
Penggunaan
explore: explore_name {
aggregate_table: table_name {
query: {
dimensions: [dimension1, dimension2, ... ]
measures: [measure1, measure2, ... ]
sorts: [field1: asc, field2: desc, ... ]
filters: [field1: "value1", field2: "value2", ... ]
timezone: timezone
}
materialization: {
...
}
}
...
}
|
Hierarki
aggregate_table |
Nilai Default
Tidak ada
Menerima
Nama untuk tabel gabungan, subparameter query untuk menentukan tabel, dan subparameter materialization untuk menentukan strategi persistensi tabel
Aturan Khusus
|
Definisi
Parameter aggregate_table digunakan untuk membuat tabel gabungan yang akan meminimalkan jumlah kueri yang diperlukan untuk tabel besar dalam database Anda.
Looker menggunakan logika aggregate awareness untuk menemukan tabel gabungan terkecil dan paling efisien yang tersedia di database Anda untuk menjalankan kueri sekaligus mempertahankan kebenaran. (Lihat halaman dokumentasi Kewaspadaan gabungan untuk mengetahui ringkasan dan strategi pembuatan tabel gabungan.)
Untuk tabel yang sangat besar di database Anda, Anda dapat membuat tabel data gabungan yang lebih kecil, yang dikelompokkan berdasarkan berbagai kombinasi atribut. Tabel gabungan bertindak sebagai rollup atau tabel ringkasan yang dapat digunakan Looker untuk kueri jika memungkinkan, bukan tabel besar asli.
Setelah membuat tabel gabungan, Anda dapat menjalankan kueri di Eksplorasi untuk melihat tabel gabungan mana yang digunakan Looker. Untuk mengetahui informasi selengkapnya, lihat bagian Menentukan tabel gabungan mana yang digunakan untuk kueri di halaman dokumentasi Pengenalan agregat.
Lihat bagian Pemecahan masalah di halaman dokumentasi Kesadaran agregat untuk mengetahui alasan umum tabel agregat tidak digunakan.
Menentukan tabel gabungan di LookML
Setiap parameter aggregate_table harus memiliki nama yang unik dalam explore tertentu.
Parameter aggregate_table memiliki subparameter query dan materialization.
query
Parameter query menentukan kueri untuk tabel gabungan, termasuk dimensi dan ukuran yang akan digunakan. Parameter query mencakup subparameter berikut:
| Nama Parameter | Deskripsi | Contoh |
|---|---|---|
dimensions |
Daftar dimensi yang dipisahkan koma dari Eksplorasi yang akan disertakan dalam tabel gabungan Anda. Kolom dimensions menggunakan format ini: dimensions: [dimension1, dimension2, ...]
Setiap dimensi dalam daftar ini harus ditentukan sebagai dimension dalam file tampilan untuk Eksplorasi kueri. Jika ingin menyertakan kolom yang ditentukan sebagai kolom filter dalam kueri Jelajah, Anda dapat menambahkannya ke daftar filters dalam kueri tabel gabungan.
|
dimensions: [orders.created_month, orders.country] |
measures |
Daftar ukuran yang dipisahkan koma dari Eksplorasi yang akan disertakan dalam tabel gabungan Anda. Kolom measures menggunakan format ini: measures: [measure1, measure2, ...]
Untuk mengetahui informasi tentang jenis pengukuran yang didukung untuk kesadaran agregat, lihat bagian Faktor jenis pengukuran di halaman dokumentasi Kesadaran agregat.
|
measures: [orders.count] |
filters |
Secara opsional, menambahkan filter ke query. Filter ditambahkan ke klausa WHERE dari SQL yang menghasilkan tabel gabungan.
Kolom filters menggunakan format ini: filters: [field1: "value1", field2: "value2", ...]
Untuk mengetahui informasi tentang cara filter dapat mencegah penggunaan tabel gabungan, lihat bagian Faktor filter di halaman dokumentasi Pemahaman agregasi. |
filters: [orders.country: "United States", orders.state: "California"]
|
sorts |
Secara opsional, menentukan kolom pengurutan dan arah pengurutan (menaik atau menurun) untuk query.
Kolom sorts menggunakan format ini: sorts: [field1: asc|desc, field2: asc|desc, ...]
|
[orders.country: asc, orders.state: desc] |
timezone |
Menetapkan zona waktu untuk query. Jika zona waktu tidak ditentukan, tabel gabungan tidak akan melakukan konversi zona waktu, dan akan menggunakan zona waktu database.
Untuk mengetahui informasi tentang cara menyetel zona waktu agar tabel gabungan Anda digunakan sebagai sumber kueri, lihat bagian Faktor zona waktu di halaman dokumentasi Pengenalan agregasi.
IDE menyarankan otomatis nilai zona waktu saat Anda mengetik parameter timezone di IDE. IDE juga menampilkan daftar nilai zona waktu yang didukung di panel Bantuan Cepat. |
timezone: America/Los_Angeles |
materialization
Parameter materialization menentukan strategi persistensi untuk tabel gabungan Anda, serta opsi lain untuk distribusi, partisi, indeks, dan pengelompokan yang mungkin didukung oleh dialek SQL Anda.
Agar dapat diakses untuk aggregate awareness, tabel gabungan Anda harus dipertahankan di database Anda. Parameter materialization tabel gabungan Anda harus memiliki salah satu subparameter berikut untuk menentukan strategi persistensi:
datagroup_triggersql_trigger_valuepersist_for(tidak direkomendasikan)
Selain itu, subparameter materialization berikut mungkin didukung untuk tabel gabungan Anda, bergantung pada dialek SQL Anda:
Untuk membuat tabel gabungan inkremental, gunakan subparameter materialization berikut:
datagroup_trigger
Gunakan parameter datagroup_trigger untuk memicu regenerasi tabel gabungan berdasarkan grup data yang ada yang ditentukan dalam file model:
explore: event {
aggregate_table: monthly_orders {
materialization: {
datagroup_trigger: order_datagroup
}
query: {
...
}
}
...
}
sql_trigger_value
Gunakan parameter sql_trigger_value untuk memicu pembuatan ulang tabel gabungan berdasarkan pernyataan SQL yang Anda berikan. Jika hasil pernyataan SQL berbeda dari nilai sebelumnya, tabel akan dibuat ulang. Pernyataan sql_trigger_value ini akan memicu regenerasi saat tanggal berubah:
explore: event {
aggregate_table: monthly_orders {
materialization: {
sql_trigger_value: SELECT CURDATE() ;;
}
query: {
...
}
}
...
}
persist_for
Parameter persist_for juga didukung untuk tabel gabungan. Namun, strategi persist_for mungkin tidak memberikan performa terbaik untuk awareness gabungan. Hal ini karena saat pengguna menjalankan kueri yang mengandalkan tabel persist_for, Looker akan memeriksa usia tabel berdasarkan setelan persist_for. Jika tabel lebih lama dari setelan persist_for, tabel akan dibuat ulang sebelum kueri dijalankan. Jika usia kurang dari setelan persist_for, tabel yang ada akan digunakan. Jadi, kecuali jika pengguna menjalankan kueri dalam waktu persist_for, tabel gabungan harus dibangun ulang sebelum dapat digunakan untuk kesadaran gabungan.
explore: event {
aggregate_table: monthly_orders {
materialization: {
persist_for: "90 minutes"
}
query: {
...
}
}
...
}
Kecuali jika Anda memahami batasan dan memiliki kasus penggunaan khusus untuk penerapan persist_for, sebaiknya gunakan datagroup_trigger atau sql_trigger_value sebagai strategi persistensi untuk tabel gabungan.
cluster_keys
Parameter cluster_keys memungkinkan Anda menambahkan kolom pengelompokan ke tabel berpartisi di BigQuery atau Snowflake. Pengelompokan mengurutkan data dalam partisi yang didasarkan pada nilai dalam kolom yang dikelompokkan dan mengatur kolom yang dikelompokkan dalam blok penyimpanan berukuran optimal.
Lihat halaman dokumentasi parameter cluster_keys untuk mengetahui informasi selengkapnya.
distribution
Parameter distribution memungkinkan Anda menentukan kolom dari tabel gabungan yang akan diterapkan kunci distribusinya. distribution hanya berfungsi dengan database Redshift dan Aster. Untuk dialek SQL lainnya (seperti MySQL dan Postgres), gunakan indexes.
Lihat halaman dokumentasi parameter distribution untuk mengetahui informasi selengkapnya.
distribution_style
Parameter distribution_style memungkinkan Anda menentukan cara kueri untuk tabel gabungan didistribusikan di seluruh node dalam database Redshift:
distribution_style: allmenunjukkan bahwa semua baris disalin sepenuhnya ke setiap node.distribution_style: evenmenentukan distribusi yang merata, sehingga baris didistribusikan ke berbagai node secara round-robin.
Lihat halaman dokumentasi parameter distribution_style untuk mengetahui informasi selengkapnya.
indexes
Parameter indexes memungkinkan Anda menerapkan indeks ke kolom tabel gabungan.
Lihat halaman dokumentasi parameter indexes untuk mengetahui informasi selengkapnya.
partition_keys
Parameter partition_keys menentukan array kolom yang akan digunakan untuk mempartisi tabel gabungan. partition_keys mendukung dialek database yang memiliki kemampuan untuk memartisi kolom. Saat kueri yang difilter pada kolom berpartisi dijalankan, database hanya akan memindai partisi yang menyertakan data yang difilter, bukan memindai seluruh tabel. partition_keys hanya didukung dengan dialek Presto dan BigQuery.
Lihat halaman dokumentasi parameter partition_keys untuk mengetahui informasi selengkapnya.
publish_as_db_view
Parameter publish_as_db_view memungkinkan Anda menandai tabel gabungan untuk dikueri di luar Looker. Untuk tabel gabungan dengan publish_as_db_view yang ditetapkan ke yes, Looker membuat tampilan database yang stabil di database untuk tabel gabungan. Tampilan database stabil dibuat di database itu sendiri, sehingga dapat dikueri di luar Looker.
Lihat halaman dokumentasi parameter publish_as_db_view untuk mengetahui informasi selengkapnya.
sortkeys
Parameter sortkeys memungkinkan Anda menentukan satu atau beberapa kolom tabel gabungan yang akan diterapkan kunci pengurutan reguler.
Lihat halaman dokumentasi parameter sortkeys untuk mengetahui informasi selengkapnya.
increment_key
Anda dapat membuat PDT inkremental di project jika dialek Anda mendukungnya. PDT inkremental adalah tabel turunan persisten (PDT) yang dibuat Looker dengan menambahkan data baru ke tabel, bukan membangun ulang seluruh tabel. Lihat halaman dokumentasi PDT Inkremental untuk mengetahui informasi selengkapnya.
Tabel gabungan adalah jenis PDT, dan dapat dibuat secara bertahap dengan menambahkan parameter increment_key. Parameter increment_key menentukan penambahan waktu yang datanya harus dikueri dan ditambahkan ke tabel gabungan.
Lihat halaman dokumentasi parameter increment_key untuk mengetahui informasi selengkapnya.
increment_offset
Parameter increment_offset menentukan jumlah periode waktu sebelumnya (pada perincian kunci inkremental) yang akan dibangun ulang saat menambahkan data ke tabel gabungan. Parameter increment_offset bersifat opsional untuk PDT inkremental dan tabel gabungan.
Lihat halaman dokumentasi parameter increment_offset untuk mengetahui informasi selengkapnya.
Mendapatkan LookML tabel gabungan dari Eksplorasi
Sebagai pintasan, developer Looker dapat menggunakan kueri Eksplorasi untuk membuat tabel gabungan, lalu menyalin LookML ke dalam project LookML:
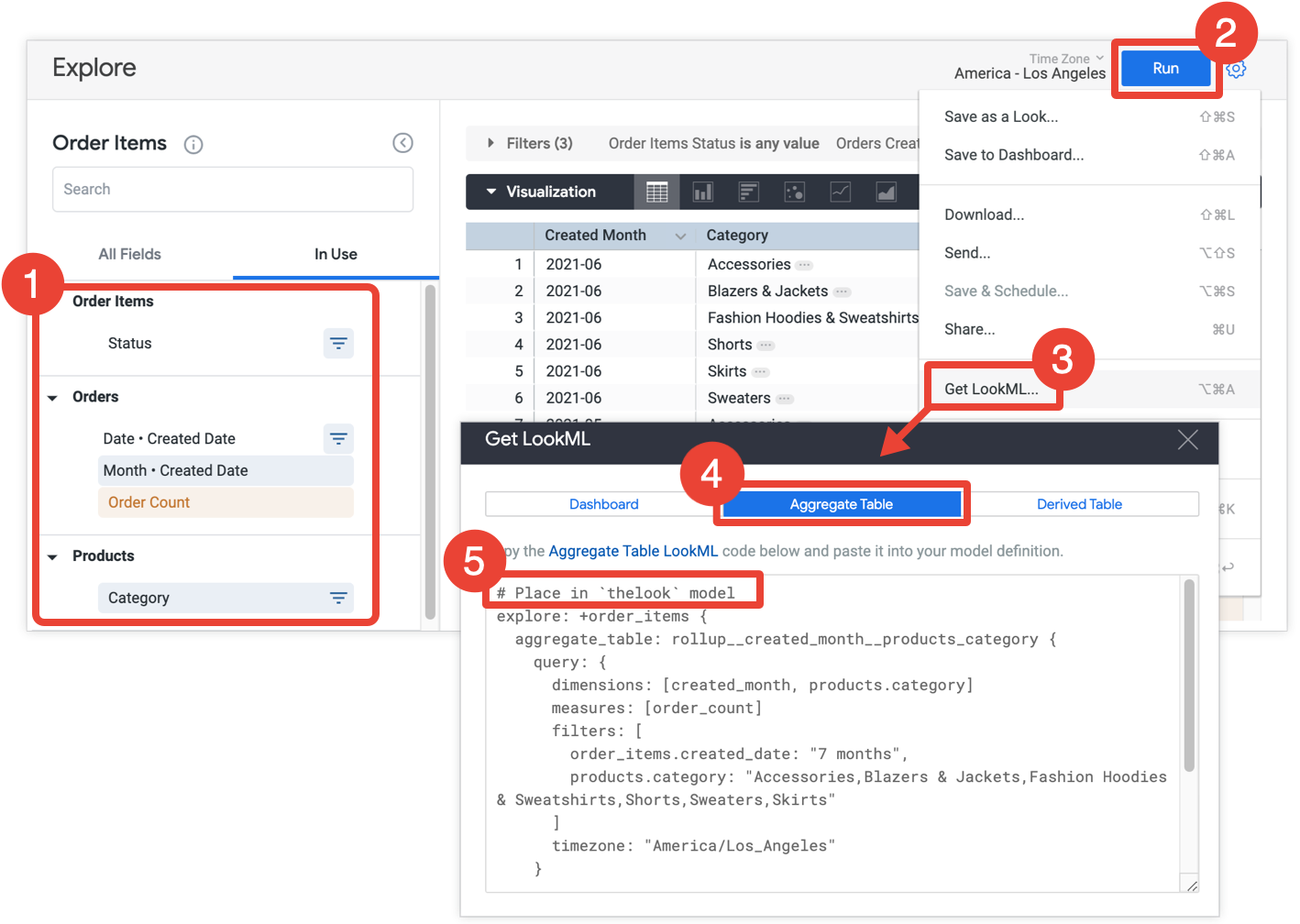
- Di Eksplorasi, pilih semua kolom dan filter yang ingin Anda sertakan dalam tabel gabungan.
- Klik Run untuk mendapatkan hasilnya.
- Pilih Get LookML dari menu roda gigi Eksplorasi. Opsi ini hanya tersedia untuk developer Looker.
- Klik tab Tabel Gabungan.
- Looker menyediakan LookML untuk penyempurnaan Eksplorasi yang akan menambahkan tabel gabungan ke Eksplorasi. Salin LookML dan tempelkan ke file model terkait, yang ditunjukkan dalam komentar yang mendahului penyempurnaan Eksplorasi. Jika Eksplorasi ditentukan dalam file Eksplorasi terpisah, dan bukan dalam file model, Anda dapat menambahkan penyempurnaan ke file Eksplorasi, bukan file model. Lokasi mana pun bisa.
Jika perlu mengubah LookML tabel gabungan, Anda dapat melakukannya dengan parameter yang dijelaskan di bagian Menentukan tabel gabungan di LookML di halaman ini. Anda dapat mengganti nama tabel gabungan tanpa mengubah penerapannya pada kueri Jelajahi asli. Namun, perubahan lain pada tabel gabungan dapat memengaruhi kemampuan Looker untuk menggunakan tabel gabungan untuk kueri Eksplorasi. Lihat bagian Mendesain tabel gabungan di halaman dokumentasi Aggregate awareness untuk mendapatkan tips tentang cara mengoptimalkan tabel gabungan guna memastikan tabel tersebut digunakan untuk aggregate awareness.
Mendapatkan LookML tabel gabungan dari dasbor
Opsi lain bagi developer Looker adalah mendapatkan LookML tabel gabungan untuk semua kartu di dasbor, lalu menyalin LookML ke dalam project LookML.
Membuat tabel gabungan dapat meningkatkan performa dasbor secara drastis, terutama untuk kartu yang membuat kueri set data besar.
Jika memiliki izin develop, Anda bisa mendapatkan LookML untuk membuat tabel gabungan untuk dasbor dengan membuka dasbor, memilih Dapatkan LookML dari menu tiga titik dasbor, dan memilih tab Tabel Gabungan:
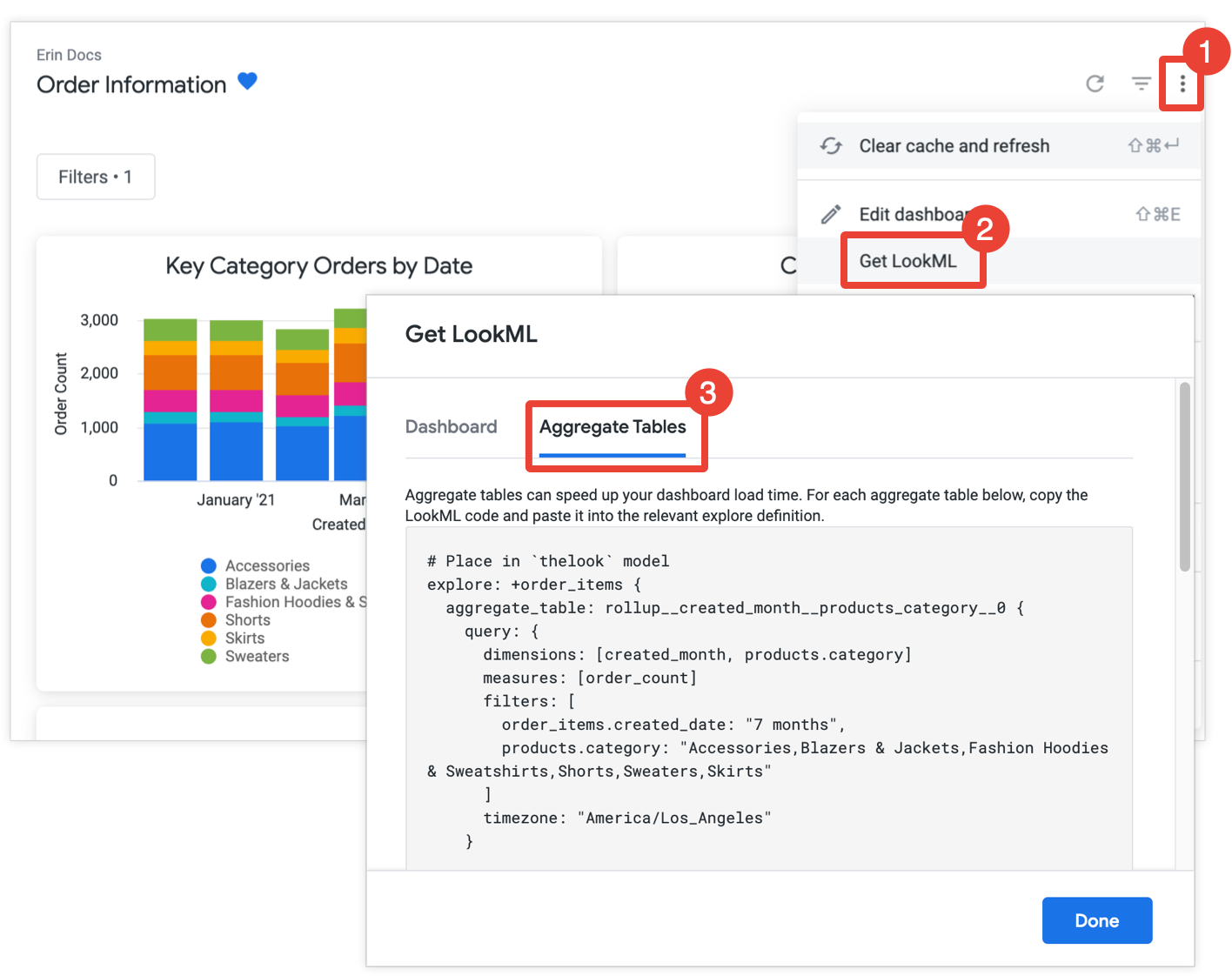
Untuk setiap kartu yang belum dioptimalkan dengan pengenalan agregat, Looker menyediakan LookML untuk penyempurnaan Eksplorasi yang akan menambahkan tabel gabungan ke Eksplorasi. Jika dasbor menyertakan beberapa kartu dari Eksplorasi yang sama, Looker akan menempatkan semua tabel gabungan dalam satu penyempurnaan Eksplorasi. Untuk mengurangi jumlah tabel gabungan yang dihasilkan, Looker akan menentukan apakah tabel gabungan yang dihasilkan dapat digunakan untuk lebih dari satu kartu dan, jika ya, akan menghapus tabel gabungan yang berlebihan yang dapat digunakan untuk lebih sedikit kartu.
Salin dan tempel setiap penyesuaian Explore ke dalam file model terkait, yang ditunjukkan dalam komentar sebelum penyesuaian Explore. Jika Eksplorasi ditentukan dalam file Eksplorasi terpisah, dan bukan dalam file model, Anda dapat menambahkan penyempurnaan ke file Eksplorasi, bukan ke file model. Lokasi mana pun bisa.
Jika filter dasbor diterapkan ke tile, Looker akan menambahkan dimensi filter ke tabel gabungan tile sehingga tabel gabungan dapat digunakan untuk tile. Hal ini karena tabel gabungan hanya dapat digunakan untuk kueri jika filter kueri mereferensikan kolom yang tersedia sebagai dimensi dalam tabel gabungan. Lihat halaman dokumentasi Pengenalan agregat untuk mengetahui informasinya.
Jika perlu mengubah LookML tabel gabungan, Anda dapat melakukannya dengan parameter yang dijelaskan di bagian Menentukan tabel gabungan di LookML di halaman ini. Anda dapat mengganti nama tabel gabungan tanpa mengubah penerapannya ke kartu dasbor asli, tetapi perubahan lain pada tabel gabungan dapat memengaruhi kemampuan Looker untuk menggunakan tabel gabungan untuk dasbor. Lihat bagian Mendesain tabel gabungan di halaman dokumentasi Aggregate awareness untuk mendapatkan tips tentang cara mengoptimalkan tabel gabungan guna memastikan tabel tersebut digunakan untuk aggregate awareness.
Contoh
Contoh berikut membuat tabel gabungan monthly_orders untuk Eksplorasi event. Tabel gabungan membuat jumlah pesanan bulanan. Looker akan menggunakan tabel gabungan untuk kueri jumlah pesanan yang dapat memanfaatkan perincian bulanan, seperti kueri untuk jumlah pesanan tahunan, kuartalan, dan bulanan.
Tabel gabungan disiapkan dengan persistensi menggunakan orders_datagroup datagroup. Selain itu, tabel gabungan ditentukan dengan publish_as_db_view: yes, yang berarti Looker akan membuat tampilan database yang stabil di database untuk tabel gabungan.
Definisi tabel gabungan akan terlihat seperti berikut:
explore: event {
aggregate_table: monthly_orders {
materialization: {
datagroup_trigger: orders_datagroup
publish_as_db_view: yes
}
query: {
dimensions: [orders.created_month]
measures: [orders.count]
filters: [orders.created_date: "1 year", orders.status: "fulfilled"]
timezone: America/Los_Angeles
}
}
}
Hal-hal yang perlu dipertimbangkan
Lihat bagian Mendesain tabel gabungan di halaman dokumentasi Aggregate awareness untuk mendapatkan tips tentang cara membuat tabel gabungan secara strategis:
Dukungan dialek untuk kesadaran agregat
Kemampuan untuk menggunakan kesadaran agregat bergantung pada dialek database yang digunakan koneksi Looker Anda. Dalam rilis Looker terbaru, dialek berikut mendukung awareness agregat:
| Dialek | Didukung? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |