ... ]
sorts: [field1: asc, field2: desc, ... ]
filters: [field1: "value1", field2: "value2", ... ]
timezone: timezone
}
materialization: {
...
}
}
...
}
|
階層
aggregate_table |
預設值
無
接受 匯總表格的名稱、用於定義表格的 query 子參數,以及用於定義表格持續性策略的 materialization 子參數
特別規則
|
定義
aggregate_table 參數用於建立匯總資料表,盡量減少須對資料庫中大型資料表執行查詢的次數。
Looker 會運用匯總感知邏輯,在資料庫中找出最小、最有效率的匯總資料表來執行查詢,同時維持結果的正確性。(如要瞭解如何建立匯總資料表,請參閱「匯總品牌知名度」說明文件頁面)。
對於資料庫中的超大型資料表,您可以建立較小的匯總資料表,將資料依不同屬性組合分組。匯總資料表就像匯總或彙整資料的表格,Looker 可在查詢時盡可能使用這類資料表,而非原始的大型資料表。
建立匯總資料表後,您可以在「探索」中執行查詢,看看 Looker 使用哪些匯總資料表。詳情請參閱「匯總感知」說明文件頁面中的「判斷查詢使用哪個匯總資料表」一節。
如要瞭解系統未採用匯總資料表的常見原因,請參閱「匯總認知度」說明文件頁面的「疑難排解」一節。
在 LookML 中定義匯總表格
每個 aggregate_table 參數的名稱在特定 explore 中不得重複。
aggregate_table 參數具有 query 和 materialization 子參數。
query
query 參數會定義匯總資料表的查詢,包括要使用的維度和指標。query 參數包含下列子參數:
| 參數名稱 | 說明 | 範例 |
|---|---|---|
dimensions |
以半形逗號分隔的「探索」維度清單,這些維度會納入匯總資料表。dimensions 欄位採用以下格式:dimensions: [dimension1, dimension2, ...]
清單中的每個維度都必須在查詢的「探索」檢視表檔案中定義為 dimension。如要納入定義為「探索」查詢中 filter 欄位的欄位,可以將其新增至匯總資料表查詢中的 filters 清單。
|
dimensions: [orders.created_month, orders.country] |
measures |
以半形逗號分隔的清單,列出要納入匯總表格的 Explore 測量指標。measures 欄位採用以下格式:measures: [measure1, measure2, ...]
如要瞭解匯總知名度支援的指標類型,請參閱「匯總知名度」說明文件頁面的「指標類型因素」一節。
|
measures: [orders.count] |
filters |
視需要將篩選器新增至 query。篩選條件會新增至產生匯總表格的 SQL WHERE 子句。
filters 欄位採用以下格式:filters: [field1: "value1", field2: "value2", ...]
如要瞭解篩選器如何避免系統使用匯總表格,請參閱「匯總資料認知」說明文件頁面的「篩選器因素」一節。 |
filters: [orders.country: "United States", orders.state: "California"]
|
sorts |
(選用) 指定 query 的排序欄位和排序方向 (遞增或遞減)。
sorts 欄位採用以下格式:sorts: [field1: asc|desc, field2: asc|desc, ...]
|
[orders.country: asc, orders.state: desc] |
timezone |
設定 query 的時區。如果未指定時區,匯總表格不會執行任何時區轉換,而是使用資料庫時區。
如要瞭解如何設定時區,以便將匯總表格做為查詢來源,請參閱「匯總資料感知」說明文件頁面的「時區因素」一節。
在 IDE 中輸入 timezone 參數時,IDE 會自動建議時區值。IDE 也會在「快速說明」面板中顯示支援的時區值清單。 |
timezone: America/Los_Angeles |
materialization
materialization 參數會指定匯總表格的持續性策略,以及 SQL 方言可能支援的其他選項,例如分配、分割、索引和叢集。
匯總資料表必須保留在資料庫中,才能供匯總感知功能使用。匯總表格的 materialization 參數必須包含下列其中一個子參數,才能指定保留策略:
此外,視 SQL 方言而定,您的匯總表格可能支援下列 materialization 子參數:
如要建立增量匯總表格,請使用下列 materialization 子參數:
datagroup_trigger
使用 datagroup_trigger 參數,根據模型檔案中定義的現有 datagroup 觸發匯總表格重新產生:
explore: event {
aggregate_table: monthly_orders {
materialization: {
datagroup_trigger: order_datagroup
}
query: {
...
}
}
...
}
sql_trigger_value
使用 sql_trigger_value 參數,根據您提供的 SQL 陳述式,觸發匯總表格的重新生成作業。如果 SQL 陳述式的結果與先前的值不同,系統會重新產生表格。日期變更時,系統會重新產生這項 sql_trigger_value 陳述式:
explore: event {
aggregate_table: monthly_orders {
materialization: {
sql_trigger_value: SELECT CURDATE() ;;
}
query: {
...
}
}
...
}
persist_for
匯總資料表也支援 persist_for 參數。不過,persist_for策略可能無法為整體知名度帶來最佳成效。這是因為使用者執行依賴 persist_for 資料表的查詢時,Looker 會根據 persist_for 設定檢查資料表的存續時間。如果資料表比 persist_for 設定還舊,系統會在執行查詢前重新產生資料表。如果年齡小於 persist_for 設定,系統會使用現有資料表。因此,除非使用者在 persist_for 時間內執行查詢,否則必須重建匯總表格,才能用於匯總認知度。
explore: event {
aggregate_table: monthly_orders {
materialization: {
persist_for: "90 minutes"
}
query: {
...
}
}
...
}
除非您瞭解限制,且有 persist_for 實作的特定用途,否則最好使用 datagroup_trigger 或 sql_trigger_value 做為匯總資料表的持續性策略。
cluster_keys
cluster_keys 參數可讓您在 BigQuery 或 Snowflake 的分區資料表中新增分群資料欄。叢集處理會根據叢集資料欄的值,排序分區中的資料,並將叢集資料欄分到理想大小的儲存區塊中。
詳情請參閱 cluster_keys 參數說明文件頁面。
distribution
distribution 參數可讓您指定要套用分配鍵的匯總資料表中的資料欄。distribution 僅適用於 Redshift 和 Aster 資料庫。如要使用其他 SQL 方言 (例如 MySQL 和 Postgres),請改用 indexes。
詳情請參閱 distribution 參數說明文件頁面。
distribution_style
distribution_style 參數可讓您指定匯總資料表的查詢在 Redshift 資料庫節點中的分配方式:
distribution_style: all表示所有資料列都已完整複製到每個節點。distribution_style: even會指定平均分配,因此資料列會以循環方式分配至不同節點。
詳情請參閱 distribution_style 參數說明文件頁面。
indexes
indexes 參數可讓您將索引套用至匯總表格的資料欄。
詳情請參閱 indexes 參數說明文件頁面。
partition_keys
partition_keys 參數會定義資料欄陣列,匯總表格將依這些資料欄分區。partition_keys 支援可分區資料欄的資料庫方言。如果查詢是依分區資料欄篩選,資料庫只會掃描包含篩選資料的分區,而不是掃描整個資料表。partition_keys 僅支援 Presto 和 BigQuery 方言。
詳情請參閱 partition_keys 參數說明文件頁面。
publish_as_db_view
publish_as_db_view 參數可讓您標記匯總資料表,以便在 Looker 以外的地方查詢。如果匯總表格的 publish_as_db_view 設為 yes,Looker 會在資料庫中為匯總表格建立穩定的資料庫檢視區塊。穩定資料庫檢視區塊是在資料庫本身建立,因此可以在 Looker 以外查詢。
詳情請參閱 publish_as_db_view 參數說明文件頁面。
sortkeys
sortkeys 參數可讓您指定要套用一般排序鍵的匯總表格一或多個資料欄。
詳情請參閱 sortkeys 參數說明文件頁面。
increment_key
如果方言支援永久累加型衍生資料表,您可以在專案中建立這類資料表。永久累加型衍生資料表是 永久衍生資料表 (PDT),Looker 會將新資料附加至資料表,而不是重建整個資料表。詳情請參閱「永久累加型衍生資料表」說明文件頁面。
匯總資料表是 PDT 的一種,可透過新增 increment_key 參數累加建構。increment_key 參數會指定時間增量,系統應查詢並附加至匯總表格的最新資料。
詳情請參閱 increment_key 參數說明文件頁面。
increment_offset
increment_offset 參數會定義將資料附加至匯總表格時,要重建的先前時間週期數 (以遞增鍵的精細程度為準)。increment_offset 參數是遞增 PDT 和匯總表格的選用參數。
詳情請參閱 increment_offset 參數說明文件頁面。
從「探索」取得匯總表格 LookML
為求方便,Looker 開發人員可以使用「探索」查詢建立匯總表格,然後將 LookML 複製到 LookML 專案:
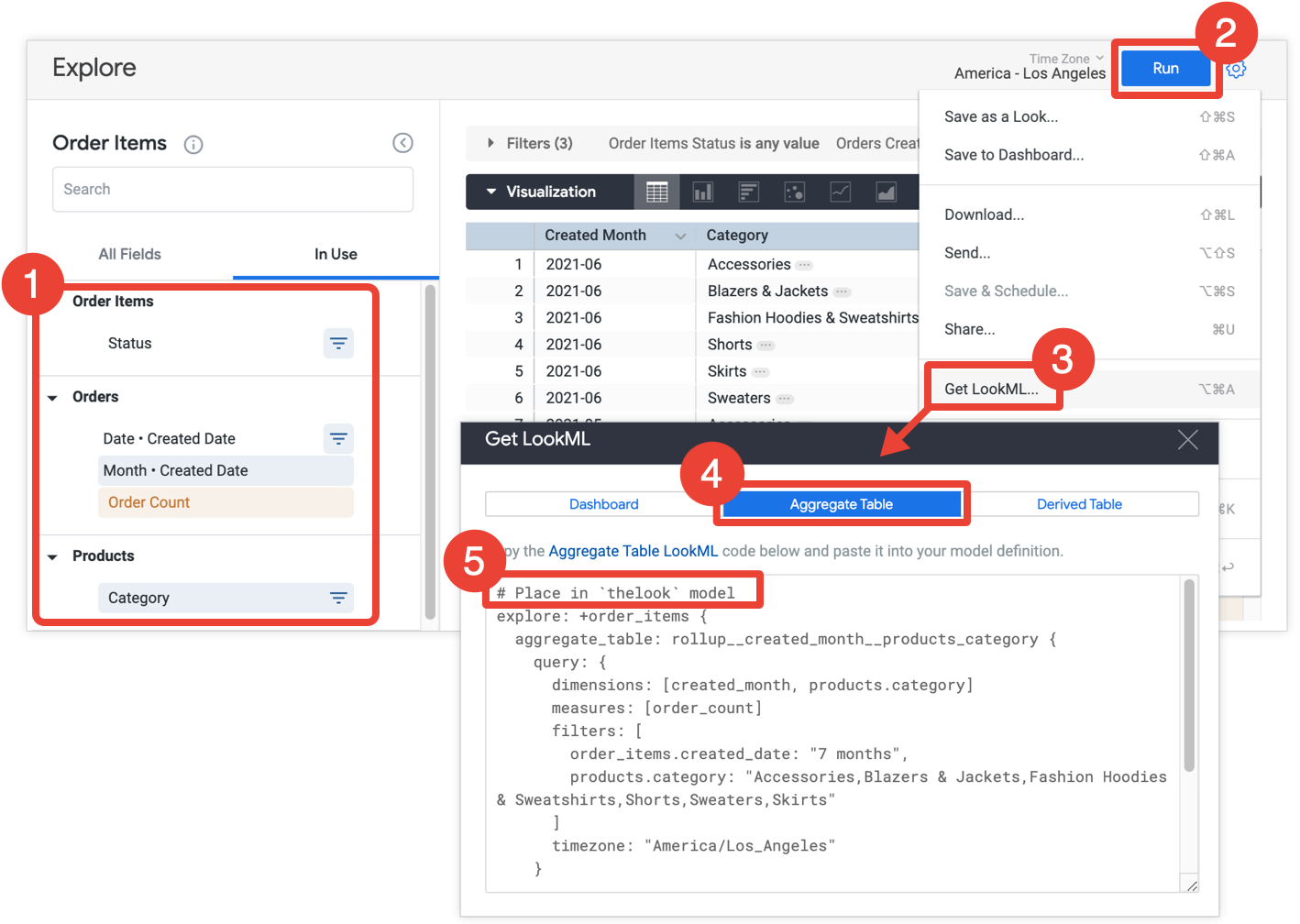
- 在「探索」中,選取要納入匯總表格的所有欄位和篩選器。
- 按一下「執行」即可取得結果。
- 從「探索」的齒輪選單中選取「取得 LookML」。這個選項僅適用於 Looker 開發人員。
- 按一下「匯總資料表」分頁標籤。
- Looker 會提供探索修改設定的 LookML,將匯總表格新增至探索。複製 LookML 並貼到相關聯的模型檔案中,該檔案會顯示在探索修改設定之前的註解中。如果探索定義在「探索」檔案中,而非模型檔案,您可以將修改設定新增至探索檔案,而非模型檔案。這兩種方式都可行。
如要修改匯總表格 LookML,可以使用本頁「在 LookML 中定義匯總表格」一節所述的參數。您可以重新命名匯總表格,而不變更其對原始「探索」查詢的適用性。不過,對匯總表格進行任何其他變更,都可能會影響 Looker 對「探索」查詢使用匯總表格的能力。如需匯總表格最佳化提示,請參閱「匯總感知」說明頁面的「設計匯總表格」一節,確保匯總表格用於匯總感知。
從資訊主頁取得匯總表格 LookML
Looker 開發人員也可以選擇取得資訊主頁上所有圖塊的匯總表格 LookML,然後將 LookML 複製到 LookML 專案。
建立匯總資料表可大幅提升資訊主頁的效能,尤其是查詢巨量資料集的圖塊。
如果您有 develop 權限,可以開啟資訊主頁,從資訊主頁的三點選單中選取「取得 LookML」,然後選擇「匯總資料表」分頁,取得 LookML 來建立資訊主頁的匯總資料表:
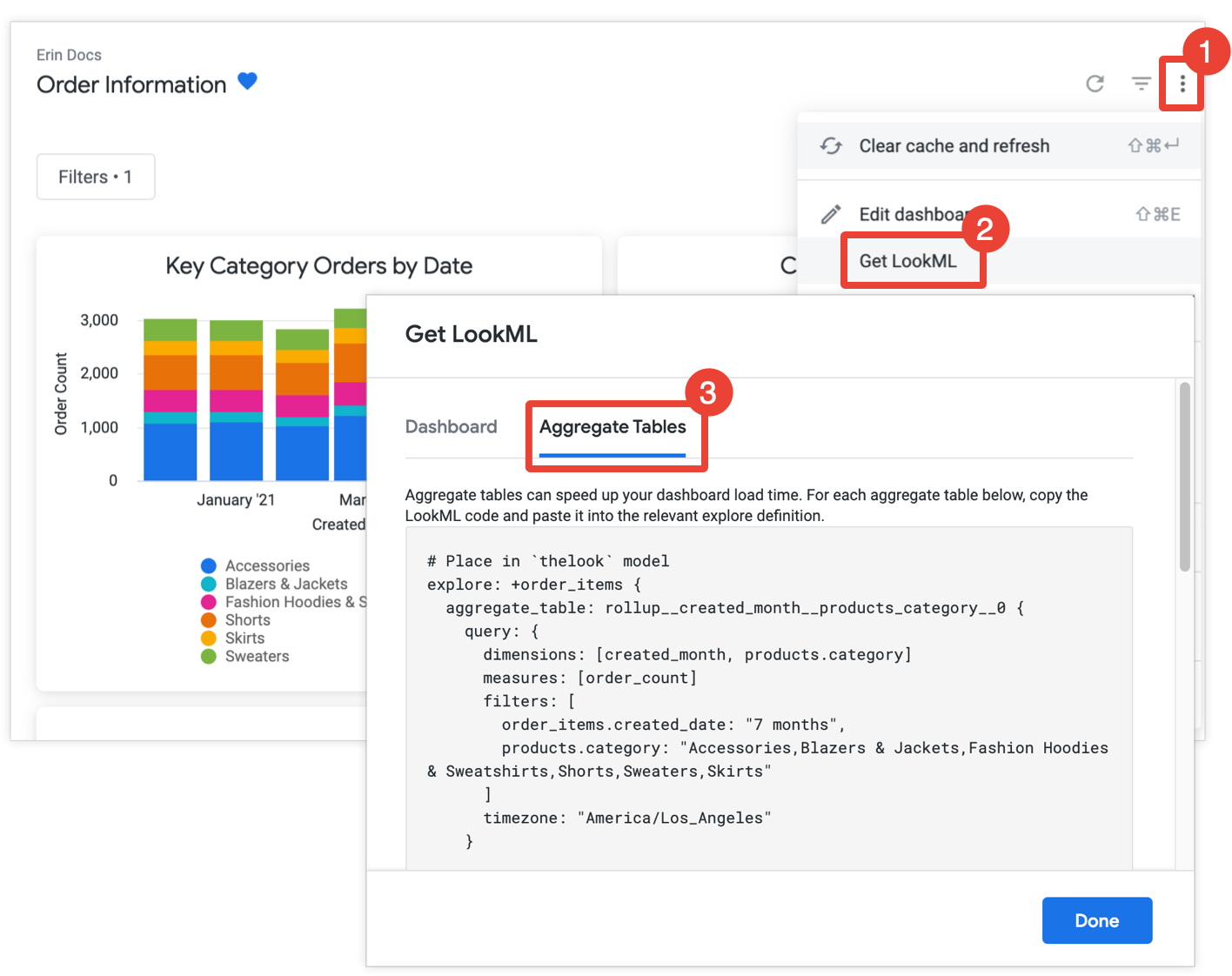
如果圖塊尚未透過匯總感知功能完成最佳化,Looker 會提供探索修改設定的 LookML,將匯總表格新增至探索。如果資訊主頁包含來自同一項探索的多個圖塊,Looker 會將所有匯總資料表放在單一探索修正項目中。為減少產生的匯總表格數量,Looker 會判斷產生的匯總表格是否可用於多個圖塊,如果是,則會捨棄可用於較少圖塊的任何多餘匯總表格。
將每個探索修正內容複製並貼到相關聯的模型檔案中,探索修正內容前的註解會指出該模型檔案。如果探索是在獨立的探索檔案中定義,而非模型檔案,您可以將修正內容新增至探索檔案,而非模型檔案。這兩種做法都可行。
如果資訊主頁篩選器套用至圖塊,Looker 會將篩選器的維度新增至圖塊的匯總表格,以便圖塊使用匯總表格。這是因為只有在查詢的篩選條件參照的欄位可做為匯總資料表中的維度時,查詢才能使用匯總資料表。如需相關資訊,請參閱「匯總認知度」說明文件頁面。
如要修改匯總表格 LookML,可以使用本頁「在 LookML 中定義匯總表格」一節所述的參數。您可以重新命名匯總資料表,而不必變更其對原始資訊主頁動態磚的適用性,但對匯總資料表進行任何其他變更,都可能會影響 Looker 使用匯總資料表來顯示資訊主頁的能力。如要取得匯總資料表最佳化提示,確保匯總感知功能會使用這些資料表,請參閱匯總感知說明文件頁面的「設計匯總資料表」一節。
範例
下列範例會為「event」探索建立 monthly_orders 匯總表格。匯總表格會建立每月訂單數。Looker 會使用匯總表格,查詢精細程度為每月的訂單數,例如查詢每年、每季和每月的訂單數。
匯總表格是使用 資料群組 orders_datagroup 設定的持續性。此外,匯總表格是使用 publish_as_db_view: yes 定義,這表示 Looker 會在資料庫中為匯總表格建立穩定的資料庫檢視畫面。
匯總表格定義如下:
explore: event {
aggregate_table: monthly_orders {
materialization: {
datagroup_trigger: orders_datagroup
publish_as_db_view: yes
}
query: {
dimensions: [orders.created_month]
measures: [orders.count]
filters: [orders.created_date: "1 year", orders.status: "fulfilled"]
timezone: America/Los_Angeles
}
}
}
注意事項
如需策略性建立匯總資料表的訣竅,請參閱「匯總感知」說明文件頁面的「設計匯總資料表」一節:
匯總感知功能的方言支援
能否使用匯總感知功能,取決於 Looker 連線使用的資料庫方言。在最新版 Looker 中,下列方言支援匯總感知功能:
| 方言 | 是否支援? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |